母语为韩语的汉语学习者加工“V+N1+的+N2”歧义结构的眼动研究
2019-03-12鹿士义逯芝璇匡柳兴邓彧君
赵 帅 鹿士义 陈 婧 逯芝璇 匡柳兴 邓彧君 付 宸
(1 北京大学对外汉语教育学院,北京 100871) (2 大连外国语大学法语系,大连 116044)
1 引言
第二语言认知加工研究领域的一个中心问题是,在加工L2句子时,L2学习者与母语者在多大程度上使用相似的认知加工机制。对这一问题的回答不仅有助于洞察二语者句子加工的机制,而且有助于从二语语言认知的角度揭示大脑功能的可塑性。Dussias(2003)指出,在L1研究领域,句法分析得到了较多关注,但从L2的角度对句法分析进行考察的研究并不多。Gregg(2001)认为,二语习得理论不仅包含具体的语言知识理论,还包含能够阐释L2学习者语言系统状态发生改变这一认知过程的过渡态理论(transition theory)。
Steinhauer(2014)认为,在二语认知领域,L1加工和L2加工之间存在以下三种关系:差异假设(difference hypothesis)认为L2加工不同于L1加工,大脑可塑性在青春期后发生了改变,晚期学习者(late learner)可能无法达到母语者水平。在关键期之后,L2学习者的语言学习效率会显著下降,使得L2学习者的脑激活机制不同于母语者。与差异假设不同的是,相似假设(similarity hypothesis)认为L2加工与L1加工在很大程度上是一致的(Hernandez, Li, & MacWhinney, 2005)。原则上说,没有理由认为L2加工和L1加工具有系统性的差异。L1和L2使用相同的神经认知系统,并且竞争相同的认知资源的假设能够解释为什么L2学习者具有不同的学习轨迹(learning trajectory)。而会聚假设(convergence hypothesis)则认为,神经认知系统处于一种动态发展变化的状态之中,会随着语言练习次数的增加和语言水平的提高,使得L2加工模式与L1加工模式趋同。该假设认为即使是成人L2学习者,其L2流利度水平以及脑激活模式也能够达到母语者水平(Steinhauer, White, & Drury, 2009)。
目前来看,L2句子加工研究主要涉及L2学习者与母语者的加工区别(如Jackson & Dussias,2009; Hopp, 2017; Jacob & Felser, 2016; Leikin, 2008;Marinis, Roberts, Felser, & Clahsen, 2005; Omaki &Schulz, 2011; Papadopoulou, 2006; Papadopoulou &Clahsen, 2003; Ravi & Chengappa, 2015; Roberts &Meyer, 2012),以及单纯的句法语义加工(如Friederici, 2002; Juffs, 1998)。这些研究主要是基于印欧语系的语言进行的,大都以句法歧义结构作为研究对象来考察L2句子加工,但汉语作为第二语言的句子加工研究并不多(戴运财, 2010; 戴运财, 王同顺, 余樟亚, 2013; 牛萌萌, 吴一安, 2007)。
本文选取汉语中常见的“V+N1+的+N2”潜在句法歧义结构(冯志伟, 1995)作为研究对象(实验语料中的“V”、“N1”和“N2”均为双音节),考察母语为韩语的汉语学习者在加工这类句法歧义结构时的加工机制。之所以选择母语为韩语的汉语学习者作为研究对象,主要基于以下考虑:汉语和韩语是两种不同类型的语言。前者属于孤立语,几乎没有外显的形态手段来标记句法范畴,而后者属于黏着语,会使用外显的形态手段来标记句法范畴,如“格”标记(徐英红,2009)。母语为韩语的汉语学习者由于母语背景的影响,其对汉语的句法歧义结构加工可能敏感,与汉语母语者存在差异,因此可以利用此类句法歧义结构作为切入点来考察L2句子的加工机制。
本文研究的问题包括:
(1)汉语母语者与母语为韩语的汉语学习者在加工汉语句法歧义结构时对语义和语境的敏感程度是否不同?
(2)母语为韩语的汉语学习者在阅读汉语句子时是属于序列加工模式,还是并行加工模式?与母语者的加工模式是否一致?
2 方法
2.1 被试
28名北京大学在读的韩国留学生,其汉语水平为高级,汉语水平考试(HSK)成绩均为6级(最高级别)。28名汉语母语者为北京大学的本科生或研究生。
2.2 实验设计
实验采用2×2×2因素设计。三个因素分别为(1)实验句前一部分“V+N1+的+N2”结构的歧义性:分为有歧义和无歧义两个水平;(2)续接语境后“V+N1+的+N2”结构可以解读的结构类型:分为偏正结构和述宾结构两个水平;(3)被试语言类型:分为汉语和韩语两个水平。其中,语言类型为被试间变量,续接语境和短语的歧义性为被试内变量。无歧义组为控制组。
2.3 实验材料
从北京语言大学汉语语料库(BCC)中选取42条“V+N1+的N2”歧义短语。然后对这些短语的结构相对合理性和事件典型性进行评定,分别由20个不参与正式实验的汉语母语者完成,以验证实验材料的有效性。
在相对合理性评定中,每条短语之后给出其可能存在的两种结构分析。例如,对于歧义结构“拥护小李的朋友”,给出“拥护朋友”和“拥护小李”两种不同的分析。随后,将42条短语产生的84个事件随机打乱,生成3种不同随机顺序的版本,以平衡位置效应,采用7点量表的方式进行评定。
短语事件典型性评定是考察歧义短语的不同结构所对应的意义在日常生活中的典型性或合理性。在事件典型性评定中,每条歧义短语按两种不同结构转化为两个不同的事件,并以短语的形式表现出来。以歧义短语“拥护小李的朋友”为例,其偏正结构对应的事件为“朋友拥护小李”,其述宾结构对应的事件为“某人拥护小李的朋友”。随后,将42条短语产生的84个事件随机打乱,生成3种不同随机顺序的版本,以平衡位置效应。在进行事件典型性评定时,被试依据已有的日常生活中的经验和常识,按照事件普遍性程度的高低,在7点量表上,对每条短语所代表的事件的普遍程度进行评定。根据设定,分数越低,表明述宾结构越合理;分数越高,表明偏正结构越合理。
利用SPSS 20.0对相对合理性和事件典型性进行相关性检验,详见表1。
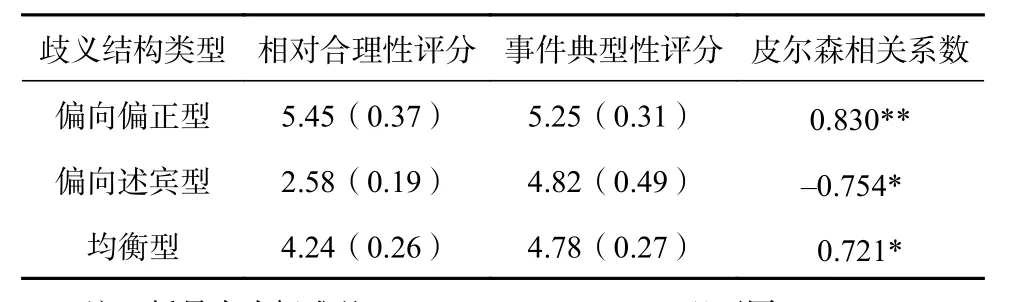
表 1 歧义结构相对合理性与事件典型性相关性检验(n=14)
根据分析结果,偏向偏正型和均衡型的相对合理性与事件典型性高度正相关,即相对合理性值越大,事件典型性程度越高;偏向述宾型的相对合理性与事件典型性呈高度负相关,即相对合理性值越大,事件典型性程度越小。
根据这两项评定后接语境生成实验句子材料,实验例句见表2。
42个歧义结构按照四种条件生成168个句子,采用拉丁方将句子分成四组,每组填加32个填充句(Dussias, 2010),填充句均为语义通顺的句子,且填充句与实验句嵌入实验程序后经过伪随机处理进行排列,每个被试只阅读其中的一组句子。同时,又随机插入37个判断题,以确保被试认真阅读句子。此外,在正式实验前,被试还将阅读6个练习句,以熟悉实验流程。这样,每个被试会阅读80个句子。实验句、填充句和判断题中出现的汉字均为HSK 6级以下的词汇,句子长度在15-20字之间。每个句子占一行。
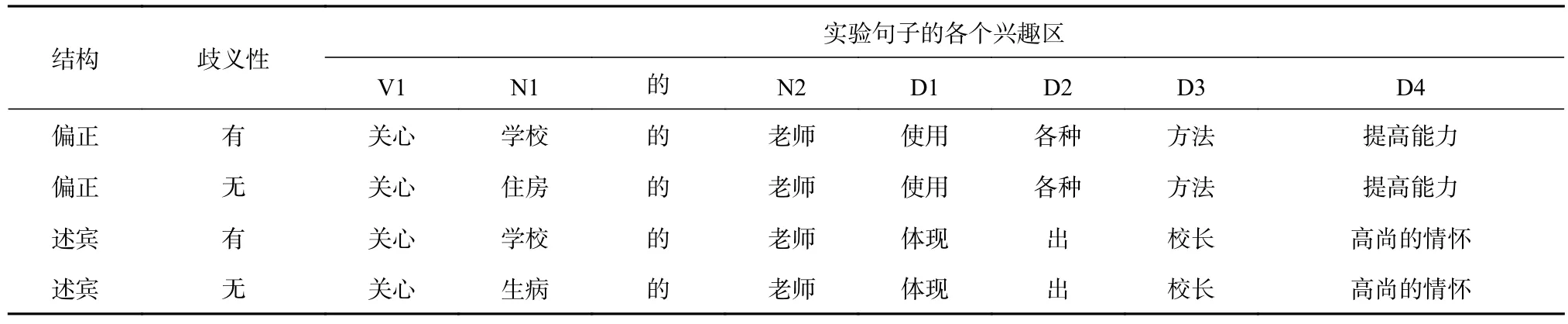
表 2 均衡型结构四种条件下的实验句子材料
2.4 实验仪器与程序
本实验采用SR EyeLink 1000 Plus型眼动仪呈现实验材料,并记录被试眼动数据。EyeLink 1000 Plus的采样频率为每秒1000次。被试进入实验室,坐在距离电脑屏幕70 cm的位置,对被试进行3点校准,之后在电脑屏幕上呈现指导语,并向被试简要说明。正式实验前有6个练习句,确认被试完全理解整个实验流程后,开始正式实验。
3 实验结果与分析
28名中国被试眼动数据正常,正确率均高于80%,平均为96%。28名韩国被试中,1名被试数据异常,进行剔除;2名被试判断正确率为60%,低于80%,其数据不参与统计分析,其余被试判断正确率均高于80%,平均为92.31%。5次以上眨眼以及在紧靠兴趣区前、兴趣区中间或紧靠兴趣区之后有眨眼的数据也予以剔除。此外,还剔除了三倍标准差以外的数据。总剔除数据占总数据的10.54%。
将实验句按照词语排列的顺序依次划分为8个兴趣区(Area of Interest, AOI),分别为A1、A2、A3、A4、D1、D2、D3、D4。其中 A1 到A4 分别对应“V”、“N1”、“的”和“N2”,兴趣区D1到D4是解歧区。
实验数据利用R语言(version3.3.3)的lme4程序包(version1.1-12, Bates, Mächler, Bolker, &Walker, 2015),采用混合效应模型进行被试分析和项目分析。具体来说,对于兴趣区A1至D4的首次注视时间(FFD)、第一遍阅读时间(FRDT)和总阅读时间(DT),采用线性混合效应模型进行统计分析。
3.1 首次注视时间
在兴趣区A1上,歧义性与续接语境交互效应显著(estimate=-0.26,SE=0.12,t=-2.15,p=0.037),续接语境与语言类型交互效应显著(estimate=-0.23,SE=0.11,t=-2.16,p=0.035)。
在兴趣区A2上,续接语境主效应显著(estimate=0.19,SE=0.09,t=2.17,p=0.034)。在兴趣区A3上,续接语境主效应边缘显著(estimate=0.09,SE=0.05,t=1.79,p=0.075)。在兴趣区A4上,歧义性主效应显著(estimate=0.09,SE=0.04,t=2.10,p=0.037),语言类型主效应显著(estimate=0.12,SE=0.05,t=2.28,p=0.024),歧义性与续接语境交互效应显著(estimate=-0.11,SE=0.06,t=-2.05,p=0.041),歧义性与语言类型交互效应边缘显著(estimate=-0.10,SE=0.06,t=-1.71,p=0.089),歧义性、续接语境与语言类型交互效应边缘显著(estimate=0.14,SE=0.08,t=1.74,p=0.084),二交互效应图如图1所示。中韩被试在兴趣A4上的平均首次注视时为MChinese=exp(5.34)=208.51 ms,MKorean=exp(5.34+0.12)=235.10 ms。统计结果如表3所示。
在兴趣区D1上,续接语境主效应显著(estimate=-0.16,SE=0.05,t=-3.35,p<0.001),语言类型主效应显著(estimate=0.12,SE=0.07,t=2.03,p=0.045)。中韩被试在兴趣区D1上的平均首次注视时间为:MChinese=exp(5.44)=230.44 ms,MKorean=exp(5.44+0.12)=259.82 ms。
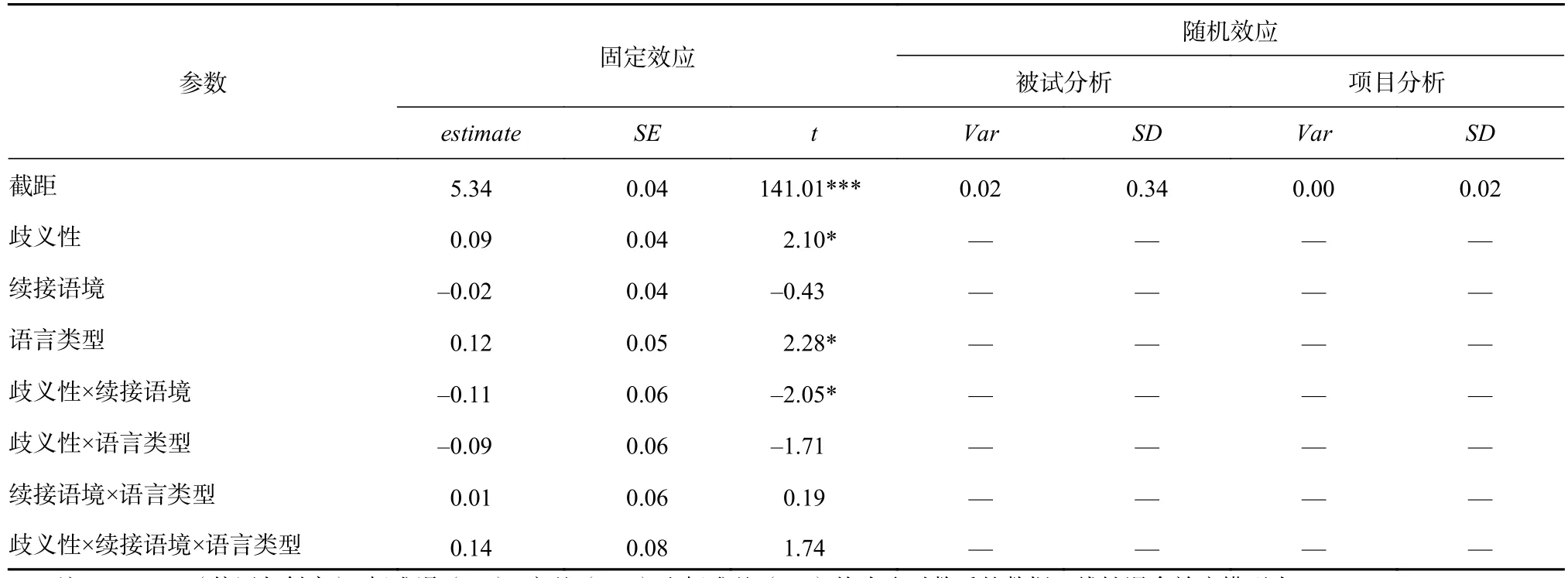
表 3 兴趣区A4首次注视时间的线性混合效应模型结果(取自然对数后)
在兴趣区D2上,语言类型主效应显著(estimate=0.08,SE=0.04,t=2.08,p=0.042)。在兴趣区D3上,续接语境与语言类型交互效应边缘显著(estimate=-0.15,SE=0.08,t=-1.88,p=0.067)。在兴趣区D4上,歧义性主效应显著(estimate=0.13,SE=0.06,t=2.22,p=0.031),语言类型主效应边缘显著(estimate=0.14,SE=0.07,t=2.02,p=0.050),中韩被试在兴趣区D4上的平均首次注视时间为:MChinese=exp(5.32)=204.38 ms,MKorean=exp(5.32+0.14)=235.10 ms。
在眼动指标首次注视时间上:在兴趣区A4和D4上出现了歧义性主效应,且在偏正续接的情况,无歧义的控制组加工时长长于有歧义的,这一点可能是由于中国被试的加工策略所导致的。在兴趣区A2、A3和D1上出现了续接语境主效应,中韩被试在兴趣区A2和A3上是按照偏正结构来加工的,在D1上是按照述宾结构来加工的。在兴趣区A4、D1和D2上出现了语言类型主效应,韩国被试加工时间长于中国被试。
3.2 第一遍阅读时间
在兴趣区A1上,续接语境主效应显著(estimate=-0.15,SE=0.06,t=-2.60,p=0.013),语言类型主效应显著(estimate=0.25,SE=0.07,t=3.64,p<0.001)。
在兴趣区A2上,续接语境主效应显著(estimate=0.21,SE=0.11,t=2.00,p=0.049),语言类型主效应显著(estimate=0.32,SE=0.99,t=3.20,p=0.002<0.01)。中韩被试在兴趣区A2上的平均阅读时间为:MChinese=exp(5.46)=235.10 ms,MKorean=exp (5.46+0.32)=323.76 ms。
在兴趣区A3上,续接语境与语言类型交互效应边缘显著(estimate=-0.13,SE=0.07,t=-1.77,p=0.076)。在兴趣区A4上,语言类型主效应显著(estimate=0.39,SE=0.07,t=5.27,p<0.001),歧义性与语言类型交互效应边缘显著(estimate=-0.12,SE=0.07,t=-1.65,p=0.09)。中韩被试在兴趣区A4上的平均阅读时间为:MChinese=exp(5.41)=223.63 ms,MKorean=exp(5.41+0.39)=330.30 ms。
在兴趣区D1上,续接语境主效应显著(estimate=-0.16,SE=0.07,t=-2.28,p=0.025),语言类型主效应显著(estimate=0.45,SE=0.08,t=5.87,p<0.001),续接语境与语言类型交互效应显著(estimate=-0.26,SE=0.10,t=-2.69,p=0.008),歧义性、续接语境与语言类型交互效应边缘显著(estimate=0.22,SE=0.11,t=1.95,p=0.051)。中韩被试在兴趣区D1上的平均阅读时间为:MChinese=exp(5.53)=252.14 ms,MKorean=exp(5.53+0.45)=395.44 ms。
在兴趣区D2上,语言类型主效应显著(estimate=0.43,SE=0.07,t=5.78,p<0.001),歧义性与语言类型交互效应显著(estimate=-0.17,SE=0.08,t=-2.05,p=0.041),歧义性、续接语境与语言类型交互效应显著(estimate=0.26,SE=0.13,t=-2.05,p=0.041),如图2所示。中韩被试在兴趣区D2上的平均第一遍阅读时间为:MChinese=exp(5.50)=244.69 ms,MKorean=exp(5.50+0.43)=376.15 ms,如表 4。
在兴趣区D3上,语言类型主效应显著(estimate=0.30,SE=0.08,t=3.84,p<0.001),续接语境与语言类型交互效应显著(estimate=-0.19,SE=0.09,t=-2.06,p=0.043)。中韩被试在兴趣区D3上的平均第一遍阅读时间为:MChinese=exp(5.59)=267.74 ms,MKorean=exp(5.59+0.30)=361.41 ms。
在兴趣区D4上,歧义主效应显著(estimate=0.24,SE=0.11,t=2.20,p=0.030),续接语境主效应边缘显著(estimate=0.20,SE=0.11,t=1.90,p=0.064),语言类型主效应显著(estimate=0.58,SE=0.11,t=5.38,p<0.001)。中韩被试在兴趣区D4上的平均第一遍阅读时间为:MChinese=exp(5.44)=230.44 ms,MKorean=exp(5.44+0.58)=411.58 ms。

表 4 兴趣区D2第一遍阅读时间的线性混合效应模型结果(取自然对数后)
在眼动指标第一遍阅读时间上:在兴趣区D4上出现了歧义性主效应,由于是解歧后区产生的歧义性主效应,所以对实验分析的参考性作用不大。在兴趣区A1、A2、D1和D4上出现了续接语境主效应,中韩被试在兴趣区A1和D1上是按照述宾结构来加工的,在A2和D4上是按照偏正结构来加工的。在兴趣区A1、A2、A4、D1、D2、D3和D4上出现了语言类型主效应,韩国被试加工时间长于中国被试。
3.3 总阅读时间
在兴趣区A1上,语言类型主效应显著(estimate=0.42,SE=0.08,t=5.37,p<0.001)。在兴趣区A2上,语言类型主效应显著(estimate=0.32,SE=0.11,t=2.82,p=0.006)。中韩被试在兴趣区A2上的平均总阅读时间为:MChinese=exp(6.00)=403.43 ms,MKorean=exp(6.00+0.32)=555.57 ms。
在兴趣区A3上,续接语境主效应显著(estimate=0.27,SE=0.07,t=3.76,p<0.001),语言类型主效应边缘显著(estimate=0.16,SE=0.08,t=1.96,p=0.052)。歧义性与续接语境交互效应显著(estimate=-0.33,SE=0.11,t=-3.07,p=0.003),续接语境与语言类型交互效应显著(estimate=-0.25,SE=0.10,t=-2.49,p=0.017),歧义性、续接语境与语言类型交互效应显著(estimate=0.34,SE=0.15,t=2.35,p=0.024),如图3所示。中韩被试在兴趣区A3上的平均总阅读时间为:MChinese=exp(5.46)=235.10 ms,MKorean=exp(5.46+0.16)=275.89 ms。统计结果如表5所示。
在兴趣区A4上,续接语境主效应显著(estimate=0.14,SE=0.06,t=2.20,p=0.031),语言类型主效应显著(estimate=0.38,SE=0.11,t=3.44,p<0.001),歧义性与续接语境交互效应边缘显著(estimate=-0.16,SE=0.09,t=-1.85,p=0.069)。中韩被试在兴趣区A4上的平均总阅读时间为:MChinese=exp(5.81)=333.62 ms,MKorean=exp(5.81+0.38)=487.85 ms。
在兴趣区D1上,续接语境主效应显著(estimate=-0.18,SE=0.08,t=-2.28,p=0.024),语言类型主效应显著(estimate=0.43,SE=0.10,t=4.16,p<0.001),续接语境与语言类型交互效应显著(estimate=-0.23,SE=0.09,t=-2.48,p=0.013)。中韩被试在兴趣区D1上的平均总阅读时间为:

表 5 兴趣区A3总阅读时间的线性混合效应模型结果(取自然对数后)
MChinese=exp(5.88)=357.81 ms,MKorean=exp(5.88+0.43)=550.04 ms。
在兴趣区D2上,续接语境主效应显著(estimate=-0.14,SE=0.05,t=-2.71,p=0.008),语言类型主效应显著(estimate=0.44,SE=0.08,t=5.46,p<0.001)。中韩被试在兴趣区D2上的平均总阅读时间为:MChinese=exp(5.73)=307.97 ms,MKorean=exp(5.73+0.44)=478.19 ms。在兴趣区D3上,语言类型主效应显著(estimate=0.25,SE=0.10,t=2.46,p=0.016)。中韩被试在兴趣区D3上的平均总阅读时间为: MChinese=exp(5.89)=361.41 ms,MKorean=exp(5.89+0.25)=464.05 ms。
在兴趣区D4上,歧义性主效应显著(estimate=0.23,SE=0.12,t=1.99,p=0.049),续接语境主效应显著(estimate=0.29,SE=0.11,t=2.60,p=0.011),语言类型主效应显著(estimate=0.69,SE=0.12,t=5.98,p<0.001)。中韩被试在兴趣区D4上的平均总阅读时间为:MChinese=exp(5.63)=278.66 ms,MKorean=exp(5.63+0.69)=555.57 ms。
在眼动指标总阅读时间上:在兴趣区D4上出现了歧义性主效应,由于是解歧后区产生的歧义性主效应,所以对实验分析的参考性作用不大。在兴趣区A3、A4、D1、D2和D4上出现了续接语境主效应,中韩被试在兴趣区A3、A4和D4上是按照偏正结构来加工的,在D1和D2上是按照述宾结构来加工的。在兴趣区A1、A2、A4、D1、D2、D3和D4上出现了语言类型主效应,韩国被试加工时间长于中国被试。
4 讨论
4.1 语义与语境对句子加工的作用
总体上来说,从反映早期加工的首次注视时间和第一遍阅读时间来看,实验句在A4和D4(首次注视时间),以及D4(第一遍阅读时间)上出现歧义性主效应,产生花园路径效应;在A2和D1(首次注视时间),以及A1、A2、D1和D4(第一遍阅读时间)上出现语境主效应。歧义性效应和语境效应的存在说明,中韩被试在句子加工的早期阶段,语义信息就对被试的句法分析产生强烈的制约,这种制约被即时用于指导句子的加工,影响句义的建构,本文的研究结果一定程度上支持句子加工的相互作用模型和基于制约的模型。
依照花园路径模型中的最小附加原则,被试会以最少的节点数把新的语言输入成分架构在句法树上。为了减少认知加工负荷,被试在加工歧义结构时,会建构相对简单的句法结构。对于“V+N1+的+N2”歧义结构来说,分析成偏正义和述宾义的节点数是一样的。也就是说,从句法的角度来看,这两种结构的复杂程度是一样的,所带来的认知加工负荷也是一样的。但从实验结果中语境主效应的偏回归斜率既存在正值,也存在负值的现象,可以得知,中韩被试在加工过程中并不是单一按照一种句法结构关系来理解的,这也就说明最小附加原则不能够解释被试的“V+N1+的+N2”句法分析加工过程。从花园路径模型中的迟关闭原则来考虑,中韩被试会将新成分N2附着到最邻近的结构上,也就是“N1+的”上,这样与V组合在一起以述宾义的结构呈现。但在实验结果中,A2、A3和A4首次注视时间和第一遍阅读时间的语境主效应的偏回归斜率为正值,这说明中韩被试在这些区段是按照偏正义来理解的,因此迟关闭原则不能解释被试的加工过程。
根据L2句子加工中的时近原则,为了提高加工效率,减少加工负荷,加工器会选择低位挂靠,这与迟关闭原则相似,但谓词邻近原则认为,语法上允许的话,加工器会将新成分高位挂靠到谓词的中心词组上(Gibson, Pearlmutter, Canseco-Gonzalez, & Hickok, 1996)。对应到“V+N1+的+N2”歧义结构,并结合实验结果,可以得知,中韩被试在加工过程中整体上是将歧义区段A2、A3和A4按照偏正义进行加工的。也就是说,他们将新成分N2挂靠在动词V上,遵循了高位挂靠的原则,这从侧面说明了在汉语句子加工中高位挂靠原则强于低位挂靠。但同时,由实验结果中的续接语境和语言类型的交互效应,可以得知,在具体的兴趣区A3和D3上,韩国被试选择了述宾义加工,而中国被试选择了偏正义加工,且韩国被试加工时间明显长于中国被试,这说明韩国被试在加工过程中的句法表征是粗颗粒的(coarse grained)。但考察解歧区D1的第一遍阅读时间和总阅读时间,我们发现,续接语境和语言类型存在着交互效应,中韩被试都选择述宾义进行加工,韩国被试的加工时间长于中国被试,这又说明有着不同语言背景的中韩被试的语言认知系统并不存在本质差异(Dekydtspotter, Schwartz, &Sprouse, 2006)。
此外,虽然汉语和韩语是两种完全不同的语言类型,分别属于孤立语和黏着语,前者几乎没有外显的形态手段来标记句法范畴,而后者会利用外显的形态手段来标记句法范畴。但从实验结果来看,歧义性和语言类型存在的交互效应,韩国被试对汉语句法歧义结构加工较为敏感。从解歧区存在着续接语境和语言类型存在着交互效应也可以发现,韩国被试在解歧区的加工模式与中国被试相类似。在本实验中,韩国被试的汉语水平已经达到近似母语者(native-like)的水平,再结合实验数据分析,可以得知韩国被试L2(汉语)水平和认知加工模式也能够达到汉语母语者水平,在L2句子加工晚期与汉语母语者趋于一致,这从一定程度上证明了Steinhauer(2014)所提出的二语者L2加工的会聚假设。
本质上说,语境效应和挂靠倾向性都是L2句子加工时被试对句法结构的语义倾向性的选择,体现了L2句子加工的加工策略和心理机制(Dussias,2010)。在本实验结果中,歧义区段出现的语境主效应,表明语境和语义信息在早期加工阶段相互影响,共同作用于句子加工。
4.2 限制性并行加工模型
从实验结果来看,在早期加工阶段,A4和D4(首次注视时间),以及D4(第一遍阅读时间)上出现歧义性主效应;在晚期加工阶段,D4(总阅读时间)上出现歧义性主效应,也即产生了花园路径效应,这说明歧义性给中韩被试增加了加工负荷,中韩被试最后输出的句法表征是单一的,符合序列加工机制。其他大部分兴趣区在早期加工阶段和晚期加工阶段均没有出现歧义性效应,说明中韩被试最后输出的句法表征不是单一的,符合并行加工机制。
被试的句子加工模式可以由被试在遇到句法歧义时所构建和维持的句法表征数目来确定(Hsiao& Gibson, 2003)。在序列加工理论框架中,如果新成分不能够被整合到当前结构中,那么加工器就会重新进行句法分析,以将新成分纳入。这种重新分析会产生额外的加工负荷,导致加工时间增加。序列加工的核心争论点在于在很多实验过程中句法歧义结构并没有导致明显的加工困难出现,而重新分析理论也从一定程度上证明并不是所有的重新分析都会产生显著的花园路径效应(Frazier& Rayner, 1982)。在实验结果中,歧义性主效应出现在兴趣区A4和D4上,但解歧区D4上的歧义性主效应只能作为参考,不能有效地说明歧义性对句子加工的作用。我们发现,兴趣区A1在早期加工阶段存在着歧义性与续接语境的交互效应(estimate=-0.26,SE=0.12,t=-2.15,p=0.037),偏正语境下,有歧义的加工时长短于无歧义的加工时长,这不符合纯粹的序列加工模式。
在并行加工理论框架中,加工器会在句法歧义区段建构并维持多个结构。以本文研究的焦点“V+N1+的+N2”为例,加工器在句法歧义区段就能够建构并维持偏正和述宾两种句法表征。在加工过程中,句法复杂度、词频、语义信息和语境等因素会影响句法表征的激活水平、排序和选择(Hsiao & Gibson, 2003)。Tabor和 Hutchins (2004)提出可计算的自组织句子加工模型(computational self-organized parse)认为在句子加工中每一个新出现的成分都尽可能并行地激活与自身相匹配的附加结构(attachment),匹配后可供选择的句法结构由加工器依据词汇化的句法知识相互竞争,直到其中一个结构达到稳定状态(stabilisation)。根据这一加工模型,加工器在加工“V+N1+的+N2”时,在新成分“的”出现时,就会同时激活偏正结构和述宾结构,然后根据加工器已有的词汇化的句法知识来进行选择。在实验结果中,兴趣区A3(“的”)在晚期加工过程中出现了歧义性与续接语境的交互效应(estimate=-0.33,SE=0.11,t=-3.07,p=0.003),反映了中韩被试根据自身已有的句法知识并行地激活了偏正结构和述宾结构,并在加工晚期依靠解歧区的语境消息输出稳定状态的句法结构,这在一定程度上符合可计算的自组织句子加工模型。
可计算的自组织句子加工模型从本质上来说是一种限制性并行加工模型(limited parallelism,Hsieh & Boland, 2015)。依据限制性并行加工模型,并结合实验结果,可以得知,中韩被试在最初并行激活两种结构后,会出现短暂的花园路径效应,不受期待的结构(dispreferred alternative)的激活水平快速降低,然后单一的句法表征被选定。中韩被试虽然快速选定的具体句法表征有所差异,但加工模式总体上是一致的。
总的来说,中韩被试句子加工是限制性并行的,是基于制约的。在歧义区段“V+N1+的+N2”,被试同时激活偏正结构和述宾结构,得到更多语境和语义支持的结构激活水平更高,不受期待的结构激活水平快速弱化。在重新分析的过程中,由于不受期待的结构在早期加工过程中得到较多激活,所以加工时间并未显著增加。
5 结论
本文发现,在句法歧义加工过程中,中韩被试的语言认知系统并不存在本质差异,语境和语义信息在句子加工的早期阶段即相互影响,共同作用于句子加工,句子的晚期加工二者也趋于一致。这在一定程度上证明了Steinhauer等人(2009)所提出的二语者L2加工的会聚假设。母语为韩语的学习者汉语句子加工是限制性并行的,符合相互作用模型和基于制约的模型。
