基于SGA-RBF的协同过滤算法研究
2019-03-14王玉珍许艳茹
王玉珍 ,许艳茹 ,常 丹
(兰州财经大学a.丝绸之路经济研究院;b.信息工程学院,兰州 730020)
0 引言
随着科学技术的发展,大量的信息出现在人们的生活中,歌曲、电影、新闻以及商品等是大多数人关注较多的信息。因此,为了满足用户迫切想获取有用信息这一需求,推荐技术的使用已经成为一种常态。而推荐技术的核心是推荐算法,目前,就应用领域来说,像贝叶斯方法[1]、神经网络方法[2]、聚类方法[3]等基于模型的协同过滤算法[4]的应用最为广泛。近年来,人们对该领域的研究越来越深入,研究成果也越来越多。主要的研究成果如下:王晓耘等[5]提出一种基于粗糙用户聚类的协同过滤推荐模型,采用粗糙K-means算法对用户聚类,形成用户的初始近邻集,然后从目标用户的初始近邻集中搜索其最近邻,根据搜索结果预测项目评分并进行推荐;Baltrunas等[6]将项目依据上下文分裂成两个,然后按照特定的上下文关系来预测用户评分并进行推荐;冷亚军等[7]在对用户聚类的基础上,根据用户偏好建立偏好矩阵,进行预测评分并推荐;张星等[8]为每个用户根据其兴趣爱好的差异性,创建了个性化的项目相似度的计算过程,因该过程与用户的兴趣爱好结合紧密,从而有效提高了推荐的精度;叶兰平等[9]利用RBF神经网络能够有效进行非线性逼近这一特点,利用用户的相似度,进行评分预测;薛福亮[10]将Vague集融入电子商务推荐中,并且使用SOM算法改进RBF神经网络,降低了预测误差;Jia等[11]将偏最小二乘法和遗传算法引入RBF神经网络中,取得了更好的效果。可见,虽然目前对基于模型的协同过滤方法已有一定的研究,但是在推荐领域采用RBF神经网络的研究成果还较少。因此,本文在优化RBF神经网络的基础上,提出了一种SGA-RBF神经网络模型,并将SGA-RBF神经网络与协同过滤算法结合,预测了未评分项目的分数,从而提高了预测的准确性。
1 推荐技术
1.1 协同过滤算法
协同过滤算法作为使用最广泛的推荐算法,其过程如下:
1.1.1 评分信息的预处理
Items代表项目,Users代表用户,Suj表示用户Usersu对项目Itemsj的评分(如表1所示)。

表1 用户-项目评分矩阵R
1.1.2 最近邻居集的建立
该步骤的任务是根据项目之间的相似度建立最近邻集。通常,相似度可采用以下方法计算:
(1)余弦相似度
余弦相似度是根据向量空间中的两个向量夹角的余弦值来度量的,见式(1)所示:
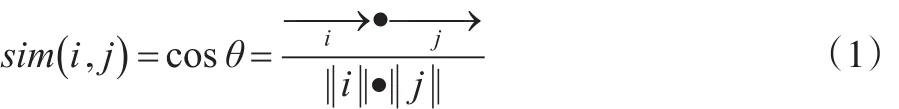
(2)修正的余弦相似度
为了弥补余弦相似度只在方向上区分差异的不足,修正的余弦相似度的计算方法应运而生。见式(2)所示:
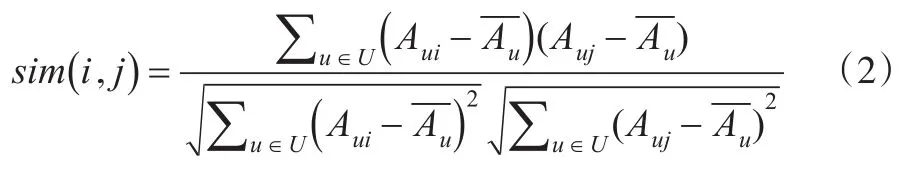
(3)Pearson相关系数
该方法是根据项目之间的相关关系来度量相似度,见式(3)所示:

其中,Aui和Auj分别表示用户对项目i和项目j的评分分别表示所有用户对项目i、项目j评分的均值。
根据相似度的计算结果,将相似度较大的n个项目用来构成最近邻集。
1.1.3 进行预测评分并推荐
由以上两步获取每个项目的最近邻居集,根据最近邻居集中的评分数据预测用户对某个项目的评分。见式(4)所示:
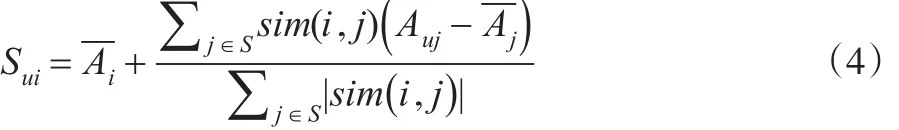
根据评分预测的结果,将分数排名靠前M个项目推荐给目标用户。
1.2 RBF神经网络
径向基函数(Radial Basis Function,RBF)神经网络[12]是20世纪80年代末,由J.Moody和C.Darken提出的,该神经网络是具有单隐层的三层前馈网络,能有效进行非线性逼近,被广泛应用于各领域。
(1)RBF网络结构
RBF网络是一种三层前向网络,其网络结构如图1所示。在图1中,xn代表输入值,hn代表隐藏层的输出值,wn代表隐藏层与输出层的连接权值,Ym代表输出层的输出值。
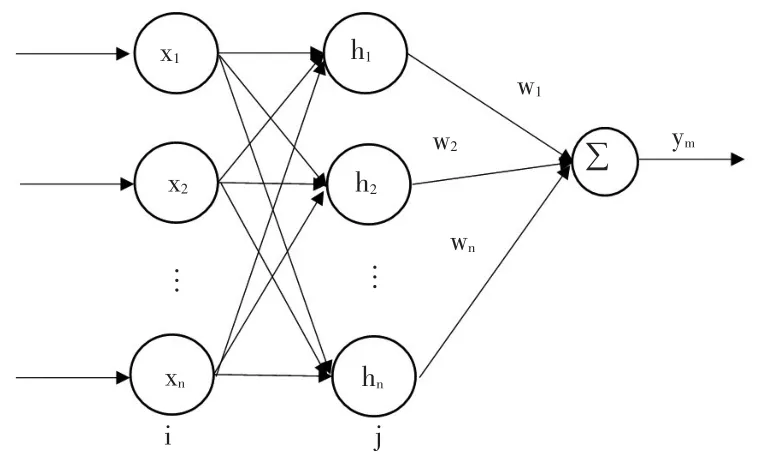
图1 RBF神经网络结构
(2)RBF网络的逼近
采用RBF网络逼近一对象的结构如图2所示。
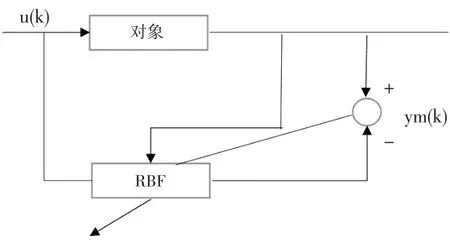
图2 RBF神经网络逼近
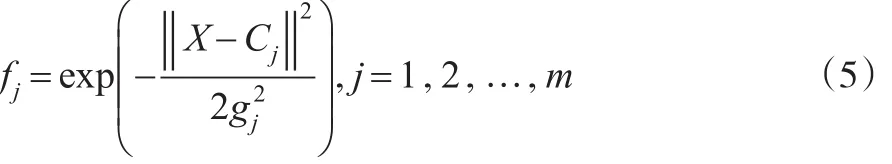

其中,gi为节点j的基宽参数,且为大于零的数。网络的权向量为:

RBF网络的输出为:

RBF网络逼近的性能指标函数为:

根据梯度下降法,输出权、节点基宽参数及节点中心矢量的迭代算法如下:

式(10)至式(14)中,η为学习速率,α为动量因子,η∈[0,1],α∈[0,1]。将对象输出对输入的敏感度称为Jacobian信息,其值由RBF神经网络辨识而得[13]。
辨识算法如下:取RBF网络的第一个输入为z(k),即x1=z(k),即:

本文使用的RBF网络中,网络隐藏层神经元个数为4,网络结构2-4-1。
1.3 遗传算法
遗传算法[14]是模仿生物生存的机理而形成的,Goldberg总结了一种最基本的遗传算法——简单遗传算法(Simple Genetic Algorithms,简称SGA)。SGA包含了编码、初始种群的生成、种群中个体适应度的检测评估、选择、交叉、变异5个基本步骤。
(1)问题编码和适应度
SGA通常作用于确定长度的二进制串上,即I={0 ,1}l。比如,分量可以表示为串长为lx的二进制代码,即译码函数为,式中,为参数xl的二进制表达,本文采用二进制编码。适应度函数Φ(x)通常选为确保适应值为正值,并且最好个体的适应值最大的函数[13]。
(2)选择
选择(Selection)即从群体中按个体的适应度函数值选择出较适应环境的个体。
(3)交叉
SGA中,交叉(Crossover)的目的是把两个不同个体上的有用段组合在一起,从而实现进化。Holland的一点交换算子作用机理如下:设两个父辈个体分别为随机选择交换点d=random(1,2,…,l-1),产生的两个子代个体分别为
(4)变异
在SGA中,通常变异(Mutation)被认为是为确保每一代个体的多样性而设置的辅助算子。Pm的值一般为0.001到0.1之间。个体,其中:

式中,∀i∈(1,…,l);θi为0与1之间的随机数。Pm的取值一般很小,否则SGA退化为简单的随机搜索。
在实际应用中,SGA的串长(1)、群体大小(n)、交叉概率(Pc)、变异概率(Pm)等参数的取值对其性能影响很大。通常情况下,各参数的取值如表2所示。

表2 SGA的各参数取值表
由于这些参数的选择难度大,近年来更多学者已经认识到研究这些参数随遗传进程而自适应变化问题的重要性。
2 基于SGA-RBF的协同过滤算法
RBF神经网络的参数初始值的选择存在随机性,容易给模型造成误差。遗传算法具有全局优化的优点,能够使RBF神经网络的初值权值得到优化,提高RBF神经网络模型的准确率。
2.1SGA优化RBF神经网络
由于RBF神经网络的初始参数很难确定,用简单遗传算法可以优化其网络参数,使逼近更加准确,具体的算法步骤如图3所示。

图3 SGA优化RBF神经网络算法流程
2.2 推荐算法设计
本文用遗传算法优化RBF神经网络的初始权值,提出了SGA-RBF神经网络模型,然后在项目相似度的基础上,将SGA-RBF神经网络与协同过滤算法结合。本文以电影推荐为例来说明该算法,具体的算法步骤如下:
(1)构建“Users-Items”矩阵
本文所构建的“Users-Items”矩阵如表3所示。
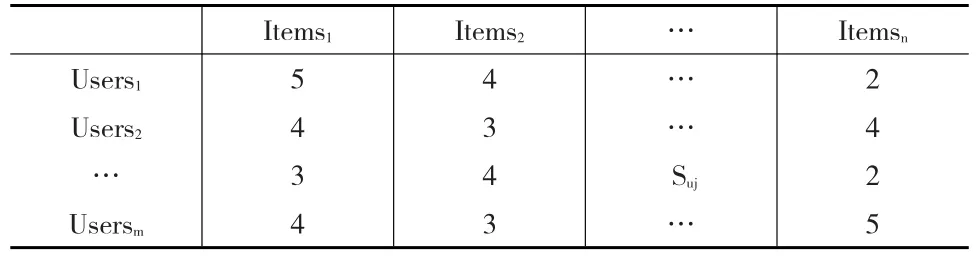
表3 “Users-Items”评分矩阵
矩阵中的行向量代表m个用户,列项代表n部电影,矩阵值代表每个用户对每部电影的具体评分。
(2)建立项目的近邻集
首先采用Pearson相关系数法计算出项目相似度,然后按照每个项目相似度由高到低进行排序,选出其中的前n个构成近邻集。
(3)构建SGA-RBF神经网络模型并预测评分
获得近邻集之后,则可用目标项目i与其近邻集的评分来训练与仿真网络。具体步骤如下[13]:
步骤1:生成集合S1和S2。其中S1是项目i与近邻集中的项目的共同评分用户集合,S2是对近邻项目评分而未对项目i评分的用户的评分数据集合;
步骤2:用遗传算法优化RBF神经网络的初始权值;
步骤3:设置神经网络的训练样本输入为S1中项目j的评分数据,训练样本输出为S1中用户对目标项目i的评分数据;
步骤4:将S2中对j评分的数据输入训练好的网络中,输出值则为S2中的用户对目标项目i的预测评分值;
步骤5:如果j是S1中的最后一个项目,则继续步骤6,否则,返回步骤3;
步骤6:根据计算结果求出目标项目求平均值。
(4)推荐
根据评分预测的结果,从中选出评分较高的M个项目,作为目标项目推荐给用户。
3 模型评价
本文使用公开的数据集movielens来检验算法的有效性。数据集共10000条数据,包括1682部电影和943个用户,按时间排序后,取出每个用户最后的10条数据为测试集,其余数据为训练集,供实验使用。
3.1 评价指标
本文的实验中,用平均绝对误差(MAE)来评估实验结果。其公式如式(17)所示:

其中mi表示预测评分,ki表示用户对项目的实际评分。
3.2 实验结果及分析
本文共进行了两个实验,分别比较了不同近邻数对应的MAE值与不同稀疏度对应的MAE值。
(1)不同近邻数对应的MAE值
用movielens数据集来测试当近邻数N变化时,采用SGA优化前后的基于RBF神经网络的协同过滤算法MAE的变化情况,其结果如图4所示。
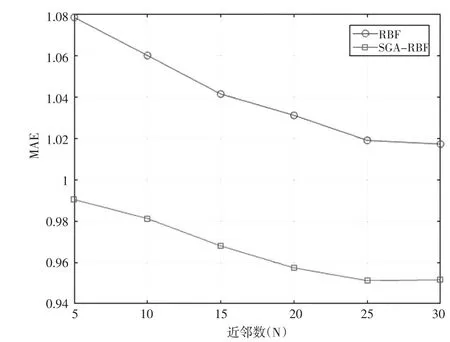
图4 不同近邻数下的MAE变化
图4显示了当近邻数N分别取5、10、15、20、25、30时,基于RBF的协同过滤算法和基于SGA-RBF的协同过滤算法的MAE值的变化。由图可知,改进算法的MAE值明显低于基于RBF的协同过滤算法的MAE值。可见,经过SGA优化的RBF神经网络的性能优于未优化的RBF神经网络。
(2)不同稀疏度对应的MAE值
本文将movielens数据集按稀疏度划分了五类,即0~0.05、0.05~0.1、0.1~0.15、0.15~0.2、0.2以上,比较每个稀疏度区间内改进算法与原RBF协同过滤算法之间的差异。
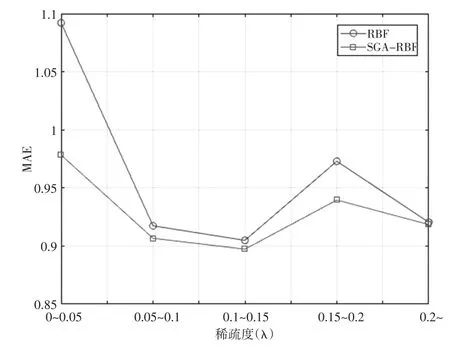
图5 不同稀疏度区间内的MAE变化
由图5可以看出,对于每个稀疏度区间,本文所提出的算法均优于基于RBF的协同过滤算法,而且对于稀疏度越小的区间,优化的效果越明显。
4 结束语
本文首先用遗传算法优化RBF神经网络的初始权值,提出了SGA-RBF神经网络模型,然后在项目相似度的基础上,将SGA-RBF神经网络与协同过滤算法结合,预测了未评分项目的分数,最后将预测评分和实际评分进行比较,并计算了平均相对误差。实验结果显示,用遗传算法改进RBF神经网络的初始权值能有效的提高RBF神经网络的性能,减小平均绝对误差,提高预测准确率。
