关联规则在电厂优化运行中的应用分析
2019-03-29丁士发杨凯镟
张 磊, 丁士发, 杨凯镟
(上海发电设备成套设计研究院有限责任公司, 上海 200240)
随着电力行业的自动化程度及信息集成度的日益提高,电厂采集了大量的机组生产运行数据,而且数据量随着时间的推移呈几何量级增长,这些数据具有大容量、多样性和价值高等大数据的明显特征。因此,以大数据为背景的数据挖掘技术逐步进入电力系统及电厂研究人员的视野。很多学者尝试运用数据挖掘技术在研究电厂运行时取得一些成果,但是很少有从纯数据角度进行电厂应用分析,笔者通过数据实验来研究数据挖掘在电厂优化运行中的应用。
电力生产工业所受到的不确定影响因素干扰小,生产过程数据表现出很强的规律性,完全可以利用从流程数据中挖掘出的知识来设计智能化应用系统,使计算机能够自动做出判断或者决策[1]。
有学者进行了电厂应用的相关研究,如基于序列模式的供电煤耗关联保护[2],利用聚类算法解决循环流化床模糊控制规则的获取问题[3]等,借用大数据技术解决了电厂运行中的一些问题。丁士发等[4]利用统计方法,进行超临界锅炉高温受热面屏间热偏差在线优化。
随着信息处理能力的不断进步,电厂分布式控制系统(DCS)中的数据是成几何量级增长的,这些大数据特征意味着可以从中发掘出有价值的信息[5]。同类型的机组烧同类型的煤,设置同样的状态,其运行效果是存在差异的。从这些运行数据中,通过大数据挖掘方法,找出运行参数潜藏的关联关系,由这些潜藏关系找出机组的共性和异性信息进行判别。
笔者通过对电厂运行数据的挖掘,根据参数分布情况进行预处理,寻找电厂运行优化目标参数与其他参数的关联关系,从数据角度找到较好的运行工况。
1 数据挖掘方法
1.1 挖掘方法的选择
数据挖掘常用的方法有回归、分类、相关性、聚类、判别、主成分、因子、时间序列等分析方法,其中大部分方法不是专为解决某个特定问题而特制的方法,方法之间不相互排斥[6]。为了研究优化目标与哪些参数存在关联关系,需要对数据进行相关性分析,采用关联规则挖掘算法。
1.2 关联规则
关联规则反映一个事物与其他事物之间的相互依存和关联关系。关联分析就是从给定的数据集D中发现频繁出现、描述数据之间相互联系的知识,被发现的知识成为关联规则[7]。通常的关联规则具有:X→Y(规则支持度S,规则置信度C)的形式,其解释为“数据库中满足X条件的记录一定也满足Y条件”。规则支持度和规则置信度分别描述了关联规则的有用性和确定性,即数据集D中有S比例的数据项包含X∩Y,有C比例的数据项满足X∩Y,表达式为:
(1)
(2)
式中:T(X∩Y)为X和Y同时发生的事物数;T为总事物数;T(X)为X发生的事物数;SX→Y为X→Y的规则支持度;CX→Y为X→Y的规则置信度。给定最小支持度和置信度(SX→Y≥Smin)∩(CX→Y≥Cmin),大于最小支持度和置信度的规则才是有效规则。规则提升是用规则的置信度除以规则后项的支持度所得的比值,表达式为:
(3)
式中:SY为X→Y的规则后项支持度;LX→Y为X→Y的规则提升。通过比较规则提升可以判别前项对后项的影响价值。部署能力P是一个比值,即支持规则前项但不支持规则后项的事物,占全部事物的比例,这个比值也从反面反映出前项与后项的关联度。综合规则支持度、规则置信度、规则提升和部署能力,可以判断出后项与前项的关联程度,从而帮助数据中关联规则的发现和判断[8]。
1.3 Apriori算法
Apriori算法是最经典的关联规则算法之一,是挖掘关联规则的频繁项集算法,其主要过程分为两个阶段:第一阶段,通过迭代检索出事物数据库中的所有频繁项集,即规则支持度不小于用户设定阈值的项集;第二阶段,利用频繁项集构造出满足用户最小置信度的规则[8]。
针对电厂多维连续的数据特点,需要进行多维量化关联规则挖掘,对连续型属性进行区间划分。在进行量化关联规则挖掘时,当全部属性取值都有限时,只需将每个属性映射为布尔型数据即可;当属性的取值范围很宽时,需要将连续属性划分成若干个区段,每个区段映射为布尔型数据。Apriori算法是进行布尔型关联规则挖掘的算法,对数值型无法进行直接的运算,如何对参数进行分组变得尤为重要。笔者在数据进行预处理时进行了聚类分析,分析数据的分布状况,根据分布情况决定数据的分位数和固定宽度离散形式,使数据分组更加合理。
1.4 关联规则挖掘流程
整体思路如下:
(1) 从电厂壁温管理系统中采集出近期数据。
(2) 对运行数据进行采样、梳理和预处理,形成利于挖掘的有效数据。
(3) 应用Apriori算法进行数据分析。
(4) 提取关联度较高的属性与传统实验进行对比。
2 关联规则的应用
某电厂超临界机组为上海锅炉厂有限公司引进Alstom技术,型号为SG-1913/25.4-M950。过热器出口压力为25.4 MPa,过热器出口温度为571 ℃,进口汽温为508 ℃。锅炉为超临界参数变压运行螺旋管圈直流炉,单炉膛、一次中间再热、采用四角切圆燃烧方式、平衡通风、固态排渣、露天布置、全钢悬吊结构的П形燃煤锅炉[4]。数据由安全仪表系统(简称SIS)采取,利用数据库管理系统进行数据整合,最后再通过SPSS (Statistical Product and Service Solutions) Modeler软件进行处理。
笔者对电厂历史运行数据的挖掘,在优化锅炉运行参数的同时,通过控制锅炉高温受热面热偏差,降低管壁温度峰值,控制管壁超温幅度和超温时间,进而减缓氧化皮生产速度和蒸汽腐蚀,以免超温爆管[4]。
2.1 挖掘目标
优化高温受热面屏间热偏差的主要目标是根据当前负荷、运行磨煤机组合寻找最优工况。优化标准是末级过热器热偏差曲线整体平坦,并向均值1靠近,方差较小,无异常跳点。末级过热器屏间热偏差系数评价函数为:
k(Ti,max1≤i≤n-Ti,min1≤i≤n),
k=1,2,…,m
(4)
式中:Ti为末级过热器第i片屏的热偏差系数;k为比例系数;n为屏数;RTMG为末级过热器屏间热偏差曲线评价值,该值越小,代表末级过热器偏差曲线越优,管屏安全性越高[4]。
寻找与RTMG有强关联规则的运行方式,将可能与之有影响的参数进行关联,寻找强关联规则是挖掘的目标。参与关联的参数有:各层风门的挡板开度、燃烧器摆角、水煤比等。
壁温监测系统是从SIS里面每隔30 s采集的数据。为了与热偏差燃烧优化试验调整相验证,取近一年同月份的运行数据作为研究对象。
从壁温监测系统中导出从开始工作至今的数据,对有用的数据进行整合。送入挖掘节点的模型见图1。
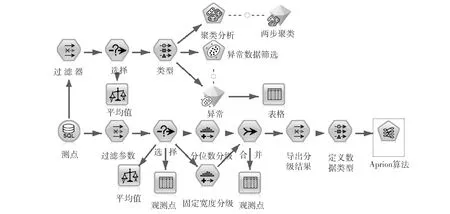
图1 关联挖掘数据流图
2.2 挖掘过程
笔者主要研究满负荷工况下,热偏差和风门等参数的关联关系。首先筛选排除不正常的数据,然后进行聚类分析,观察各项参数的分布状况,将参数进行离散化,最后将处理好的数据进行Apriori算法分析得出规则。参与挖掘的参数有:各层风门挡板开度(各风门代号由下而上分别为AA风门、A风门、AⅡ风门、AB风门、B风门、BⅡ风门、BC风门、C风门、CⅡ风门、CD风门、D风门、DⅡ风门、DE风门、EⅡ风门、EF风门、FⅠ风门、FⅡ风门、CCOFA1风门、CCOFA2风门、SOFAⅠ风门、SOFAⅡ风门、SOFAⅢ风门、SOFAⅣ风门、SOFAⅤ风门),SOFA摆角,燃烧器摆角[4],给水流量,水煤比等。
每个风门参数分为4个角,分别为1、2、3、4号角,总输入参数112个,而风门4个角之间的差别引入函数为:
(5)

通过聚类找到异常数据(见图2),BZT2715为EF层的风门差异函数,由于BZT271503即EF层3号风门采集到的参数出现问题,导致差异过大,需要进行排除。各个风门4角的差异函数均聚类小于1的值附近,意味着4个角的开度相差不大,故用1号角代替4个角,简化输入参数,便于挖掘。
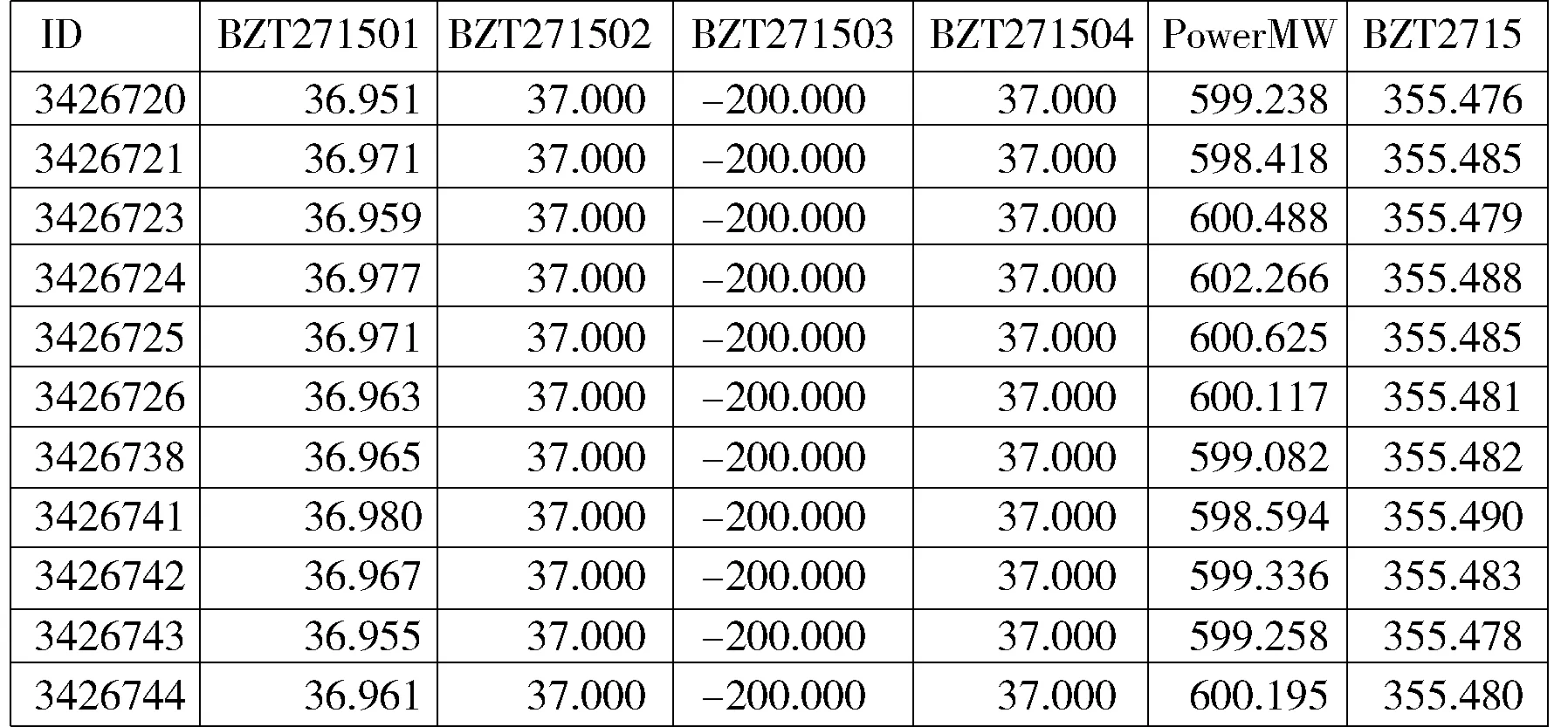
图2 部分异常参数
由聚类结果看出各个参数的分布状况不统一,为了更好地找出参数之间的关联关系,在进行离散化时采用不同的分组办法,见图3。图3中,横坐标为参数的值,纵坐标为参数值出现的频率(单位为1),TPWhole即RTMG的分布区间广且比较集中,在进行离散化时采用分位数分组,AZT271201即CCOFA2开度1号的分布区间固定且比较分散,离散化时采用固定宽度分组。
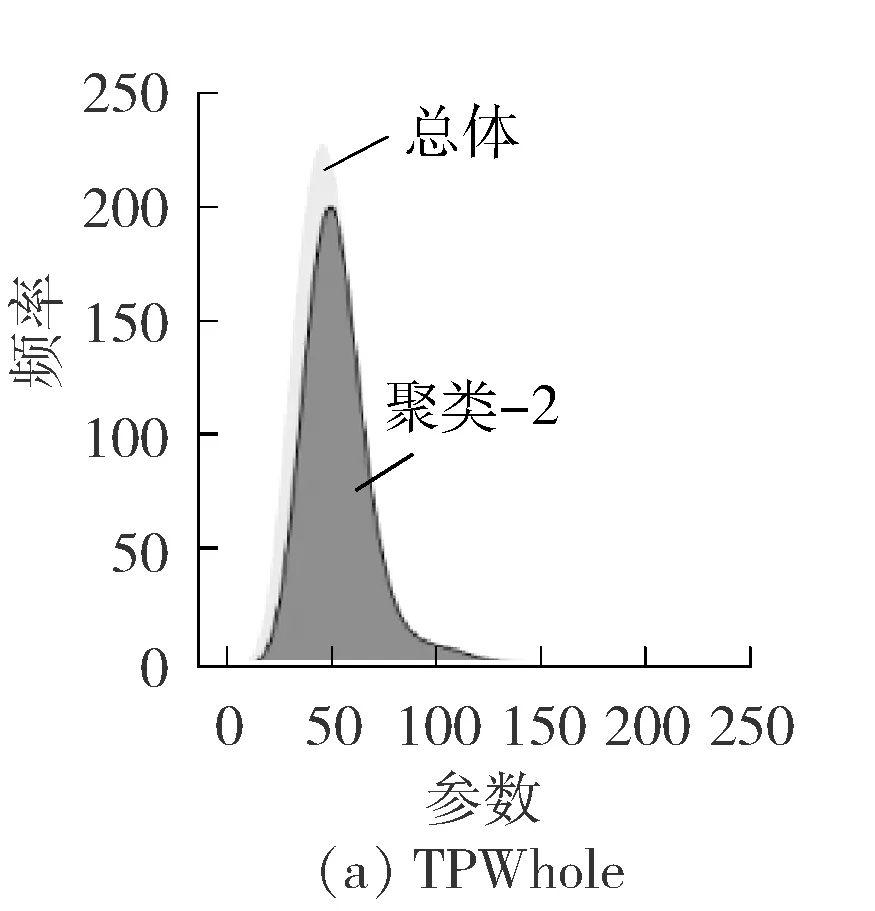
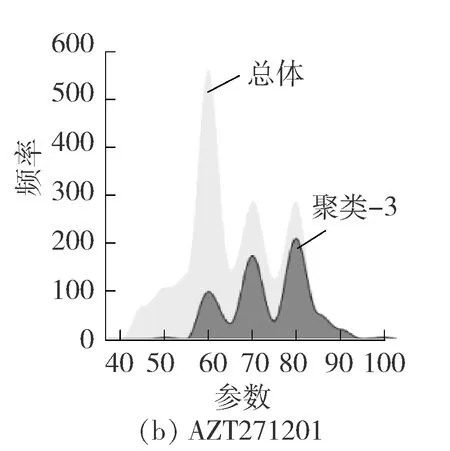
图3 部分参数聚类情况
经过处理之后,原数据与转换数据见图4,转换过的参数通过添加后缀(TILE5、BIN)与原参数区分,如TPWhole分位数分组离散用TPWhole_TILE5来代替,AZT272301固定宽度离散后用AZT272301_BIN来代替。

图4 部分转换数据
通过调整置信度和支持度试验,当置信度为75%、支持度为8%的规则条件时,能较好地得到关联规则。由200多万个数据关联分析得到规则中最频繁出现的项目参数信息见表1。
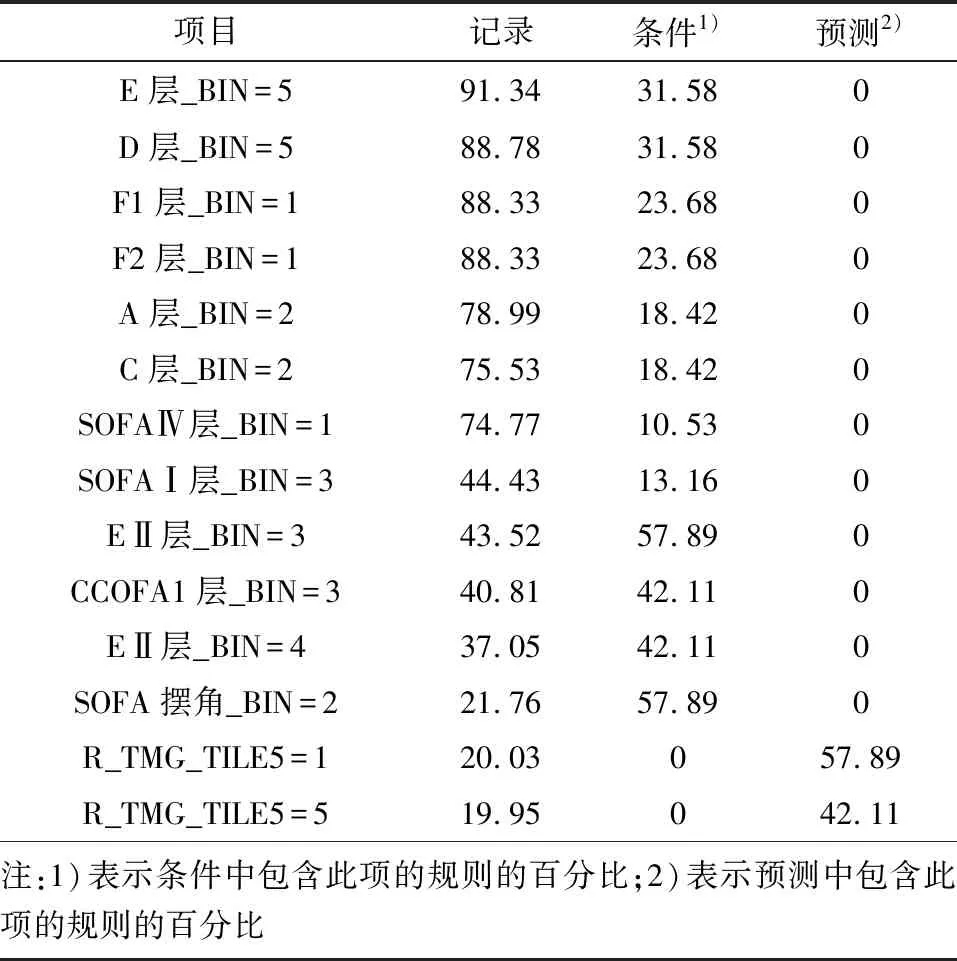
表1 最频繁出现的参数项信息 %
由表1可以看出:预测属性中EⅡ层、SOFA层、CCOFA层有很大的可能是强关联属性,被预测的受热面热偏差系数在偏小值和偏大值时是频繁项。
根据表2中的关联规则信息可进一步有效确定预测参数(各风门开度等)与被预测参数(受热面热偏差系数)之间的关系。由频繁项得到的关联规则有38条,由于规则较多,表2中只显示部分规则。
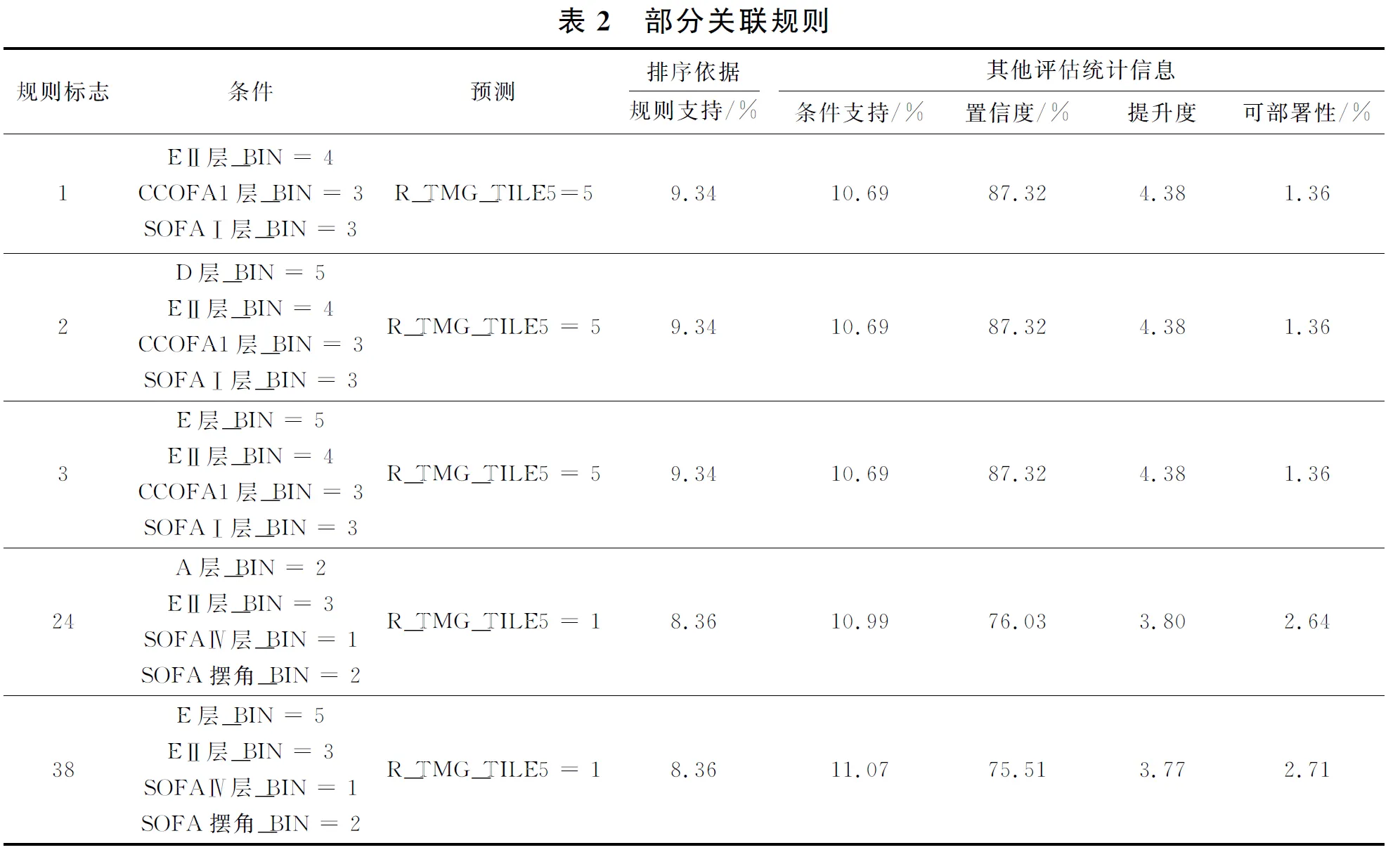
由表2可以看出:当EⅡ层风门开度为41.95%~55.98%、CCOFA1层风门开度为54.50%~66.50%、SOFAⅠ层风门开度为19.87%~29.91%时,偏差函数预测为60~92,发生的概率为9.34%,这个置信度为87.32%,当“规则标志1”条件发生时预测系数在59.92~91.44的概率提高了4.93倍,条件发生预测结果不发生的事件占全部事物的1.36%。当A层风门开度为52.80%~55.90%、EⅡ层风门开度为27.92%~41.95%、SOFAⅣ层开度为0.06%~12.16%、SOFA摆角为45.51°~51.35°时,偏差函数预测为27.81~44.65,发生的概率为10.99%,该置信度为76.03%,当“规则标志24”条件发生时,预测事件的发生概率提高了3.8倍。
通过使用规则约束参数,热偏差函数均值由48.91降到40.56,降低了17%。
2.3 结果分析
挖掘出的关联规则显示热偏差系数与SOFA层、CCOFA层有较强的关联关系。当燃烧器摆角在45°~51°时,热偏差系数会变低,热偏差趋于1。在该锅炉热偏差调整燃烧实验报告中,根据变二次风风门开度试验,其他参数固定,CCOFA风开度为60%时,SOFA风开度均为20%时的热偏差函数比SOFA风门开度为40%和60%时高;当CCOFA风固定不变,SOFA风开下三层的热偏差函数比开上三层的热偏差函数高。数据挖掘的结果在一定程度上能印证实验结果。
3 结语
笔者以某电厂壁温监测系统为基础,通过对历史数据的处理,结合大数据挖掘关联规则算法——Apriori算法,利用电厂大数据的特性,找出与热偏差系数关联的参数项,分析出与之强关联的参数项,并与实际印证,通过挖掘的规则对预测参数进行约束,有效降低了受热面热偏差系数,进而能有效降低管壁温度峰值,控制管壁超温幅度和超温时间,减缓氧化皮生产速度和蒸汽腐蚀,避免超温爆管,进一步肯定了电厂数据的隐藏价值。在对数据进行预处理时,通过对数据自身的特征进行相应的预处理,为数据的挖掘提供了便利。通过对电厂数据的挖掘,寻找到符合要求的强关联规则,得出目标属性有关的参数项,指导运行,提高电厂的经济性和安全性。
