基于深度CNN和极限学习机相结合的实时文档分类
2019-04-01董莺艳
闫 河 王 鹏 董莺艳 罗 成 李 焕
1(重庆理工大学计算机科学与工程学院 重庆 401320) 2(重庆理工大学两江人工智能学院 重庆 401147)
0 引 言
如今,商业文件(见图1)通常由文档分析系统(DAS)进行处理,以减少工作人员的工作量。DAS的一项重要任务是对文档进行分类,即确定文档所指的业务流程的类型。典型的文档类是发票、地址变更或索赔等。文档分类方法可分为基于图像[1-6]和基于内容的方法[7-8]。DAS选取哪一种方法更合适,通常取决于用户处理的文档。像通常的字母一样,自由格式的文档通常需要基于内容的分类,而在不同布局中包含相同文本的表单则可以通过基于图像的方法来区分。

图1 来自不同类别的Tobacco-3482数据集的样本图像
然而,并不总是事先知道文档属于什么类别,这就是为什么在基于图像的方法和基于内容的方法之间很难选择的原因。一般来说,基于图像的方法是大多数学者首选的方法,因为它直接工作在数字图像上。由于文档图像类的多样性,存在高类内方差和低类间方差的类,分别如图2和图3所示。因此,很难找到用于文档图像分类的人工特征提取方法。

图2 Tobacco-3482数据集广告类的文档, 显示了较高的类内差异

图3 不同类别数据集的类间差异
近几年,随着深度学习的发展,该技术已经应用到众多领域。众多学者将深度学习应用于文档结构学习中,使用CNN自动学习并提取文档图像中的特征,然后对文档图像进行分类。然而,同样在这种方法中,即使使用GPU训练此过程也非常耗时。通过以上分析,以下简要概述相关研究发展历程。
文献[9]使用布局和结构相似性方法进行文档匹配,而文献[10]将基于文本和布局的特征结合起来。2012年,文献[4]中提出了一种文档分类的方法,该方法依赖于从文档图像的图像块中派生出的编码码字符。在文档学习中编码字典是以一种无监督的学习方式。为此,该方法递归地将图像划分为块,并使用图像块中字的直方图来建模图像块之间的空间联系。两年后,同一位作者还提出了另一种方法,即建立文档图像SURF描述符的编码记录[11],并用之前所提方法,运用这些特征用于文档分类。Chen等[5]提出了一种利用低层图像特征对文档进行分类的方法。然而,它们的方法仅限于结构化文档。以上方法大部分都局限于结构化文件。文献[6]中使用二进制图像中的像素信息对表单文档进行分类。该方法利用k均值算法对图像进行像素密度分类。在文献[12]中,为了准确地识别出中文、日语、泰语等文档,本文提出了CE-CLCNN的深度卷积网络结构。这种结构是基于端到端的学习模型,并通过对文档的每个字符作为文档处理。实验表明,该方法取得了不错的识别分类效果。文献[13]中运用卷积神经网络识别文档图像,并运用智能手机的相机提取文档字符,解决了文档因权限不能下载等问题,通过在文档图片上的对比实验取得了较好的效果。文献[14]中提出了一种多视角重构方法,将高维数据映射到低维空间,通过降维处理,并应用于文档分类识别,通过实验验证了此方法有效。文献[15]提出预训练网络结构,并通过训练学习不同大小的文档图像,以增加训练的数据量,在英文和印度文上的实验结果表明,此方法具有更好的识别效果。文献[16]提出了基于区域的深度卷积神经网络框架,用于文档学习,在ImageNet数据集中,通过预训练vgg-16网络结构中导出权重来训练文档分类器,从而实现“域间”转移学习。文献[17]运用了轻量级的神经网络训练Tobacco-3482数据集,在没有使用迁移学习的条件下,取得了不错的效果。在文献[18]中,比较了RVL-CDIP数据集上的使用AlexNet和Google网络架构的性能,显示出比常规方法更高的鲁棒性。同时,在文献[19]分别用AlexNet、VGG-16、Google和ResNet-50模型对RVL-CDIP和Tobacco3482数据集进行了迁移学习测试。尽管上述基于CNN的深度学习方法在鲁棒性等方面有了很大的提升,但是大部分网络的训练非常耗时。为了使深度神经网络CNN表现出最佳性能同时满足实时训练要求,本文提出使用CNNs[20]和极限学习机(ELM)[21-22]相结合的方法。
在本文中,我们提出使用极限学习机(ELM)的方法完成实时训练。为了克服人工特征提取和长时间训练的困难,我们设计了一种将深度CNN的自动特征学习与高效的极限学习机相结合的方法。此方法共有两阶段:第一阶段是深度神经网络的训练并将其用作特征提取器;第二阶段用ELM进行分类。ELM的本质不同于其他神经网络,具有高效迅速等特点。结果表明,在一幅图像上平均训练时间仅需1 ms,因此显示出对于实时性能的要求。同时,该方法使得神经网络非常适合在增量学习框架中使用。
1 极限学习机

(1)
式中:wi是连接第i个隐含节点和输出节点的权值矩阵;βi是第i个节点的输出权值向量;bi是偏置;函数g为relu、sigmoid等激活函数。
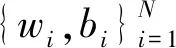
(2)
式中:正则化是为了避免过拟合,其中C是调整系数,通过计算H=[[ψ(x1)]T,[ψ(x2)]T,…,[ψ(xN)]T]T和T=[t1,t2,…,tN]可以得到如下的最优化问题,并称为岭回归:
(3)
上述问题是凸优化问题,并受下列线性条件的约束。
B+CHT(T-HB)=0
(4)
该线性系统可以用数值方法求解,从而得到最优解B*。
(5)
本文方法不需要高分辨率的文档特征,如光学字符识别。相反,它完全依赖于文档的结构和布局来对它们进行分类。
本文提出的网络体系结构是基于AlexNet[21]的CNN网络。它由五个卷积层和一个极限学习机组成。与原有的AlexNet体系结构一样,在最后一个最大池层之后,我们得到了256个大小为6×6的特征映射(如图4所示)。虽然AlexNet使用多个完全连接的层来对生成的特征映射进行分类,但我们建议使用单层ELM。卷积层的权重是在一个大型数据集上预先训练成一个完整的AlexNet网络,此网络有三个全连接层和标准反向传播机制。在训练结束后,全连接层被丢弃,卷积层被固定,并作为特征提取器。然后,由CNN提取的特征向量作为ELM训练和测试的输入向量。该体系结构中使用的ELM是一种单层前馈神经网络。当目标数据集有10类时,我们用隐藏层中的2 000个神经元和10个输出神经元对极限学习机进行测试。隐含层神经元以sigmiod作为激活函数。
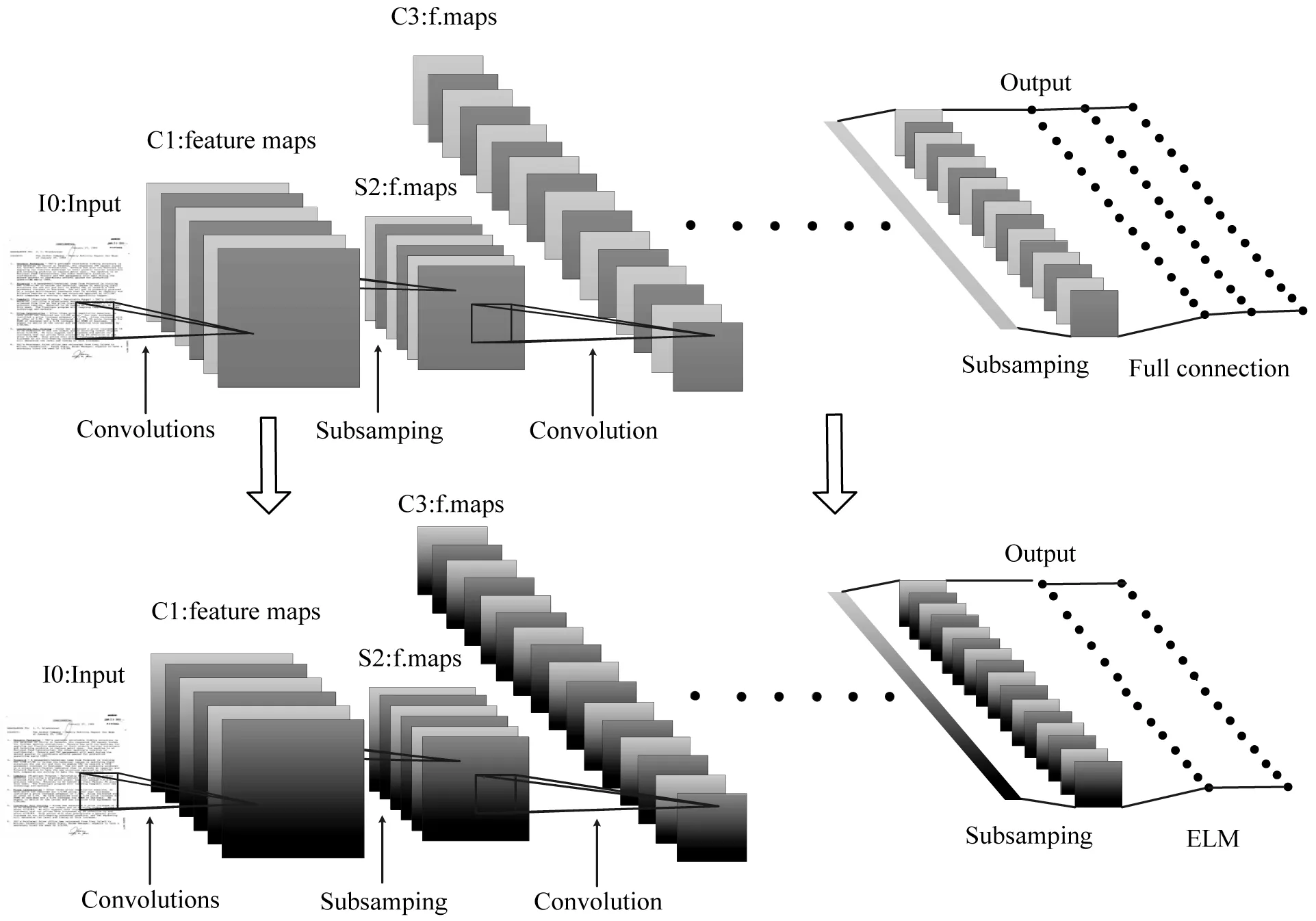
图4 CNN与ELM结合网络图
在一个大型数据集上训练一个完整的AlexNet,为ELM提供一个有效的特征提取器,然后在目标数据集上对ELM进行训练。具体来说,在数据集上训练AlexNet网络,其中数据中包含16个类。因此,AlexNet最后一个全连接层中的神经元数目从1 000变为16。除了最后一个网络层之外,所有的网络层都是使用在ImageNet上预先训练过的AlexNet网络模型,并保留此模型的初始化条件。训练使用随机梯度下降,批量大小为25,初始学习速率为0.001,动量为0.9,重量衰减为0.000 5。为了防止过拟合,第六层和第七层配置dropout ratio为0.5。经过40次迭代的训练后,完成了整个训练过程。本文用Caffe框架[24]来训练这个模型。
极限学习机被用来训练和评估包含10个类别的图像Tobacco-3482数据集[11]。这些图像通过CNN训练后并将第五个池化层的激活值传递给ELM(全连接层)。
2 实验和结果
2.1 实 验
在本文中,使用了两个数据集。首先,我们使用Ryerson视觉实验室复杂文档信息处理(RVL-CDIP)数据集[3]来训练一个完整的AlexNet。此数据集包含400 000幅图像,其中分布着16个类,320 000幅用于训练,40 000幅用于验证和测试。
其次,我们使用Tobacco-3482数据集[11]对提出的ELM进行训练,并对其性能进行评价。训练结果如表1所示。此数据集包含来自10个文档类的3 482幅图像。由于两个数据集之间存在一些重叠,因此我们将包含在大数据集中的两个数据集排除。AlexNet并不是对32万幅图像进行训练,而是只对319 784幅图像进行训练。
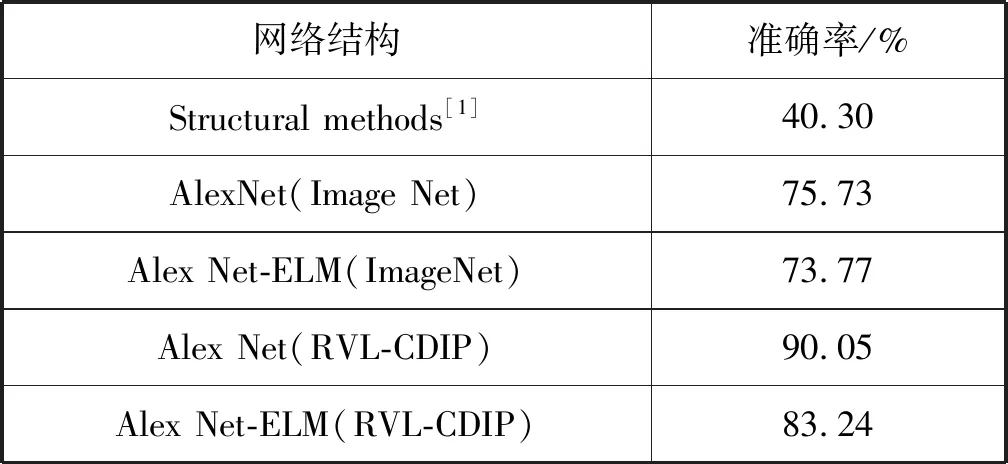
表1 在数据集Tobacco-3482上采用不同预训练方法 得到的准确率比较
为了与Tobacco-3482数据集上的其他方法进行公正的比较,我们使用了与Kang[2]和Harley[3]类似的评估标准。具体来说,我们只使用Tobacco-3482数据集的子集进行训练,从每类10幅图像到每类100幅图像不等,剩下的图像用于测试。由于数据集非常小,因此对于每个数据集分为10个不同的数据集来训练和评估分类器,并得到评估的性能。训练时间对比如表2所示。

表2 图像分类所需的时间对比
由于本实验需要最初的网络结构AlexNet,因而需要对AlexNet进行训练,通过运用ImageNet预先训练好完整的网络结构,与Afzal等[1]使用Tobacco-3482数据集训练网络一样。前面我们训练了多个版本的网络,每个训练数据的大小划分为10个不同的区间,即每类图像分别为10,20,…,100,共训练了100个网络。这些实验的训练数据集进一步细分为用于实际训练的数据集(80%)和用于验证的数据集(20%)。
我们对319 784幅RVL-CDIP语料库的图像进行了初始化AlexNet的训练,并丢弃了网络中全连接的部分。保留的网络结构被用作特征提取器来训练和测试极限学习机。极限学习机在Tobacco-3482数据集上训练。由于这些网络初始权值都是随机初始化,我们为100个分区中的每一类训练10个ELM,并得到每个分区的平均精度。训练对比如图5所示。
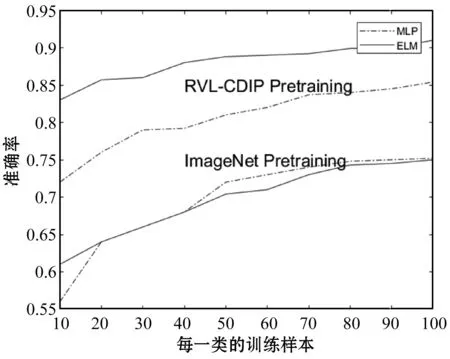
图5 不同ELM分类器与原始网络的平均精度对比图
2.2 结 果
本文提出的分类器性能与图5中描述的Artis状态相比较,带有文档预训练的ELM分类器的性能已经优于当前最先进的技术水平。每类100个训练样本,测试准确率由75.73%提高到83.24%,相比较减少30%以上的误差。随着识别性能的提高,训练和测试所需的运行时间也减少了。特别是在GPU加速训练的情况下,本文方法比当前先进水平快500多倍。对于训练和测试,CNN与ELM相结合的方法每幅图像识别只需要约1 ms,从而实现了实时性。超过90%运行耗时用于特征提取,使用不同的CNN架构可以进一步加快速度。采用ImageNet预训练的ELM分类器达到了与目前最先进水平相当的精度,其计算成本仅为计算量的一小部分。
图6显示了对每类100幅图像进行训练的示例性ELM分类器的混淆矩阵。可以看出,科学这一类文本是迄今为止最难辨认的。这个结果是与Afzal等[1]的实验结果一致,同时也可以解释科学类与报告类之间的低类间差异。

图6 ELM的混淆矩阵
3 结 语
本文主要解决了文档分类和实时训练的问题,提出了针对文档分类的实时训练方法。本文方法主要分为两个步骤:首先选用深度神经网络完成对特征的有效提取;然后运用极限学习机对数据的高效训练。使用极限学习机后,数据的训练效率和训练的时间明显提升。通过在众多评定标准和对比实验下证明了本文方法的有效性和鲁棒性。对于文档分类识别领域是一次重大的突破。
下一步研究方向是如何快速提取图像特征,因为在本文方法中,超过90%的时间用于从深层神经网络中提取特征。另一个的研究方向是在一个高性能集群中对googlenet和Resnet-50与ELM结合的分类器进行进一步性能测试。
