基于轨迹的时空光谱特征语音情感识别算法①
2019-03-11朱艺伟宋泊东张立臣
朱艺伟,宋泊东,张立臣
(广东工业大学 计算机学院,广州 510006)
引言
在过去的十年中,情感计算的研究蓬勃发展,已经开始使机器能够感知和具有情感表达行为[1].其技术广泛应用于人机界面[2]和交互式机器人设计[3]领域,甚至是新兴的交叉研究领域,如社会信号处理[4]和行为信号处理[5]等.作为人类交流的自然编码信息,语音可以反映人类信息[6],例如:情感、性别、年龄及人格等等.因此,开发语音情感识别算法,仍然是一个流行的话题.
目前,国内外在情感识别建模语音声学方面进行了大量的研究,比如:底层特征工程、机器学习算法、甚至是联合特征标签表示[7].这些研究大多数都依赖于提取一组常用的短时间特征(声学低层描述符—— LLDs),例如:这些特征可以是相关的光谱特征(如MFCCs)、韵律特征(如音高语调)、语音质量(如抖动)、低能量算子等[8],然后选择情感识别框架.例如:支持向量机[9]或深层神经网络[10].或者利用时间序列模型将短语音低级描述符特征的时间性特征纳入到表达水平的情感识别中.如隐马尔科夫模型[11].有一些研究利用听觉感知激发的调制光谱轨迹的时间特征[12],用于情感识别.基于上述研究成果,本文提出了一种基于轨迹的视频描述符提取方法.该方法将音频文件本质上视为一组光谱图(通常是0.5-1),通过跟踪重要节点提取一组轨迹.然后通过对轨迹的时间过程和随时间的空间变化进行建模、计算,获取这些描述符在事件[13]和运动识别特征[14].基于上述研究成果,本文提出了一种基于轨迹的时空谱特征语音情感识别方法.该方法的核心思想是从语音频谱图,获得空间和时间上的描述符,进行分类和维度情感识别.与MFCCs和基频等特征提取方法相比,本文提出的方法在噪声条件下,调制光谱特更具鲁棒性.在4类情绪识别实验中获得了可比较的非加权平均值回馈,在激活识别任务中显著优于Conv-PS和Opem-Utt.
1 研究方法
1.1 情感语音数据库的选择
语音信号的特征是指它的声学特征、语音信号的时域波形、频谱特征以及语音信号的统计特性.语音信号首先是一个时间序列,进行语音分析时,最直观的就是它的时域波形.通过分析语音信号的时域波形,提取情感特征,就可以判断说话者的喜怒哀乐.
从语音信号中提取反映情感的参数较为困难,因为语音信号中包含了多种特征信息,不仅包括了说话者自身的特征信息、说话者的情感状态信息,也包括了说话内容、词汇和语法信息等.目前很多文献对如何提取语音中的情感特征参数做了大量的研究.其中,基频作为描述情感的最主要特征,很多文献都采用基于基频的统计特征,如峰值、均值、方差等.虽然这些特征描述了语音信号在不同情感状态下的变化,但是没有进一步详细描述基频曲线的变化趋势.针对这种现状,提出了一种基于轨迹的空间-时间谱特语音情感识别方法.其核心思想是从语音频谱图,获得空间和时间上的描述符,进行分类和维度情感识别,来提高情感的判断力.
本研究采用著名情感数据库:USC IEMOCAP数据库[15]用于算法实验.这个数据库由10个参与者组成,他们两人一组,进行面对面的互动.二元互动的设计是为了从演员中引出自然的多模态情感表现.话语都有明确的情感标签(如:愤怒、快乐、悲伤、神经等)和维度表征(如:价感、激活和支配).每句话的特征标签至少由3个评分者标注,维度属性至少由2个评分者标注.考虑到这个数据库的自发性和评估者之间的协议约为0.4,这个数据库对于算法的发展仍然是一个具有挑战性的情绪数据库.在这项工作中,我们在这个数据库上进行了两项不同的情绪识别任务:1)四类情绪识别;2)三层的情感效价维度和激活维度识别.对于分类情绪识别,分别是快乐的、悲伤的、中性的和愤怒的,可以认为样本与“兴奋”的标签是相同的“快乐”.评价和激活的三个层次被定义为:低(0-1:67)、中(1:67-3:33)和高(3:33-5),其中每个样本的值是基于评分者的平均值计算的.表1列出了每种类型标签的样本数量.

表1 情感分类标签的样本数量
1.2 基于轨迹的时空光谱特征提取
语音信号的振幅特征和各种情感信息也具有较强的相关性.当说话者处于生气或者高兴时,出现较大的幅值,而悲伤情感的幅度值较低,而且这些幅度差异越大,体现出情感的变化也越大.此外,语音的共振峰频率也是表达情感的特征参数之一.当同一人发出的带有不同情感而内容相同的语句时,其声道会有不同的变化,而语音的共振峰频率与声道的形状和大小有关,每种形状都有一套共振峰频率作为其特征.
因此,本研究试图从语速、基频(范围、平均值、包络等)、谱信息(共振峰位置,带宽等)、 语音能量信息特征方面具体分析语音中的情感特征.
图1描述了基于轨迹的时空光谱特性的音频文件分析流程.以下是特征提取的步骤:空间时间谱特征提取:话语框架,代表了信号实现框架使用一个情感序列,形成每个MFB-系数轨迹,计算基于网格的时空特征和获得额外导出轨迹.如假设p=(p1,p2,···,pk)是一个语音信号的基础频率,其中k为这个语音信号的基础频率帧数,那么,这个语音信号基础频率的最大值为:pmax=max(p1,p2,···,pk);最小值:pmin=min(p1,p2,···,pk);均值:;动态范围为:prange=pmax-pmin;方差为:.

图1 基于轨迹的时空光谱特征分析流程
语音信号的时空谱计算则可以表示为:Δp前端,Δp后端,Δp争端语音信号帧.通过计算统计函数轨迹,就可获得框架水平特性.
(1)框架的信号
将整个话语分割成帧的区域,每个帧的长度为L(L=250 ms,150 ms).帧之间有 50% 的重叠.
(2)代表段
使用26个Mel滤波器能量组(MFB)输出的序列表示每一帧中的信号——也可以被成像为光谱图.MFB 的窗口大小设置为 25 ms,重叠度为 50%.MFB计算的频率上限为3000 Hz.
(3)形成基本轨迹
26个滤波器输出的每个能量轮廓在每个帧的持续时间内形成一个基本轨迹.
(4)计算时空特征
对于每个基本轨迹,在t= 1 时,我们计算其相邻网格的一阶差分(8total:在图1中标记为黄色);然后我们沿着时间轴移动,计算这些网格差,直到帧结束.因此,我们得到8个额外的轨迹(所谓的派生轨迹),为每帧26个滤镜输出(一个轨迹的真实例子见图1),组成总共9个轨迹(1个基本轨迹+8个派生轨迹).
(5)框架水平时空描述符
我们通过应用4个统计功能,即基于帧级轨迹的时空描述符,得到最终的帧级轨迹.即:最大、最小、平均、标准偏差.26×9轨迹——每帧形成一组特性.
我们新提出的特性的基本思想本质上是跟踪光谱能量的变化在一个长期的框架内,在频率轴(空间)和时间轴的方向上.由于框架灵感来自于视频描述符的提取方法,与语音生成/感知相关的物理意义虽然很难建立.但是,这个框架提供了一种简单的方法来量化语音信号的频谱-时间特性之间的各种相互关系,直接从时间-频率表示,而不需要进行更高级别的处理.
2 实验与结果分析
在本研究中,我们对前文所述的情感识别任务进行了如下两个实验:
(1)实验 I:三种情绪识别实验中我们提出的带有Conv-PS和OpEmo-Uttfeatures的Traj-ST的比较和分析.
(2)实验 II:在三个情感识别实验中,Traj-ST 与Conv-PS和/ oropem-utt特征融合后的识别精度分析.其中,Conv-PS特征提取方法与Traj-ST相似,但不是计算Mel-filter输出轨迹的时空特征,而是每10 ms计算基本频率(f0)、强度(INT)、MFCCs、它们的delta和 delta-delta -delta -delta -delta -delta 45 个低级描述符.然后我们将 7 个统计函数 (max,min,mean,standard deviation,kurtosis,skewness,inter-quantile range)应用到这些LLD特征上,从而得到每一帧Conv-PS总共有315个特性.OpEmo-Utt是一个详尽的语音级特性集.在许多辅助语言识别任务中都有使用.每句话包含6668个特征.所有的特征都是针对单个说话者的.所有的评价都是通过一对一的交叉验证进行的,精度是用非加权平均的方法来衡量的.基于ANOVA测试的单变量特征选择是针对Traj-ST和Conv-PS特性集进行的.
2.1 识别框架
在实验 I中,对于 Traj-ST 和 Conv-PS 特征集,我们使用高斯混合模型(M=32)生成帧级每个类标签的概率分数pi,t,然后使用以下简单规则进行帧级识别:

在提到的类标签中,t指的是框架指数,而N则指的是一个话语中的总帧数.对于OpEmo-Utt,由于它是一个大维度的话语级特征向量,我们在进行主成分分析(90%的方差)和线性核支持向量机多类分类器后,使用了基于GMM的方法.
在实验 II中,Traj-ST与 Conv-PS和 OpEmo-Utt的融合方法如图2所示.融合框架基于逻辑回归.对于Traj-ST和Conv-PS,融合是在统计功能上进行的,即均值,标准差,最大值和最小值,应用于pi,t;对于OpEmo-Utt,融合是基于从一个Vs-all多类支持向量机输出的决策分数进行的.

图2 三个特征集融合方法
图2描述了三种特征集的融合方法.基于框架的特征用GMM模型概率评分输出的统计功能进行融合,使用SVM分类器的决策分数直接融合话语层次特征.最后采用的融合模型是logistic回归.
2.2 实验I:结果和讨论
表2总结了Exp i的详细结果.对于Traj-ST和Conv-PS,我们报告了使用不同帧长进行特征提取的GMM 模型的 UARsof,即 125 ms,250 ms,375 ms,完整发音长度.对于OpEmo-Utt,我们报告了使用GMM和svm模型的UARs.
结果中有几点需要注意.在四类情绪识别任务中,Traj-ST 与 OpEmo-Utt (47.5% vs.47.7%)进行了比较,而最佳准确率为Conv-PS(48.6%).在三层价识别任务中,使用 OpEmo-Utt(47.4%)是最准确的,在这一任务中,Traj-ST 和 Conv-PS 表现不佳.最后,我们建议的Traj-ST特性集在三层激活识别任务上的性能明显优于Conv-PS和OpEmo-Utt.它的识别率达到了61.5%,比Conv-PS提高了1.7%,比OpEmo-Utt提高了2.9%.通过三种类型的情绪识别任务的运行,似乎可以明显地看出,每一组这些特征确实具有不同数量和不同质量的情绪内容.Opem-Uttem似乎对价性表现得最好,这可能是由于对价度的感知的复杂性.例如,需要在话语层面提取语气特征.虽然过去已经证明,与声音有关的特征在激活维度中往往包含更多的信息,但是我们仍然可以很肯定地看到我们提出的特征,Traj-ST,在预测激活的整体感知方面比这两个其他特征集更有效.
识别任务:4级情绪识别,3级激活/情感效价识别.对于Traj-ST和Conv-PS,采用具有不同框架长度的GMM模型的UARs,用于特征提取.对于OpEmo-Utt,使用GMM和SVM模型的UARs.帧的持续时间也对获得最佳的精度forTraj-ST(也适用于Conv-PS)起着重要的作用.由此可见,大约 250 ms 的持续时间是最理想的帧-持续时间.
这一结果证实了已有研究在情感识别中使用长期光谱特征的发现.此外,Traj-ST的特征选择输出结果表明,时空特征的前三个方向分别为{0,0}-基轨迹,{1,0}-高时空等效方向轨迹,以及{1,-1}-高时空-早时空方向轨迹.这三种特征占选择产生的特征的50%.这些轨迹量化了光谱能量向高频段方向的变化,具有较高的情感识别精度,在3级激活识别中也表现显著.
2.3 实验II:结果和讨论
假设在实验I中,每一组特征似乎都能识别不同的情绪表现.为了进一步验证算法的可靠性,本文融合这三种不同的特征.表2列出了各种融合结果.OpEmo-Utt是指融合SVM模型输出的决策分数.表3总结了三个不同特征集的融合结果.
需要注意 Traj-ST,Conv-PS,OpEmo-Utt为使用UAR计算所呈现的数目.
由表3可见.首先,不同特征集的融合都提高了最佳单特征集的结果数据.具体表现在,4类情感识别的最佳融合精度是通过融合所有三组特征获得的53.5%(相对于绝对单个特征集的4.8%的绝对改进);3级情感效价的最佳融合结果是47.8% (1%绝对改进优于最佳单特征集,OpE).最后,三级激活的最佳融合结果是61.2% (相对于最佳单特征集0.9%的绝对改进,Traj-ST).由此可见,本文新提出的特征Traj-ST确实能够在该融合框架下进一步提高分类情感识别和激活水平检测的识别率,这意味着我们的特征的互补信息在情感方面具有较高的一致性.总之,实验证明,以轨迹为基础的空间时间谱特征可以结合利用两个不同的声学特征集,提高情感识别率.
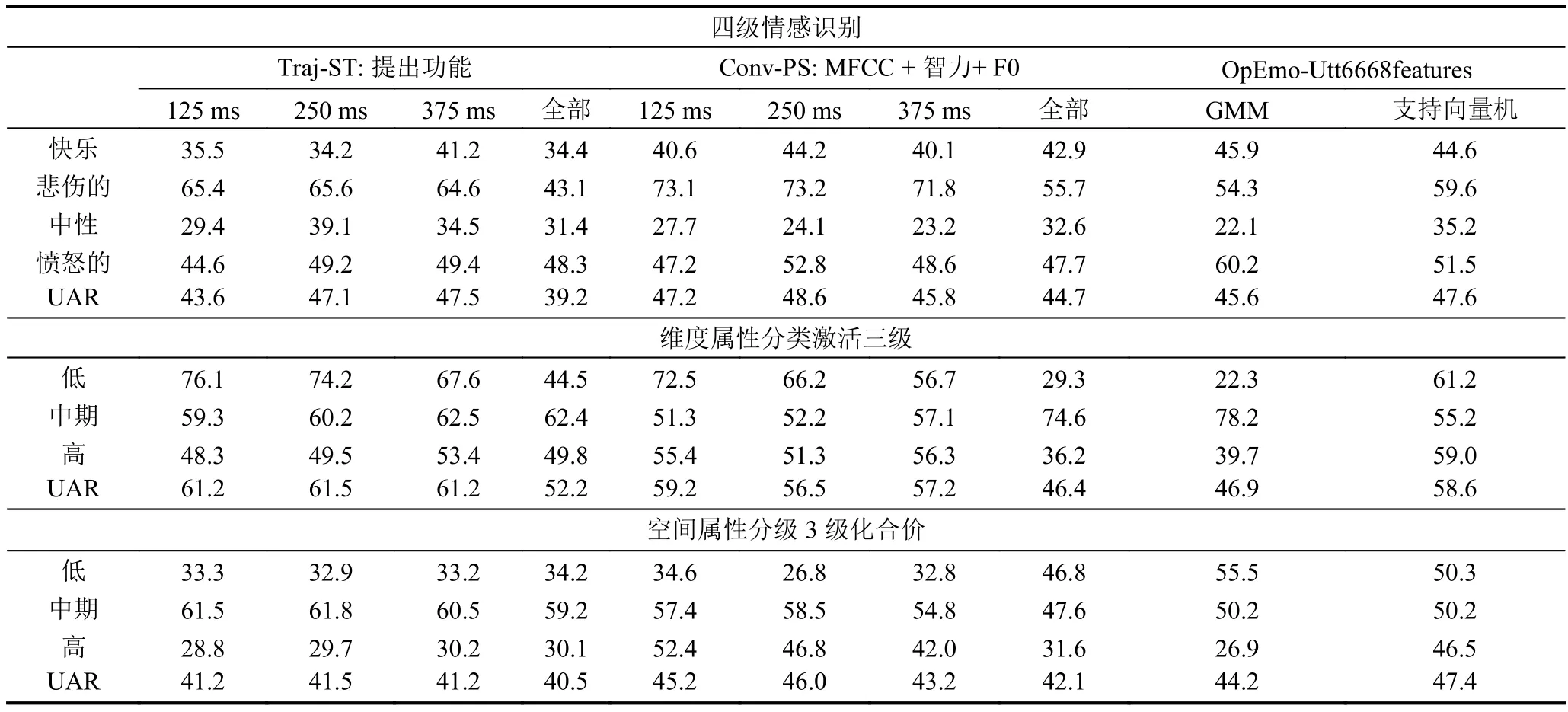
表2 实验 I输出了三种不同情绪的结果

表3 实验II输出了三个不同特征集融合的分析结果
3 结语
本文提出了一种低水平声学特征的语音情感识别方法,以表征语音信号的长期时空信息.我们利用所提出的特征对分类情感归因和维度表征进行情感识别实验.实验表明,所提出的特征集与已建立的低级声学描述符和最先进的穷举特征提取方法相比,在分类情感识别方面具有更优秀的性能,在激活水平识别的任务上优于现有的特征提取方法.通过融合基于轨迹的时空特征,提高了情感识别的整体精度.
