面向热点新闻的爬虫系统设计与实现
2019-02-14林文涛陈伟强刘杭燕
林文涛,陈伟强,刘杭燕,叶 楠
(福州理工学院工学院,福州 350506)
1 引言
在这信息如此庞杂的时代要使热点新闻信息更易于查询,易于获取。用爬虫程序实现热点新闻高效、快速而便捷的获取与整合。通过建立网站的方式来展示获取的新闻信息。为了让用户定制个人信息获取偏好、保存历史记录等功能,而编写了用户模块[1-2]。
2 热点新闻的爬虫系统设计原理与创新
网络爬虫是通过程序或脚本借助现有爬虫技术或工具编写的系统,该系统将有目的性的自动抓取互联网信息[3]。网络检索功能起于互联网内容爆炸性发展所带来的对内容检索的需求。搜素引擎不断发展,人们的需求也不断提高,网络信息搜索已经成为人们每天都有进行的内容。如何使搜索引擎能够时刻满足人们的需求?最初的检索功能通过索引站的方式实现,从而有了网络机器人[4]。本项目来源于新闻爬虫系统项目的建设,旨在为相关机构或个人提供及时的网络信息服务。
2.1 设计原理
(1)利用Python语言结合该语言的相关库或技术如Requests/urllib等编写爬虫系统[5]。系统可以定期的对几个大型的新闻发布平台进行广度优先的爬取策略来增量获取新闻数据。
(2)采用Xpath/Re/BeautifulSoup库对获取到的新闻数据进行关键字段提取。其中关键字段有新闻标题、编辑者、发布平台、发布时间等,之后再将这些关键字段与新闻图片、正文内容一并存储与本地,等待进一步操作。
(3)使用python的pymysql库对MySQL数据库进行对接。
(4)通过Flask web框架构建网站,负责为用户需求而控制和调度相应的模块以及对MySQL数据库中资源的调用与整合,为实现前端页面的对接实现不同使用场景下的多种数据请求接口:由用户通过URL请求时,服务器端将直接返回相应的HTML页面;若碰到特殊的需求需要使用异步传输时,将返回以JSON格式封装的数据,在前端通过JavaScript脚本语言对其进行相应处理。
(5)前端界面利用Python的Jinja2模板引擎以及Bootstrap/AJAX/JQurey等相关技术实现,兼顾用户交互方式的多样性以及系统的跨浏览器兼容性。
2.2 爬虫程序编写逻辑
本文中的基于网络爬虫的热点新闻发布系统可以简单的理解为,对新闻发布平台的众多的新闻页面格式化——根据需要提取该新闻页面中的关键信息。因此,为了让程序更加易读、更容易拓展,在爬虫设计之初先编写了一个Website类,供后续爬虫程序拓展。

图1 Website类图
在此类中根据系统需要,主要提取新闻页面的链接、新闻发布时间、新闻标题、新闻来源、新闻编辑、新闻内容、新闻类型。根据上述程序,针对相应的新闻发布平台编写相应的爬虫类实现Website类中的抽象方法。其中,getLinks()与fromRank()方法用于在对应新闻发布平台遍历新闻页面。当后续程序需要批量爬取新闻页面时只需调用getParams()方法即可。
3 热点新闻发布系统设计与实现
3.1 数据爬取
在本系统中,数据获取依赖于python编写的网络爬虫,爬虫程序基于Requests来发起对新闻发布平台的请求,获取返回的HTML页面,之后通过Xpath(XML路径语言)与python内置的re(正则表达式)库编写定位HTML上关键字段的爬取逻辑,将新闻的标题、来源、编辑者、存储路径、发布时间、新闻类别等字段存储进MySQL,新闻内容与新闻图片存储到本地中。由此即可编写一个针对新闻信息的可扩展爬虫程序。
爬虫程序主要由链接过滤子模块、页面解析子模块、爬行控制子模块以及数据存储子模块构成,其模块结构如图2所示:
3.1.1 链接过滤子模块

图2 数据获取功能模块结构图
本系统的爬虫程序运行过程中,将会不断往URL队列中添加新的URL链接,其中某些URL链接可能并不是程序所需要的。因此这时候就需要再编写一个用于过滤URL链接的过滤器。对于这个过滤器只有某些条件符合的URL才能进入待爬URL队列,将其余不符合条件的URL剔除,不会加入到待抓取的爬行队列中。同时对于符合条件的URL也要判断该URL是否被爬取过,如果已被爬过则舍弃。
在爬虫程序中使用链接过滤器对URL进行过滤是有必要的。由于大量不符合条件的URL被过滤掉了,爬行队列中仅仅加入符合条件的URL,充分节省了宝贵的内存空间。链接过滤子模块的工作方式如图3所示:
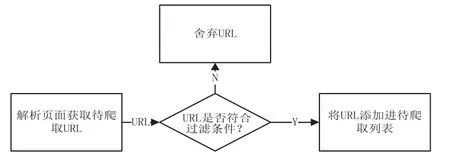
图3 链接过滤子模块
3.1.2 页面解析子模块
通过链接过滤子模块过滤获取的URL队列,传输进此模块。页面解析子模块将会对URL队列中的链接逐一解析,解析过程是通过Xpath(XML路径语言)定位页面中需要抽取消息的具体位置,后获取该信息并存储进数据库。但是有些URL即使通过了过滤器子模块,也会因为排版的些许差异而使得Xpath无法定位,这是就需要有相应的程序来检测这样的URL。页面解析子模块的工作方式如图4所示:

图4 页面解析子模块
3.1.3 爬取策略子模块
爬取策略模块是整个爬虫程序的核心,它控制着整个爬虫的抓取策略(宽度优先或者深度优先)以及停止条件。爬行控制子模块的工作流程如图5所示:

图5 爬行控制子模块
3.1.4 数据存储子模块
对HTML页面进行解析后,获得的关键字段,将会存储于数据库中,而新闻内容与新闻图片将会被整合存储为本地文件。数据存储子模块的工作流程如图6所示:
3.2 数据可视化功能模块
系统可视化功能模块的主要功能结构如图7所示,通过ExtJS结合Google Visualization API进行构建,其主要功能包括:首页新闻推荐:登录网站后首页将是按热度排序推荐的新闻条目;按类型查看:查看特定类型的新闻;按时间查看:查看某个时间段的新闻:通过关键字检索:输入关键字检索查看当前符合条件的新闻;每日新闻增量:查看近20天每日新增新闻的数量;当日新闻词频分析:查看发布日期为当日的新闻的词频分析柱状图;关键字检索查看每日词频变化折线图:数日某个关键字,获取该词近20日的词频变化。

图6 数据存储子模块

图7 数据可视化功能结构图

图8 网站首页
4 热点新闻发布系统测试与分析
4.1 测试环境
该系统的运行的性能会受到实验机器的网络与机器硬件性能的影响,本节列举测试环境。

表1 硬件环境
由于条件限制,在测试系统时,本文只使用两台机器。

表2 软件环境
4.2 测试
在项目完成后需要对系统是否符合最初的需求做出一定的测试,系统测试就是对当前整个项目的检验。检查项目中的不足的地方。之后再进一步优化系统。本节将依据系统测试规则设计一系列测试用例,以系统测试的一般方法来测试新闻爬虫系统。
发现系统中的漏洞与缺陷是软件测试的主要目的,软件测试在软件的整个开发过程中也占据着举足轻重的地位。因此本节对系统关键功能设计相应的测试用例:数据爬取模块爬取数据;数据爬取模块周期爬取数据;数据可视化模块分析图;数据可视化模块新闻内容展现;数据可视化模块关键字检索近期词频变化。
根据测试用例将设计相应的预设条件、输入、操作步骤以及预期输出以判断相应功能模块能否正常运行,如表3所示:
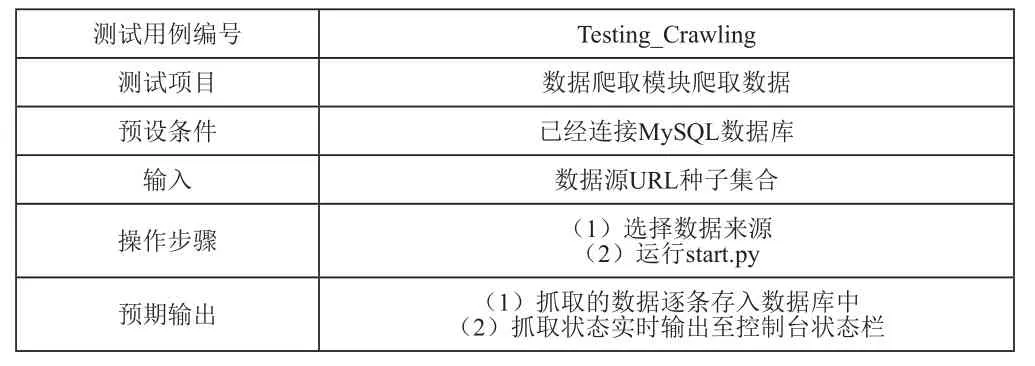
表3 测试用例一
在测试用例的帮助下对整个系统进行了详尽的测试,之后对于各别测试不通过的系统功能模块的测试结果分析,获得照成测试不通过的原因,对其中照成错误的代码进行仔细的调试与修改。在之后对功能模块不断的整合解耦下终于使得所有测试用例都通过了考验,均达到了测试的预期结果。
5 结束语
在这网络高度发达的时代,每日信息都在爆炸式的增长。而对于如何获取其中有用的信息也越来越被人们所重视,对于此网络爬虫正扮演着越来越重要的角色,它将成为分析信息数据的利器。本文所设计实现的新闻爬虫系统,参考综合了现在主流的几种爬虫技术路线。通过编写爬虫程序实现了对于新闻内容、标题、发布时间等数据的抓取,使用Chart.js结合Python的Jinja2模板引擎以及Bootstrap/AJAX/JQurey等相关技术实现了数据可视化功能,兼顾用户交互方式的多样性以及系统的跨浏览器兼容性。
