基于语义信息提取的卡通非真实感渲染
2019-03-04张诚
张诚
(四川大学计算机学院,成都610065)
0 引言
和追求照片级效果的真实感渲染相比,非真实感渲染(Non-Photorealistic Rendering,NPR)为使用计算机图形学来模拟绘画的艺术风格的渲染算法的总称。随着目前电影电视以及游戏的普及带来的需求提高,以及计算机硬件的发展,NPR 成为了一个热门的研究对象。本文主要着眼于一种广泛使用的所谓赛璐璐风格的卡通风格,其艺术风格可以描述为由大色块构成的前景,层次清晰的阴影,固定的背景等。由于该风格在动画中应用广泛,使用CG 技术模拟赛璐璐风格的尝试在业界已有不少尝试。早在90 年代,就已经有小部分的动画尝试将部分镜头使用3D 渲染了,而近年甚至存在专门的从事此类工作的动画公司。

图1 手绘图片与同风格的卡通渲染CG的对比
然而包括卡通渲染在内的大部分NPR 技术,其本质都是使用一套固定的算法的处理三维模型,而目标却是对某种手绘艺术风格的模拟[1]。换句话说,作为一种3D 渲染算法其最终目标却是消除其3D 感,此外不同艺术家的风格也有微妙的不同。为此许多情况下,在渲染算法已经确定的情况下NPR 的算法经常需要或经过参数调整才能达到希望的效果。这里存在两个主要的不足:过于忠实于物理的光照模型导致渲染出的结果过于呆板,缺少个人风格,自由度过低;对现有二维卡通风格的基于NPR 的模拟需要基于个别案例的具体分析,为得到较为接近的效果需要多次手动重复调整-检查的过程。
本文针对性地解决了上述问题。首先,本文提出了一套算法,通过分析现存的手绘卡通图片样本提取出配色,阴影风格等与其艺术风格相关的语义信息,并讨论了一套紧凑而适合GPU 渲染的方式保存。其次利用提取出的语义信息,本文提出了一套改进的赛璐璐风格渲染算法,和现存算法最大相比区别在于增加了数个随局部三维场景等改变的参数,大幅增加了可调整的参数数目,从而可以适应多样的风格。通过自动从现存的卡通图像中提取这些参数,不仅能减少工作量,还保证在各个视角以及不同光照下都能达到比较一致的渲染效果。
1 相关工作
图片的语义信息理解与提取是计算机视觉(CV)的一个主要课题,且长年间都有成熟的算法。随着近年深度学习特别是卷积神经网络的普及与发展,各大传统的CV 课题都迎来了新的进步。计算机视觉领域,找出图片前景的任务被称为saliency mapping,但对应算法大多机械地根据颜色特征进行判断,导致对于充满饱和颜色的卡通图片效果不佳。2018 年,Google 开发的基于深度学习的语义分割库DeepLab V3[2],根据其论文也可以应用于前景分割,且最近有了应用其对卡通场景进行前景分割的实例。2002 年,SF Johnston 发表了第一种实用的通过手绘线稿生成法线图的算法:通过在线稿笔画处设定边界条件,Lumo 使用对画面插值的方法实现了法线图的生成[3]。2018 年发表的Deep-Normal 则使用大量生成的样本训练CNN 的方式实现了同样的功能[4]。Anjyo K I 等人分析了不规则的高光对非真实感渲染艺术风格的影响,通过更改Blinn 公式实现了卡通风格的高光[5]。
2 语义信息提取与拟合
2.1 流程

图2 本文的流程图
为了实现以特定手绘卡通图片为基准艺术风格的非真实感实时渲染的目标,整个本文大致分为两部分:第一部分,从图片中提取高层次的信息。本文首先通过计算机视觉和机器学习的方式获取以下信息:前景、线稿、风格分析用的配色表、法线图,最后由法线图与配色信息推导出这张图片最可信的光照方向。这些统称为原图片的语义信息。其中线稿图由指定颜色通过阈值处理得到,前景提取使用了未经修改的DeepLab v3 神经网络,法线的生成结合使用了DeepNormal 与Lumo 的方法,下文不再赘述。第二部分,说明现在常用的卡通渲染算法的不足并做修改以便表达更广范围的艺术风格,使用第一部分提取出的语义信息,结合源图片的场景上下文,转换为适合上述渲染算法使用的参数:漫反射参数与各向异性高光参数。转换的过程中还讨论了不同数据表达方式对效果的影响。
2.2 语义信息提取

图3 输入图像

图4 配色分析得到的色块位置
前景由有限的少数几种颜色构成是卡通风格的一个特点。然而由于扫描,图片压缩或后处理等因素,对同一色块其RGB 值不一定完全一致。因此,需要一种提取出图像中独立色块方法。此外,我们期望在颜色划分的时候意识到主颜色与阴影色的关系,因为在美术上两者被认为是表示立体关系的一对或配色,且其关系对之后的光照分析有重要作用。
将图像转换为HSV 表示后,我们期望拥有一类配色的像素的色相值会趋于相同。利用这个特性,我们以图像上像素的色相值作为样本x1, x2,…, xn使用核密度估计(Kernel Density Estimation,KDE)来寻找H 值聚集的中心,其估计函数为:
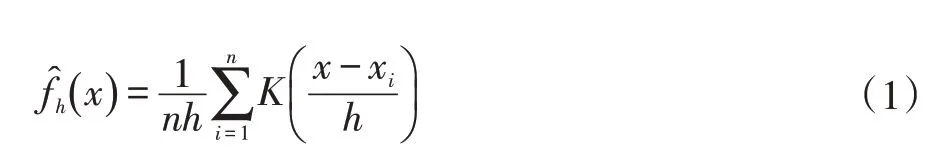
K 是任意的核函数,一般使用正态分布,h 控制核函数的宽度。但要注意色相是一个定义在圆周上的量,即最大值与最小值是连续的,因而预测时使用了定义在圆周上的von Mises 分布作为核函数进行圆周核密度估计运算。核密度估计的圆周版本有相同的表达式。von Mises 分布函数在其定义域0 到2π 中,首尾连续,且积分为1,适合此类问题的要求。直观上可以看出对应配色的H 值位于估计函数的极大值处。在以量化误差小于指定阈值的条件下,取尽可能少的估计函数最大的前数个H 值作为结果。
作为一个优化,观察注意到KDE 法本质上与一个所有样本点为中心的冲激函数之和的函数与给定核函数的卷积成正比,因而圆周上的KDE 可以看作为循环卷积,能够等效地由两信号的DFT(离散傅里叶变换)的乘积计算得到。在信号采样率,即圆周0 到2π 上单位长度能表示的色相数为M 的情况下,前者的时间复杂度为O(M2),后者在对DFT 运算充分优化的情况下为O(M log M),即FFT 的时间复杂度。
每一个相似的色相同时包含了亮部与暗部,需要进行主颜色和阴影色的分离。找到一个合适的明度的阈值将对应颜色数据分为两部分,使得两部分的方差和最小。这也是K-means 算法的定义。最常用的随机迭代的K-means 算法实现主要应用于高维数据,对一维数据较难收敛。对于一维的K-means 的特殊情况,有基于动态规划的最优化算法,时间复杂度为O(N)[6]。

图5
从左至右:记录源图像暗部的蒙版;记录亮部的蒙版;生成的法线图;猜测得到的光照。法线图通过将三维法线向量的分量使用RGB 三个通道的强度进行存储。
在得到图片的主颜色与阴影色及其在图片上的位置之后,要据此结合法线图猜测图片所表示场景的最合理的光照配置。我们暂时只研究受一个平行光的场景,例如典型的户外只受太阳光的情况。设平行光方向为,图片上x→点的法线为,光线与法线的夹角与正相关。一个合理的光照方向应尽可能直射亮表面,使得图片的亮表面的光照夹角尽量小,而暗表面的光照夹角尽量大,即:

其中L 与D 分别表示法线图所表示的三维场景中亮表面与暗表面的点集。为了将这个积分转换为离散的图像运算,需要注意到一个事实:图像上每个像素所对应的三维场景模型的表面积与法线与视角向量夹角的余弦成反比。设是视角方向,前景有N 个像素,对于第i 个像素设L 与D 在图像上对应位置像素下标的集合分别为L'与D',则(2)式可以离散化并求值得到:
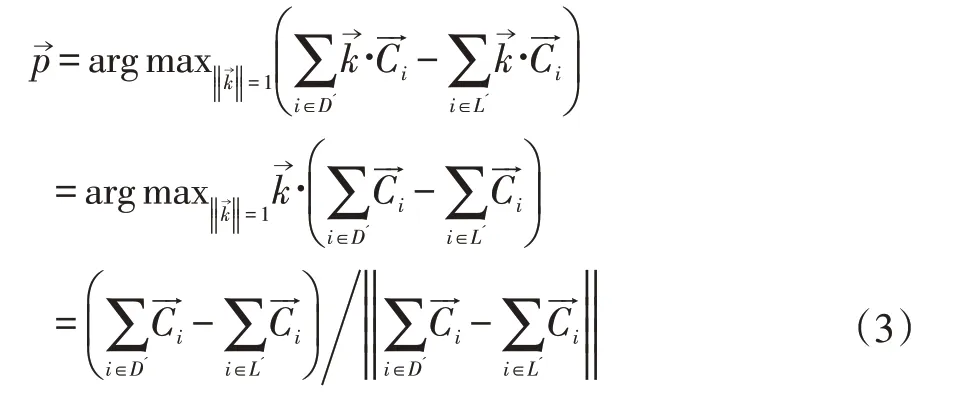
2.3 光照模型与拟合

图6 直接采样得到的阈值函数与滤波后结果的比较
大多数NPR 模型的光照模型都可以分为散射(Diffuse)与高光两部分。卡通渲染的阴影基本上都是某种Lambert 光照的变体。一个常用的简化模型就是将Lambert 二值化,根据阈值判断表面上某点是否在阴影中,然而这种做法的结果通常比较呆板。为了减少这种现象,同时更重要地为了更精确地模拟多样的风格,需要更精细的光照模型的建模。
我们将传统的Lambert 模型参数化,通过一个连续函数映射到不同的Lambert 阈值并使用该函数进行三维渲染,意图对不同的空间相对位置逐渐更改渲染方式,通过学习拟合出目标图片最近的函数,达到风格模仿的目的。具体来说,对于场景表面任一点,我们使用切空间坐标系下光照向量L 在tangent-bitangent 平面(切平面)上的投影与切线的夹角作为自变量,Lambert二值化的阈值作为因变量。对于输入图像的每一个像素,其法线方向已经确定,因而可以临时构建出一个切空间,确定该像素在上述函数中对应的自变量的位置,从而插值拟合出函数。实时渲染时通常使用一维贴图来保存和使用这个函数。
然而这样得到的阈值函数在实际渲染中细节处会有尖刺般的噪声。这是因为使用一维贴图表示函数时采样率过高导致容纳下了高频噪声。噪声出现主要的原因在于当沿着法线图阴影边界路径采样时,并不能精确地采样到并不存在的子像素的数据,而是直接读取了距离路径最近的像素中点的法线数据,保存下了并不该有的数据跳变。经验表明法线图的数据精度不足也是部分原因。
本文的解决方法为,最开始从图片生成阈值函数时,用尽可能高的采样率采取数据,之后使用信号处理的方法用低通滤波器去除高频噪声,但并不降采样地直接写入贴图使用。这样结果上解决了问题,然而使用高采样率来保存远小于其奈奎斯特频率的信号是一种空间的浪费。作为改进,我们可以直接从原始函数中提取并保存谐波,对高次谐波的丢弃等效于低通滤波。渲染时实时对谐波进行加总。此方法在函数梯度大的部分可实时丢弃部分高次谐波,起到类似Mipmap的作用。
此外,出于卡通风格的要求,我们希望得到不规则形状的高光。传统上这个问题大多由各向异性的BRDF 进行模拟,常用Kajiya-Kay[7]与Ashikhmin[8]模型。前者的BRDF 主要由对头发的几何特性进行分析而得到,对任意风格的高光形状的表达力不强,这里选用了后者。Ashikhmin BRDF 的表达式如下:

利用这个性质,由卡通图片拟合各向异性高光渲染参数的流程如下:由图片的高光光斑中心出发,以对应的切线或旁切线为方向找到相交的高光边缘位置,加上由法线图得到此处的法线,带入Ashikhmin BRDF求解得到nu或nv。
3 结果分析

图7
自左至右:Lambert 模型渲染结果;不使用滤波的结果;使用滤波后的结果。注意阴影边缘的改进。
为了测试算法应用于实际卡通渲染场景的可行度,使用Unity 引擎的ShaderLab 语言实现本文的光照模型并与业界常规的UnityChanToonShader 比较,在中度复杂度的场景中实验结果如表1。

表1
语义信息提取过程中本文改进的圆周KDE 与传统卷积法的性能比较如表2。

表2
根据以上数据可以得出结论,与传统方法相比,本文的解决方案从效果和速度两个方面评价都有一定的优势,具备了一定的可用性。
4 结语
本文通过分析现有非真实性渲染中卡通渲染算法的不足点,提出了一套全新的卡通渲染流程。通过创新的自动语义信息提取流程,在注重算法效率的前提下,实现了卡通风格的由二维到三维的风格模仿,包括一个有一定可用度的卡通渲染算法,并利用信号分析等方法对流程中的性能热点进行了优化。实验结果显示,本文的解决方案在实际运行中能达到引言介绍的要求,有相当的实用性,适宜于各类实时与非实时的卡通渲染场景。
