我国区域工业经济与环境污染的实证分析
2019-03-14秦炳涛葛力铭
秦炳涛,葛力铭
(1.上海理工大学 管理学院,上海 200093;2.复旦大学 区域与城市发展研究中心,上海 200433)
0 引言
我国自改革开放以来,工业经济经历了粗放式高速增长的过程,工业企业数量也在不断扩大,成为我国经济发展的重要支撑。但在我国工业经济发展的同时也产生了大量的工业污染物,几乎占据了总污染负荷的70%,这严重阻碍了我国工业经济的可持续发展。因此研究我国区域工业经济与环境污染的关系具有重要意义。
关于经济发展和环境污染的关系,起初Grossman和Krueger(1995)[1]吸收了库兹尼茨的倒“U”型理论的观点,得出经济发展与环境污染之间呈现倒“U”型,称为环境库兹尼茨曲线。Panayotou(1997)[2]研究结果表明二氧化硫、氮氧化物和固体悬浮物与人均GDP呈现倒“U”型关系。施锦芳和吴学艳(2017)[3]认为经济发展和环境污染之间呈一种“N”型关系,即环境污染与经济发展的关系并不是只有一个拐点,而是存在两个拐点,呈现出了三次关系。马树才和李国柱(2006)[4]研究发现经济增长不能自发降低环境污染,需要政策干预。吕健(2010)[5]基于VAR模型研究了上海经济发展与环境污染之间的关系。孙伟增等[6]利用EKC验证了能源与环境在某些方面的激励作用。樊良树(2015)[7]研究了环境维权“中国式困境”的解决路径。张金锁等(2009)[8]探究了工业经济发展与环境污染之间的环境库兹涅茨曲线分析思路。李小胜等(2013)[9]研究得出仅工业废水排放与人均收入之间满足环境库兹涅兹假说。谭秀杰等(2016)[10]通过研究碳交易机制对我国经济环境的影响,进一步分析了工业经济发展与环境污染的问题所在。本文运用主成分分析法和聚类分析法,将2015年全国31个省份根据工业经济发展和环境污染状况划为4个区位,通过散点图呈现不同区位的特征,并结合我国现实情况提出科学合理的政策建议,从而促进我国工业经济与环境的可持续发展。
1 研究设计
1.1 研究方法
首先,当选取的指标较多时,为更好地反映工业经济发展与环境污染的关系,这时应采用降维的方法,将多个指标转化为可用主成分代替的较少指标,因此采用主成分分析法。其次,通过工业经济发展和工业环境污染的主成分分析,根据二者综合得分情况对我国31个省份进行排名,按照综合得分情况进行分类,能够更好地分析各省份的发展情况以及有针对性地提出建议,因此采用聚类分析法。
1.1.1 主成分分析法
主成分分析也称作主分量分析,是Hotelling在1933年首先提出的,主成分分析利用降维的思想,以损失较少信息量为前提,将多个指标转化为较少的综合指标,通过转化生成的综合指标称为主成分,原始变量的线性组合均由求得的主成分构成,各主成分间为不相关关系。Stata对主成分的分析主要是主成分估计,然后通过KMO检验和SMC检验分析其合理性,通过碎石图显著反映其主成分,直观看出其各个特征值的大小,通过得分图分析其宏观现象,通过载荷图直观得出各个变量对主成分影响的大小。设原始变量为x1,x2,…,xn,主成分分析后得到新变量为y1,y2,…,ym,它们是x1,x2,…,xn的线性组合(m<n)。
步骤2:计算相关系数矩阵R=(rij)n×n。

步骤3:计算特征值与特征向量。
由|R-λI|=0计算求得每一个特征值λi,从而计算求得每一个特征向量u1,u2,...,un。
1.1.2 聚类分析法
聚类分析法是理想的多变量统计技术,其中包括两个体系,分别是系统聚类和非系统聚类。系统聚类法包含有中间距离法、最长距离法和最短距离法,非系统聚类法包含有K均值聚类法和K中位数聚类法。聚类分析也称群分析、点群分析。本文研究的是工业经济发展与环境污染,采用K均值聚类法,在用Stata进行K均值聚类法之前,应该进行聚类停止法,即通过F值与T-squared值来判断最优的分类数。
1.2 指标选取与数据来源
科学合理的指标体系能够全面综合地反映我国工业经济发展与环境污染的关系。为了更好地反映各地区的工业经济发展状况,本文从工业经济总量、工业经济效益、工业经济结构三个角度出发,选取了8个工业经济指标。为了更好地反映各地区的环境污染状况,本文从工业废气和有害气体、工业废水、工业固体废物三个方面综合分析,选取了6个工业污染指标。现将此指标体系按照层级递进的关系,将其分为目标层、准则层和指标层,如表1所示。
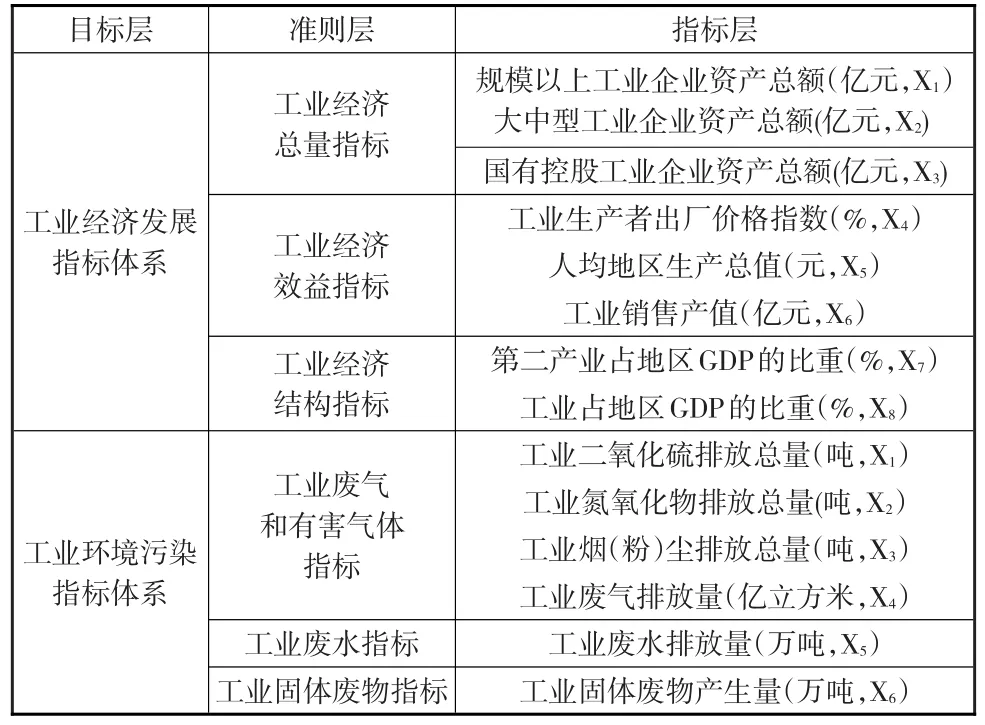
表1 工业经济发展与环境污染的指标选取
本文是以我国31个省市作为研究对象,相关数据来源于《中国统计年鉴》(2016)、《中国环境统计年鉴》(2016)、《中国工业经济》(2016)、《中国工业统计年鉴》(2016)、各省市《统计年鉴》(2016)、CNKI数据库。具体数据统计工具为Stata14.0,分析方法为主成分分析法和聚类分析法。
2 实证分析
2.1 工业经济发展与环境污染的主成分分析及检验
2.1.1 工业经济发展的主成分分析
本文通过计算工业经济发展原始数据的相关矩阵,得到如表2所示的主成分分析结果。
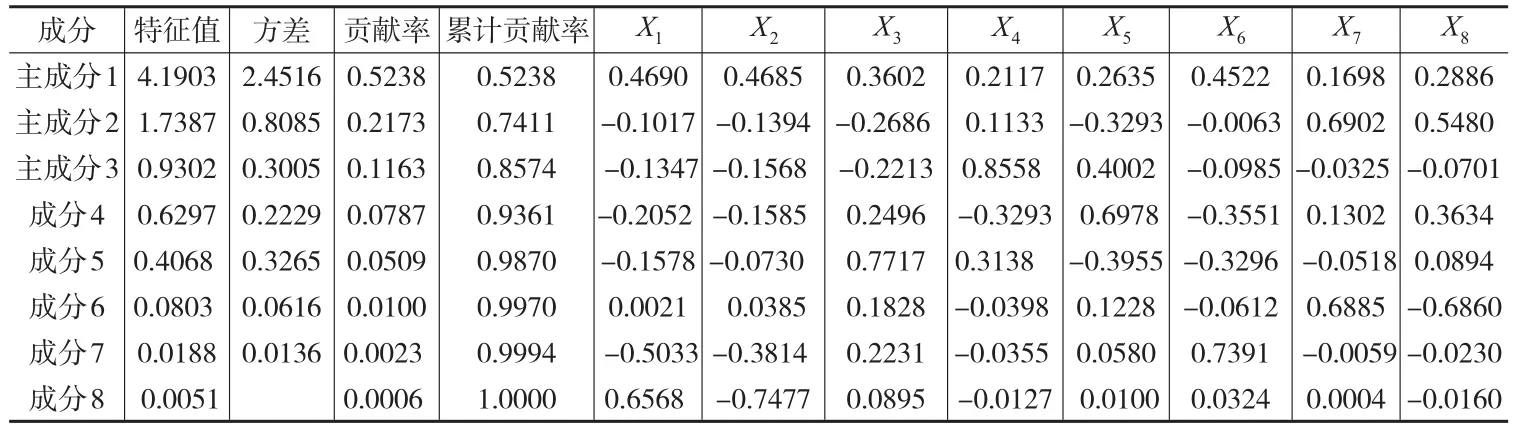
表2 工业经济发展的主成分分析结果
由表2可以看出,第一个特征值为4.1903,第二个特征值为1.7387,第三个特征值为0.9302,前三个主成分的累计贡献率达到85.74%,可以很好地反映原始数据的大量信息。从三个主成分的特征向量来看,主成分1在X1(规模以上工业企业资产总额)、X2(大中型工业企业资产总额)前的系数较大,可以认为主成分1是反映各地区工业经济总量的经济指标。主成分2在X7(第二产业占地区GDP的比重)、X8(工业占地区GDP的比重)前的系数较大,而且主成分2与其他的特征向量几乎都呈现负相关的趋势,这时可以认为主成分2可以较为准确地反映工业经济结构对工业经济发展的影响。主成分3在X4(工业生产者出厂价格指数)和X5(人均地区生产总值)前的系数较大,呈现正相关关系,而且主成分3与其他特征向量全部呈现负相关关系,可以认为主成分3可以准确地反映工业经济效益,它是反映工业经济效益对各地区工业经济影响的经济指标。
2.1.2 工业经济发展主成分分析的KMO检验及SMC检验
首先为了使得分析可靠,测度变量之间相互关系,在这里做KMO检验和SMC检验,KMO是测度变量之间相互关系的指标,KMO介于0~1之间,一般来说KMO值越高,表明变量之间的共性越强,一般KMO检验值小于0.5为不可用,大于0.5为可用,大于0.6达到接受层面,这时说明主成分分析合适。SMC为一个变量与其他变量的复相关系数的平方,也就是复回归方程的可决系数,SMC值越高表明变量之间的关系性越强,主成分分析越合适。通过KMO检验,overall值为0.6848,达到接受层面,同时根据SMC结果判定变量之间的相互关系较强,说明主成分分析能起到很好的数据约束化效果。KMO及SMC检验结果如下页表3所示。
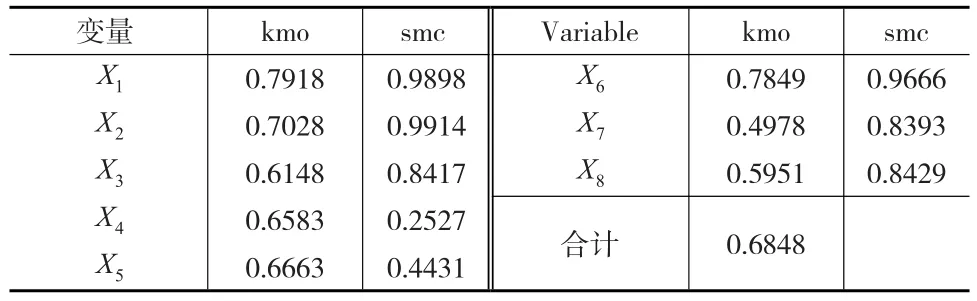
表3 KMO及SMC检验
将各个主成分的贡献率作为加权平均的系数,可以得到工业经济发展程度的综合得分(记为U1),用C1表示主成分1,C2表示主成分2,C3表示主成分3。
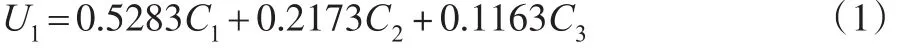
2.1.3 工业环境污染的主成分分析
本文通过计算工业环境污染原始数据的相关矩阵,得到如表4所示的主成分分析结果。

表4 工业环境污染的主成分分析结果
根据表4可以得出,第一个特征值为4.7195,第二个特征值为0.8358,前两个主成分的累计贡献率达到92.59%,可以较为准确地反映原始数据的信息。根据两个主成分的特征向量,主成分1与工业环境污染指标均为正相关,可以反映各个地区的综合状况,进一步,主成分1在X1(工业二氧化硫排放总量)、X2(工业氮氧化物排放总量)、X3(工业烟(粉)尘排放总量)、X4(工业废气排放量)前的系数较大,表明K1是反映工业废气和有害气体对环境污染影响的重要指标;主成分2在X5(工业废水排放量)、X6(工业固体废物产生量)前的系数较大,并且与X5呈现出正相关,与X6呈现出负相关,说明主成分2是反映工业废水和工业固体废物对环境污染影响的重要指标。
2.1.4 工业环境污染主成分分析的KMO检验及SMC检验
同样,为了使得分析可靠,测度变量之间相互关系,在这里用Stata做KMO检验和SMC检验。根据上述对KMO检验和SMC检验的相关内容的叙述,通过KMO检验,overall值为0.7999,检验表明变量之间的相互关系较强,说明主成分分析能起到很好的数据约束化效果。通过SMC检验,可以得出变量之间线性关系强,表明主成分分析合适。KMO及SMC检验结果如表5所示。

表5 工业环境污染的KMO检验和SMC检验
将各个主成分的贡献率作为加权平均的系数,可以得到工业经济发展程度的综合得分(记为U2),用K1表示主成分1,K2表示主成分2。

2.2 工业经济发展与环境污染的综合得分结果及聚类分析
2.2.1 工业经济发展与环境污染的综合得分结果
根据工业经济发展的综合得分U1与工业环境污染的综合得分U2,通过计算得出31个省在工业经济发展及环境污染中的排名情况,结果如表6所示。

表6 工业经济发展与环境污染的综合得分及排名情况
2.2.2 工业经济发展与工业经济污染的聚类分析
根据以上得出的各个地区的工业经济发展状况U1与工业环境污染程度U2的综合得分表。采用Stata14.0中的聚类分析法,利用K均值聚类法,对各个地区的两项综合指标进行聚类。
首先,在聚类的过程中,需要用Stata中聚类停止法的F值与T-squared值来判断最优的分类数,F值越大,其分类效果越好;而T-squared值越小,其分类效果越好。得到的情况如表7所示。
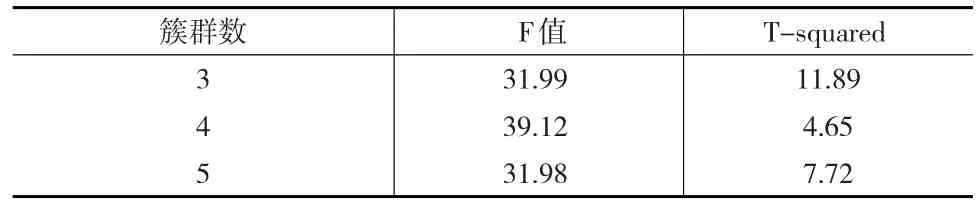
表7 聚类分析的F值与T-squared值
由分四类的F值最大,而T-squared值最小,可以得知分为四类为较优选择。
第一类:北京、上海、陕西、安徽、浙江、天津、湖北、湖南、重庆、四川、江西、福建、吉林
第二类:新疆、西藏、黑龙江、海南、宁夏、青海、贵州、云南、甘肃、广西
第三类:河北、河南、山西、辽宁、内蒙古
第四类:山东、江苏、广东
根据聚类分析的结果可以看出,第一类中有13个地区属于工业发展状况较好且环境污染程度较轻的,这与第四类的3个地区形成鲜明的对比,山东、广东和江苏素来是我国的工业大省,工业产值占据国家较大比例,但是所带来的工业污染也是相当严重,由此可以说明,工业发达的地区,大都有着严重的工业污染问题,经济的增长是以牺牲环境作为代价的。一方面是由于工业大省过多地重视经济指标,而忽视了环保问题以及资源节约问题,这使得中小企业过度开采和浪费资源,从而造成了大量的环境污染;另一方面,各地区的政策有待完善,所有的工业发展都应该建立在不破坏环境的基础上来完成,如果造成大量工业污染,势必对我国未来发展带来不利局面。第二类主要是我国西部地区,它们的工业环境污染较轻但同时工业经济发展状况较差,主要原因还是我国西部地区长期以来的地理因素问题,由于远离东部发达地区,使得运输成本增加,从而使得工业基地很少在西部地区建立,如此循环过程导致西部地区的工业发展一直处于劣势。第三类主要是一些工业经济发展状况相对较好,但环境污染程度很重的地区。典型的像河北、山西和辽宁,其中河北和辽宁的重工业比较发达,而由此造成的工业环境污染也非常严重,山西主要是煤矿业,这三个地区是全国污染最严重的地区,因此当下各省应该充分重视环境保护,积极研发绿色排污技术,加强地区环境规制水平。
3 结论与对策建议
本文通过选取代表工业经济发展的8个指标和代表工业经济污染的6个指标,利用主成分分析法和聚类分析法,综合分析我国31个省份的工业经济发展和环境污染状况,并将其划分为4类地区,分别为强可持续发展地区、弱可持续发展地区、弱不可持续发展地区和强不可持续发展地区,针对每类地区提出相关的政策建议。
第一类地区是我们提倡的工业发展模式,工业发展过程中,要避免“先污染后治理”的模式。像北京、天津和上海,虽然工业规模相对山东和广东等工业大省较小,但是第二产业人均GDP高,产业结构良好,在工业经济得到有力发展的同时重视了环境治理,这是很多工业污染程度较深的地区需要反思的地方。安徽、湖南、湖北、陕西和福建等地工业污染程度相对重一些,尤其是对于安徽,即将跨入第三类地区,这些地区需要在保持现有工业发展模式下,改善环境保护政策,通过优化产业结构和产业政策,在保证良好工业环境的基础上提升工业经济增长。
第二类地区主要是我国西部地区,这些地区的工业污染程度较低,现阶段主要目标应该放在如何大力提高工业经济的问题上。西部地区战略地位非常重要,但是在国内国际分工中长期处于不利地位,各地区应利用自己的特色产业,促进产业优化升级。例如新疆的金属,钢铁相对比较集中在乌鲁木齐,可以乌鲁木齐为中心建立多个工业园区,联动发展工业。西藏地区近年来建立了机械、纺织和皮革等小型工业企业,其中西藏毛纺织工业发展很快,主要产品呢绒、毛绒和毛毯远销其他省份和国外,极大地带动了西藏地区的工业经济发展。西部这些中国工业较为落后的地区,应该逐渐建立地区的优势工业园,利用自己现有的资源,提高工业经济发展水平。
第三类地区和第四类地区大都是我国工业大省,有以辽宁、河北为主的大型重工业基地,也有以广东为主的大型轻工业基地,工业废水废气和固体废物排放十分严重。其中,江苏、山东、广东工业废水排放总量之和为55.43万吨,占据全国工业废水排放总量的27.78%。虽然这三个省份的工业经济位居全国前三,但是地区的发展应该始终以可持续为前提,各地区政府应相应加强环境规制水平,优先发展以质量效益和资源节约为主导的新型工业;各地区政府应该对污染程度较深的企业进行限期治理,同时应该选取符合我国实际情况的技术,合理有效地解决地区工业环境污染现状;各地区大中型工业企业应该使用节能少废的新型设备,大力推广无害化生产技术。
