数据模型及其发展历程*
2019-03-01信俊昌王国仁李国徽高云君张志强
信俊昌,王国仁,李国徽,高云君,张志强
1(东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
2(北京理工大学 计算机学院,北京 100081)
3(华中科技大学 计算机科学与技术学院,湖北 武汉 430074)
4(浙江大学 计算机科学与技术学院,浙江 杭州 310058)
5(浙江财经大学 信息管理与工程学院,浙江 杭州 310018)
在信息化社会,数据库技术是管理信息系统、办公自动化系统、决策支持系统等各类信息系统的核心部分,是进行科学研究和决策管理的重要技术手段.数据库技术从诞生到现在,在不到半个世纪的时间里,形成了坚实的理论基础、成熟的商业产品和广泛的应用领域,吸引了越来越多的研究者加入.数据库的诞生和发展,给计算机信息管理带来了一场巨大的革命[1].几十年来,国内外已经开发建设了成千上万个数据库,它已成为企业、部门乃至个人日常工作、生产和生活的基础设施.同时,随着应用的扩展与深入,数据库的数量和规模越来越大,数据库的研究领域也已经大大地拓广和深化了.自1966年计算机图灵奖设立以来,数据库领域共获得了4次该奖项(1973年C.W.Bachman1,1983年E.F.Codd,1998年J.Gray和2014年M.Stonebraker),更加充分地说明了数据库是一个充满活力和创新精神的领域.
数据模型是数据库中数据的存储方式和操作方式,是数据库系统的基础.现实世界中客观存在的事物之间存在着多种联系,数据模型是将不同的联系通过筛选、归纳、总结、命名等抽象过程产生出概念模型,用以表示对现实世界的描述,然后转换成真实、容易被人们理解和便于计算机处理的数据表现形式.也可以说,数据模型用于表达现实世界中的对象,也就是将现实世界中杂乱的信息,用一种规范而形象化的方式表达出来.
根据不同模型的应用层次,可以将数据模型分为概念数据模型、逻辑数据模型和物理数据模型:概念数据模型中最常用的有E-R模型和面向对象模型等,主要用来描述世界的概念化结构,它使数据库的设计人员在设计的初始阶段,集中精力分析数据以及数据之间的联系;逻辑数据模型反映的是系统分析设计人员对数据存储的观点,是对概念数据模型进一步的分解和细化,其中最常用的是层次模型、网状模型、关系模型和大数据模型等;物理数据模型描述了数据在储存介质上的组织结构,是在逻辑数据模型的基础上,考虑各种具体的技术实现因素,进行数据库体系结构设计,真正实现数据在数据库中的存放.根据不同模型的语义关系,可以将数据模型分为XML、RDF模型和超模型等:XML模型是一种分层自描述模型;RDF是一种基于XML(可扩展标记语言)编写的元数据(描述数据的数据),用于描述Web资源的标记语言;超模型是一组超实体以及定义在它们上面的关系和约束组成,为复杂的实体模型建模提供了快捷的方法.根据不同模型的应用场景,可以将数据模型分为离线模型、在线模型和近线模型:离线模型的主要代表为OLAP模型;在线模型可以可靠地处理无限的数据流,像 Hadoop批量处理大数据一样,实时处理数据,主要代表为 Storm等;近线模型定位于在线存储和离线存储之间,是指将那些并不是经常用到或者说数据的访问量并不大的数据加以存储,但要求对这些数据寻址要迅速、传输率要高.目前,近线模型很多是基于 Hadoop分布式文件系统构建起来的.根据数据模型的发展历程,按时间段将数据模型分为结构化模型、半结构化模型、OLAP分析模型和大数据模型,其发展过程如图1所示.20世纪60年代中后期,出现了结构化模型,主要包括层次模型、网状模型、关系模型和面向对象模型等.20世纪80年代以前主要研究关系模型,关系模型为数据库系统和产业的发展奠定了坚实的基础.20世纪70年代后期产生了ER模型,80年代中期开始出现面向对象模型,到20世纪 90年代初期,面向对象模型达到一个顶峰.20世纪90代末期,随着互联网应用和科学计算等复杂应用的快速发展,开始出现半结构化模型,包括XML模型、JSON模型、RDF模型、图模型和超模型等.XML模型是一种分层自描述模型;JSON使用文本表示一个JS对象的信息,支持字符串、数字、对象、数组等各种类型;图模型应用图论存储实体间关系.进入21世纪,随着电子商务、商业智能等应用的不断发展,数据分析模型成为研究热点,主要包括ROLAP模型、MOLAP模型和Storm模型等.ROLAP模型主要研究事实表和维表的组织表示及其变种,包括星型模型、雪花模型等;MOLAP模型主要研究数据立方及其优化计算算法.2010年以来,随着大数据工业应用的快速发展,以NoSQL和NewSQL数据库系统为代表的大数据模型成为新的研究热点,主要包括key-value模型、key-column模型和key-document模型等.本文对上述数据模型进行了综述,并选取每个模型的典型数据库系统进行了性能的分析.
因此,根据数据模型的发展历程,本文第 1节和第 2节分别综述结构化模型和半结构化模型.第 3节综述OLAP分析模型.第4节综述大数据模型.第5节选取每个模型的典型数据库系统进行性能的分析.第6节进行总结.
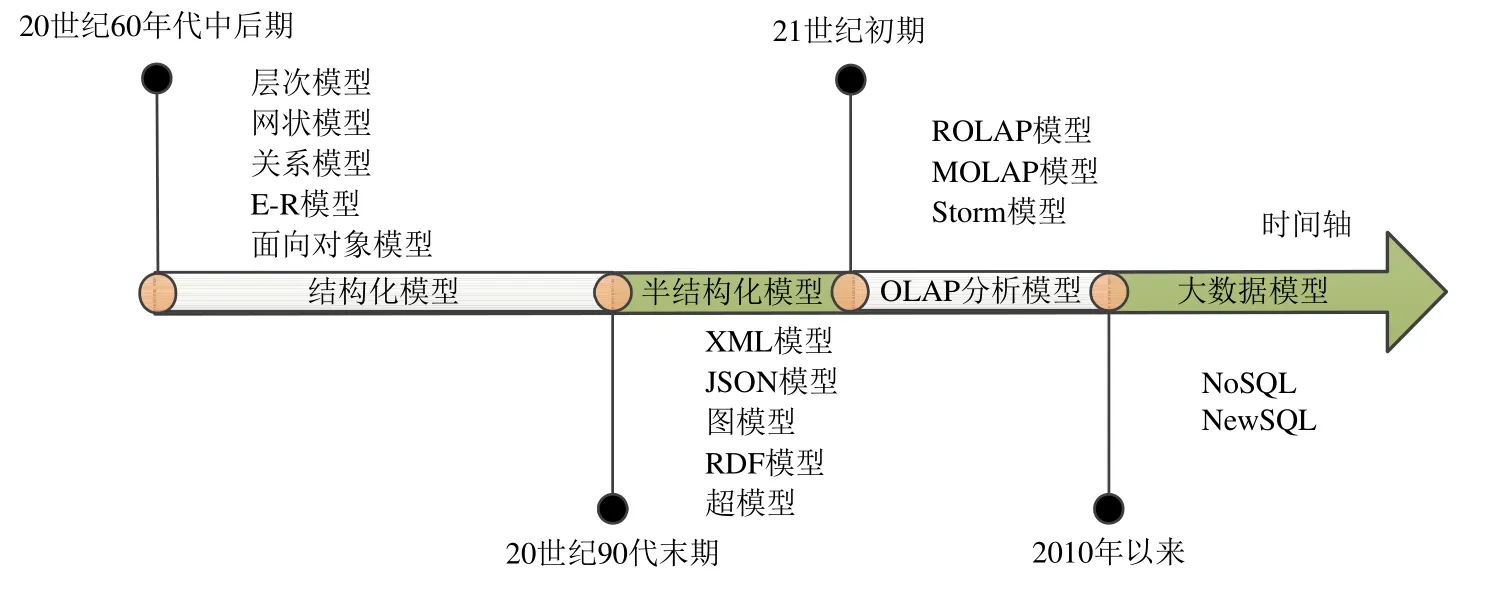
Fig.1 Timeline for the development of data models图1 数据模型的发展时间轴
1 结构化模型
结构化模型是最早被提出来的数据模型,是数据模型中最基础的模型之一.结构化模型主要包括层次模型、网状模型、关系模型和面向对象模型等.20世纪60年代中后期,出现了以IBM公司的IMS系统[2]为代表的层次模型、DBTG[3]提出的网状模型和 Codd[4,5]提出的关系模型.关系型数据库是目前最为流行的数据库,同时也是被普遍使用的数据库.20世纪70年代后期产生了E-R模型,通过E-R图,计算机专业人员与非计算机人员可以进行交流合作,以真实、合理地模拟一个单位,作为进一步设计数据库的基础.20世纪 80年代以前主要研究关系模型,关系模型为数据库系统和产业的发展奠定了坚实基础.20世纪80年代中期开始出现面向对象模型,到20世纪90年代初期,面向对象模型达到一个顶峰.面向对象数据模型是一种可扩充的数据模型,它吸收了语义数据模型和知识表示模型的一些基本概念,同时又借鉴了面向对象程序设计和抽象数据类型的一些思想.面向对象数据模型不是一开始就有明确的定义,而是在发展中逐步形成的.直到 1991年,美国国家标准协会(ANSI)的一个面向对象数据库工作组才提出第一个标准化的报告.
结构化模型可以分为传统数据模型和非传统数据模型,如图2所示.传统数据模型主要包括层次模型、网状模型和关系模型;非传统数据模型主要包括E-R模型和面向对象模型等.
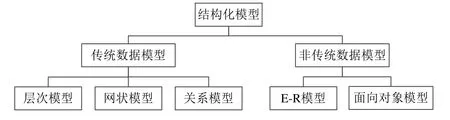
Fig.2 Classification of structured models图2 结构化模型类别
1.1 层次模型
层次模型采用树形结构来表示各类实体以及实体间的联系,具有数据结构比较简单清晰、数据库的查询效率高等优点.然而,现实世界中很多联系是非层次性的,而层次数据库系统只能处理一对多的实体联系;其次,由于层次模型查询子女节点必须通过双亲节点,查询效率较低.
在采用层次模型的典型数据库系统中,最著名的是IBM公司于1968年研制的IMS(information management system)[2].在IMS数据库管理系统中,数据被分层处理,层与层之间的数据彼此独立.这样使得数据保持彼此的独立完整,优化了数据的存储和获取进程.由于IBM公司具有强大的竞争力并且IMS是最早的大型数据库管理系统,因此该系统在公开之后被广泛应用.
1.2 网状模型
由于层次数据库系统只能处理一对多的实体联系,对现实世界的描述比较局限,因此出现了网状模型.网状模型的主要特点是子女节点与双亲节点的联系可以不唯一.
网状模型具有更好的性能和较高的存取效率,但网状模型结构、数据定义语言和数据操作语言比较复杂,用户不容易掌握和使用;其次,由于网状模型记录之间的联系是通过存取路径实现的,应用程序在访问数据时必须选择适当的存取路径,因此用户必须了解系统结构的细节,加重了编写应用程序的负担.在采用网状模型的典型数据库系统中,最具代表性的是 20世纪 70年数据系统语言研究会 CODASYL(Conf.on Data Systems Language)下属的数据库任务组(Data Base Task Group)提出的DBTG系统[3],亦称CODASYL系统.DBTG在数据定义语言中提供了数据库完整性的若干概念和语句.现有的网状数据库系统大都采用DBTG方案.
1.3 关系模型
由于层次模型和网状模型缺乏充实的理论基础,于是人们开始寻求具有较充实理论基础的数据模型.IBM公司的E.F.Codd从1970年~1974年发表了一系列有关关系模型的论文[4,5],从而奠定了关系数据库的设计基础.关系数据模型使用二维表表示实体和实体之间的关系,其数学定义如下.
(1) 域:具有相同的数据类型值的集合,语义上通常是指某一对象的取值范围;
(2)笛卡尔积:设D1,D2,…,Dn是n个域,则它们的笛卡尔积为D1×D2×…×Dn={(d1,d2,…,dn)|di∈Di,i=1,2,…,n},其中每一个元素称为一个n元组,简称元组;元组中的每个值di称为一个分量;
(3)关系:笛卡尔积D1×D2×…×Dn的子集合,记作R(D1,D2,…,Dn).其中,R称为关系名,n为关系的目或度.
关系型数据库管理系统的特征如下.
(1) 无论是实体、还是实体之间的联系都被映射成一张二维表;
(2) 借助关系表,表示实体之间的多对多的关系;
(3) 关系中的每个属性是不可分割的实体.
图3是学生选课系统的关系模型.从图中可以看到,学生与课程之间的联系以及教师和课程之间的多对多联系都被映射成了表格.其中,选课表中的sut_id和cour_id分别是引用学生表和课程表的cour_id的外键;教课表也是如此.
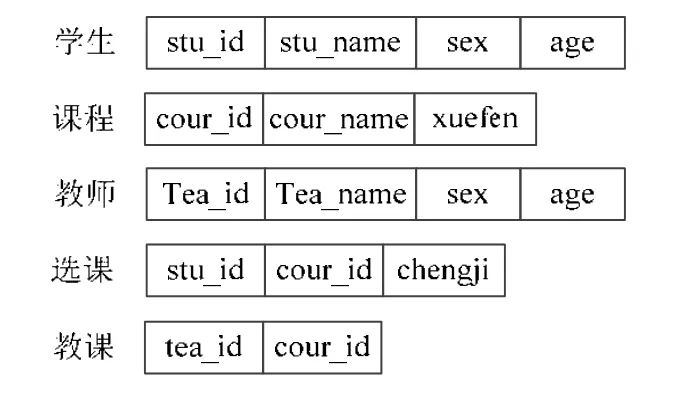
Fig.3 Relationship model instance of student图3 学生关系模型实例
关系模型是一些表格的框架,实体的属性是表格中列的条目,实体之间的关系也是通过表格的公共属性来表示,结构简单明了;其次,存取路径对用户而言是完全隐蔽的,程序和数据具有高度的独立性;再次,关系数据模型操作方便,在模型中操作的基本对象是集合而不是某一个元组数据.但是关系数据模型查询时只需指明数据存在的表和需要的数据所在的列,不用指明具体的查找路径,因而加大了系统的负担,查询效率较低.关系型数据库是目前最流行的数据库,同时也是被普遍使用的数据库.在采用关系模型的典型数据库系统中,目前业界普遍使用的有 MySQL[6]、PostgreSQL[7]、DB2[8]、Oracle[9]以及 SQL Server[10]等系统:MySQL 数据库是由瑞典MySQL AB公司1994年开始研发的一个开源数据库系统,因其具备处理速度快、可靠性高和适应性强等特点而备受关注;PostgreSQL是由加州大学伯克利分校计算机系开发的POSTGRES系统发展而来,支持处理丰富的数据类型;DB2是由IBM公司开发,采用多进程、多线索体系结构,可以运行于多种操作系统之上的关系型数据库管理系统;Oracle关系数据库管理系统是由甲骨文公司研发的一种高效率、高可靠性并适应高吞吐量的数据库解决方案;SQL Server是Microsoft公司推出的关系型数据库管理系统,具有使用方便、可伸缩性好与相关软件集成程度高等优点.
1.4 E-R模型
传统数据模型以记录为基础,不能很好地面向用户和应用[11].因为人们对现实世界的认识往往通过实体来实现,而现实中实体不一定与模型中的记录相对应,一个记录可能包含多个实体,一个实体可能分在多个记录中描述,有些实体也可能仅仅作为某个记录中的属性出现;其次,用户很难从传统数据模式看出实体间的全面联系,现实世界中的实体联系被淹没在关系和属性之中;再次,传统数据模型语义贫乏,支持的数据类型较少.因此从20世纪70年代后期开始,出现了第一种非传统的数据模型——E-R模型.E-R模型不同于传统数据模型面向数据库的实现,而是面向现实世界.E-R模型(entity-relationship model)即实体联系模型,是非传统数据模型之一,于1976年由P.Chen提出[12].其主要有3个抽象概念.
(1) 实体:一般认为,客观上可以相互区分的事物就是实体,实体可以是具体的人和物,也可以是抽象的概念与联系,关键在于一个实体可与另一个实体相区别.用实体名及其属性名的集合来抽象和刻画同类实体;
(2) 属性:实体所具有的某一特性,一个实体可由若干个属性来刻画.属性不能脱离实体,属性是相对实体而言的;
(3) 联系,也称关系,信息世界中反映实体内部或实体之间的关联.实体内部的联系通常是指组成实体的各属性之间的联系;实体之间的联系通常是指不同实体集之间的联系.
E-R模型实例如图4所示.由于E-R图直观易懂,在概念上表示了一个数据库的信息组织情况,所以若能画出E-R图,意味着彻底搞清了问题,此后就可以根据E-R图,结合具体DBMS的类型,把它演变为DBMS所能支持的数据模型.这种逐步推进的方法已经普遍用于数据库的设计中,成为数据库设计的一个重要步骤.
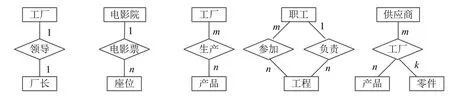
Fig.4 E-R model instance图4 E-R模型实例
通过E-R图,计算机专业人员与非计算机人员可以进行交流合作,以真实、合理地模拟一个单位,作为进一步设计数据库的基础.在 E-R图中:实体用矩形表示,矩形框内写明实体名,如果是弱实体的话,在矩形外面再套实线矩形;属性用椭圆形表示,并用无向边将其与相应的实体连接起来;联系用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型(1:1,1:n或m:n).比如,老师给学生授课存在授课关系,学生选课存在选课关系.
1.5 面向对象模型
基于面向对象模型的数据库属于非传统的数据库.与传统的数据库和 E-R模型相比,面向对象数据库适合存储不同类型的数据,如图片、声音、视频、文本、数字等.因为,其结合了面向对象程序设计与数据库技术,提供了一个集成应用开发系统.
基于对象定义语言描述的面向对象模型允许使用以下数据类型.
(1) 原子类型:包含整型、浮点型、字符型、字符串、布尔型和枚举型,定义方式与C语言类同;
(2) 结构类型:用StructN{T1F2,T2F2,…,TNFN}表示,其中,Struct是关键字;N是结构名;T1,T2,…,TN是类型,一般是原子类型;Fl,F2,…,FN是域名;第i个域名是Fi,类型是Ti;
(3) 聚集类型:一般由类型相同的原子类型或结构类型的元素聚集而成,包含集合、包、列表和数组;
(4) 接口类型:即类类型,面向对象模型定义的类型.
面向对象模型没有准确的定义,因为该名称已经应用到很多不同的产品和原型中,而这些产品和原型考虑的方面可能不一样,所以很难提供一个准确的定义来说明面向对象DBMS应建成什么样.
面向对象模型的数据结构是非常容易变化的.与传统的数据库(如层次、网状或关系)不同,面向对象模型没有单一固定的数据结构.编程人员可以给对象类型定义任何有用的结构,如链表、集合、数组等.此外,对象可以包含可变的复杂度,利用多重类型和多重结构.面向对象数据模型的实例如图5所示.
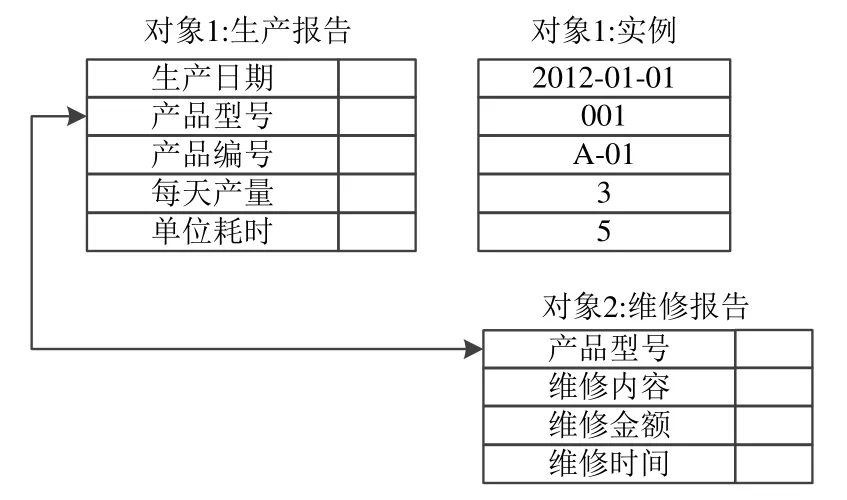
Fig.5 Object-Oriented model instance图5 面向对象模型实例
面向对象数据模型提供强大的特性,如继承、多态和动态绑定,允许用户不用编写特定对象的代码即可构成对象并提供解决方案,提高了数据库应用程序开发人员的开发效率;其次,面向对象数据模型明确地表示联系,支持导航式和关联式两种方式的信息访问,比基于关系值的联系更能提高数据访问性能;再次,面向对象数据模型适合于需要管理数据对象之间存在复杂关系的应用,特别适合特定的应用,如工程、电子商务、医疗等.
但是随着组织信息需求的改变,对象的定义也要求改变,并且需移植现有数据库,以完成新对象的定义,面向对象数据模型维护困难;其次,面向对象数据模型并不适合所有应用,当其被用于某些应用时,其性能将会降低.在采用面向对象模型的数据库系统中,典型的有 Gemstone[13]、Ontos[14]、O2[15]、Itasca[16]等:GemStone Systems于1982年3月1日成立,名为Servio Logic,于1995年6月更名为GemStone Systems,Gemstone系统是第一个作为面向对象的数据库;Ontos系统是美国Ontologic公司用C++语言开发的,采用多C/S体系结构,每个用户进程处理一个逻辑数据库;O2是法国Altair公司研制开发的,其设计目标是集成面向对象程序技术和数据库技术,支持CAM、CAD等高级应用;Itasca系统是Itasca公司在ORION系统基础上研发的商业化系统,采用基于对象服务器的多服务器多客户的分布式体系结构,支持复合对象和版本管理.
2 半结构化模型
结构化模型虽然可以很好地表达现实世界实体之间的关系,但对于诸如文本文件、超链接、HTML文档等半结构化数据缺乏有效的支持.不同于结构化模型,半结构化模型的特点主要有隐含的模式信息、结构不规则、缺乏严格的类型约束等[17].半结构化模型包括XML模型、RDF模型、JSON模型、图模型和超模型等.
2.1 XML模型
可扩展标记语言(extensible markup language,简称XML)是一种标记语言被作为互联网信息交换的标准[18],XML是一种分层自描述模型,具有良好的语义和可扩展性,可以灵活地表示和组织数据,并提供高效的查询方法,例如 XPath[19]、XQuery[20]、关键字查询[21,22]、子树匹配[23,24]等.此外,XML模型在数学(MathML[25])、化学(CML[26])、地理(GML[27])等领域也被广泛应用.
XML模型是由若干带有标签的节点组成的有向树,具体定义如下.
(1) 元素节点:该类型的节点为XML树中的标签;
(2) 属性节点:该类型的节点为 XML树中标签相关的属性.不同于元素节点,属性节点不是嵌套的,即,属性节点不能有任何子元素.相同的属性节点不能嵌套在同一个元素节点中,并且属性节点是无序的;
(3) 值节点(叶子节点):该类型的节点为标签的值;
(4) 有向边描述了各类型节点之间的关系.
此外,XML图模型允许用户引入 ID/IDREF属性来对树模型进行扩展,其中,ID属性唯一地标示了某个元素;IDREF引用其他被ID属性标示的元素,构成一个有向无环图.
XML模型如图6所示.
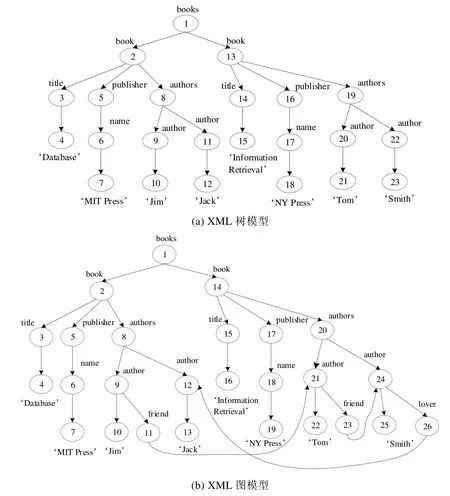
Fig.6 XML model instance图6 XML模型实例
在图6(a)所示的XML树模型中,book节点表示一个元素,title节点表示book的一个属性,而Database节点表示book的值.在图6(b)所示的XML图模型中,author=“Jim”的节点通过ID属性指向了他的friend节点(author=“Tom”).
基于XML模型的数据库有BaseX[28]、eXist[29]、MarkLogic Server[30]等:BaseX是一个开源的轻量级的XML数据管理系统,提供XQuery查询,常用于XML数据的存储、查询和可视化等.同样,eXist也是一个开源的XML源生数据库,除了支持XML数据,还支持JSON、HTML以及二进制文档的存储和管理;MarkLogic Server是一个面向对象的XML数据库,支持多维模型,支持JSON和RDF数据.
2.2 RDF模型
RDF(resource description framework)模型又称为资源描述框架,本质上是一个数据模型,它提供了一个统一的标准来描述Web上的资源,所谓的资源可以是指类(class)、属性(property)、实例(Instance)等等.RDF在形式上表示为一个三元组,即主语s(subject)、谓词p(predicate)、宾语o(object),以描述具体的事物及关系.RDF也可以表示为一张带有标记的有向图,图中有节点和边,节点对应实体,边对应关系或者属性,关系指的是实体之间、实体与属性之间的关系,其形式化描述如下.
RDF三元组:给定一个URI集合R、空节点集合B、文字描述集合L,一个RDF三元组t是形如(s,p,o)的三元组,其中,s∈R∪B,p∈R,o∈R∪B∪L.这里的s通常称为主语(subject)、资源(resource)或主体,p称为谓词(predicate)或属性(property),o称为宾语(object)、属性值(value)或客体.例如,知识图谱中的一条知识:“人工智能之父是图灵”,其中,“人工智能”是主语,“之父是”是谓语,“图灵”是宾语.
RDF模型以三元组的形式描述资源,简洁明了,并且令使用元数据的软件可以更容易和快速地制造.同时,索引是基于元数据而不是从正文得来,搜索者将得到更精确的搜索结果.在应用中,RDF模型可以用来表示Web上的任何被标识的信息,并且使得它可以在应用程序之间交换而不丧失语义信息.因此,RDF模型成为语义数据描述的标准,被广泛应用于元数据的描述、本体及语义网中很多机构和项目,如Wikipedia、DBLP等都用RDF表达它们的元数据.
2.3 JSON模型
虽然XML模型有统一的格式和标准、可提供多种复杂查询方法等优点,但数据文件较大,格式较复杂,不利于互联网上的数据传输.JSON(JavaScript object notation)是一种易于读写的轻量级数据表示格式,可以被快速、高效地解析[31,32].JSON使用文本来表示JavaScript对象的信息,支持字符串、数字、对象、数组等各种类型,并且提供快速读取数据的方法,被广泛用在数据采集[33]、数据挖掘[34]中.
JSON模型中有两种结构.
(1) 对象:一个对象包含一系列非排序的键-值对,一个对象以“{”开始,并以“}”结束.每个键-值对之间使用“:”区分;
(2)数组:一个数组是若干值的集合,一个数组以“[”开始,并以“]”结束.数组成员之间使用“,”区分.
例如,在图7(a)所示的 JSON 模型中,“address”表示了一个数组,存储了若干键-值对,即“streetAddress”:“21 2nd Street”,“city”:“New York”等.此外,JSON 模型可以与 XML 模型进行相互转换[35],例如,图7(a)所示的 JSON文档可以转换成图7(b)所示的XML模型.
虽然JSON和XML都可以完整地表示数据,并且可以相互转换,但它们之间存在以下不同之处.
· 首先,XML是一种标记语言,而JSON是由若干键/值对组成的集合,这使得应用程序在读取XML时需要更多的时间开销;
· 其次,XML的设计理念与JSON不同.XML利用标记语言的特性提供了良好的延展性(如XPath),并且提供高级检索,包括关键字查询、满足特定语义(如SLCA)查询等操作;而JSON相比于XML更加轻量级,可以被快速解析,使其更适用于互联网中的数据传输.
JSON模型多用于大数据的存储,支持JSON模型的数据库主要有MongoDB、CouchDB等.

Fig.7 JSON and XML conversion examples图7 JSON和XML相互转换举例
2.4 图模型
虽然 JSON模型可以有效地解决互联网中的数据传输问题,但在表示复杂实体关系时的可读性较差.针对这一问题,研究人员基于图论提出了图模型来存储和表示实体间关系[36,37].图模型是一种良好的数据表现形式,并提供多种查询方法,例如最短路径查询[38]、子图同构[39]等.图模型的应用十分广泛,如社交网络、知识图谱、时序数据管理等.基本的图模型可以分为无向图模型和有向图模型.随着研究的进展,图模型又细分为不确定图模型[40-43]、超图模型[44-48]、时序图模型[49-52].
(1) 图G=(V,E,∑),其中,V是节点集合,E是边集合,表示节点之间的关系,∑表示标签集合.更进一步地,如果图中的边是没有方向的,如图8(a)所示,则称为无向图;否则,称为有向图,如图8(b)所示;
(2) 不确定图G′=(G,P),其中,G表示一个有向图.对于任意边e∈E,P(e)→(0,1]表示e存在的概率.特别地,P(e)=1表示边e确定存在.不确定图模型如图8(c)所示;
(3) 时序图是一种随时间而变化的图模型,一般是有向的.时序图可以被看作是一组有向图序列TG=,其中,Gtx表示在时间点tx时的图G,时序图模型如图8(d)所示;
(4) 超图H=(X,E),其中,X表示一个有限集合S,S中的元素称为节点e;E是X的一个非空子集,称为超边或连接.超图模型如图8(e)所示.

Fig.8 Graph model example图8 图模型举例
基于图模型的数据库有AllegroGraph[53]、DEX[54]、HyperGraphDB[55]、Neo4j[56]等.AllegroGraph是一个商业型的数据库,提供图模型存储数据,提供多种语言的API接口,并支持SQL语言.DEX是一个轻量级的、可扩展的、高性能的图数据库,支持多种操作系统.HyperGraphDB是一种通用的开源数据存储机制,提供高效的数据管理方式.Neo4j是最常用的图数据管理系统,具有原生图存储机制,并支持ACID事务.
2.5 超模型
超模型与其他数据模型一样,超模型由一组超实体以及定义在它们上面的关系和约束组成,其差别是超模型必须由一个或多个模型来实现.其中,超实体被定义为实体或超实体类型的集合.超实体像实体一样,除试图捕获更高级的信息以外,它还可以有属性、协议以及参加各种关系等.超模型为复杂的实体模型建模提供了快捷的方法,其形式表示如图9所示.

Fig.9 Super entity representation图9 超实体表示形式
以某集团公司为例,超实体集团公司是公司、产品、市场等实体(或超实体)类型的抽象,它还可以定义一些有意义的属性,如利润、税金等,我们给出的定义如图10所示.

Fig.10 Instance of super entity图10 超实体实例
3 数据分析模型
3.1 OLAP模型
随着电子商务、商业智能等应用的不断发展,关系数据库之父E.F.Codd[57]于1993年提出了联机分析处理(on line transaction processing,简称OLAP)的概念.Codd认为,联机事务处理(on-line transaction processing,简称OLTP)[58]已不能满足终端用户对数据库查询分析的需要,SQL对数据库进行的简单查询也不能满足用户分析的需求,故提出了多维数据库和多维分析的概念.数据分析模型主要包括关系型 ROLAP和多维型 MOLAP[59]:ROLAP模型主要研究事实表和维表的组织表示及其变种,包括星型模型、雪花模型等;MOLAP模型主要研究数据立方及其优化计算算法.
为了严谨地综述OLAP模型[60],下面我们对一些OLAP模型用到的定义给出形式化描述.
(1) 度量:度量u是一个独立变量,它们参照每个维的某一维值,并作为OLAP的分析对象.度量的粒度是度量参照的维值所在的维级别,最细粒度的度量参照每一维d中的最低维级别的某一维值.设u参照维集合D={d1,d2,…,dn},∀d∈D,即集合D可以确定度量u,记作D→u,则满足D→u⇔∃!v∈md(lmd)˄v→u(d有m个维级别),其中,v→u是指维值v可以确定度量u;
(2) 单元格:在逻辑视图中,单元格是由若干不同的度量组成的原子单元,这些度量都参照相同的维值.对于维集合D而言,单元格可以表示为度量的集合,记作{u|D→u};
(3) 数据立方:根据定义1~定义3,数据立方是OLAP中的多维数据结构,简称立方;
(4) 块:块是数据立方的逻辑划分,一个数据立方可以根据维的取值分成多个块.
3.2 ROLAP模型
ROLAP(relational OLAP)[61,62]是基于关系数据库的 OLAP技术.ROLAP以关系型结构进行多维数据的表示和存储.ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维度使用一个或多个表来存放层次、成员类别等维度的描述信息.ROLAP模型主要包括星型模型、雪花模型.
星型数据模型是数据仓库和联机分析处理使用的最基本、最常用的数据模型,它能准确、简洁地描述出实体之间的逻辑关系.一个典型的星型模型包括一个大型的事实表和一组逻辑上围绕这个事实表的维度表.事实表是星型模型的核心,其中存放的大量数据,是同主题密切相关的、用户最关心的度量数据.维度是观察事实、分析主题的角度.维度表的集合是构建数据仓库数据模式的关键.维度表通过主键与事实表相连.用户依赖维表中的维度属性,从事实表中获取支持决策的数据.
图11所示为一个酒店经营数据仓库星型数据模型,记载了每位客人的消费形式、消费价格、促销方式、促销折扣、消费金额、成本、利润等度量数据.围绕经营主题,酒店经营数据仓库建立了客户维、消费项目维、时间维和促销维这4个维度.
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型.雪花模型是对星型模型的扩展,它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表.如图12所示,对消费项目维度的餐饮种类进行划分、对促销维度打折程度进行划分等.雪花型数据模型通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,除了数据冗余.
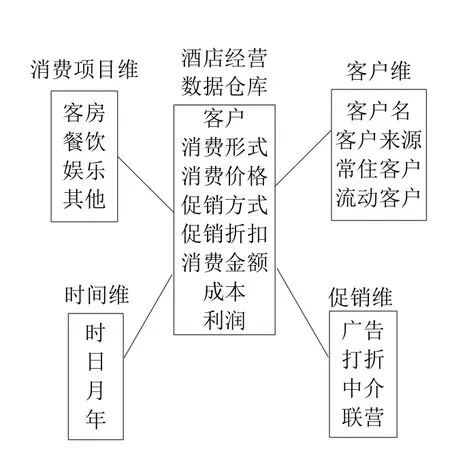
Fig.11 Star data model instance图11 星型数据模型实例
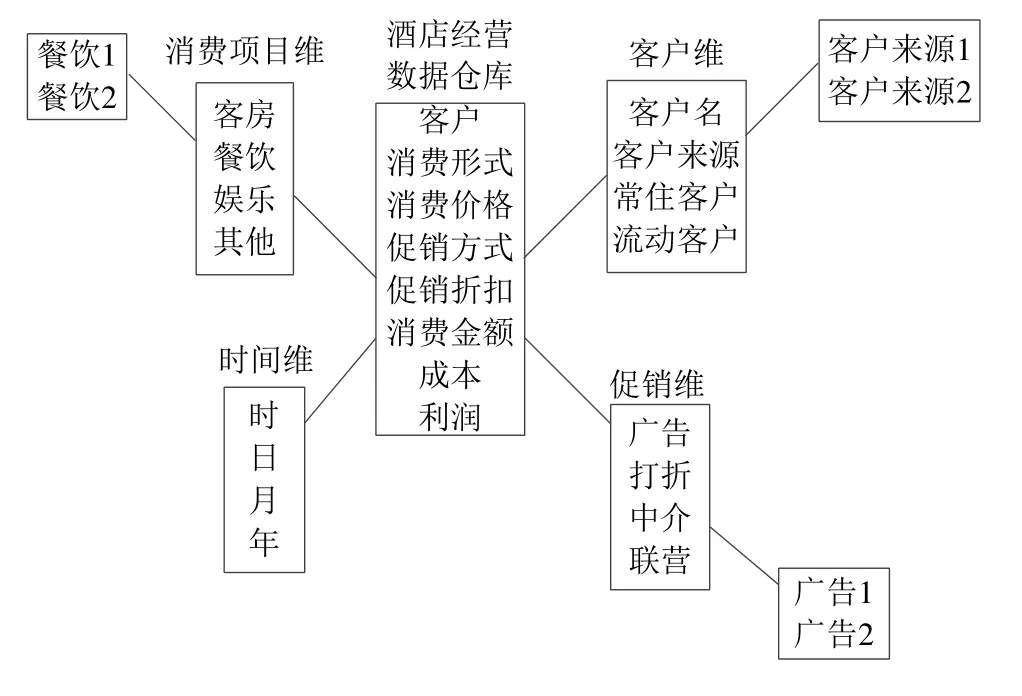
Fig.12 Snowflake data model instance图12 雪花型数据模型实例
微软Access的数据透视表(pivot table)[63]就是采用ROLAP数据模型的一个例子.Pivot Table是一种交互式的表,可以根据数据在数据透视表中的排列进行求和与计数等操作.同时,数据透视表可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号和页字段.当每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据.
3.3 MOLAP模型
ROLAP是将用户的OLAP操作转换成SQL语句提交到数据库中执行,并且提供聚集导航功能,根据用户操作的维度和度量,将SQL查询定位到最粗粒度的事实表上.ROLAP提供了更大的灵活度,但响应速度较慢,因此提出了MOLAP(multidimensional OLAP)[64,65],这是一种基于多维数据组织的OLAP技术.
MOLAP将OLAP分析所用到的多维数据以多维数组的形式存储,形成“立方体”的结构.MOLAP事先将汇总数据计算好,存放在自己特定的多维数据库中,用户的OLAP操作可以直接映射到多维数据库的访问,不通过SQL访问,加快了响应速度.
图13所示为某一超市连锁店的销售数据立方体,其中,用户关心的是销售量,并习惯从时间、地点和商品这3个角度来分析销售数据.在这里,销售量称为度量,时间、地点和商品称为维度.如图13所示,时间维、地点维和商品维的层次分别是年、城市和商品种类.这3个维层次以及由维到度量的映射关系决定的度量数据构成了一个数据立方体实例.
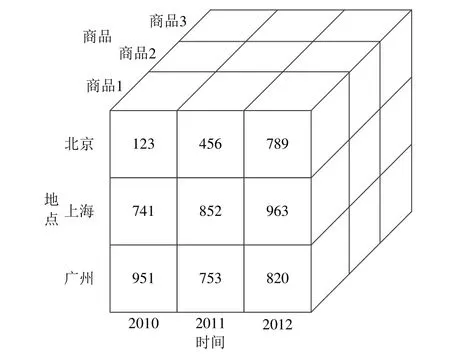
Fig.13 Data cube instance based on time,place,product图13 基于时间、地点、商品的数据立方体实例
采用MOLAP模型的数据库系统的代表产品有Hyperion(原Arbor Software) Essbase[66]等.Hyperion Essbase平台是全球领先的企业绩效管理(business performance management,简称BPM)解决方案提供商.借助此平台,企业可以制定战略方针、构建业务模型,并有效规划企业资源.业务智能平台同时可以监控由上述因素所推动的业务改进流程,并提供详细报表.这样不仅可以分析出推动企业成长的主要动力,还可以预测核心业务的前景.
3.4 Storm模型
Storm[67,68]是一个免费并开源的分布式实时计算系统,利用 Storm,可以很容易做到可靠地处理无限的数据流.像Hadoop批量处理大数据一样,Storm可以实时处理数据.Storm操作简单,可以使用任何编程语言.
Storm实现了一个数据流(data flow)的模型,在这个模型中,数据持续不断地流经一个由很多转换实体构成的网络.一个数据流的抽象叫作流(stream),流是无限的元组(tuple)序列.元组就像一个可以表示标准数据类型(例如int、float和byte数组)和用户自定义类型(需要额外序列化代码的)的数据结构.每个数据流由一个唯一的ID来标示,这个ID可以用来构建拓扑中各个组件的数据源.
Storm[69]模型对数据输入的来源和输出数据的去向没有作任何限制.像 Hadoop,是需要把数据放到自己的文件系统HDFS里的.在Storm里,可以使用任意来源的数据输入和任意的数据输出,只要实现对应的代码来获取/写入这些数据即可.
Storm模型具有编程简单、低延迟、可扩展性强、容错性高和消息不易丢失等优点.Storm模型提供的编程原语与 Hadoop类似,也很简单,开发人员只需要关注应用逻辑;Storm 模型可以分布式处理,轻松应对数据量大、单机搞不定的场景;并且随着业务的发展,数据量和计算量越来越大,Storm模型可以水平扩展.
4 大数据模型
随着互联网、物联网、社交网络等技术的飞速发展,传统的数据模型已经无法应对数据量的爆炸式增长.为了解决因这些海量数据造成的存储瓶颈以及管理复杂性等问题,以NoSQL和NewSQL数据库系统为代表的大数据模型逐渐成为新的研究热点.
4.1 NoSQL模型
NoSQL模型是指非关系型、不遵循 ACID原则的存储模型[70,71].NoSQL模型遵循CAP理论[72]和BASE原则[73].CAP理论指出:任何分布式系统无法同时满足一致性(consistency)、可用性(availability)和分区容错性(partition tolerance),最多只能满足其中的两个.而 BASE指出,分布式系统在设计时需要考虑基本可用性(basically available)、软状态(soft state)和最终一致性(eventually consistent).
NoSQL模型主要有3类,即Key-Value模型、Key-Column模型、Key-Document模型.
4.1.1 Key-Value模型
Key-Value模型的主要思想主要来自于哈希表.Key-Value模型由一个键-值映射的字典构成.Key-Value不仅支持字符串类型,还支持字符串列表、无序(或有序)不重复的字符串集合、键-值哈希表.Key-Value通常将数据存储在内存中,从而提高运算速度.此外,Key-Value模型又可以细分为临时性和永久性两种类型.临时性Key-Value模型中所有操作都在内存中进行,这样做的好处是读取和写入的速度非常快,但一旦数据库实例关闭后,将会丢失所有数据.临时性 Key-Value模型的数据库通常作为高效缓存技术应用在高并发场景.而永久性Key-Value模型会将数据写入到硬盘上,这个过程中会造成I/O开销,导致性能较差,但数据不会丢失.
图14给出了一个Key-Value模型举例,其中,键k1对应的值value={11,22,33},键k2对应的值是一个字符串数组{Name:Jim,Tel:1234}.综上可以看出,Key-Value模型支持任意格式的值存储.
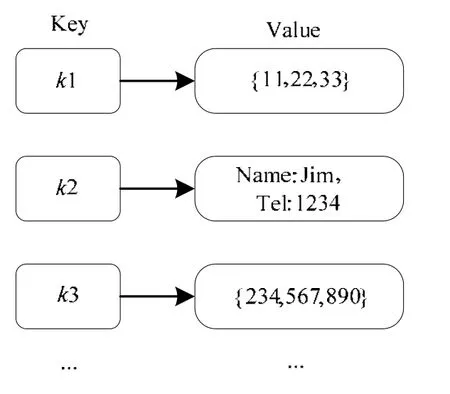
Fig.14 Key-Value model example图14 Key-Value模型举例
基于 Key-Value模型的数据库实例主要有 Memcached[74]、Redis[75]、LevelDB[76]等:Memcached是一个通用的分布式内存缓存系统,通常用于缓存数据和对象,以减少读取外部数据源(如数据库或API)的次数;Redis是一款开源内存数据库项目,实现了分布式内存键-值存储和可选持久性,提供字符串、列表、位图和空间索引;LevelDB是一个开源的Key-Value数据库,实现了快速读、写机制,并提供键-值之间的有序映射.
4.1.2 Key-Document模型
虽然Key-Document模型可以快速地访问数据,但当数据规模较大、无固定模式时,读写的效率会明显降低.Key-Document模型的核心思想是“数据用文档(如JSON)来表示”,JSON文档的灵活性使得Key-Document模型数据适合存储海量数据.
Key-Document模型如图15所示,Key-Document模型是“面向集合”的,即数据被分组存储在数据集中,这个数据集称为集合(collection).每个集合都有一个唯一标识,并且存储在集合中的文档没有数量限制.Key-Document模型中的集合类似于关系型数据库中的表结构.所不同的是,Key-Document模型中无需定义模式(schema).
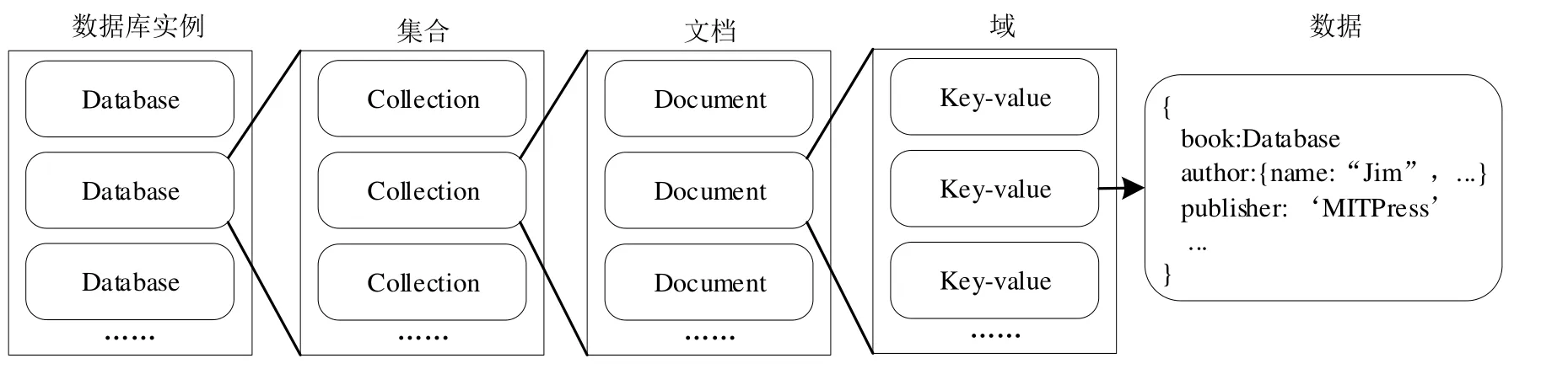
Fig.15 Key-Document model example图15 Key-Document模型举例
基于Key-Document模型的数据库实例主要有MongoDB[77]、CouchDB[78]等.MongoDB是开源的、跨平台、面向文档的数据库,使用JSON文档和模式存储数据.CouchDB是开源的、基于Key-Document模型的数据库,专注于易用性和可扩展的体系结构,它使用JSON来存储数据.
4.1.3 Key-Column模型
虽然Key-Value模型和Key-Document模型在特定的场景下得到了广泛的应用,但它们对范围查询、扫描等操作的效率较低.Key-Column模型是一个稀疏的、分布式的、持久化的多维排序图,并通过字典顺序来组织数据,支持动态扩展,以达到负载均衡.存储在Key-Column模型中的数据可以通过行键(row key)、列键(column键)和时间戳(timestamp)进行检索.其中,列族(column family)是最基本的访问单位,存放在相同列族下的数据拥有相同的列属性,并使用时间戳来索引不同版本的数据,以避免数据的版本冲突问题.同时,用户可以通过指定时间戳来获得不同版本的数据.
图16给出了通过Key-Column模型来存储网页的示例.
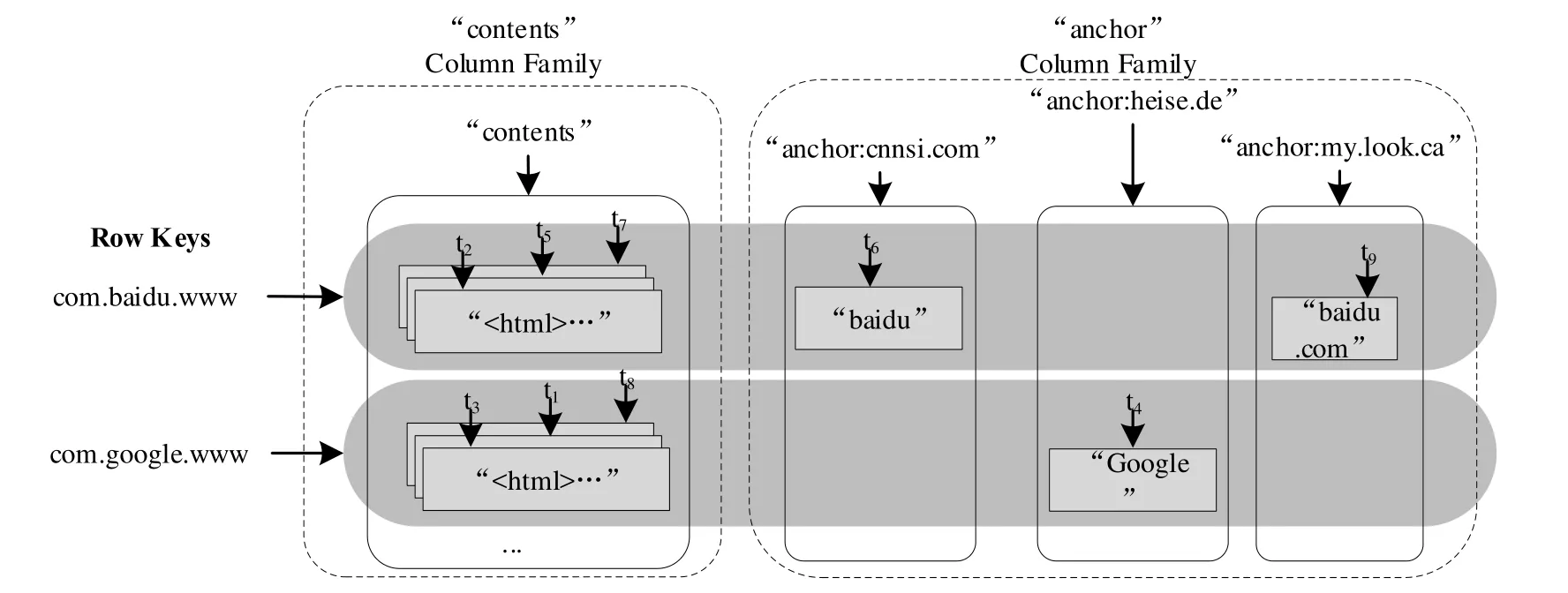
Fig.16 Key-Column model example图16 Key-Column模型举例
可以看出:不同于关系型数据库中的表结构,Key-Column模型中的表是一个“多维Map”结构.每个行都代表了一个对象,由一个行键,如“com.baidu.www”,和一个或多个列组成,如“contents”.相关的行键标识的行对象存储在相邻的位置.每个列由列族和列标示符组成,并用“:”隔开,例如 anchor:cnnsi.com.单元格是行、列族和列标识符的组合,并且包含了一个值和一个时间戳来标示数据的版本,如t2.
基于 Key-Column模型的数据库实例主要有 BigTable[79]、HBase[80]、Cassandra[81]等:BigTable是 Google公司推出的一种高扩展性的分布式数据库,提供列压缩等功能,被用于存储海量数据;HBase是BigTable的开源实现,提供了压缩算法、内存操作和布鲁姆过滤器等功能;Cassandra最初是由 Facebook开发的一款开源的Key-Column模型数据库,支持海量数据的读、写,拥有较高的可扩展性,并提供类SQL语言来操作数据.
4.2 NewSQL模型
NewSQL被称作“下一代可扩展关系型数据库”,为传统数据库系统提供了接近 NoSQL的处理性能,使用SQL语言作为应用之间交互的主要机制,并且遵循ACID特性[82,83].值得一提的是:NewSQL并没有提出新的数据模型,而是将传统的关系型模型和NoSQL模型的优点相结合.NewSQL使用“无锁”的并发控制机制,使得应用程序在实时读取数据时不会被阻塞.此外,部署了NewSQL的分布式集群中的每个节点都可以处理请求,从而提高了效率,且高于传统RDBMS解决方案.NewSQL使用了无共享的架构,可以方便地部署在海量节点中,并提供了良好的水平扩展性,从而使得系统不受性能瓶颈的影响[84,85].
为了更好地比较RDBMS、NoSQL和NewSQL的特点,表1从不同的角度分析了三者之间的优劣.通过比较结果可以看出:NewSQL结合了传统关系型数据库和 NoSQL数据库的优点,提供了管理海量数据的新方法,这也是未来的一个重要研究方向.

Table 1 Comparison of RDBMS,NoSQL,and NewSQL features表1 RDBMS、NoSQL和NewSQL特点比较
基于NewSQL模型的数据库主要有H-Store[86]、S-Store[87]、Spanner[88]、VoltDB[89]等:H-Store是一款内存并行数据库管理系统,是一个高度分布的基于行存储的关系数据库,运行在无共享的群集上;S-Store是一个全球化的流式 OLTP引擎,将在线事务处理和实时数据流处理相结合,并支持事务的 ACID特性和事务的有序性;Spanner是Google公司推出的全球化的基于BigTable模型的NewSQL数据库,在原有BigTable模型的基础上实现了事务的ACID特性;VoltDB是一个横向可扩展的NewSQL关系数据库,支持SQL访问和事务的ACID特性,并基于连续快照和命令日志记录的组合实现数据持久性.
5 数据库实例的分析与比较
本节选取每个模型的典型实例分析特点[90],并通过实验对比了大数据模型实例的效率.
5.1 结构化模型
在结构化模型中,选取开源关系型数据库实例(MySQL和 PostgreSQL)和商业型关系型数据库(Oracle和SQL Server)作为分析对象.
表2给出了开源的关系型数据库MySQL和PostgreSQL的分析结果:相比于MySQL,PostgreSQL允许对象模型的存储,具有良好的可扩展性,可扩展到多节点中进行部署;而 MySQL不支持物化视图和对象存储.这两种数据库都支持GUI接口,都支持多种操作系统环境,也都提供临时表.
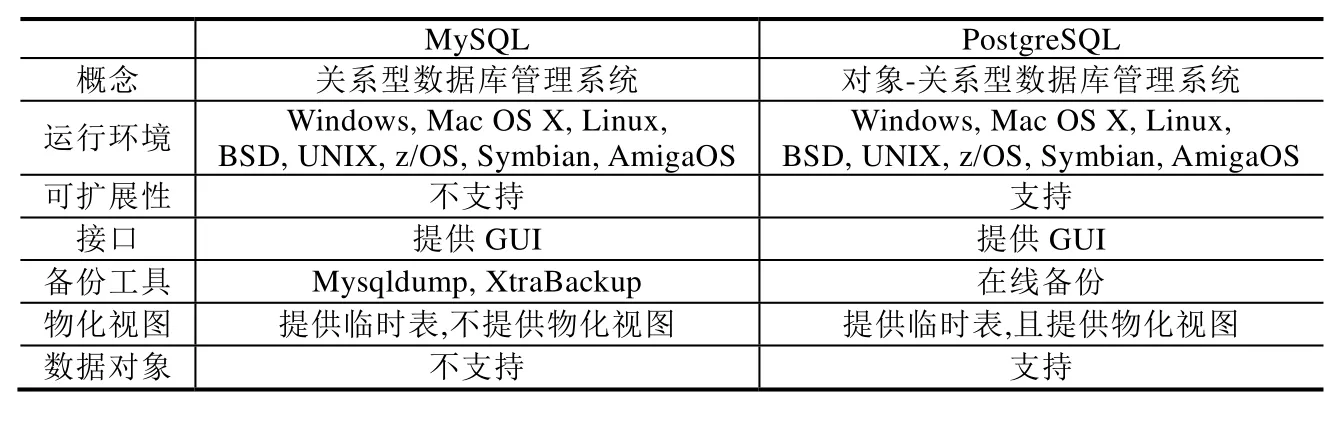
Table 2 Comparison between MySQL and PostgreSQL表2 MySQL和PostgreSQL对比
表3给出了商业的关系型数据库Oracle和SQL Server的分析结果.
· 首先,这两种关系型数据库所使用的查询语言不同.Oracle使用PL/SQL,SQL Server使用T-SQL;
· 其次,这两种关系型数据库中的事务提交方式不同.在 Oracle中,事务的提交依赖于管理员(DBA)发出Commit命令,如果没有Commit命令,则事务无法提交;而在SQL Server中,即使没有确切的Commit命令,事务中的命令也可以被独立地运行;
· 在 Oracle中,所有的数据库在用户之间是共享的,Oracle通过权限管理来限制用户的访问权限;而在SQL Server中,数据库是私有的,无法在多个用户之间共享;
· Oracle支持多种操作系统;而SQL Server只能运行在Windows或Linux上,通用性较差.
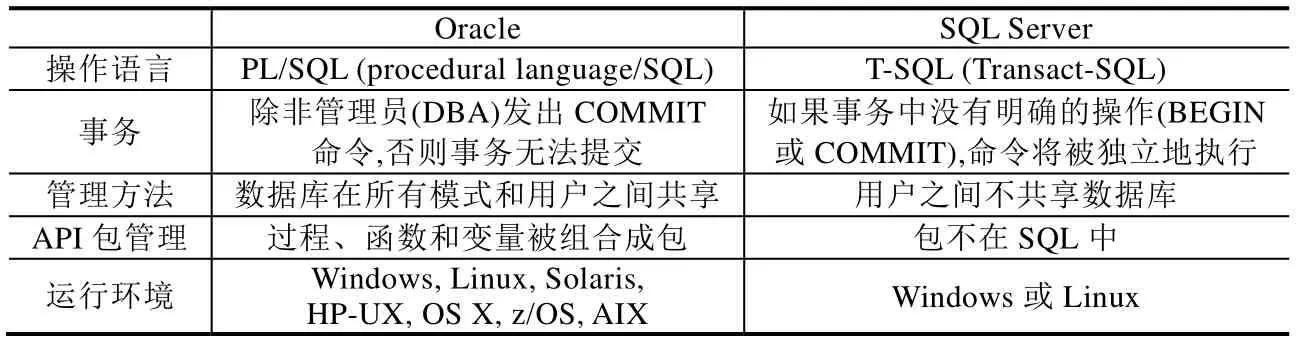
Table 3 Comparison of Oracle and SQL Server表3 Oracle和SQL Server对比
5.2 半结构化模型
在半结构化模型中,选取XML模型实例(MarkLogic和BaseX)和图模型实例(Neo4j和HyperGraphDB)作为分析对象,结果见表4.如前所述,由于JSON模型常用于大数据的存储,这里没有给出JSON模型实例分析结果.
在XML模型实例分析中,MarkLogic支持SQL查询语言,支持数据划分策略并提供数据副本存储方法.在这些方面要优于BaseX;同时,在MarkLogic中的事务支持ACID特性,而在BaseX中支持并发读数据,但支持单进程写数据;最后,MarkLogic对内存计算有良好的支持,并提供范围索引.
在图模型实例分析中,Neo4j不支持SQL查询语言,而HyperGraphDB支持SparQL.Neo4j没有提供数据划分策略,而HyperGraphDB支持数据分布到多个节点组成的联盟中.这两种图模型数据库中的事务都遵循ACID特性.最后,HyperGraphDB提供良好的内存计算能力.
此外,通过比较结果可以看出,这 4种半结构化模型实例都支持二级索引和触发器,同时支持并发操作和数据持久.
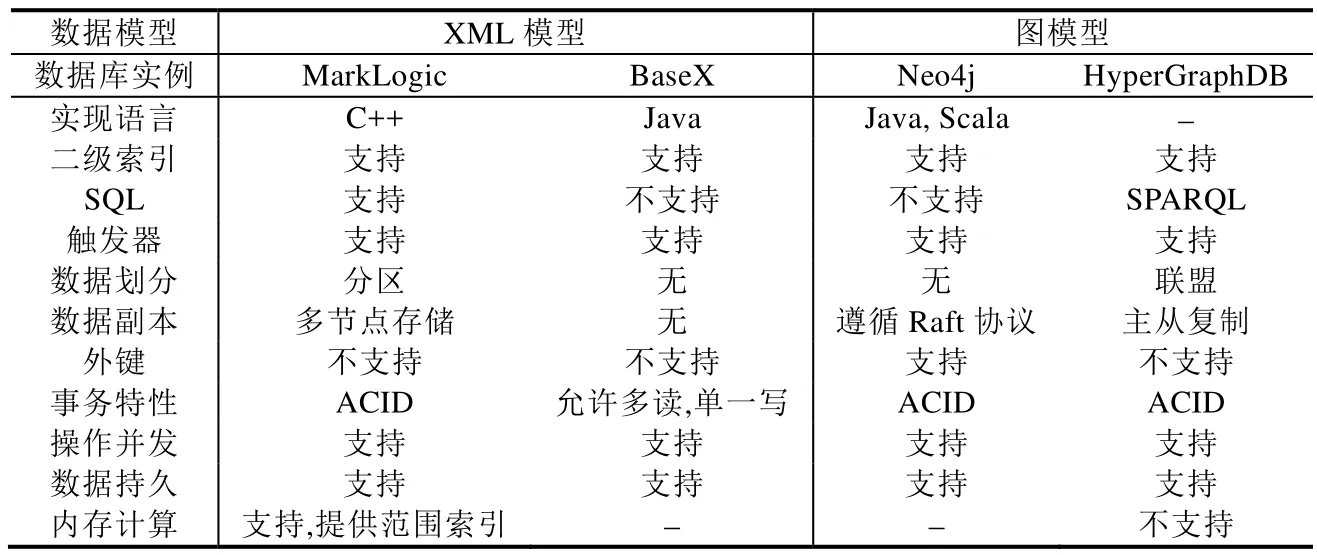
Table 4 Semi-Structured database instance comparison表4 半结构化数据库实例对比
5.3 OLAP模型
在OLAP模型中,选取ROLAP模型实例(PivotTable)和MOLAP模型实例(Hyperion)进行分析,结果见表5.可以看出:PivotTable系统比 Hyperion系统占用的存储空间要小,但 PivotTable查询速度较慢.因此,一个新的OLAP结构 HOLAP被提了出来.但是迄今为止,对 HOLAP还没有一个正式的定义,HOLAP不是 MOLAP与ROLAP结构的简单组合,而是这两种结构技术优点的有机结合,可满足用户各种复杂的分析请求.HOLAP的优越性就在于它能将ROLAP和MOLAP相互取长补短,充分利用ROLAP的灵活性和数据存储能力以及MOLAP的多维性和高效率.不同OLAP应用的优化目标也不同,有的应用优先考虑效率和相应时间,那么MOLAP的比重就应该加大,常用汇总数据都应该采用多维数据库来存储,有的应用对存储容量的要求较高,那么就应该充分利用关系数据库的存储能力,把大部分统计数据用ROLAP的模式来存储.

Table 5 Comparison between PivotTable and Hyperion表5 PivotTable和Hyperion对比
5.4 大数据模型
在大数据模型中,选取了 Key-Value模型实例(Redis、Memcached和 LevelDB)、Key-Document模型实例(MongoDB、DynamoDB和CouchDB)、Key-Column模型实例(HBase和Cassandra)进行分析.结果见表6.
通过比较结果可以看出:Key-Value模型实例不支持二级索引、SQL、触发器、外键等传统关系型数据库的操作;Redis支持事务操作、数据划分和数据副本存储策略;这3种Key-Value模型实例都支持内存计算,从而获得更快的执行效率.
在3种Key-Document模型实例中,都支持二级索引技术、数据分区、操作并发和数据持久,但都不支持事务操作、SQL查询语言和外键.DynamoDB和CouchDB支持触发器.MongoDB和CouchDB提供数据副本策略.MongoDB支持内存计算.
在两种Key-Column模型实例中,都支持触发器、数据划分、数据副本存储、操作并发和数据持久,都不支持外键、事务操作和内存计算.Cassandra支持二级索引,并提供类SQL查询语言(CQL).
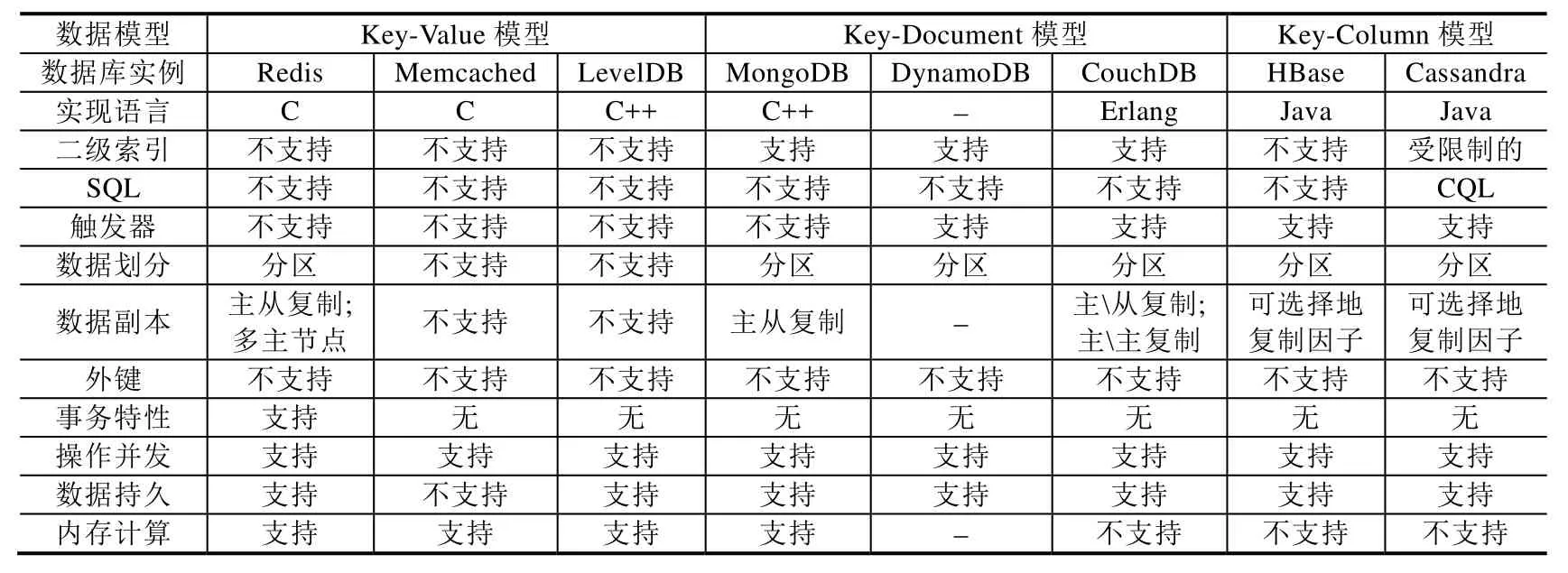
Table 6 NoSQL database instance comparison表6 NoSQL数据库实例对比
6 总 结
在数据库领域,数据模型用于表达现实世界中的对象,也就是将现实世界中杂乱的信息用一种规范而形象化的方式表达出来.经过近半个世纪的发展,数据模型形成了坚实的理论基础和广泛的应用领域.本文综述了结构化模型、半结构化模型、OLAP分析模型和大数据模型这4种数据模型的概念、特点和国际上的主要研究进展,并选取每个模型的典型数据库系统进行了性能的分析.
结构化模型在20世纪60年代中后期被最早提出,包括了层次模型、网状模型、关系模型和面向对象模型等,主要应用有MySQL、PostgreSQL、Oracle和SQL Server等:PostgreSQL允许对象模型的存储,比MySQL具有更为良好的可扩展性;Oracle支持多种操作系统,而SQL Server只能运行在Windows或Linux上,通用性较差.20世纪 90代末期,随着互联网应用和科学计算等复杂应用的快速发展,开始出现半结构化模型,包括 XML模型、JSON模型和图模型等.主要的应用有MarkLogic、BaseX、Neo4J和HyperGraphDB等:MarkLogic相较于BaseX支持SQL查询语言,支持数据划分策略并提供数据副本存储方法;而HyperGraphDB支持SQL,比Neo4J内存计算能力更强.21世纪,随着电子商务、商业智能等应用的不断发展,数据分析模型成为研究热点,出现了基于ROLAP模型的实例PivotTable和基于MOLAP模型的实例Hyperion:PivotTable比Hyperion占用存储空间更小,但PivotTable查询速度较慢.2010年以来,随着大数据工业应用的快速发展,以NoSQL和NewSQL数据库系统为代表的大数据模型成为新的研究热点,主要应用实例有:基于 Key-Value模型的 Redis、Memcached和LevelDB;基于 Key-Document模型实例的 MongoDB、DynamoDB和 CouchDB;基于 Key-Column模型实例的HBase和Cassandra等.
目前,NewSQL一直在尝试解决摆脱人工运维束缚,在存储层实现真正的自生长、自维护,同时实现用户可以用最自然的编程接口访问和存储数据等问题.解决这些问题以后,NewSQL就可以摆脱存储的介质及容量的限制.在未来,NewSQL将作为“下一代可扩展关系型数据库”,成为数据库主要的研究方向之一.
