基于分布式架构的海量文本快速相似度检测研究
2019-04-12晋晓琳张树武刘杰
晋晓琳,张树武,刘杰
(1.中国传媒大学 信息工程学院,北京 100024;2. 中国科学院自动化研究所 数字内容技术与研究中心,北京 100190;3.北京电影学院未来影像高精尖创新中心,北京 100088)
1 引言
在高速发展的21世纪,每时每刻都有大量的信息产生并在互联网上快速传播。数据集合规模已实现从GB到PB的飞跃,未来网络大数据还将实现近50倍的增长。IDC《数字宇宙》的研究报告表明:2020 年全球新建和复制的信息量将超过40ZB,是2012年的12倍;而中国的数据量则会在2020年超过8ZB,比2012年增长22倍。虽然数据量的飞速增长带来了大数据技术和服务市场的繁荣发展,但面对海量文本数据人们变得越来越手足无措,所以人们越来越希望能够在海量文本环境下快速精确地提取出所需要的信息,从而对所选信息进行后续处理。为了解决这一问题,就需要一个文本相似性检测技术,使人们能够快速准确地从海量数据中找到最为相似的文本。
文本相似度算法一直是自然语言处理领域研究的重点之一,国内外学者也提出了一些解决方案。基于距离的计算相似度的方法主要有余弦距离[1]、编辑距离[2]、汉明距离、欧几里得距离。如丁智斌等提出先用VSM向量空间模型进行文本向量化[3],通过使用余弦相似度和 Jaccard 相似度这两种基于向量内积的方法进行相似度计算。胡维华等利用汉明距离计算文本相似度[4],该方法首先采用TF-IDF算法以及《知网》的语义信息来加强语义信息,然后利用汉明距离计算文本相似度,避开对高维稀疏矩阵的直接处理并提高了文本计算的准确性。基于距离的计算方法适用于文本数量较小的情况,在海量文本环境下,该计算方法的效率非常低。VSM 向量空间模型(Vector Space Model)是一种基于向量空间的方法,它是由Gerard Salton 等在1969年首先提出的[5] [6]。该模型需要逐个进行向量化,并进行余弦计算,比较消耗CPU处理时间,所以不适合于海量文本环境下。Simhash算法是2002年由Google 的Charikar提出的文本指纹算法[7]。该算法主要用来处理Google网页去重问题,也是目前主流的海量相似度算法之一[8] [9] [10]。Simhash算法主要通过指纹间的汉明距离来比较文本的相似程度,而且其“降维”的思想使得检测速度快,常常被用做处理海量文本查找。但该算法的实质是基于哈希的算法,只能得到一个粗略的相似度筛选,高的相似度并不意味着文本一定相似。
现在使用最多的搜索引擎主要是Elasticsearch和Solr[11][12][13]。Elasticsearch是一个建立在全文搜索引擎 Apache LuceneTM基础上的搜索引擎,可以说Lucene是当今最先进、最高效的全功能开源搜索引擎框架。它是一个实时分布式的搜索引擎和数据分析引擎,能够进行全文检索,结构化检索,数据分析,可以帮助你用前所未有的速度去处理大规模数据。对于海量数据来说,ES可以自动将大规模数据分布到多台服务器上进行存储和检索,而不需要额外建立数据库。对于Solr来说,在建立索引时,它会产生io阻塞,查询性能较差,实时索引搜索效率不高。所以海量数据进行搜索时,ES更具有优势。因为ES实时搜索的优点,国内外很多公司都使用该框架作为信息检工具。例如,Github公司使用Elasticsearch搜索20TB的数据,包括13亿的文件和 1300亿行的代码;维基百科作为多语言的网络百科全书,整个网站的总编辑次数已超过10亿次,它使用Elasticsearch来进行全文搜索并高亮显示关键词,以及给用户进行搜索推荐等功能;The Guardian是英国三大综合性内容日报之一,Elasticsearch作为该新闻网站的搜索引擎去记录用户行为日志、发布用户评论、进行数据分析。
在对海量文本进行搜索查询时,Elasticsearch能够分布式实时文件存储,并将每一个字段都编入索引,使其可以被实时搜索。本文选用ES作为文本相似度检测的第一步,通过多个关键词的并行搜索来筛选出候选样本。余弦相似度算法适合于小样本集合,因此本文选用TF-IDF作为关键词提取算法,通过关键词作为ES查询条件在海量文本环境下快速筛选出可疑候选集,进而再用余弦相似度来进一步找到最为相似的文本。
2 关键技术
2.1 Elasticsearch
Elasticsearch(简称ES)是一个基于Lucene构建的实时、分布式、RESTful的搜索引擎。它的高级之处在于,使用Lucene作为核心来实现所有索引和搜索的功能,使得每个文档的内容都可以被索引、搜索、排序、过滤。同时,它还提供了丰富的聚合功能,可以对数据进行多维度分析;对外统一使用REST API接口进行沟通,即Client与Server之间使用HTTP协议通信 ,Elasticsearch的架构图如图1所示。

图1 Elasticsearch分布式搜索引擎架构图
Elasticsearch进行全文检索有以下流程:(1)建立索引:ES中的索引相当于SQL中的一个数据库,通过建立索引名字来进行后续文档的搜索、更新及删除等操作。不同于传统的关系型数据库,ES能够将数据存储于一个或多个索引中进行分布式索引。分布式索引通过将一个索引进行分片,也就是说将一个索引通过分片又重新分成一个个独立的索引。在海量数据下,ES正是因为对索引进行分片来分摊硬件压力,从而达到能够进行实时快速搜索。在创建索引时,用户可指定其分片的数量,默认数量为5个。(2)建立映射:在存储文本之前需要建立映射,ES中使用Mapping来对存储文本进行分析。使用者可根据需要在Mapping中申明字段的数据类型、是否建立倒排索引、建立倒排索引时使用什么分词器。默认情况下,ES会为所有的string类型数据使用standard分词器来建立倒排索引。这个类似于MySQL在db schema。(3)文本存储:ES是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式。一个文档中包含_index、_type、_id、_source等核心元数据,其中_index说明一个document属于哪个index,这里的index为文本集合建立的索引,索引相当于一个数据库;_type说明document属于index中的哪个类别,也就是数据库中的表;_id代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document ;_source代表了document中具体包含的内容,例如标题、关键词、文本内容等信息,也就是数据库中的字段。一个 ES 集群可以包含多个索引,也就是说索引中包含了很多类型。这些类型中包含了很多的文档,然后每个文档中又包含了很多的字段。(4)文本查询:ES的查询语法(query DSL)分为两部分:query和filter,区别在于查询的结果是要完全匹配还是相关性匹配。filter查询考虑的是“文档中的字段值是否等于给定值”,答案在“是”与“否”中;而query查询考虑的是“文档中的字段值与给定值的匹配程度如何”,会计算出每份文档与给定值的相关性分数,用这个分数对匹配了的文档进行相关性排序。
2.2 余弦相似度
余弦相似度,也称为余弦距离,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。它是文本相似度计算比较经典和常用的算法之一。如果余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫“余弦相似性”。该算法的基本思路是:如果两个文本的用词越相似,它们的内容就应该越相似。因此,一般通过词频来计算它们之间的相似程度。余弦距离计算相似度主要采用以下步骤:第一步,对文本进行分词以及去停用词。对于短文本,可以直接对文本进行分词;而对长文本来说,则需要进行文本关键词提取;第二步,计算词频。列出文本中所有词语,如果文本中有该词语就加1,没有出现则为0;第三步,通过第二步计算出的词频可以生成文本的词频向量;第四步,计算向量之间的余弦距离,值越大就说明两个文本越相似。文本的向量为多维向量,设向量A=(A1,A2,,An),B=(B1,B2,,Bn),则余弦距离公式如公式1所示:
(1)
2.3 TF-IDF
TF-IDF(term frequency-inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术[14]。TF-IDF是一种统计方法,用以评估一个词在一个文档集中的某一份文档的重要程度。TF-IDF主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或短语在该文章中占有重要位置,而且更能代表该文章的主题。TF-IDF实际上是:TF * IDF,其中,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。如果一个词的TF-IDF的权重越大说明这个词汇有很好的辨别能力。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低词语频率,可以产生出高权重的TF-IDF。因此,通过TF-IDF来提取文本的关键词。TF-IDF计算公式如公式2所示:
(2)
3 分布式海量文本快速相似度检测技术研究改进
本文所研究的海量文本快速相似度检测主要是使用分布式搜索引擎框架Elasticsearch来筛选出候选样本集,然后使用余弦距离来进行最终的相似度比较,最后选出相似度最大的值为所需样本。分布式搜索框架通过输入关键词来进行文本搜索,搜索出来的文本都是包含关键词的文本,所以可以通过搜索引擎在海量文本下尽可能多的过滤到无关文档,召回相关文档,从而来加快比较速度。分布式搜索框架只能做到关键词或者关键句的搜索,也就是说只能做到筛选出文本含有搜索关键词或者句子的文本。如果句子有所改动就无法搜索出来,所以筛选之后的候选样本集需要采用精确的相似度算法进行更加精确的比对,最后选出最为相似的文本。
分布式海量文本快速相似度检测技术研究流程如图2所示,具体步骤如下:
1.首先将海量文本集合存入ES分布式搜索引擎中,并设置中文分词器。这样做主要是可以进行词语对的搜索,例如,搜索“科学”,如果设置分词器就会查询到包含“科学”的词的文本,而不会搜到只包含“科”或“学”的文本,从而能够找到更加相关的文本;
2.通过特征提取算法TF-IDF来进行文本关键词的提取,提取的关键词作为ES搜索引擎的查询条件。每篇文本选取TF-IDF值高的前20个关键词来表示文本主题意思;
3.将提取的文本关键词作为ES的查询条件来筛选出文本候选样本。本文从每篇文本提取TF-IDF高的前20个关键词中并选取前10个关键词作为可以ES的查询条件,并通过最少匹配来选取候选文本;
4.经过召回一定数量的文本作为候选样本进行余弦相似度计算。例如全文比对召回前150个文本,句子比对的话召回前200。那么,对候选文本集合进行余弦距离的比较,最后选取文本相似度最大作为相似文本输出。

图2 分布式海量文本快速相似度检测技术研究流程框图
4 实验验证
4.1 实验数据及工具
本实验选用了THUCNews作为实验数据,总共有836075万条新闻数据,数据主要分为财经、科技、体育、社会、教育等十四类新闻。THUCNews是根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选过滤生成,均为UTF-8纯文本格式。在新闻中同一类型的新闻数据之间的特征词很相似,这也为实验增加难度。
文本预处理过程中,去停用词表采用的是哈工大的停用词表;使用jieba分词来进行文本分词处理。jieba分词支持最大概率法(Maximum Probability),隐式马尔科夫模型(Hidden Markov Model),索引模型(QuerySegment),混合模型(MixSegment),共四种分词模式,同时有词性标注,关键词提取,支持自定义字典等功能。
实验运行环境是在CPU为Intel(R)Core(TM)i7- 4790 @3.60GHz,内存16GB,操作系统为windows7 64bit,采用Python语言实现算法,并在Anaconda3自带的Spyder编译器上运行,分布式搜索引擎选用Elasticsearch 2.3.4版本,IK为搜索引擎的分词器。
4.2 实验结果分析
实验分为2个实验,其中实验1主要是通过文本之间的相似度比较;实验2是句子与文本之间的相似度比较。为了更加符合实际环境,我们从80多万篇文本中随机选取500篇新闻文本,并对其进行25%左右的随机修改。对文本的修改主要是对文本进行开头、结尾、中间的不同程度的删除、增加和修改,从而更加符合现实中大多数相似文本并不是完全相似,都有一下杂质的干扰存在。这两个实验主要是通过修改后的文本和句子,能够通过快速精确的找到未修改前的文本以及包含该句子的文本。
实验1中,主要是修改后的500个文本在80多万的文本集合中找到对应的文本,从而验证该算法的性能。该实验通过Simhash算法、Simhash算法结合余弦距离以及ES搜索引擎结合余弦距离的方法进行召回率、准确率以及时间复杂度的比较。在ES结合余弦距离的算法中,输入10个关键词,且最少匹配6个;然后通过ES召回前150个文本,最后用余弦距离与召回的文本进行相似度比较,选出最大相似度文本。实验1结果如图3所示:

图3 修改文本相似度比较
实验2中,从文本集合中通过句子符号进行文本分割,并且在众多句子集合中随机选取68个句子,并对句子进行一定程度的修改。在对文本按句子分割时,会为每个句子配上对应的id号,从而能更好的验证。该实验的目的主要是通过修改后的句子来找到句子所在的文本。该实验通过Simhash算法、Simhash算法结合余弦距离、余弦距离、最长公共子序列以及ES结合余弦距离来进行准确率和时间复杂度的比较。在ES结合余弦距离的算法中,输入10个关键词,且最少匹配6个,且ES召回前200个文本。对召回文本进行分句,然后用余弦距离进行句子之间的比较,最后选出相似度最大的句子所在文本为最后结果。实验2结果如图4所示:
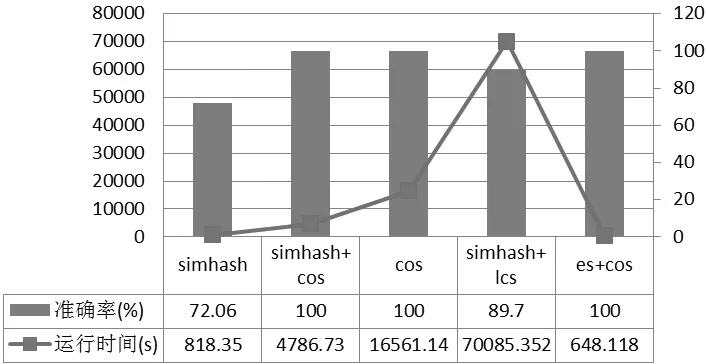
图4 修改句子相似度比较
通过实验可知:实验1中该实验将Simhash的汉明距离设为10、16、25,通过实验比较发现阈值为16的准确率以及召回率最为合适。ES结合余弦距离方法的召回率和准确率为100%,运行时间为77.45s;而阈值为16的Simhash算法结合余弦距离的方法召回率为98.4%,准确率为96.7%,运行时间为574.38s。对于修改文本来说,本文方法在准确率和召回率有很大的提升,而且时间上也满足海量文本快速检测的要求。在实验2中,该实验通过比较发现,LCS和余弦距离的方法运行时间太长,不适合海量文本;只用Simhash算法进行相似度虽然比较,时间上缩短,但是准确率只有72.06%;Simhash结合余弦距离与ES结合余弦距离的方法比较适合海量文本环境下,其中,两者在准确率上都为100%,但是,前者的运行时间是后者的7.4倍,所以分布式搜索引擎结合余弦距离的方法更加适合海量文本。
5 结束语
为了满足海量文本环境下快速且准确的找到所需文本,本文提出了基于分布式架构的海量文本快速相似度检测技术。本文主要是通过常用海量文本相似度算法Simhash与分布式搜索引擎ES进行比较发现,分布式搜索引擎在准确率、召回率以及时间复杂度上都更加适合作为海量文本初步筛选算法。该方法比simhash算法能够更有效的缩小比较范围来提高查找速率。对于分布式搜索引擎来说,准确率以及召回率的高低取决于查找的关键词的精确性,所以为了完善本文提出的算法,接下来需要更加精确的关键词提取算法来提取更能代表文本意思的词语,从而缩小候选文本集来进一步加快比较速度。
