采用划分融合双向控制的粒度支持向量机
2019-02-27赵帅群郭虎升王文剑
赵帅群,郭虎升,,王文剑
(1.山西大学 计算机与信息技术学院,山西 太原 030006; 2.山西大学 计算智能与中文信息处理重点实验室,山西 太原 030006)
支持向量机(support vector machine,SVM)是由Vapnik 等[1]提出的基于统计学习理论和结构风险最小化准则的一种学习策略,在小样本多维度的数据分类和回归问题方面表现出了优良的泛化性能,广泛应用于机器学习、模式识别、模式分类、图像处理等领域[2-8]。目前在大规模数据处理方面,SVM 仍存在一些不足。主要问题是当样本数n较大时,会消耗大量的内存空间和运算时间,严重降低了SVM 的学习效率,限制了SVM 在大规模数据集上的应用。
粒度支持向量机的含义最早由Tang 等[9]提出,其主要思想是首先构建粒度空间获得一系列信息粒,然后在每个信息粒上进行SVM 学习,最后聚合信息粒上的信息获得最终的决策函数。依据粒划分方式的不同,衍生出了基于聚类的GSVM、基于分类的GSVM 以及基于关联规则的GSVM 等方法[10-19]。GSVM 采用粒化的方式压缩数据集的规模,以提高SVM 的学习效率,而目前的GSVM 大都在静态层级进行划分,即只对信息粒进行有限次的浅层次划分,丢失了大量对分类起关键作用的样本信息,且冗余信息较多,降低了模型的性能。尽管已经提出的动态粒度支持向量机(dynamic granular support vector machine,DGSVM)[20],以及动态支持向量回归机(dynamic granular support vector regression,DGSVR)[21],采用动态的方式对重要信息粒深层次划分,对无关信息粒则进行浅层次划分,但DGSVM 随着粒划分过程会使数据规模不断增加,使得SVM 的效率有所降低。
为了进一步提升SVM 在大规模数据集上的应用能力,本文提出了采用划分融合双向控制的粒度支持向量机方法。在SVM 分类过程中,对分类起关键重要的信息分布于超平面附近,称为强信息区,超平面远端的信息对分类影响较小,称为弱信息区,本文提出的方法通过对强信息区的强信息粒进行深度划分,同时融合弱信息区的弱信息粒,使训练数据始终动态保持在较小规模。该方法分为两个阶段,首先通过聚类算法对原始数据集进行初始粒划分,挑选粒中代表信息组成新的训练集训练得到初始分类超平面,然后通过迭代划分融合的方式深度划分强信息粒,同时融合远端弱信息粒。实验表明,该方法能够在保证模型精度的条件下显著提升SVM 的学习效率。
1 粒度支持向量机
粒度支持向量机引入粒计算的概念,对复杂问题进行抽象和简化,以较低的代价来得到问题的满意近似解。在多种的粒划分方式中,基于聚类的粒度支持向量机(clustering-based granular support vector machine, CGSVM)是当前研究的热点之一[22-25]。CGSVM 通过聚类算法将大规模数据集分解成多个小规模数据簇,簇内信息具有高度相似性,而簇间信息相似度较低,挑选出每个簇中具有代表性的样本信息作为新的训练样本,整合所有挑选出的样本训练得到新的模型。
CGSVM 只采用了少量代表样本作为训练集,有效地加速了SVM 学习过程。但CGSVM 本身也存在一些不足,在SVM 学习过程中,距离分类超平面较近的信息对分类起关键作用,而距离超平面较远的信息几乎不影响模型训练过程。CGSVM 在数据处理过程中没有区分不同信息粒对分类的影响程度,对所有信息粒都进行同等层次的划分,导致对重要信息提取不足且仍存在过多的冗余信息。如图1 中,距离超平面较近的中包含较多支持向量信息,对分类起到了关键作用,距离超平面较远的对分类影响较小。尽管DGSVM 通过对超平面附近重要信息粒深度划分,但远端的冗余信息仍然被保留,在动态划分过程中数据规模会不断增加,导致训练时间也不断地提高。
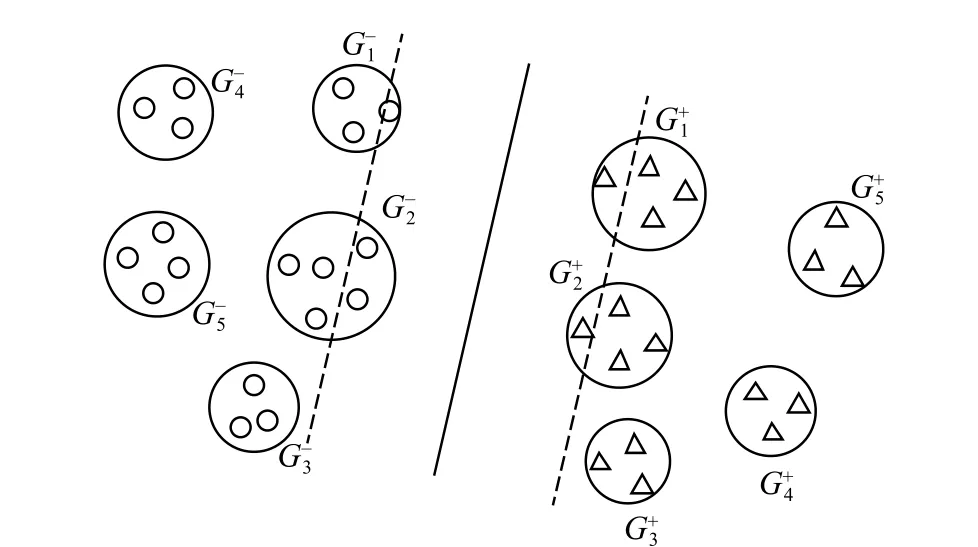
图1 CGSVM 粒度划分Fig.1 CGSVM granular division
2 DFSVM 模型
现阶段CGSVM 通过静态的、浅层次的方式,对粒划后的信息粒进行无差别的信息提取,导致对分类起关键作用的信息提取不足且还保留了大量对分类影响较小的冗余信息。本文提出的方法采用多层次的划分策略,由于超平面附近的样本信息有较大概率成为支持向量,距离超平面较远的样本信息对分类几乎没有影响,因此,DFS-
VM 采取动态迭代划分的方式,对超平面附近可能成为支持向量的信息粒深度划分,同时融合距离超平面较远的冗余信息,不断更新超平面以获得更多潜在有效的分类信息,该方法能够将训练集始终固定在一个较小的规模,加速了SVM 的训练过程。
2.1 初始粒划分
给定原始数据集D={X,y}={(x1,y1),(x2,y2), ···,(xe,ye)},ye∈{1,-1},xe∈Rl,DFSVM 首先通过聚类算法将数据集中的正类与负类样本分别划分为k个粒,通过初始粒划分方式得到新的信息粒集:
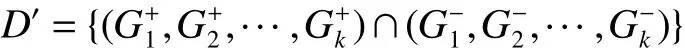
式中:Gk表示通过划分得到的信息粒。SVM 通过核函数K(x,y)=φ(x)φ(y) 将数据映射到N维核空间,将数据集经过初次划分在N维空间形成的粒称为超粒,第i个超粒的中心ui和半径 γi为
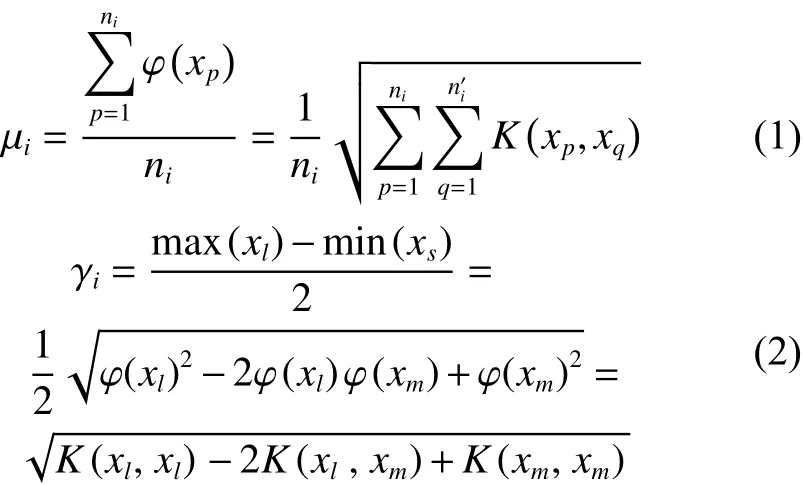
式中: φ (xl) 和 φ (xm) 代表核空间上下边界,超粒半径通过其平均值衡量,样本 φ(xs) 到任意超粒Gi中心 µi的距离可表示为
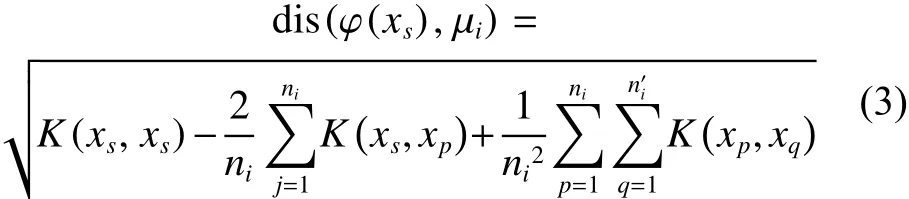
通过初始粒划分将原始数据集划分为G1、G2、 · ··Gk个粒,提取每个粒中的代表信息以训练获得初始分类超平面。
2.2 动态划分融合方法
通过初始粒划过程获得超平面y=WT·φ(x) +b,在SVM 模型分类过程中,对分类起关键作用的样本信息主要分布在最大间隔内部以及间隔线附近,该区域的样本在模型训练过程中会被多次遍历,而位于超平面相对较远的样本无需过多的遍历即可将其分类正确。因此,基于以上条件将样本划分为强信息区与弱信息区。给出两个参数β+和 β-, 其中 β+>β-。当样本与超平面之间的距离满足D′≤ γ/2+β-时,样本点对分类超平面具有重要影响,划分为强信息区。同理,样本与超平面之间的距离D′≥γ/2+β+时,认为样本点对分类超平面影响较小,划分为弱信息区。其中 β-可在0 至 γ /2 之间选取, β+可在 γ /2 至 γ 间选取。强信息区的信息有较大可能在迭代融合划分过程中成为支持向量,弱信息区的数据则对分类影响较小,对强信息粒区域采用划分方式提取分类信息,对弱信息区采用融合方式减少冗余信息。其中,超平面最大间隔 γ 为

针对每个划分好的信息粒,选择中心点 µi作为代表点计算该粒到超平面之间的距离,公式如下:
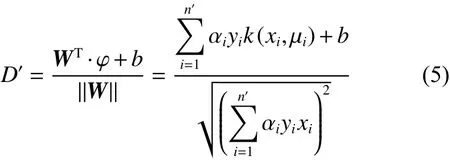
动态划分过程通过衡量粒与超平面之间距离来选取候选粒进行深度划分。但由于不同粒的大小、粒内部数据分布等差异,密度较大的粒中信息分布集中、重叠度大,含有更多潜在成为支持向量的信息;密度较小的粒中信息分布稀疏,包含的支持向量信息少。因此,对超平面附近密度较大的信息粒优先选择在当前迭代过程中划分,密度相对较小的信息粒可能成为后续划分过程中的候选粒。为了衡量每个粒的差异程度,给出粒密度的定义:
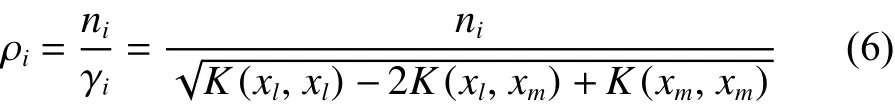
式中:ni为第i个粒 中 的 样本数; γi为第i个粒的半径。
图2 表示DFSVM 动态粒划过程,其中G1+、G2-被选为当前最优分类信息粒,G1+被划分为Gd1+、Gd2+,G2-被划分为Gd1-、Gd2-。同时将G4-和G5-融合为Gm-,G4+和G5+融合为Gm+
2.3 DFSVM 算法
DFSVM 模型的数据处理过程分为两个阶段:1) 对原始数据进行初始粒划分,然后通过式(1)计算得到每个粒的粒心,将所有粒心作为训练集训练得到初始分类超平面;2)利用动态划分融合的思想,对信息粒不断迭代处理以获得最优分类超平面。首先通过式(4)与参数 β+、 β-划分强信息区与弱信息区,利用式(5)、(6)计算这两个区域内每个粒与超平面的距离和自身的粒密度,挑选强信息区距超平面较近且粒密度大的粒在当前迭代过程进行划分,挑选弱信息区距超平面较远且粒密度小的粒在当前迭代过程进行融合,用划分后的超粒代替原始超粒。在该方式下,数据规模能够保持在较低水平,SVM 的学习效率也得到有效的提升。
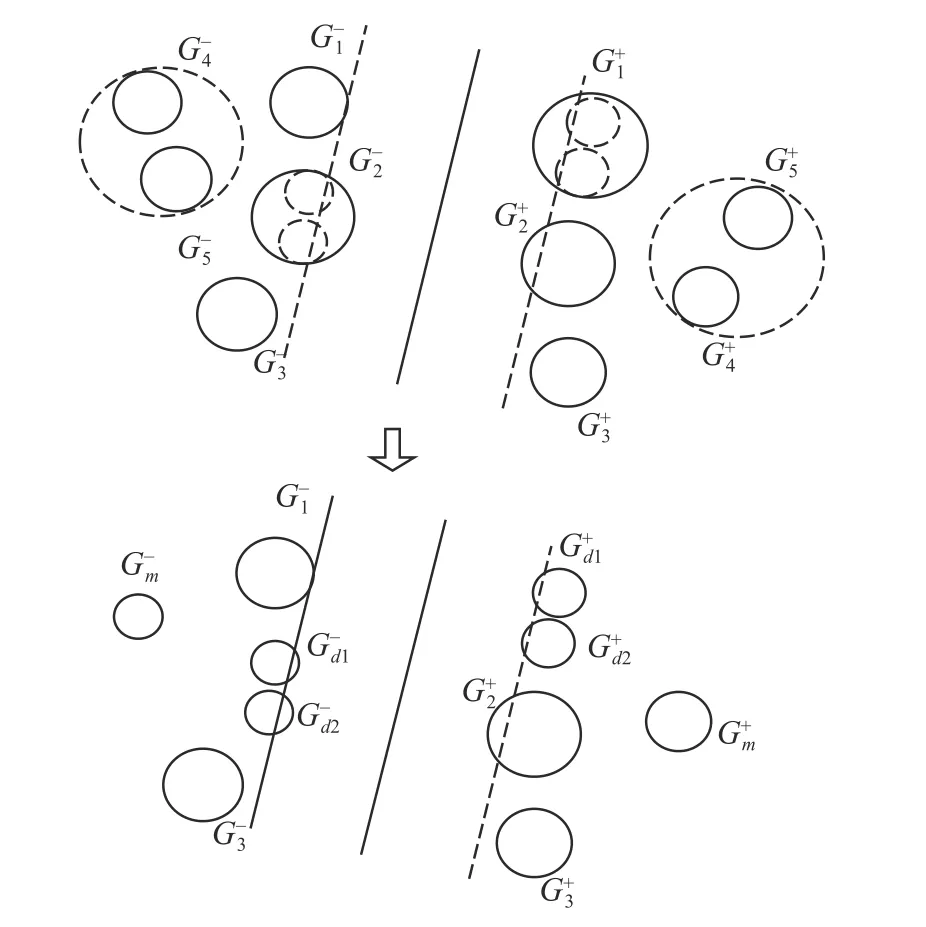
图2 动态划分融合过程Fig.2 Dynamic division and fusion process
本文提出的DFSVM 针对传统SVM 无法高效的处理大规模数据以及CGSVM 静态划分的不足进行了改进,探讨的目标是DFSVM 是否能够在保证精度损失较少的情况下有效提升SVM 的学习效率。本文在不同的参数下做了大量实验,基本算法描述如下:
算法采用划分融合双向控制的粒度支持向量机
输入原始数据集D,初始粒化参数k,动态粒化参数m,迭代粒化参数d,停止条件t(预先设定的模型迭代次数);
输出划分融合过程得到的模型测试结果集。
1)用聚类算法将数据集D中每一类划分为k个粒G1,G2,···,Gk;
2)将划分后的每个粒中心加入到训练集中训练得到初始分类超平面f′;
3)通过式(4)和式(6)计算强信息区的信息粒与超平面的距离Di以及粒密度 ρi,挑选当前需要划分的d个信息粒,并将这些信息粒分别深度划分为m个子粒;
4)通过式(4)和式(6)计算弱信息区信息粒、超平面的距离Di与粒密度 ρi,挑选出当前需要融合的d×m个弱信息粒;
5)将更新后的信息粒代替原信息加入到训练集并更新分类超平面,同时记录模型测试结果;
6)重复4)~6),直到满足停止条件t;
7)记录模型结果集,算法结束。
传统SVM 模型训练的时间复杂度和空间复杂度分别为o(n3) 和o(n2), 其中n为数据的规模。SVM 在模型训练过程中,需要存储和计算大规模的核矩阵,随着数据规模的增长,效率会大大降低。DFSVM 算法采用动态划分融合双向控制的方式对数据集进行迭代划分,始终将训练集维持在较小的规模,提高了模型的学习效率。尽管DFSVM 在划分过程中会多次训练超平面,但训练总耗时仍然较少,并进一步改进了CGSVM 静态单层划分对重要信息提取不足的缺点,针对于强信息粒进行信息提取,同时融合冗余的弱信息粒,降低训练规模的同时提升CGSVM 的训练精度。DFSVM 模型在保证较高分类精度的条件下,有效地提升了模型的学习效率。
3 实验和分析
3.1 实验数据集
本文实验在多个UCI 数据集和标准数据集上进行实验,见表1,SVM 选用高斯核函数,在多种参数下进行实验。实验在一台CPU 为2.50 GHz,内存8 GB 计算机上运行,实验平台为Matlab2016a。
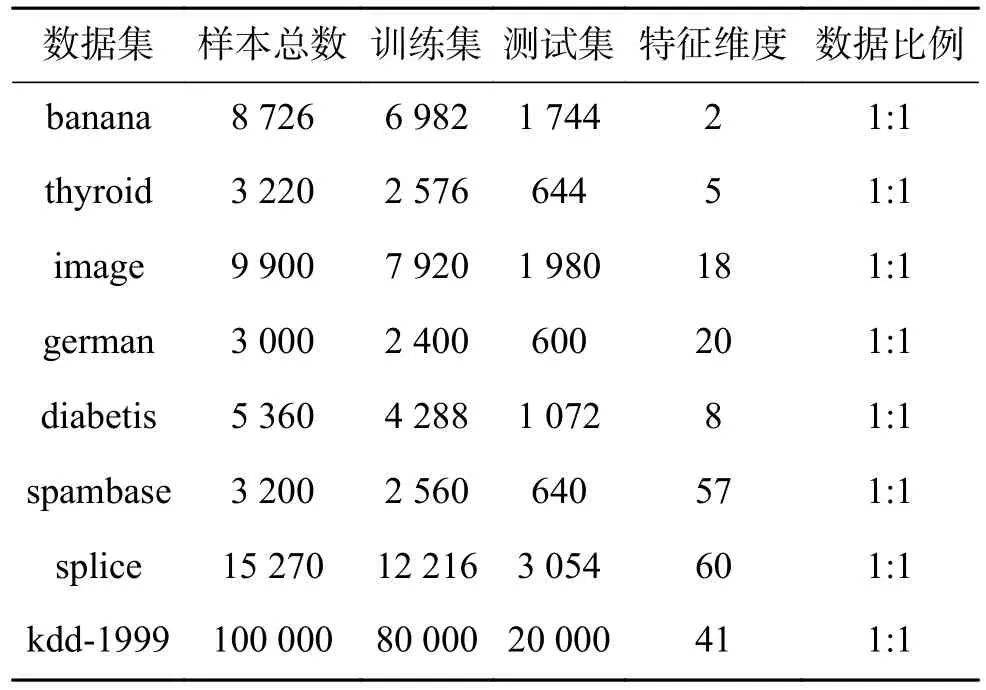
表1 实验数据集Table 1 Experimental data sets
3.2 动态粒划分结果分析
本文提出的采用划分融合双向控制的粒度支持向量机模型,在粒划分过程中逐步提取潜在的支持向量信息,通过信息融合清除掉过多的冗余信息,提升SVM 的学习效率。本小节实验验证DFSVM粒划分融合过程中对SVM 泛化能力的影响。
由于初始参数k决定了动态划分融合阶段的数据规模,k值过小会导致学习性能的下降,过大会增加时间消耗,因此对于不同数据集需要选择合适的参数值,在3.4.3 节中有相关参数讨论。为了尽可能观测粒划过程中预测准确率的变化,本节实验设定迭代粒划参数d=1, 动态粒化参数m=2,既每次将一个强信息粒划分为2 个子粒,同时将远端的两个弱信息粒进行融合,图中初始结果即为CGSVM 结果,SVM 惩罚因子c=1,高斯核参数g=1/k′(k′为特征数)。
从图3 中可以看出,在对数据集迭代划分融合过程中,SVM 的分类准确率逐步提高,但不同数据集的变化情况也存在差异。
实验结果表明本文提出的方法能够充分提取数据集中的关键信息,有效地提升了模型的学习效率。在有限次的数据处理过程中,数据分布增强了对SVM 的适应性,但随着划分次数增加,数据分布的改变可能导致SVM 过拟合化,降低模型性能,如spambase 数据显示出迭代次数大于20 时,准确率有明显下降趋势。实验表明采用划分融合双向控制的粒度划分方法在一定程度上具有普适性。

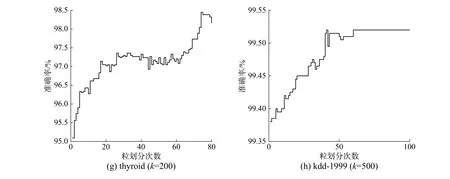
图3 粒划分过程中精度变化Fig.3 Accuracy change during granules division process
3.3 模型精度与时间结果分析
针对在迭代过程中模型预测准确率和时间变化与传统SVM、CGSVM、DGSVM 进行对比,参数选取与4.2 节中实验相同,DGSVM 平均每次划分数据增量为4,图4 为时间对比图,图5 为准确率对比图。
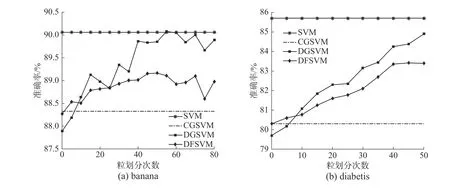
图4 中的实验结果表明,随着迭代次数的增加,DGSVM 的训练时间增加率快于DFSVM。实验在german、thyroid、spambase 数据集上的预测准确率没有在有效粒划次数内达到最优,在其他数据集上都达到了最优值。图5 中结果表明DGSVM的精度达到的峰值要高于DFSVM,但时间消耗上要接近DFSVM 的两倍,且高于传统SVM 的训练时间。DGSVM 与DFSVM 在传统SVM 基础上通过数据压缩的方式降低了数据规模,提升了模型效率,而迭代次数会影响DGSVM 与DFSVM 的学习效率。DFSVM 通过划分融合的方式动态保持了数据规模的稳定,而DGSVM 的数据规模在划分的过程中不断增大,导致训练时间增加。DFSVM 在时间上有明显的提升,与DGSVM 相比仍然损失了一些精度。
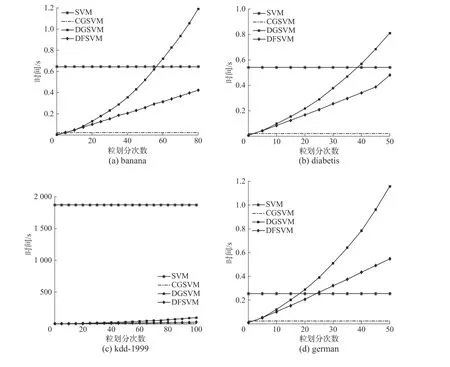
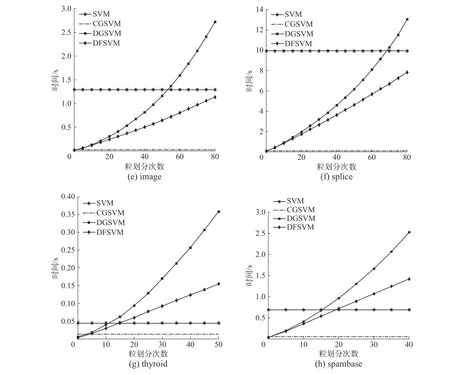
图4 不同方法模型训练时间对比Fig.4 Comparison of model training time on different methods
3.4 参数对DFSVM 的影响
3.4.1 迭代参数与粒划分参数分析
DFSVM 迭代过程中参数d控制每次划分的粒数目,参数m控制每个粒进行深度划分的数目,其他参数与3.2 节中设置相同。实验中准确率、时间和迭代次数分别采用模型训练结果达到稳定时的平均水平进行对比,见表2,其中acc 表示模型准确率,t表示所用时间,h表示动态迭代划分次数。
由表2 中数据可以看出,随着参数d、m的增大,每次参与划分和融合的数据增多,模型能够在较少的迭代次数内收敛到最优值。由于数据集规模与分布的不同,结果存在一定的差异,预测结果波动范围较小,表明参数d、m在取值较大时能够降低算法迭代次数,有效缩短模型训练时间。
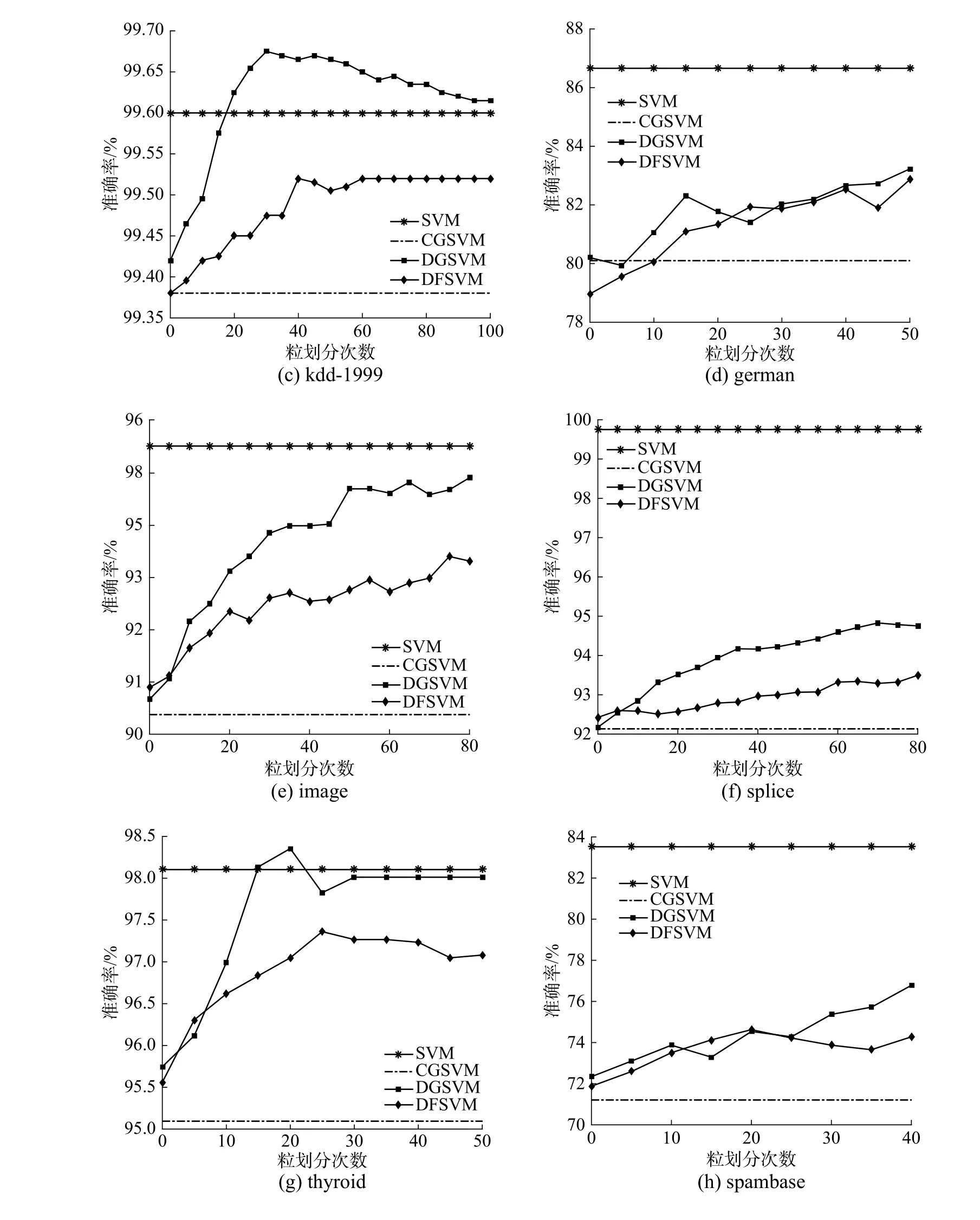
图5 不同方法测试精度对比Fig.5 Accuracy comparison on different methods
3.4.2 SVM 模型参数分析
本实验中主要调节SVM 中参数惩罚因子c以及高斯核参数g。实验选取不同c、g参数值进行实验,讨论惩罚因子及核参数对实验结果的影响,其余参数与3.2 节中设置相同,模型预测结果见图6,c、g参数取值见表3。如图6,参数c、g的变化影响数据的最优性能,所有数据集都能够通过惩罚参数和核参数的调节来提高DFSVM 的性能,而且大部分数据集在迭代过程中都表现出较好的稳定性,thyroid、spambase 数据集出现了一些离群点,但不影响总体结果。
3.4.3 初始聚类参数k
动态划分首先要通过初始聚类参数k对数据进行压缩,压缩过小会因欠拟合而降低模型精度,压缩过大则可能造成数据冗余而降低模型效率,因此,本节实验选取不同的参数k进行了实验分析,其他参数与3.2 节中设置相同,测试结果见图7。
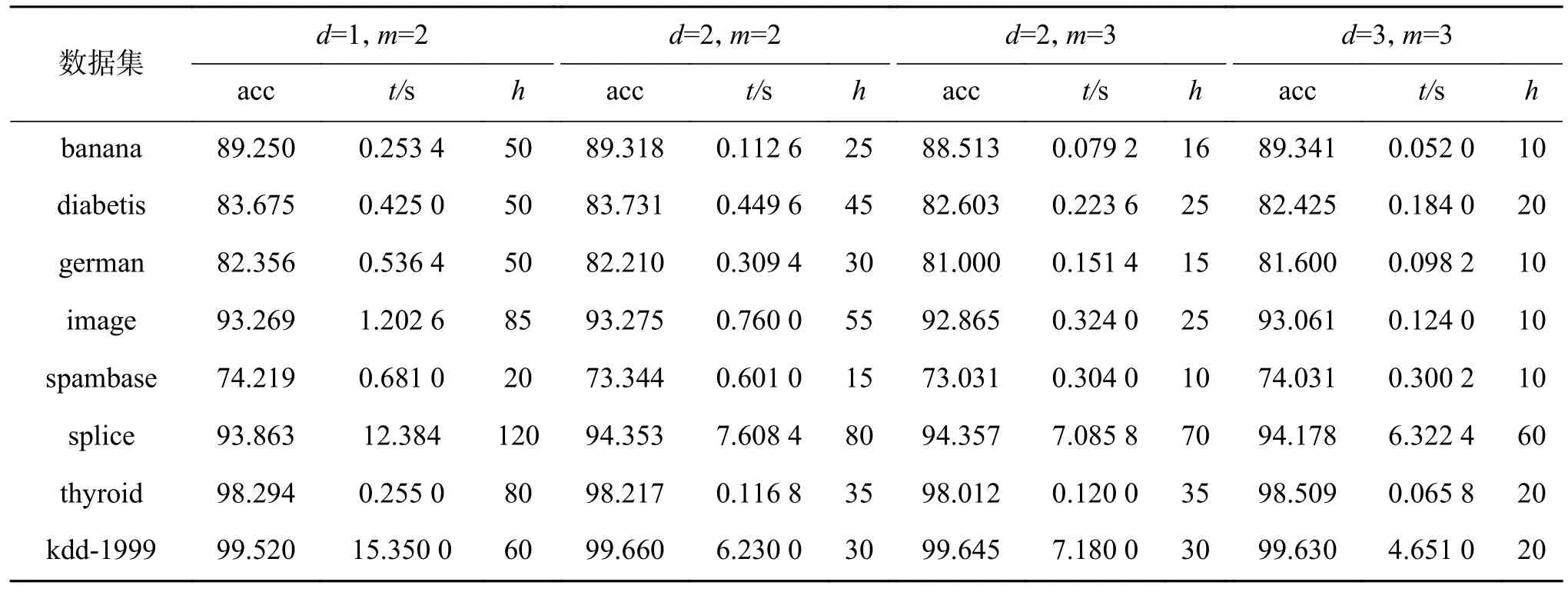
表2 迭代参数 d 与粒划参数 m 实验结果Table 2 The result on iteration parameter d and dividing parameter m
由于不同数据集规模和分布差异,参数k的选取也不同。从图7 中可以看出,k值在一定范围内增加会使模型准确率有所提升,在splice 和german 数据结果中,不同的参数k对应的曲线具有明显差异性,但对于diabetis 和image 数据集,参数k存在相对最优值,即k高于某一值后对模型结果提升不明显。当k值较小时,甚至会显著降低模型性能,如german 数据集在k取100 时,结果变差。实验表明,k值的选取对模型结果有一定的影响。
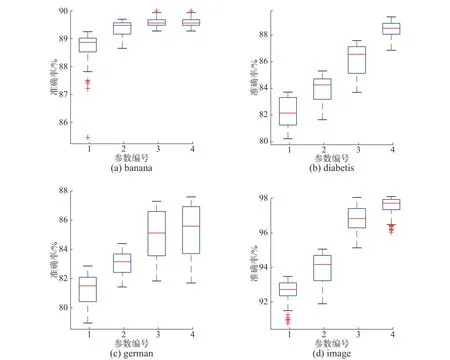
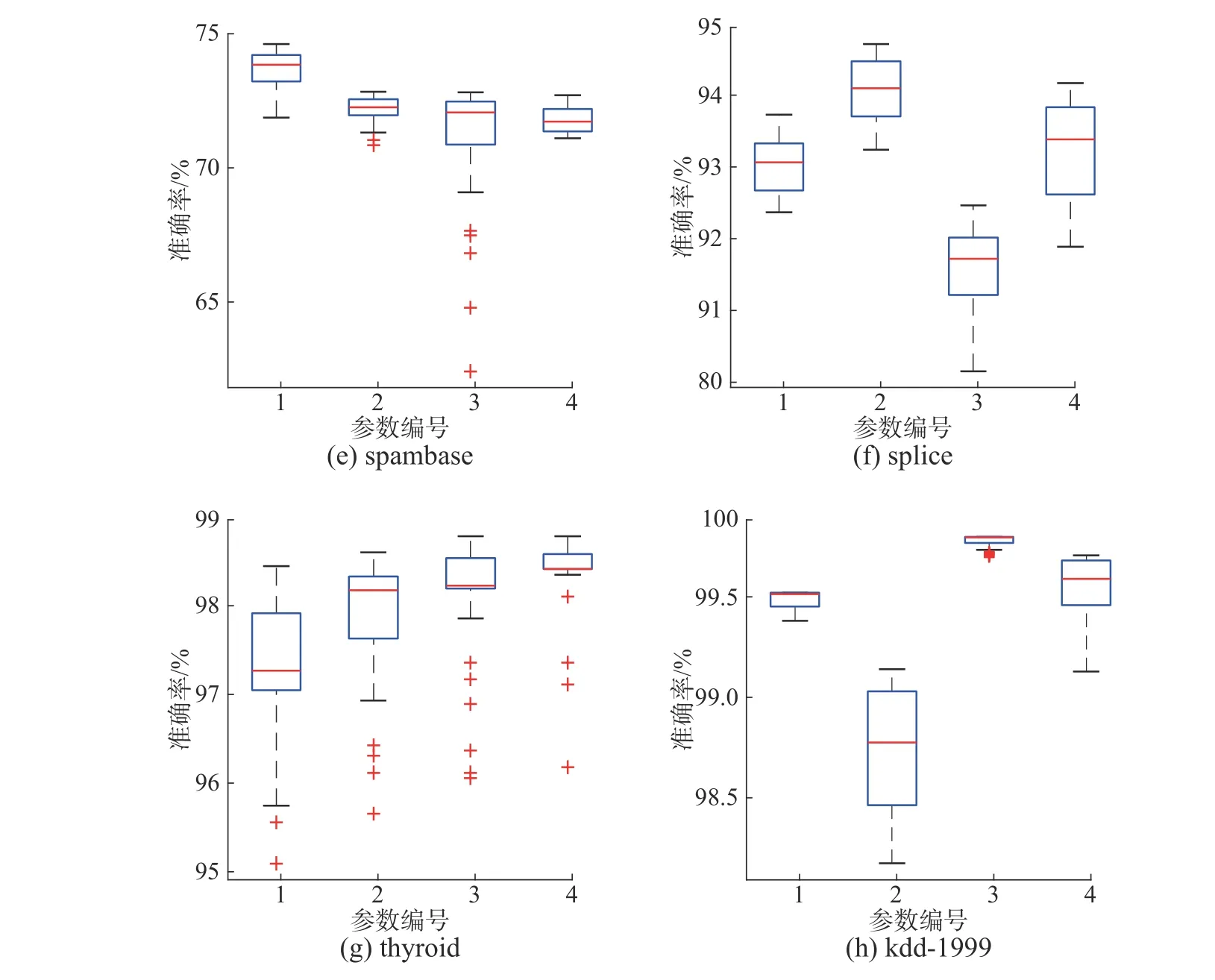
图6 惩罚因子 c 与高斯核参数 g 的影响Fig.6 The effect of cost parameter c and RBF kernel parameterg
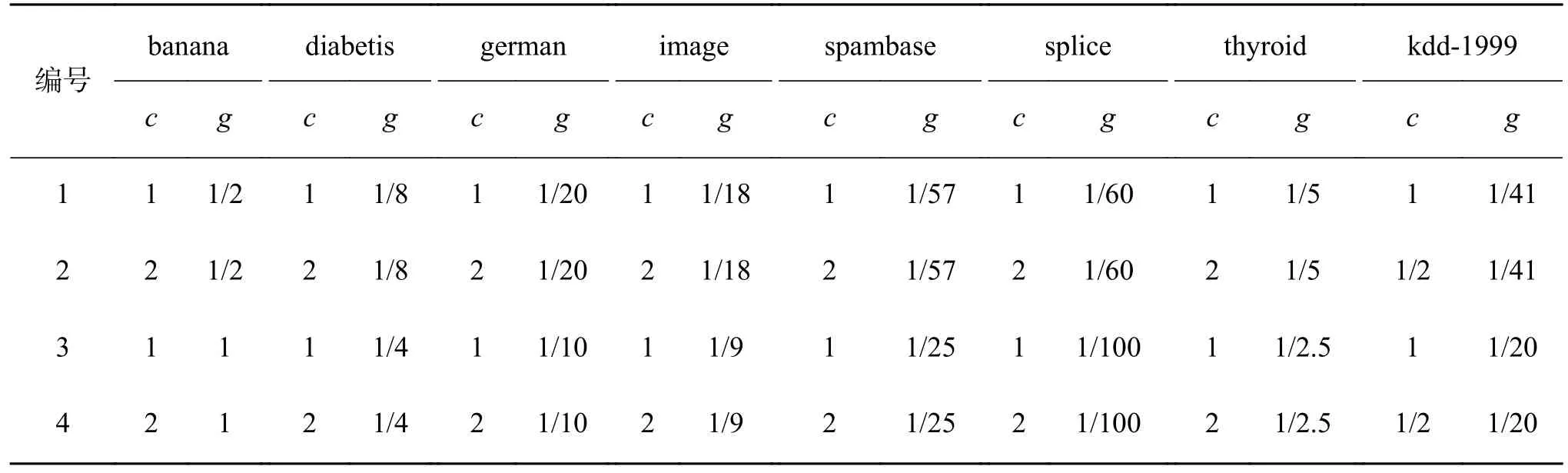
表3 SVM 模型参数取值Table 3 The value of the SVM model parameters
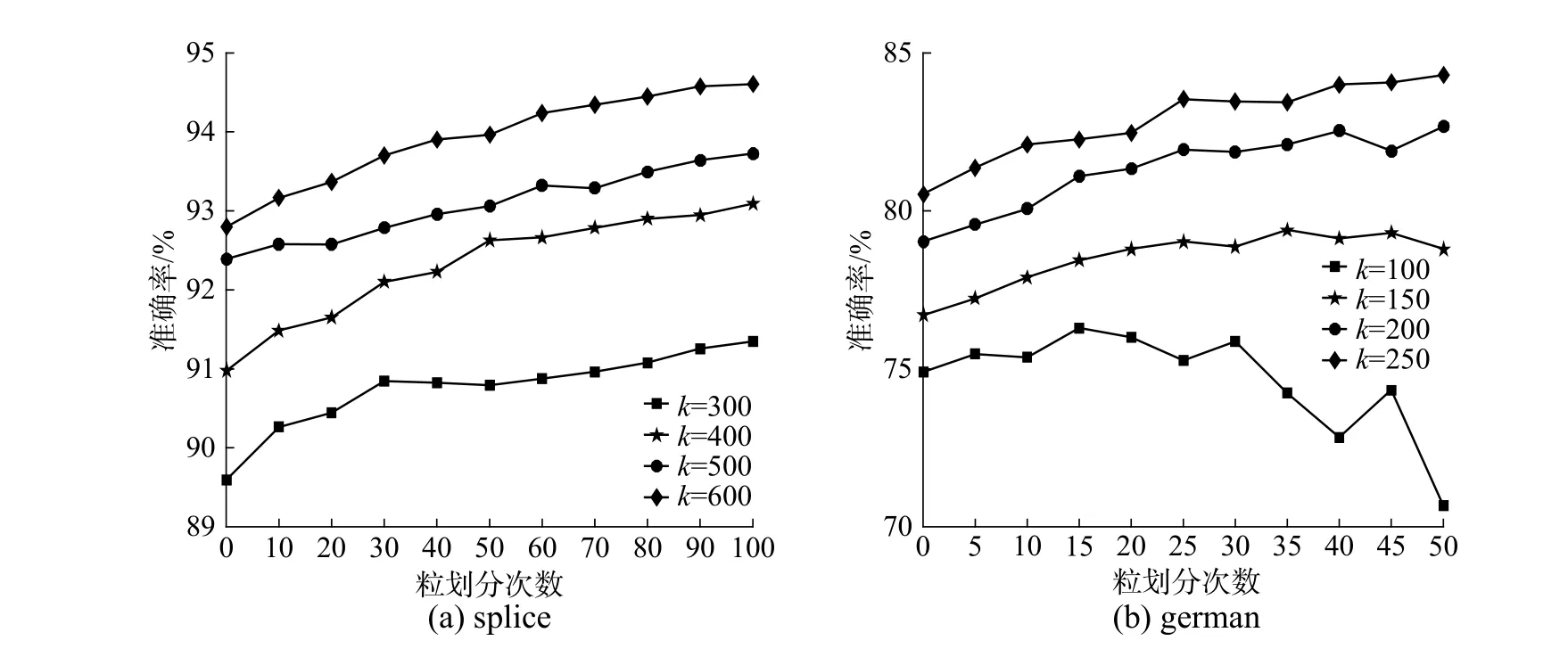
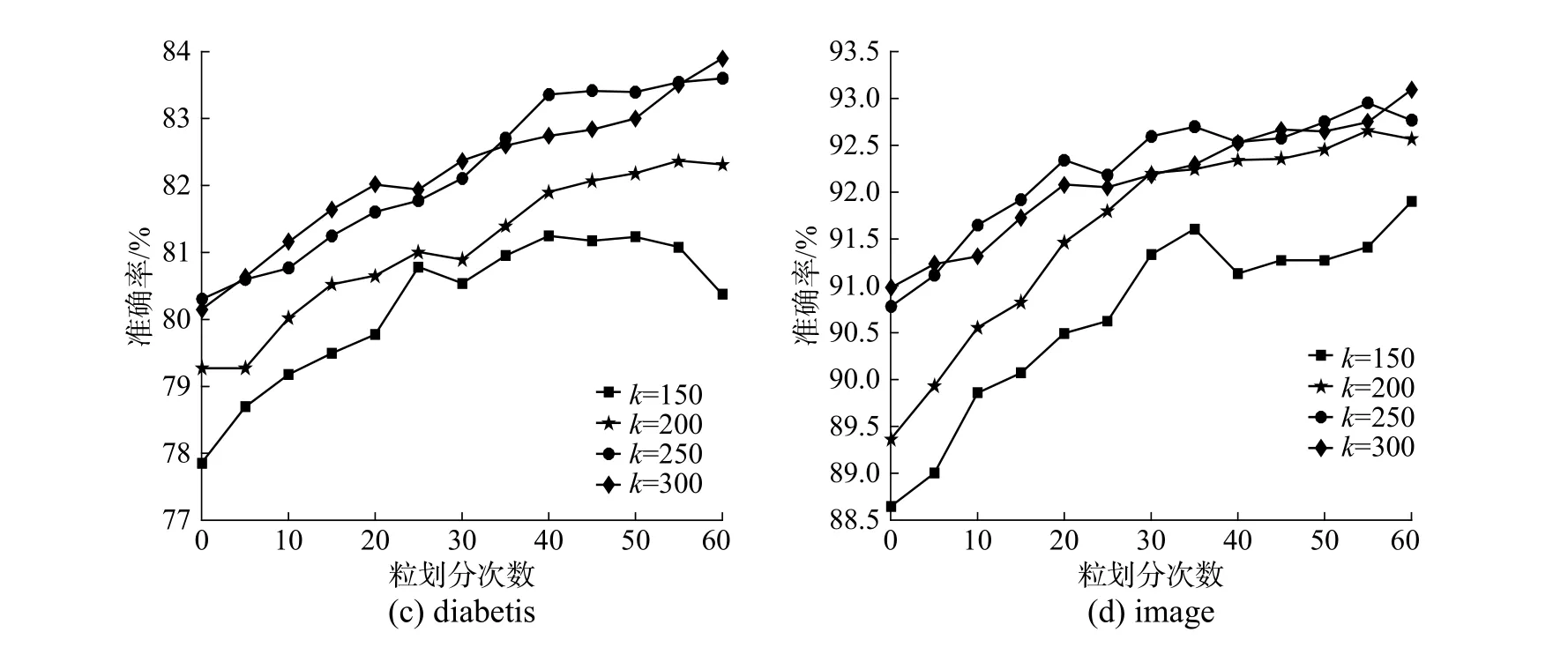
图7 初始聚类参数 k 对测试结果的影响Fig.7 The effect of initial clustering parameter k on the experiment
4 结束语
本文在动态粒度支持向量机的基础上结合划分与融合的思想,扩展了SVM 在大规模数据集上应用的能力,通过多种参数共同调节,能够保证在精度损失较小的情况下,提升SVM 的学习效率。但在采用划分与融合的思想在数据处理过程中可能会改变数据集的分布,限制了数据迭代划分次数,参数调节也增加了模型的复杂度。在未来的工作中,会继续针对该模型在实际应用问题中进行探讨,在简化模型的同时保证模型的泛化性能。
