基于华为大数据平台的车辆销售数据分析应用
2019-03-05刘磊蔡欣桦许锐强
刘磊,蔡欣桦,许锐强
(广东开放大学,广州510000;广东理工职业学院,广州510000)
1 分析背景
随着云计算、大数据、人工智能等技术的飞速发展和应用,各行各业产生的数据规模也呈爆炸性增长,通过使用大数据平台对海量的行业数据信息进行分析挖据,提取出有价值的信息,对市场决策起到辅助作用。各行业通过各种不同方式产生的大量数据,堆积起来达到一定规模,可以构成大数据,大数据分析就是利用特定平台对规模巨大的数据进行分析挖掘,找到相关因素之间的关系。例如大数据分析可以让超市使用通过收集到的大数据来研究消费者的习惯,根据分析结果更合理地摆放商品的位置以增加销售量,从而为公司带来更高的利润。本文分析的是汽车销售数据,汽车销售是消费者支出的重要组成成分,也是了解一个国家经济循环强弱情况的第一手资料,早于其他个人消费数据的公布,汽车销售为随后的零售额和个人消费支出提供了很好的预示作用,汽车消费额占零售额的25%和整个销售总额的8%。本文使用华为大数据平台,从三个角度对汽车销售数据进行分析,并对分析结果进行可视化展示,非常直观地展现数据价值。
2 华为大数据平台
华为大数据平台FusionInsight HD 是华为企业级大数据存储、查询、分析的统一平台,通过分布式部署,对外提供大容量的数据存储、查询和分析能力,能够快速构建海量数据信息处理系统,对海量信息数据实时与非实时的分析挖掘,FusionInsight HD 兼容开源Hadoop 框架及众多组件,是完全开放的大数据平台,可运行在开放的x86 架构服务器上。FusionInsight HD 系统的逻辑架构如图1 所示。

图1 FusionInsight HD系统逻辑架构图
FusionInsight HD 对开源组件进行封装和增强,包含了管理系统Manager 和众多组件,常用功能如下:
(1)Manager:运维管理系统,为FusionInsight HD提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装部署、监控、告警、用户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等;
(2)Loader:实现FusionInsight HD 与关系型数据库、文件系统之间交换数据和文件的加载工具;同时提供REST API 接口,供第三方调度平台调用。Loader支持关系型数据库和HDFS、HBase、Hive 表等之间的互相导入导出。本文采用Loader 对加载和导出数据。
(3)Hive:建立在Hadoop 基础上的开源的数据仓库,提供类似SQL 的Hive Query Language 语言(HQL)操作结构化数据存储服务和基本的数据分析服务。本文采用HQL 对数据进行分析。
(4)MapReduce:提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境。本文采用Python 编写MapReduce 程序对数据进行清洗。
(5)HDFS:Hadoop 分布式文件系统(Hadoop Distributed File System),提供高吞吐量的数据访问,适合大规模数据集方面的应用。
(6)HBase:提供海量数据存储功能,是一种构建在HDFS 之上的分布式、面向列的存储系统。
3 分析方案设计
基于大数据平台对海量数据分析展示一般分步进行,本文对汽车销售数据分析设计的方案如下:
(1)获取源数据:本文汽车销售数据来源于互联网,可以通过大数据交易、API 接口、网络爬虫、统计图表等方式获取源数据。
(2)分析源数据:源数据拿到后,根据定下的分析角度,分析源数据字段是否全部满足分析角度的需求,是否有脏数据,是否需要数据清洗,本文从三个角度分析:行业市场分析、用户市场分析、不同品牌市场分析。
(3)加载源数据:使用ETL 工具将源数据导入HDFS,这里采用Loader 组件将数据从关系型数据库导入Hive 表。
(4)数据预处理:源数据通常包含脏数据,不能直接用来分析,需要根据需求进行预处理,包括数据清洗,缺省值填充,数据选择,数据变换,数据集成等。
(5)HQL 分析:对预处理后的数据,使用HQL 语言进行分析,HQL 可以查询和分析存储在Hadoop 中的大规模数据,使用HQL 可以快速方便地进行MapReduce 统计。
(6)Python 分析:使用Python 编写MapReduce 程序进行数据清洗和可视化呈现分析结果。
(7)导出分析结果:使用Loader 工具将分析结果从HDFS 导出到关系型数据库,为Web 系统应用提供大数据分析结果。
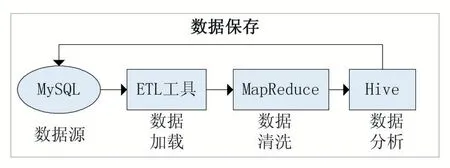
图2 分析方案示意图
4 源数据分析
本文收集到的汽车销售数据,包含销售信息和具体参数信息,数据包括汽车生产地点、生产时间、车辆型号、品牌、车辆类型、排量、油耗、功率、发动机型号、燃料种类、车外廓长宽高、轴距、前后车轮、轮胎规格、轮胎数、载客数、购买人相关信息等,共70 万条记录,样例数据如图3。

图3 源数据样例
这些源数据存储在关系型数据库MySQL 中,定义表名为te_bd_sp,通过分析源数据,使用Loader 工具加载转换时,做出处理:①第一行为字段,数据无效,去除第一行;②具体参数对于后面的分析角度无用,去除一些具体参数字段。处理后的源数据格式,如表1 所示。
5 数据预处理
高质量的大数据分析要基于高质量的数据,但是源数据通常存在部分脏数据,例如数据不完整、数据存在错误或异常、数据内容不一致等。这时要根据分析需求预先进行数据清洗。数据清洗是清除错误和不一致数据的过程,在数据挖掘过程中,数据清洗是第一步骤,即对数据进行预处理的过程,数据是不完整、有噪声和不一致的,数据清洗的任务是过滤或者修改那些不符合要求的数据,数据清洗的目的是为分析提供准确而有效地数据,提高分析效率。

表1 处理后的源数据格式
通过分析汽车销售数据,发现存在内容缺失的数据行,部分省份信息缺失的数据行内容残缺,影响后面的数据分析,因此对省份缺失的数据也进行过滤。编写MapReduce 程序进行数据清洗,清洗过程由Mapper负责,Reducer 则负责把清洗后的数据输出,使用Python 编写代码。
Mapper 部分代码如下:


使用以下语句执行MapReduce 程序:
yarn jar godlike/Yarn/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar-file data_analysis_map_version_3.py,data_analysis_reduce_version_3.py -mapper data_analysis_map_version_3.py-reducer data_analysis_reduce_version_3.py-input/tenant/user04/data/*-output/tenant/user04/opt
6 HQL分析
Hive 是基于Hadoop 的数据仓库基础构架,可以将结构化的数据文件映射为一张数据库表,提供了一种存储、查询和分析Hadoop 中的大规模数据的机制。Hive 定义了简单的类SQL 查询语言,称为HQL,它允许熟悉SQL 的用户查询数据,可以将HQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。同时,这个语言也允许熟悉MapReduce的开发者开发自定义的mapper 和reducer 来处理内建的程序无法完成的复杂分析工作。
Hive 中所有的数据都存储在HDFS 中,支持textfile、Sequencefile、Rcfile 等数据格式。使用Hive 创建表的时候,需要设定数据中的列分隔符和行分隔符,这样才能将数据正确导入Hive 表。
车辆销售数据创建Hive 表语句如下:
create table table_name(sp_id int,province string,month int,dc string,qx string,year int,car_type string,manufacturer string,pinpai string,leixing string,suoyouquan string,xingzhi string,nums int,fdj_type string,pailiang string gonglv int,ry_type string,fdjqy string,car_name string,1age int,sex string)row format delimited fields terminated by‘,’lines terminated by‘ ’;
使用load 将清洗完的数据导入Hive 表,语句为:
load data inpath‘/tenant/user04/opt5/part-00000’into table te_bd_sp;
下面使用HQL 从三个角度分析车辆销售数据:
(1)汽车行业市场分析
例如统计山西省2013 年每个月的汽车销售数量的比例,需要的字段为省、年、月、销量,先统计出总销量,再统计出2013 年每个月的销量,两表进行join 操作,计算出比例,分析语句如下:
select t2.m as`月`,CONCAT(ROUND(t2.n/t1.r1*100,2),'','%')as`比例`from(select sum(nums)r1 from te_bd_sp where province='山西省'and year='2013')t1 join(select month m,sum(nums)n from te_bd_sp where province='山西省'and year='2013'group by month)t2 on 1=1;
运行结果如图4 所示。
(2)用户市场分析:
例如统计买车的人的性别比例,需要的字段为性别、主键,先统计出所有的销售数量,再按性别分组统计出销售数量,两表进行join 操作,计算出比例,分析语句如下:
select(case when t2.m='男性 'then'男性'when t2.m='女性 'then'女性'else'无性别'end)as`性别`,CONCAT(ROUND(t2.n/t1.r1*100,2),'','%')as`比例`from(select count(sp_id)r1 from te_bd_sp) t1 join (select sex m,count(sp_id) n from te_bd_sp group by sex)t2 on 1=1;

图4 汽车行业市场分析
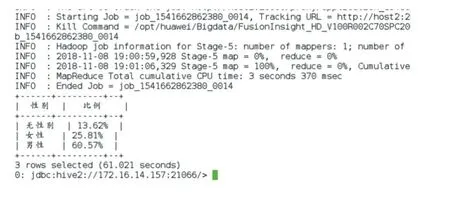
图5 用户市场分析
(3)不同品牌市场分析:
例如统计五菱在2013 年每个月的销售量和增长率,需要的字段为品牌、年、月、销量,增长率计算公式为:(本月销量-上月销量)/上月销量*100%,先统计出每个月的销量,再使用Hive 窗口函数LAG(col,n,DEFAULT)获取上月销量,计算出增长率,分析语句如下:
select month as`月`,sum(nums)as`销售量`,CONCAT(ROUND((sum(nums)-lag(sum(nums),1,0)over(order by month))/(lag(sum(nums),1,0)over(order by month))*100,2),'','%')as`增长率`from te_bd_sp where pinpai='五菱'and year='2013'group by month;
运行结果如图6 所示。
7 Python分析
将大数据分析结果导入关系型数据库,使用Python 代码编写程序,从数据库读取数据,呈现可视化结果。

图6 不同品牌市场分析
以统计山西省2013 年每个月的汽车销售数量的比例结果为例,使用Python 编写关键代码如下:

(1)分析每个月的汽车销售比例,按每月比例组成的饼图如图7 所示。

图7 饼图
(2)分析买车人的性别比例,有部分没填性别,显示时设置为无性别,所形成柱状图如图8 所示:

图8 柱状图
(3)分析五菱在2013 年每月增长趋势,形成折线图如图9 所示。

图9 折线图
8 结语
传统行业产生的海量数据正呈指数性增长,如何从这么大规模的数据量中分析挖掘出有价值的信息,这给技术带来了挑战。随着大数据平台的日渐成熟和普及,能够轻松实现TB 级数据的存储、PB 级数据的查询分析,为海量数据的分析预测提供了技术手段。本文基于业界流行的华为大数据平台,对车辆销售数据进行了三个角度的分析,先进行数据清洗,再使用HQL语言做统计分析,最后使用Python 可视化分析结果,为基于大数据平台的分析应用提供了参考。
