基于深度差异性网络的真假面瘫识别
2019-04-15管子玉许鹏飞辛晓瑜
管子玉,刘 杰,谢 飞,许鹏飞,辛晓瑜
(1.西北大学 信息科学与技术学院,陕西 西安 710127;2.上海交通大学 医学院 附属瑞金医院,上海 200025)
面瘫是一种常见病,发病范围很广,不受年龄限制,不仅会对患者的生活造成一定的影响,同时也会对其内心造成一定的打击,严重影响着患者的身心健康。随着面瘫发病率的不断增加,越来越多的学者开始关注面瘫识别研究。
为实现面瘫的自动识别,目前国内外诸多学者已对该方面进行了研究。他们通过关注静态面部不对称和动态面部变化、跟踪面部关键点的运动差异、利用深度学习方法对关键点进行定位、利用深度卷积神经网络(deep convolutional neural network, DCNN)提取特征等方法对面瘫进行识别[1-6]。然而,这些方法均根据人脸的面部异常或不对称情况进行判定,比较武断地将面部不对称或异常确定为面瘫。现实中存在一些面部异常但并非是面瘫患者的人,这种情况我们称之为假面瘫现象。由于研究者们忽略了假面瘫现象的存在,使得现有的面瘫识别方法存在误判情况,从而在一定程度上降低了面瘫识别的准确率。因此,针对上述存在的假阳性问题(称为“假面瘫”),目前的面瘫识别研究领域需要一种更鲁棒的自动化识别方法对真假面瘫进行识别。
通过对真假面瘫的图像和视频数据进行分析发现,面瘫患者在重复做一个面部动作(如闭眼)时,患者每次所做动作几乎无明显差异,而让假面瘫对象在不同时刻重复做相同的面部动作(如正常人模仿面瘫患者的动作)时,其动作前后往往会出现明显差异,如图1所示。

(a1)与(a2)表示面瘫患者的两次闭眼动作;(b1)和(b2)表示正常人两次闭眼动作图1 真假面瘫不同时刻动作图像对比Fig.1 Comparison of the facial states between a facial paralysis patient and a normal person at different times
根据以上情况,我们认为识别真假面瘫的一个重要依据为不同时刻动作的前后差异,当前后动作差异较大时,存在较大概率为假面瘫,当前后动作差异较小时,较大概率为真面瘫患者。以往基于传统的机器学习方法,人们提出了面瘫识别和评价的方法[1,7-8],它们需要执行多个预处理步骤,并且提取的面部特征不包含多次重复相同面部诊断动作时的面部状态差异信息。近年来,学术界对于神经网络的结构有了更深入的研究,例如孪生网络使用双通道CNN分别提取两幅图像的特征,并计算两个特征向量之间的欧式距离以评估两幅图像的相似性[9-10]。本文面瘫的识别主要基于不同时刻做同一面部诊断动作时面部状态的不同。受孪生网络思想的启发,我们设计了一个新的神经网络模型,称为深度差异性网络(DDN)。它以两张面部图像作为输入,代表不同时刻同一面部诊断动作幅度达到最大时的面部状态。不同于传统的孪生网络,我们的目标是测量能够区分真假面瘫病例的“差异”,总体思路如图2所示。
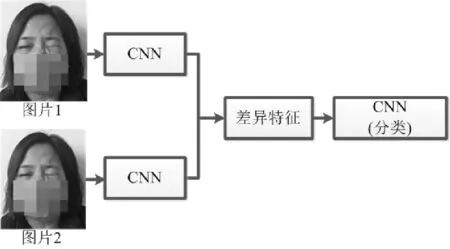
图2 总体解决方案Fig.2 The overall solution scheme
DDN通过一个双数据流卷积神经网络(two-stream CNN)提取不同时刻的同位状态图像的深层特征,并根据所提取特征计算两张图像间的特征差异;再利用单分支CNN提取深层差异特征的特征,实现真假面瘫识别。在DDN中,two-stream CNN提取的是一对图像的深层特征图,特征图的提取保留了图像的纹理、形状、面部器官位置等特征信息;通过计算两张图像的特征图差异(称为“差异特征图”),可获得面部纹理、形状、面部器官位置等特征的差异;通过CNN提取差异特征图的特征(即自动提取对判断真假面瘫有益的高层特征),使得网络着重关注于面部图像之间差异信息的特征。
1 相关工作
现如今由于面瘫发病率的不断增高,高效、自动化的面瘫识别方法成为临床诊断的迫切需要,目前,国内外诸多学者已对面瘫识别进行了相关研究,提出了各种基于不同算法的面瘫识别方法,这些识别方法为临床诊断提供极为高效、便利的诊断途径,克服了主观因素对诊断结果的影响,并且在一定程度上达到了较高的识别率。
1)基于关键点检测和边缘检测算法的面瘫识别研究:Liu Li′an等人在2010年提出利用SUSAN边缘检测算法,通过关注特定面部区域的表面积变化对面瘫进行识别[11];Wang Ting等人在2016年的面瘫研究中提出,利用主动形状模型(ASM)的关键点定位算法,结合患者面部静态特征与动态变化,根据静态面部不对称和动态面部变化自动评估面部麻痹程度[1];Nishida等人同样利用关键点检测算法,选择左颊点和右颊点作为一对关键点进行定量分析,首先计算出关键点移动距离,然后根据关键点之间的运动差异对麻痹程度进行定量测量[2]。
2)基于红外热成像和滤波器算法的面瘫识别研究:Liu Xulong等人利用一种红外热成像算法,以获得面部相关区域的温度分布特征,实现面瘫的自动化评估[12];Ngo等人提出利用同心调制滤波器,对滤波后的图像进行脸部两侧对称性和不对称性的测量,根据测量信息对面瘫进行评估分析[13]。
3)基于深度学习方法的面瘫识别研究:Yoshihara等人提出了基于深度CNN的面瘫特征点自动检测方法,先利用主动外观模型(AAM)进行关键点检测,之后将中心带有检测点(特征点)的区域作为DCNN输入,实现关键点精确定位[5];Guo Zhexiao等人提出利用DCNN算法对面瘫进行客观评估,将整张图像作为输入,捕捉脸部区域并通过DCNN提取特征[6]。
这些基于不同算法的面瘫自动化识别方法虽然能在一定程度对面瘫症状进行识别,但仍存在一些问题:①在基于边缘检测与关键点检测的识别算法中,首先,边缘检测与关键点检测大多依赖于检测模板,模板的质量会对其准确性产生一定的影响;其次,一些方法根据图像区域计算表面积差异,或根据关键点位置距离计算面部不对称性,这类方法不能体现其较好的适用性,且计算方法复杂、计算量大;再者,传统的特征提取方法只能提取纹理形状等单方面特征,不能对其进行有效的结合。②基于红外热成像和滤波器的识别方法的缺点在于,利用红外热成像技术形成的图像对比度低,分辨细节的能力较差;利用滤波器方法对图像滤波后进行测量同样依赖于测量模板。此外,这些算法均针对单张图像的面部异常情况作出评估,比较武断地将面部异常的图像确定为面瘫图像。③基于深度学习的识别方法对于特征的学习有了较好的效果,一定程度上提高了面瘫识别的准确率并减少了计算量,但与以上非深度学习方法一样,均存在一个问题:将单幅人脸图像呈现异常者判定为面瘫患者。可见,现有的面瘫识别算法最为突出的问题是,忽略了正常未患病的人(假面瘫)亦可能存在面部异常和不对称,无法很好地区分真假面瘫。当假面瘫数据存在时,识别结果存在一定的误判。因此,本文希望通过设计一个新的网络结构来实现对真假面瘫的较好识别。
2 基于深度差异特征的面瘫识别方法
2.1 关键帧的选择和面部区域的定位
对于实验数据中的视频数据,我们需要提取视频动作的关键帧,用于DDN的训练与测试。针对这个问题,我们利用multi-stage CNNs方法定位视频中动作的起始与结束位置[14-17],获取动作发生的连续帧,并选取这些动作连续帧的中间帧(即动作幅度最大时的帧)作为实验所用数据,关键帧获取过程如图3所示。
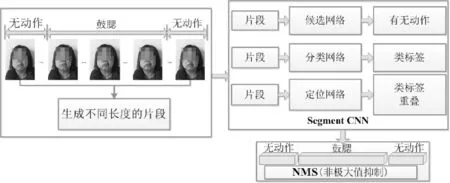
图3 利用multi-stage CNNs获取视频动作关键帧Fig.3 The key frames obtained by multi-stage CNNs from videos
在实验过程中,由于数据采集的环境不同,导致数据间存在不同的背景信息,而DDN的重要依据为图像特征的差异性,因此,这些背景信息一定程度上干扰了实验效果,降低了识别的准确率。为了尽可能地降低背景信息对实验结果的干扰,对于实验数据,需要最大程度去除图像的背景信息。本文利用Faster R-CNN进行区域检测[18-20],提取图像中脸部区域,去除与脸部信息无关的背景信息,尽可能地避免因背景不同而产生的图像之间的差异信息对实验结果所造成的影响,如图4所示。
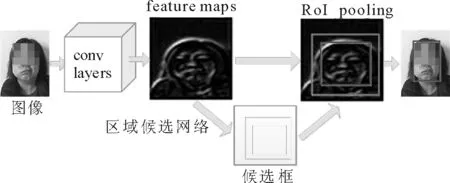
图4 Faster R-CNN目标检测Fig.4 Object detection with Faster R-CNN
2.2 深度差异性网络模型
本文根据真假面瘫的识别依据——不同时刻同一诊断面部动作间的差异,设计了一套基于DDN的面瘫识别算法。该网络模型的基本原理是通过two-stream CNN提取深层特征的差异性信息,再利用CNN从该差异性信息中进一步提取差异的特征,最终根据深度差异特征对面瘫的真假性进行识别。
根据DDN的设计原理,可将网络分成两部分。前半部分为two-stream CNN,用于深度特征图提取。我们将被测对象在不同时刻所做同一动作的两张图像输入two-stream CNN,分别得到两张图像的输出特征图序列,然后,将两个特征图序列分别进行融合(256个特征图融合成一张),形成一对特征图,进而构造一个特征图差异度量,作为两张图片的差异性特征的计算函数,得到差异特征图。后半部分用于提取差异特征图的特征,将网络前半部分获取的差异特征图输入一个深层CNN,提取差异特征(特征图间的差异)的特征,并利用softmax函数进行分类,得到真假面瘫识别结果。
根据孪生网络原理[9-10],two-stream CNN采用同一网络相同参数的模型:包含7个卷积层和两个池化层,同时提取两张图片的深层特征。由于在提取差异特征时,需要关注的是人脸图像的纹理及器官位置、形状等信息,根据这些信息的差异来识别面瘫的真假性,因此,在two-stream CNN部分,需要通过多个卷积层提取图像的深层特征图。通过利用不同深度的网络模型提取特征图,我们发现7个卷积层可以将图像的纹理特征等信息较好地提取出来,并且为差异特征函数提供较为清晰且适用的数据信息。
通过实验分析,我们将two-stream CNN训练模型最终确定为有7个卷积层与两个池化层组成的CNN:
(conv+ReLU)+
(conv+ReLU+pooling)+
(conv+ReLU)+
(conv+ReLU+pooling)+
(conv+ReLU)×3
(1)
网络卷积层的卷积核大小均为3×3,步长默认为1,池化层池化大小均为2×2,步长为2,激活函数均采用ReLU函数[21],通过多层卷积和池化最终获得256个深层特征图。这样,就通过7层卷积和两层池化,最终从每对人脸图像数据中分别获取包含256个特征图的序列F(Im),Im表示输入的图像,m为图像序号,m=1,2。
F(Im)=(fm,1,fm,2,fm,3,…,fm,256)。
(2)
其中,fm,i表示第m个图像的第i个特征图,i=1,2,…,256。
DDN的核心是特征的差异性特征。孪生卷积网络通过计算图像特征的欧式距离来判定相似度,而DDN关注于图像的纹理差异,眼、鼻子、嘴等器官的位置与形状差异等信息,这些差异作为真假面瘫的判定依据。因此,我们希望获取人脸图像数据的特征图之间的差异,通过提取差异特征图的特征来判定面瘫的真假性。
为了获取由two-stream CNN提取的特征图之间的差异,在网络中需要构造一个度量函数,用于计算深度特征的差异特征图。
由于CNN提取的特征图为一个序列,为了方便计算图像特征图之间的差异,把由two-stream CNN提取的特征图序列F(I1)和F(I2)分别进行融合,
Fm=(fm,1+fm,2+fm,3+…+fm,256)/256。
(3)
其中,Fm表示融合后的特征图。每对图像数据得到融合后的特征图F1和F2,然后构造一个用于获取差异特征的度量函数,
DF=F1-F2。
(4)
我们发现,通过这个简单的差异特征度量函数可以有效提取两个特征图的差异信息,得到差异特征图。
DDN后半部分的主要作用是通过提取深度差异特征的特征以实现真假面瘫识别。研究表明,CNN可在其顶层加上一个softmax作为分类器,广泛应用于图像分类,并达到了极高的分类准确率。我们在网络结构后半部分连接一个二元分类器,以进行真假面瘫识别。通过模型训练测试发现,一个深度为8的CNN可以实现较好的分类效果,因此,我们将网络后半部分的CNN结构设置为
(conv+ReLU+pooling+LRN)×2+
(conv+ReLU)×2+
(conv+ReLU+pooling)+
(fc+ReLU)×2+softmax
(5)
网络第1层卷积层采用大小为11×11、步长为4的卷积核,第2层卷积核大小为5×5,步长默认为1,前两层在进行卷积和池化的同时,利用LRN(Local response normalization)技术进行归一化。第3,4,5层卷积核大小均为3×3,步长默认为1,网络中池化大小均为3×3,步长为2。该单分支网络利用多层卷积与池化,提取深度差异特征的高层特征,再通过2层全连接层,送入softmax层输出最终分类结果。网络整体设计框图如图5所示,图6显示了DDN在特定示例下的内部状态。
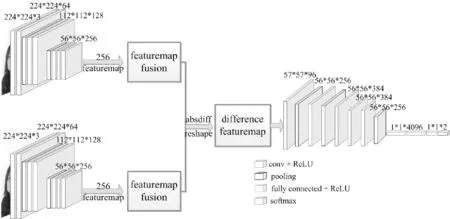
图5 深度差异性网络(DDN)Fig.5 Deep differentiated network (DDN)

图6 特定例子中深度差异性网络的内部状态Fig.6 The intermediate results of the DDN for a specific sample instance
我们用two-stream CNN提取图像深层特征,然后用差异特征函数计算特征差异,最后用单分支CNN提取深度差异特征的特征并进行分类。这些组件共同组成了深度差异性特征网络DDN,实现了对真假面瘫的分类识别。综上所述,DDN是一个根据差异性特征的特征进行分类的深度神经网络模型。
3 实验与分析
3.1 实验计划
为验证提出的方法能够有效识别真假面瘫,我们采集了面瘫患者和正常人在做面部动作时的视频进行实验,并针对训练过程及测试结果对比现有几种识别方法进行讨论。
在数据采集过程中,我们借鉴Kihara等人提出的动态面部表情数据库的建立方法和临床医生的面瘫诊断流程[22],建立了一个视频数据库,记录了健康志愿者和面瘫患者的面部动作。其中面瘫患者的数据包括微笑、示齿、耸鼻、皱眉、抬眉、闭眼、鼓腮等动作数据;健康志愿者的面部数据包括正常人模仿面瘫患者各类动作的数据。对于数据的要求:每位动作数据提供者需针对同一动作在不同的时刻随机重复做两次。通过这种采集方式,我们收集了57例面瘫患者和106例正常人的面部运动录像。经过视频编辑,共有2 282个视频片段(163×7×2)作为实验数据,即1 141对。从这些视频中提取的一些面部图像或帧记录了相应的面部动作的最大面部状态,如图7和图8所示。图7(a)和图8(a)分别是真假面瘫闭眼的面部动作,图7(a1),7(a2)和图8(a1),8(a2)是在不同时间出现的最大面部状态,图7(b),7(c)和图8(b),8(c)展示的是另外两种面部动作的结果。可见,面瘫患者在不同时刻做同一诊断动作时所出现的最大面部状态非常相似,但正常人的面部状态却存在一定的差异。
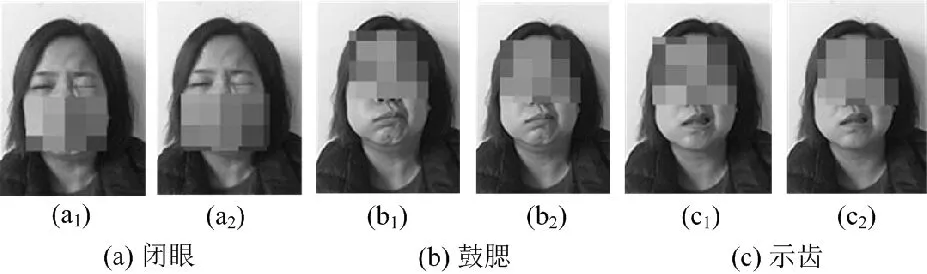
图7 面瘫人脸部分动作图像Fig.7 Partial movement images of a facial paralysis patient face

图8 假面瘫人脸部分动作图像Fig.8 Partial movements images of false facial paralysis face
在模型训练之前,对采集到的原始视频进行一些预处理,利用Multi-stage CNNs从视频中提取记录最大面部运动的关键帧[14-16],并通过Faster RCNN检测主要面部区域,以去除大部分无关的背景信息[18-20],如图9所示。

图9 对图像数据进行预处理去除背景信息Fig.9 Image data preprocessing by Faster RCNN to remove background information
3.2 实验结果
在DDN的训练过程中,使用疑似患者的两幅记录了同一面部动作在达到最大幅度面部运动状态时的面部图像作为DDN的输入数据,实现对面部瘫痪的识别。在实验中,700对人脸图像用作训练数据,剩下的441对人脸图像用作测试数据。将该过程重复10次,并对实验结果的平均值进行分析。
对于实验数据,需要说明的是,由于数据采集是个不连续的过程,所有的视频片段都是在任意地点和随机时间拍摄的,因此造成部分数据存在背景不同、脸部发生偏转等现象,使得数据存在由外部因素产生的较大差异;此外,由于不同的人对于临床诊断面部动作有不同的理解,这导致疑似患者在重复相同的诊断面部动作时,其面部状态是不同的。基于上述情况,我们的识别结果在一定程度上依赖于所选数据,识别任务难度较大。
由于本文的任务是识别真假面瘫,假面瘫中包括了自然不对称的人脸数据以及正常人模仿面瘫病人的表情动作数据。而现有的面瘫识别方法关注点均为面部异常或不对称,且大多以面部不对称性作为识别依据,造成将假面瘫现象误识别为面瘫的情况。这些现有方法不具备识别假面瘫的能力,无法达到识别真假面瘫的效果,因此,本文中我们不再与这些方法进行实验比较。
针对真假面瘫的识别任务,根据现有方法的识别原理,我们选取了几种具有代表性的神经网络模型进行实验并观察效果:LeNet,AlexNet和VGG,这些方法均利用一个单一的卷积神经网络进行面瘫识别,将带有标签的单一的实验数据直接输入网络,通过网络提取特征,并利用softmax实现二分类得到分类结果,实验结果如表1所示。从表1可以看到,这些传统方法的面瘫识别效果并不太好,DDN在多个评价指标方面比这些传统方法具有更好的性能。平均起来,DDN比VGG,AlexNet和LeNet在准确率方面提高了26.17%,16.5%和15.67%;在精确度方面提高了25.74%,14.29%和15.73%;在召回率上提高了26%,20.33%和14%,在F1值上提高了25.77%,17.69%和15.24%。此外,DDN的优点也在图10中得到了证实,图10将这些评价指标以直方图的形式输出显示。
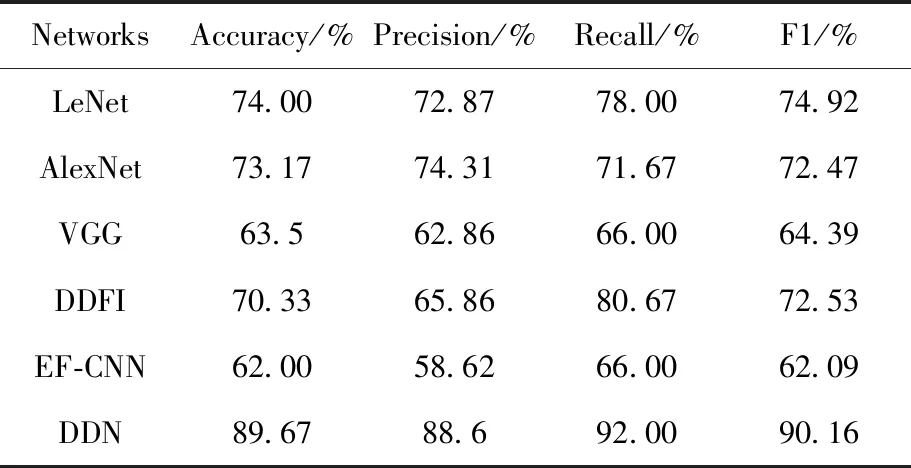
表1 不同方法的实验结果Tab.1 Experimental results on different methods
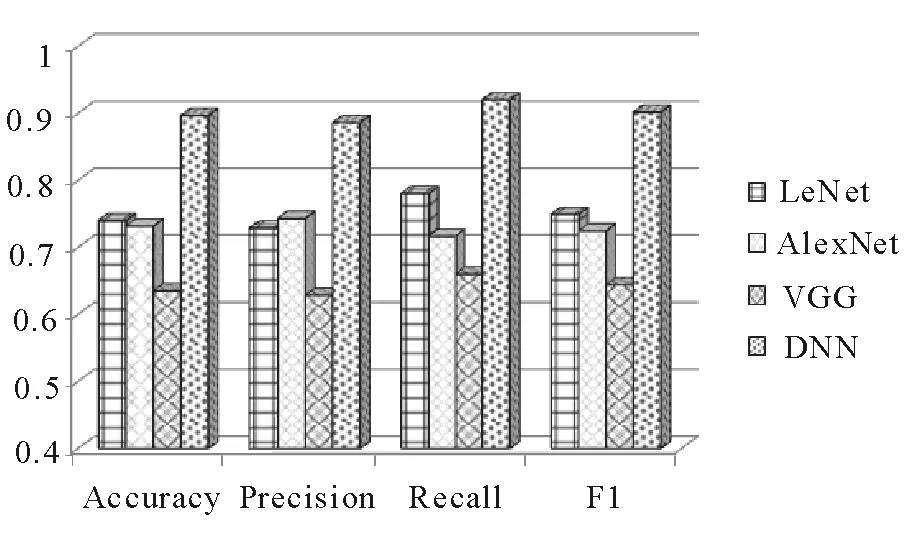
图10 DDN模型与传统神经网络模型在准确度、精确度、召回率和F1值上的比较Fig.10 Comparison of DDN and traditional neural network models in accuracy, precision, recall and F1-measure
本文提出了利用面瘫患者在不同时间做面部动作时面部状态的差异进行面瘫识别的思想。那么,对基于人脸图像直接进行作差(DDFI)后提取的人脸特征或基于两个卷积神经网络(EF-CNN)直接提取特征差异的面瘫识别方法进行性能测试,其效果如何呢?在这里,我们将DDFI,EF-CNN和DDN这3种方法进行比较,实验结果如表1所示。从表1可以看出,DDFI比EF-CNN具有更好的性能,但与DDN相比其各性能指标还是要低很多,其中准确率低19.34%,精确度低22.74%,召回率低11.33%,F1值低17.63%。因此,这两种方法不能取得更好的结果。这是因为DDFI是基于图像本身的差异来进行判断的,但是,这些面部图像在背景、光线、拍摄角度等因素上存在很大差异,而这些差异不是面部状态的差异。EF-CNN是基于孪生网络的识别方法,利用函数对图像特征进行映射,通过差值(欧式距离)损失函数进行类别匹配,忽略了部分面部纹理、形状、面部器官位置等差异信息,例如,面部器官向左或右两个方向歪斜而形成的差异,这使得该方法无法达到理想的结果。相比之下,DDN具有最好的性能,这主要归因于DDN在提取特征之间的差异的特定能力。此外,图11清楚地显示了DDN在4个评价指标中一般优于DDFI,EF-CNN这两个比较方法。
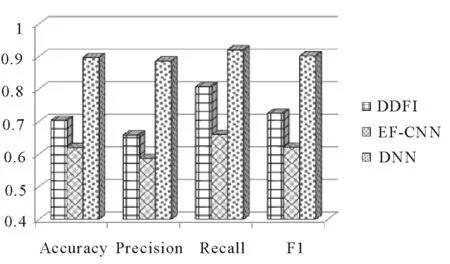
图11 DDFI, EF-CNN在准确率、精确度、回归率以及F1值上与DDN的比较Fig.11 Comparison of DDFI, EF-CNN and DDN in accuracy, precision, recall and F1-measure
4 结 论
本文提出了一个面瘫识别中存在的新问题:假面瘫数据导致的面瘫误判,并且为了解决此问题,在孪生神经网络基础上,设计了一种新网络:深度差异性神经网络,为真假面瘫的识别奠定了基础。对于真假面瘫的识别,解决了自动化面瘫识别中由于假面瘫数据的存在而导致的误判现象,进一步提高了面瘫识别的准确率。此外,DDN采用two-stream CNN与单一深层CNN相连的网络,该网络关注人脸五官的纹理形状、位置、肌理等特征差异,通过提取差异性特征的高层特征进行分类,很好地解决了真假面瘫识别问题,并达到了较高的准确率。
