基于多目标演化聚类的大规模动态网络社区检测
2019-02-20赵宇海王国仁
李 赫 印 莹 李 源 赵宇海 王国仁
(东北大学计算机科学与工程学院 沈阳 110819)
真实世界中,网络的节点和边通常会随时间动态地变化,这导致了网络中的社团结构也会随着时间发生改变.从2005年开始,对静态网络缺失的动态特征的研究逐渐成为了研究者们关注的热点[1].动态网络可以表示成由各个时刻静态网络组成的快照序列,动态网络社区检测的目的就是准确地挖掘出每一时刻快照的社区结构,从而可以分析社区结构随着时间的演变过程,这是无法通过静态网络社区检测洞察的.
动态网络社区检测有广泛的应用.在基因网络分析方面,动态网络社区检测能揭示特征基因集随时间的变化过程;在电商数据分析方面,动态网络社区检测能发现用户的偏好变化情况;在社交网络数据分析方面,动态网络社区检测能找出兴趣团体,预测团体可能参加的活动.此外,在新闻标题内容分析、论文作者合作关系分析、金融股市分析等方面,动态网络社区检测也有着广泛的应用.随着社区检测技术的发展,动态网络社区检测将会在越来越多的实际网络中得到应用,并发挥巨大的作用.
演化聚类框架是动态社区检测的主流方法之一,其基本思想是在第一时刻网络快照社区检测的基础上,根据社区结构的时间平滑性,用前一时刻的社区检测结果指导当前时刻的社区划分,以提高动态网络社区检测的效率.为了避免噪音等因素的影响,保证动态社区检测的准确性,许多文献把演化聚类框架引入到动态网络社区中来.但是,演化聚类存在以下2个问题: 1)在有效性方面,若初始社区结构检测不准确,会导致后续社区结构检测的“结果漂移”和“误差累积”问题,即上一个结果不准确将导致下一个聚类不准确,并导致这种不准确性愈演愈烈;2)在效率方面,基于模块度优化的社区检测方法是NP难的[2],许多精确算法无法在合理的时间内解决该问题.
针对以上问题,本文提出一种基于改进演化聚类框架和离散粒子群算法的多目标动态社区检测方法,本文的主要贡献有4个方面:
1) 提出基于最近未来参考的演化聚类框架,提高初始聚类准确性,保证动态网络社区检测的可靠性.
2) 离散粒子群优化算法与基于精英策略的非支配排序遗传算法(NSGA-Ⅱ)结合,并基于演化聚类框架,利用前一时刻社区划分结果来快速指导粒子群算法搜索当前快照中的社团结构.
3) 提出基于去冗余策略的随机游走初始个体生成算法DIGRW,对粒子群的位置进行初始化,提高了初始粒子群的个体多样性和个体精度.
4) 提出多个体交叉算子,增强算法的局部搜索能力,提高算法的收敛速度.
1 相关工作
由于动态网络社区检测能揭示静态网络检测无法洞察的社区结构随时间变化的规律,所以,自动态网络社区检测这一概念出现以来,一系列针对该问题的相关算法被先后提出.如Sarkar等人[3]提出利用数据挖掘技术分析动态网络的方法——基于潜在空间模型的动态网络社区检测方法.Cordeiro等人[4]提出一种基于本地模块度优化的动态社区自适应发现算法. Li等人[5]提出了一种基于增量识别的聚类方法来解决动态网络社区检测问题. Lander等人[6]提出多目标图挖掘算法,用来在复杂动态网络中挖掘和检测社区结构.Ma等人[7]提出进化非负矩阵因子分解算法来发现动态网络中社区的演变规律.
由于基于模块度优化的社区检测方法是经典NP难问题,上述精确算法在处理大规模动态网络社区检测时面临很大挑战.与精确算法相比,演化算法在处理大数据过程中具有较明显的优势[8].特别地,由于演化算法具有高度伸缩性、灵活性、全局优化等能力,并在特征选择时可同时实现针对多目标的优化,因此演化聚类算法在动态网络分析领域中逐渐崭露头角.
Chakrabarti等人[9]首次提出演化聚类框架,该框架指出动态网络具有时间平滑性,即相邻时刻动态网络前后变化差距不大.Kim等人[10]为了提高效率,进一步提出基于演化聚类框架的动态网络社区检测方法,即粒子和密度的演化聚类方法来分析动态网络的社区结构.Pizzuti等人[11]提出经典的DYN-MOGA算法.首次将多目标优化方法和演化聚类框架结合用于动态网络社区检测,使算法具有隐并行性,既保证了当前时刻社区划分质量,又保证了当前时刻社区划分与前一时刻社区划分的相似度较大.这些算法将演化聚类和演化算法结合,用于动态网络社区检测,在处理大规模网络效率上有所提高,但有效性仍存在问题.
针对现有同类算法存在的以上问题,本文提出一种基于多目标演化聚类的动态网络社区检测算法DYN-MODPSO,既提高了效率,又保证了结果的有效性.
2 基本概念及问题定义
本节主要描述算法执行过程中涉及的基本概念,并对要解决的主要问题给出具体定义.
2.1 基本概念
动态网络社区检测主要涉及2个基本概念,一个是对某个社区划分好坏的评估,另一个是对不同社区划分相似性的评估.以下分别描述这2个概念.


(1)


(2)

(3)


(4)
2.2 问题定义
动态网络可以建模为图N={N1,N2,…,NT}的形式,其中T表示时刻,Ni表示时刻i的网络快照.社区是一系列的节点集合,这些集合内部节点具有强关联关系,集合间的节点具有弱关联关系.动态网络社区检测就是要找出不同时刻网络快照中存在的真实社区结构.为了定量地衡量社区结构划分好坏,本文采用社区分数CS来评估社区划分质量,用归一化互信息函数NMI来评估2种社区划分的相似性.
3 基于改进粒子群的社区检测算法MRDPSO
基于模块度的动态社区检测是NP难问题,因此本文提出将粒子群优化算法和演化聚类框架相结合的有效解决方法.传统粒子群算法主要用于处理静态网络数据,不能和演化聚类框架相结合.本文对文献[11]提出的离散粒子群算法进行了改进,提出了算法MRDPSO(multi-results discrete particle swarm optimization).MRDPSO与现有的粒子群算法不同,主要从3个方面进行了改进:1)改进了粒子群算法的输出,可以输出多个最优解,避免了最优解的遗漏问题;2)用基于去冗余的随机游走初始群体生成方法初始化粒子群,提高粒子群中个体多样性并保证个体初始精度;3)提出多个体交叉算子(multi-individuals crossover operator, MICO)及改进的干扰算子NBM+(neighbor based mutation),增强算法的局部搜索能力.
3.1 MRDPSO总体描述
MRDPSO伪代码如算法1所示.MRDPSO框架由3个主要部分构成: 1)初始化阶段,利用基于去冗余策略的随机游走初始群体生成算法DIGRW初始化粒子群的位置信息,保证了初始种群个体具有一定精度和多样性,避免算法陷入早熟(行①~④);2)搜索阶段,对多目标粒子群社区检测方法进行改进,使得粒子群的全局最优位置都保留下来,使算法能够适应动态社区检测的需求(行⑤~);3)突变阶段,提出多个体交叉算子MICO(行)及改进的干扰算子NBM+(行⑨),使得粒子群在向全局最优解靠近的同时,能够在小范围的精英粒子群体中进行局部搜索,提高算法发现全局最优解的效率.3.2~3.4节将对这3个主要步骤分别进行描述.
算法1. MRDPSO.
输入:静态网络G={V,E};
① 粒子群位置初始化:利用DIGRW得到所有粒子的位置P={x1,x2,…,xpop};
② 粒子群速度初始化:初始化所有粒子速度V={v1,v2,…,vpop},令vi=0,其中i=1,2,…,pop;

⑤ 迭代,t=0;
⑥ fori=1,2,…,popdo



3.2 粒子群初始化
3.2.1 编码方式
在用演化计算进行社区检测的过程中,每个个体作为一种社区划分方案,都以编码的方式存在.目前的编码方式主要有字符串编码方式和位邻接编码方式[13].
图1(a)为一个原始网络;图1(b)为原始网络的3个子图,每个子图表示一个社区.图2的位邻接编码对应图1(b)所示的划分,图2中字符串编码为位邻接编码的解码.在位邻接编码方式中,如果节点i的基因值是j,则节点i与节点j位于相同社区;在字符串编码方式中,如果节点i的基因值为k,则节点i在标号为k的社区中.
如图2所示,基于位邻接的编码方式先转换成字符串编码,然后再解码成社区划分C={C1,C2,C3}的集合形式.所以位邻接编码方式解码困难、效率低,故本文采用直观、高效的字符串编码方式.
3.2.2 初始化粒子群位置
如果初始粒子群有过多的冗余个体,就不能保证初始种群个体有较强的多样性.如图3所示.
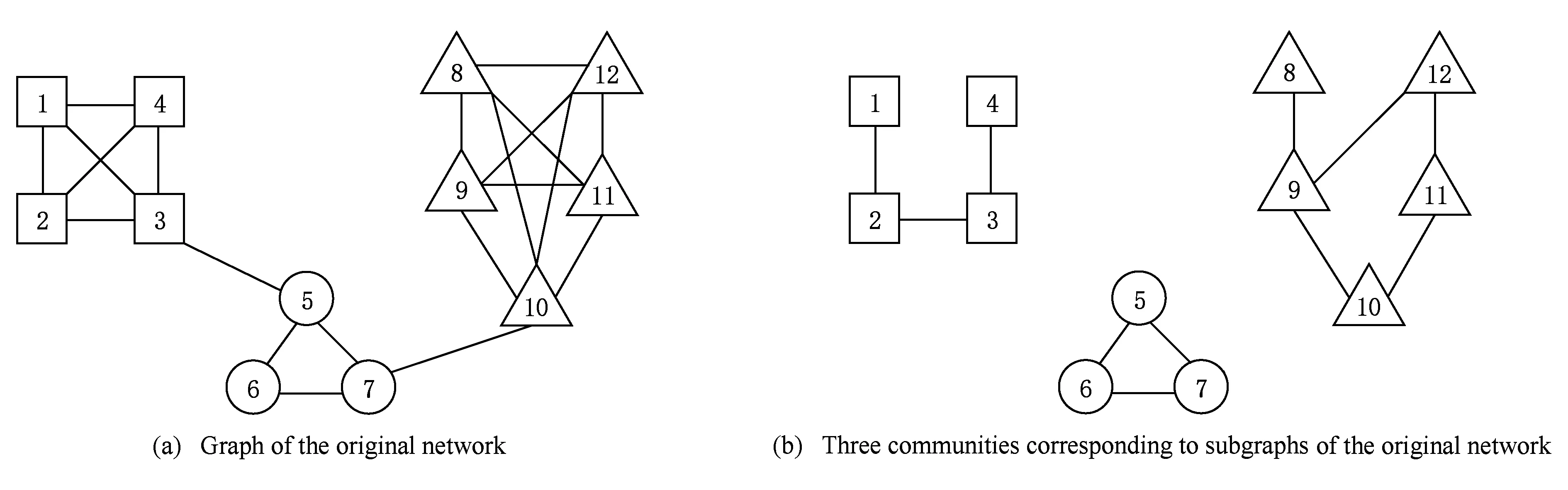
Fig. 1 Community division of the network图1 网络的社区划分

Fig. 2 The encoding scheme图2 编码方式

Fig. 3 The encoding scheme and the corresponding community division图3 编码方式与对应的社区划分
图3(a)中2种不同的字符串编码均对应如图3(b)所示的划分,因此图3中的2种字符串编码称为冗余编码.过多的冗余个体很容易导致算法陷入局部最优,或者算法的收敛速度降低.
针对这一问题,本文提出基于去冗余策略的随机游走初始群体生成算法DIGRW(different individual generation based on random walk).算法DIGRW大致过程有4个步骤:1)用基于随机行走的初始群体生成算法生成一个粒子位置p;2)用字符串去冗余方法(redundancy removal method, RRM)将个体p唯一化;3)若个体不重复,保留到种群中,否则删除;4)当种群个数达到上限时,停止生成个体.后2个步骤比较直观,以下主要对DIGRW算法的前2步加以描述.
随机游走初始化社区划分的理论基础是:根据社区的连接属性,即社区内的连接密度远大于社区外的连接密度,那么如果起始节点和目的节点位于同一社区,则会有更多经过k步到达目的节点的路径存在;反之,经过k步到达目的节点概率很小.基于随机游走的初始化社区划分基本过程为:1)随机选定一个目的节点n,计算每个节点经过k步到n的概率;2)将所有节点依照概率值降序排列,在排序后的节点中找出二分分列点,使得模块度函数Q增加最大;3)如果不存在使函数Q增大的分裂点,递归终止,否则分裂点将当前网络分裂成2个子网络,并分别对其递归执行上述操作.
算法2.RRM(p).
输入:编码p;
输出:p所对应的唯一编码u.
①u[1]=1;
② max=u[1];
③ for inti=0,1,…,|p|-1 do
④ for intj=0,1,…,ido
⑤ if(p[i]≠p[j])
⑥ continue;
⑦ else
⑧u[i]=u[j];
⑨ break;
⑩ end if
字符串去冗余策略RRM是将给定的编码标准化,使其成为能唯一表示该编码所对应社区划分的形式.算法RRM步骤如算法1所示.RRM的本质是对节点所属的社区标号进行调整.在每个编码p中,规定节点1所属社区的标号为1,即u[1]=1(行①~②).从节点2开始,依次对节点的社区标号进行调整:如果节点i与前面的节点j处于相同社区,那么u[i]=u[j],否则如果节点i与前面的每个节点都不在一个社区,那么将当前最大的社区标号值加1,作为u[i]的社区标号(行③~).
3.3 粒子群搜索


(5)

(6)

3.4 干扰算子和交叉算子
粒子群优化算法可以通过结合遗传操作中的交叉和变异操作来保留最优粒子,增强种群多样性和增加跳出局部最优区域的能力.本研究中分别提出一种新的交叉算子MICO和一种新的干扰算子NBM+来实现粒子群优化过程中的个体交叉和变异操作.以下分别对这2个算子进行介绍.
3.4.1 多个体交叉算子MICO
传统交叉算子仅是针对2个父代个体,与此不同,本文提出一种新的多个体交叉算子.受聚类融合算法平衡多个聚类结果获得更准确结果的思想启发[14-17],本文将遗传算法中传统2个父代个体交叉算子扩展成多个体交叉算子,提出多个体交叉算子MICO.
MICO交叉操作过程有3个:1)从所有粒子的历史最优位置pbest中随机挑选出M个位置;2)设交叉产生的新位置为x,将x[i]赋值为M个位置中第i个元素上出现次数最多的社区标号,如果有多个出现最多的社区标号,则随机选一个赋值;3)交叉完成,产生新位置x,对x采用去冗余策略RRM去冗余.
如图4所示,若M=5,则随机选出5个位置向量x1,x2,x3,x4,x5,对它们进行多个体交叉操作,产生的新位置向量记为x.现在对基因位x[3]进行赋值,可以看出x1~x5的第3个基因值中的社区标号2出现次数最多,则令x[3]的基因值为2.以此类推,x的所有基因位都按照这个规律赋值,最终x=(1,1,2,1,2,3,3,3).

Fig.4 Search operation based on elitist-crossover图4 精英交叉搜索算子
3.4.2 干扰算子NBM+
为了提高粒子群算法的局部搜索能力,文献[14]提出干扰算子NBM.然而,NBM会产生冗余个体,故本文在此基础上加入了字符串去冗余策略,提出改进的干扰算子NBM+来增强解的多样性,避免算法陷入局部最优.
NBM+的过程有3步:1)生成一个[0,1]之间的随机数m;2)判断m与突变概率pm之间的关系,若m 算法MODPSO处理的是单时间片上静态网络聚类问题,本节基于前面提出的单快照社区检测算法MRDPSO,进一步提出基于演化聚类框架的动态网络社区检测算法DYN-MODPSO(multi-objective discrete particle swarm optimization for dynamic network)来处理动态网络社区检测问题. DYN-MODPSO伪代码如算法3所示. 算法3. DYN-MODPSO. 输入:动态图N={N1,N2,…,NT},时刻T,最大迭代次数genmax; 输出:Nt的聚类结果Ct. ① while(t==1‖t==2) ④ end if ⑤ fort=3 toTdo ⑦ while (gen≤genmax) ⑧ fori=1,2,…,popdo 算法3由2个主要部分构成:1)基准聚类校正,此阶段分别用MRDPSO处理动态网络中的前2张快照,通过计算不同快照中社区划分的相似性,基于时间平滑性原理对初始社区的检测结果进行校正,避免因快照1聚类结果不准导致快照2聚类结果不准的问题(行①~④);2)多目标演化聚类.此阶段在基准聚类校正的基础上,将多目标优化算法NSGA-Ⅱ与MRDPSO融合,处理后续快照的社区检测问题(行⑤~).以下各节将对这2个主要步骤分别进行描述. 前面改进的粒子群算法MRDPSO在与演化聚类结合处理动态社区检测的过程中,仍然会产生“结果漂移”和“误差累积”的问题.为解决该问题,本文提出基于最近未来参考策略的基准聚类校正方法,保证初始聚类结果的准确性,从而提高动态社区检测结果的有效性. 对poplist采用多目标优化算法NSGA-Ⅱ中的非支配排序和拥挤距离排序[18-20],根据动态网络社区的时间平滑性,选出社区划分质量好,同时又与前一张快照划分最相似的解作为当前快照的划分结果(行~).依照这样的规律,DYN-MODPSO对每一张动态图快照都进行关联性地处理,直到处理完最后一个动态图快照NT,输出最优社区划分方案CT,算法结束(行~).粒子群的非支配排序过程,就是粒子通过两两比较CS与NMI后,按照适应度值从大到小进行的排序过程.粒子群的拥挤距离排序过程,就是在同一个支配等级中,即适应度值相同的条件下,选择互不相似的粒子排在前面,将比较与前面粒子比较相似的粒子排在后面,这样能够避免得到的解扎堆聚集,从而保证解的多样性. 本文分别用人工网络和真实世界网络对算法进行了测试,对比算法是DYN-MOGA,Kim-Han,IBEA.本实验所用的软硬件环境如下:Red Hat 64位操作系统,16核CPU,主频1.9 GHz,16 GB内存,2 TB硬盘;Eclipse版本为4.5.0,Java版本为1.8.0. 本文使用Youtube,LiveJournal,DBLP,Flickr这4个真实数据集和人工数据集进行实验[21-22].其中,Youtube是用户到用户的链接关系网;DBLP是作者合作关系网;LiveJournal是在线社交关系网;Flickr是一个分享网站的组员关系网. 人工数据集使用文献[21]中的算法生成.数据集Dz(z=3,4,5,6),其中z表示不同社区之间的边平均数.z越大,社团间的连边越多,社团内的边越少,社团结构越不明显.数据集统计信息如表1、表2所示. Table 1 Real Datasets表1 真实数据集 Table 2 Synthetic Datasets表2 合成数据集 实验结果主要从NMI值、模块度、运行时间和收敛性4个方面验证算法的有效性.以下分别给出算法DYN-MODPSO在这4个指标下的度量结果. 5.3.1 NMI值比较 由于人工网络的社区划分已经确定,所以本文选择第2节介绍的归一化互信息函数NMI作为指标,来评估这3个算法的社区划分结果和标准社区划分的相似性,从而检测算法的准确性.图5所示的是算法对人工网络10张快照检测结果的NMI值. NMI的值越接近1,算法的检测结果越接近真实的社区划分.如图5所示,当z=3时,DYN-MODPSO的NMI值接近1,而DYN-MOGA和Kim-Han的NMI值分别在0.95和0.9上下浮动,IBEA的值初始接近0.95,随着时间的推移,它的NMI值逐渐下降,在时间片T=10时低于0.9.当z=4,5时,4个算法的NMI值都下降,但是DYN-MODPSO的NMI值都稳定在0.9,明显高于DYN-MOGA,Kim-Han和IBEA.当z=6时,DYN-MOGA, Fig. 5 NMI value of the synthetic dataset图5 人工数据集的NMI值 Kim-Han,IBEA的NMI值已经接近0.6,而DYN-MODPSO仍稳定在0.85. 由此可以看出,当网络社区结构明显时,4个算法都能检测到动态网络中准确的社区结构.当动态网络社区结构变得模糊,4个算法的社区检测能力均下降,但是DYN-MODPSO依然可以检测到相对准确的社区结构.故算法DYN-MODPSO的检测能力都优于DYN-MOGA,Kim-Han,IBEA,并且稳定性较强. 5.3.2 模块度比较 由于真实数据集的社区划分未知,所以用衡量社区划分质量的模块度函数来对实验结果进行评估.模块度值越大,结果越接近真实的社区结构.模块度函数记作Q,定义为社区内实际的边数与随机连接情况下社区内期望的边数之差.函数Q的计算公式如下: (7) 其中,A是网络的邻接矩阵,m是网络的总边数,ki表示节点i的度,ci表示节点i所在的社区标号.如果i=j,则δ(i,j)=1,否则δ(i,j)=0. 本文选择数据集的前5张快照,记录它们的模块度,如图6所示.从图6中可以看出DYN-MODPSO的模块度大于DYN-MOGA,Kim-Han,IBEA.如图6(a)(b),4个算法的模块度都很高,DYN-MODPSO稳定在0.65上下,随着数据集规模变大,如图6(c)(d),4个算法的模块度均减少,但是DYN-MODPSO的模块度值仍然在0.53上下.所以,DYN-MODPSO准确性很高,并且适合处理大数据网络图. 5.3.3 运行时间比较 Fig. 6 The modular comparison of four real datasets图6 4个真实数据集的模块度比较 Fig. 7 Runtime comparison of the two algorithms图7 算法运行时间对比 图7所示的是算法的运行时间对比图.算法在人工数据集上的平均运行时间如图7(a)所示,可以看出DYN-MODPSO的运行时间小于DYN-MOGA.当z=3,4时,算法DYN-MODPSO和DYN-MOGA的运行时间相差不大.当z=5,6时,网络中的社团结构变得模糊,此时DYN-MOGA的运行时间比DYN-MOGA将近缩短了一半. 算法在4个真实数据的平均运行时间如图7(b)所示,DYN-MOGA的运行时间比DYN-MRDPSO长,而且数据集越大,运行时间差越大,如图7所示DYN-MOGA在LiveJournal数据集的运行时间是DYN-MRDPSO的2倍多.所以DYN-MRDPSO是更高效的动态社区检测演化算法,更适合处理大规模数据. 5.3.4 收敛性比较 在社区检测方法中,DYN-MRDPSO和DYN-MOGA都是演化算法.收敛性是评估演化算法的一个指标.在不断地迭代过程中,种群中不断优化最优解,当达到一定迭代次数时,最优解趋于稳定,不会随着迭代次数的增加而变化,这时算法收敛. 本文记录了DYN-MRDPSO和DYN-MOGA收敛时的最小迭代次数,如图8所示.DYN-MRDPSO的迭代次数远小于DYN-MOGA,说明DYN-MRDPSO具有更高的执行效率.因为DYN-MRDPSO利用DIGRW来初始化种群,使种群在一定程度上接近最优解,而DYN-MOGA的初始种群是随机生成的,所以算法的迭代次数比DYN-MRDPSO多许多. Fig. 8 Convergence comparison of algorithms图8 算法收敛性对比 本文提出一个参考最近未来的演化聚类框架,并将其引入粒子群社区检测方法中,提出了DYN-MODPSO算法.为了加快粒子群算法的收敛速度,本文对随机行走社区划分方法做了改进,提出了基于去冗余策略的随机行走初始个体生成算法,来初始化粒子群,使得粒子具有一定的精度和多样性.在粒子群的搜索过程中,本文引入多目标优化算法NSGA-Ⅱ来同时优化NMI和CS这2个社区划分适应度函数,并加入干扰算子和多个体交叉算子来加强算法的局部搜索能力. 通过实验可以看出,在社区检测的性能方面,算法DYN-MRDPSO比DYN-MOGA和Kim-Han能检测到更准确的社区结构,是有效的.在社区检测的准确性方面,算法DYN-MODPSO的社区划分准确性高于DYN-MOGA和Kim-Han,且具有较优的稳定性.故算法DYN-MODPSO是有应用意义的,可以用于动态网络社区检测.4 算法DYN-MODPSO
4.1 算法总体描述






4.2 基准聚类校正

4.3 多目标演化聚类

5 实验结果与分析
5.1 实验环境配置
5.2 实验所用数据集


5.3 实验结果及分析





6 总结与展望
