联合空-谱信息的高光谱影像深度三维卷积网络分类
2019-02-13余旭初张鹏强
刘 冰,余旭初,张鹏强,谭 熊
信息工程大学,河南 郑州 450001
高光谱遥感影像能够同时提供地物丰富的光谱和空间信息,因此被广泛应用于精细农业、环境监测、城市规划和军事侦察等领域。高光谱影像地物分类则是开展各类应用的重要环节之一,其最终目的是给影像中的每个像元赋予唯一类别标识。然而,高光谱影像的高维和小样本特性使得高光谱影像地物分类仍然面临巨大挑战。为此,支持向量机[1](support vector machine,SVM)、稀疏表达[2]、半监督学习[3]和主动学习[4]等一系列分类方法被用于高光谱影像分类。但在不进行特征提取的情况下,这些分类方法很难在高光谱遥感影像地物分类中取得理想结果。
深度学习方法通过多层的神经网络来提取更加抽象的特征表达,以更好地描述高维数据的复杂结构,进而获得更高的分类和识别精度。卷积神经网络(convolutional neural network,CNN)是深度学习技术中极具代表性的网络模型之一,其能够直接处理高维的二维图像数据,避免了人工设计特征的复杂过程,而是隐式地从训练数据中进行学习,从而降低了分类和识别过程中数据重建的复杂度。由于采用了权值共享机制,使得CNN易于并行实现;此外,CNN对平移、尺度、形状、光照等具有一定程度的不变性。由于具有以上优点,CNN近年来已经被成功用于目标识别、图像理解、机器翻译等不同领域。随着深度学习的快速发展,高光谱研究人员逐渐将深度学习方法用于解决高光谱影像分类问题。堆栈式自编码器[5](stacked autoencoders,SAE)是一种简单有效的深度学习方法,率先被用于高光谱影像分类。随后,一维卷积神经网络[6](1D-CNN)、深度置信网络[7]和循环神经网络[8]也被用于高光谱影像分类。大量的研究成果表明,综合利用光谱和空间特征能够有效提高高光谱遥感影像地物分类的精度。因此,利用二维卷积神经网络[9-13](2D-CNN)提取高光谱影像空间特征,并结合光谱特征,能获得比1D-CNN更好地分类效果。此外,深度学习还与主动学习[14]、半监督分类[15]、迁移学习[16]等方法结合以进一步提高高光谱影像地物分类精度。
近年来,基于深度学习的高光谱遥感影像地物分类方法得到了广泛的研究,并取得了一定进展。但神经网络中通常包含了大量参数,需要大量标注数据对其进行优化。而高光谱遥感影像标注数据费时费力,用于训练的标注数据非常有限。因此无法直接应用大规模的深层网络对高光谱遥感影像地物进行分类。针对此问题,目前主要的研究集中于如何简化网络和减少参数数量,以使深度学习方法适应高光谱遥感影像地物分类小样本的特性。此外,为利用空间特征提高分类精度,现有的深度学习方法一般需要首先使用主成分分析对高光谱影像进行降维预处理,进而采用CNN提取空间特征,最后结合光谱特征进行分类。但降维处理会丢失高光谱数据的细节信息,而这些细节信息很有可能是区别不同地物的判别信息。
针对以上问题,本文通过引入残差学习结构来解决小样本条件下深层网络难以训练的问题,并利用三维卷积来对高光谱影像进行特征提取。三维卷积可直接对高光谱影像进行处理,不需要降维等预处理操作,因此能够更加充分地利用高光谱影像提供的光谱和空间信息。本文构建的深层三维卷积网络能够提取更加抽象的特征表达,且不需要降维预处理,能够提高高光谱遥感影像地物分类精度。在Pavia大学、Indian Pines和Salinas三组高光谱数据集上验证了本文算法的有效性。
1 本文算法
1.1 卷积神经网络
CNN最初是受到视觉系统中神经机制的启发,针对二维形状的识别而设计的一种多层感知机。该方法将局部连接、权值共享、空间亚采样三种思想结合起来获得某种程度的平移、尺度、形状不变性,具有对二维图像适应性强的特点。同时,CNN结构的可拓展性很强,它通常由若干卷积层、池化层(下采样层)和全连接层组成,可以采用很深的网络结构。因此,CNN能够处理更复杂的分类和识别问题,并取得较为理想的结果。

(1)
池化层完成对卷积层输出特征图的下采样操作,以实现特征对平移、尺度、形状的不变性,同时达到减少训练参数的目的。常见的下采样操作有均值池化和最大池化。卷积神经网络经过若干交替的卷积层和池化层后,将特征输入全连接层和分类器中,并计算损失函数。卷积神经网络的训练目标是使损失函数最小,通常采用反向传播算法进行训练。
1.2 三维卷积
CNN最初是针对二维形状的识别而设计,可以直接处理二维图像,建立从底层信号到高层语义的映射关系,并在视觉图像分类和识别中取得了成功。然而,卷积神经网络在对视频等三维数据进行分析时,具有一定局限性。高光谱遥感影像是三维的数据立方体。因此,卷积神经网络在对高光谱遥感影像地物进行分类前需要使用主成分分析等方法进行降维预处理。但降维处理会损失高光谱图像中的细节信息,而这些细节信息往往有助于区分不同地物类别。

(2)
1.3 残差学习


图2 残差学习示意Fig.2 Illustration of residual learning
残差学习的基本思想是在传统网络结构的基础上,引入一条捷径,跳跃绕过一些层的连接与主径相加。引入捷径后,训练过程中的底层误差可以通过捷径向上层传播,缓解了因层数过多而导致的梯度弥散问题,使得深层网络的训练变得容易。
1.4 本文网络结构
高光谱遥感影像是典型的三维数据立方体,且标注训练样本费时费力。因此,在应用深层网络对高光谱影像进行分类时,需要面临高维和小样本导致的“维数灾难”问题以及网络退化问题的挑战。为此,本文构建如图3所示的深层三维卷积网络用于对高光谱遥感影像进行分类。图3所示的深层三维卷积网络的深度主要体现在具有更多的隐藏层数,该网络由输入层、一个三维卷积层、两个残差学习模块(包含3个三维卷积层)、两个池化层、一个全连接层和输出层组成。表1给出了常用于高光谱影像分类的深度学习模型包含的隐藏层数和本文网络包含的隐藏层数。由表1可知,与目前常用于高光谱影像分类的深度学习模型相比,本文网络具有更多的隐藏层数,能够提取和利用更加抽象的深层特征。
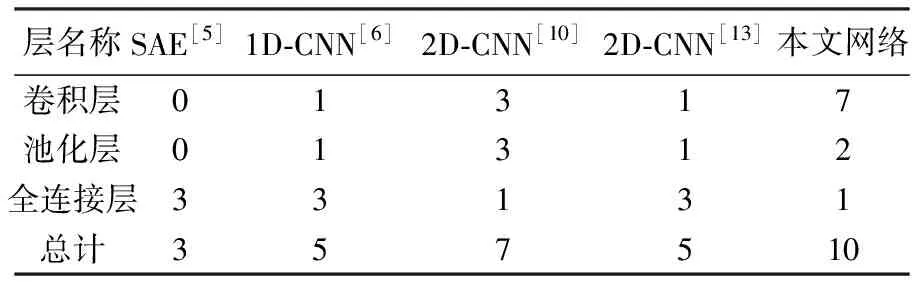
表1 常用于高光谱影像分类的深度学习模型的隐藏层数
图3中,Conv表示卷积核大小为3×3×3的三维卷积层,Pooling表示步长2×2×4为池化层,FC表示全连接层。ReLU[20-21](rectified linear units)激活函数相比于传统的Sigmoid和tanh激活函数具有更快的收敛速度。因此,本文所有三维卷积层均采用ReLU激活函数进行非线性映射。ReLU激活函数形式为
f(x)=max(0,x)
(3)
图3中,虚线框内为一个残差学习模块。通常的残差学习模块中包含池化层,这将导致捷径和主径特征维度不同而无法相加,一般的做法是对主径的特征图进行补全或上采用处理。本文对每个三维卷积层的输入进行补全处理,以使得卷积前后的特征图维度相同,且在残差学习模块中不使用池化层,从而实现主径和捷径特征图的相加融合。每个残差学习模块后连接一个步长2×2×4为的池化层,以减少计算量,并对特征进行聚合。高光谱影像通常具有较高的光谱维度,且各波段间存在较强的相关性,即存在大量冗余信息。文献[6]在利用1D-CNN对光谱特征进行分类时,仅使用了一个池化层。因此,使用了较大的池化步长5,以达到快速降低光谱特征维度的目的。鉴于此,本文网络在每个残差模块后连接一个池化层,并将光谱维度池化步长设置为4,而空间维度池化步长均设置为2。然后,将最后一个三维卷积层输出的特征图展成一维向量,与全连接层相连,并在全连接层采用Dropout正则化方法,随机丢弃隐藏层一定比例的节点,以控制过拟合风险。最后,在输出层采用Softmax函数作为激活函数,以完成高光谱影像的多种地物分类任务。Softmax激活函数形式为
(4)
本文网络的训练与传统卷积网络训练相同,包含前向网络计算和反向传播两个步骤。首先,将训练样本输入到网络中得到输出的类别标签,并计算相对于已知类别标签的交叉熵损失函数。然后,采用基于反向传播的随机梯度下降法来优化网络参数。
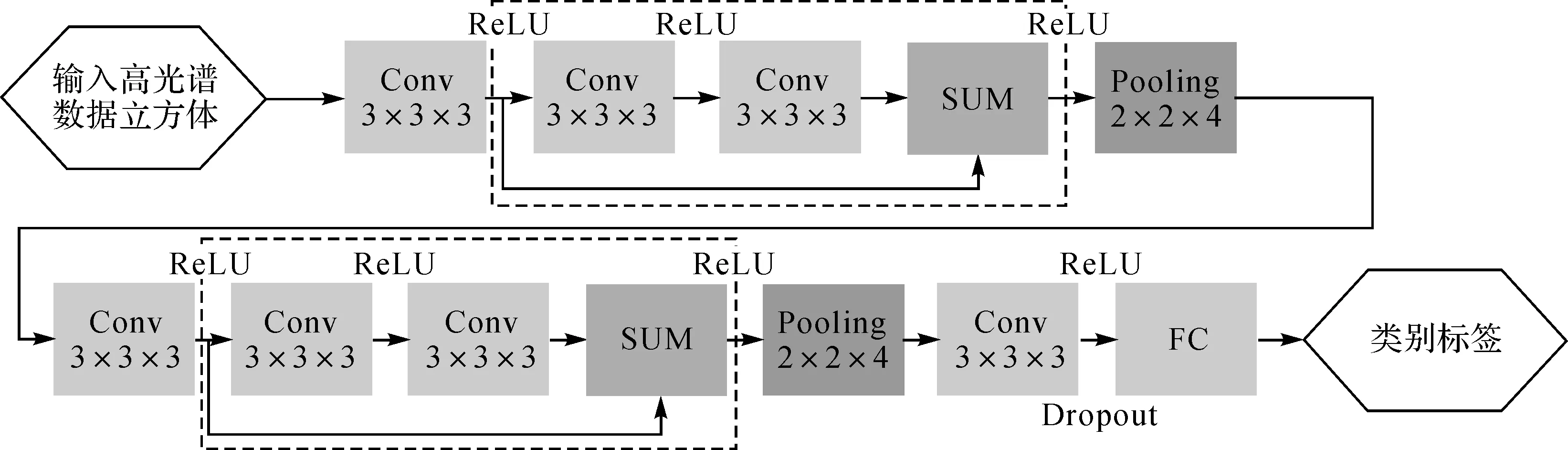
图3 深度三维卷积网络结构Fig.3 Architecture of deep 3D convolution network
2 试验结果与分析
试验的硬件环境为32 G内存、i7-5700Q处理器,GTX970M显卡。试验程序均在Ubuntu16.04系统下,基于谷歌深度学习开源库TensorFlow实现。
2.1 试验数据
为验证算法的有效性,使用具有代表性的Pavia大学[22-23]、Indian Pines[24]和Salinas[25]高光谱遥感数据集进行分类试验。
(1) Pavia大学数据集:该数据由ROSIS传感器获得,光谱覆盖范围为430~860 nm,影像大小为610×340像素,空间分辨率为1.3 m,去除受噪声影响的波段后,剩余103个波段可用于分类。该数据集对9种地物进行了标注。地物类别、选取的训练样本数量、确认样本数量以及测试样本数量见表2。
(2) Indian Pines数据集:该数据集由AVIRIS传感器获得,光谱覆盖范围为400~2500,影像大小为145×145像素,空间分辨率为20 m,去除受噪声影响的波段后,剩余200个波段可用于分类。该数据集对16种地物进行了标注。参照文献[24],去除样本数量较少的地物类别,选取样本较多的9种地物进行试验分析。地物类别、选取的训练样本数量、确认样本数量以及测试样本数量见表3。
(3) Salinas数据集:该数据集由AVIRIS传感器获得,光谱覆盖范围为430~860,影像大小512×217为像素,空间分辨率为3.7 m,去除受噪声影响的波段后,剩余204个波段可用于分类。该数据集对16种地物进行了标注。地物类别、选取的训练样本数量、确认样本数量以及测试样本数量见表4。
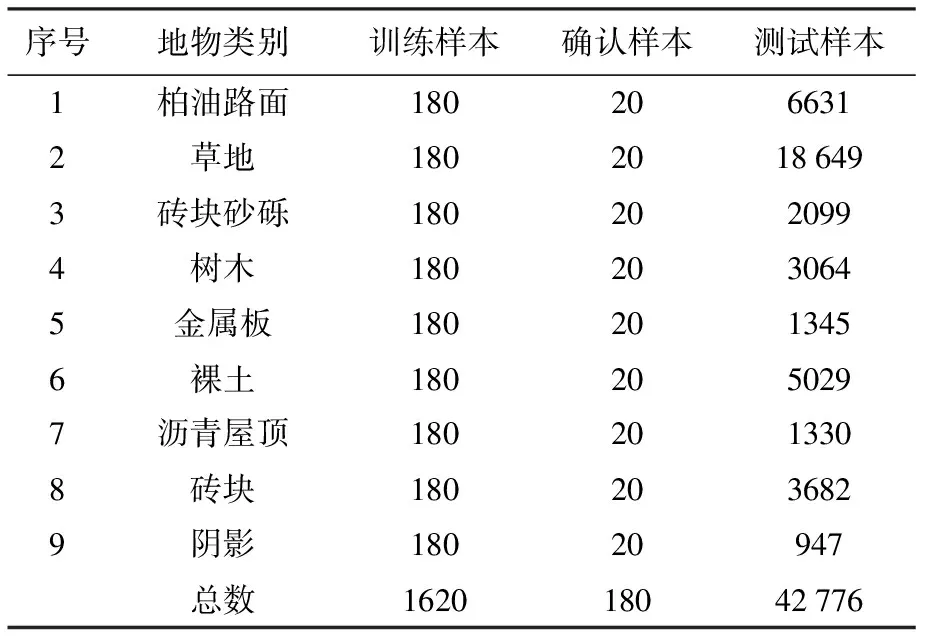
表2 Pavia大学数据集样本信息
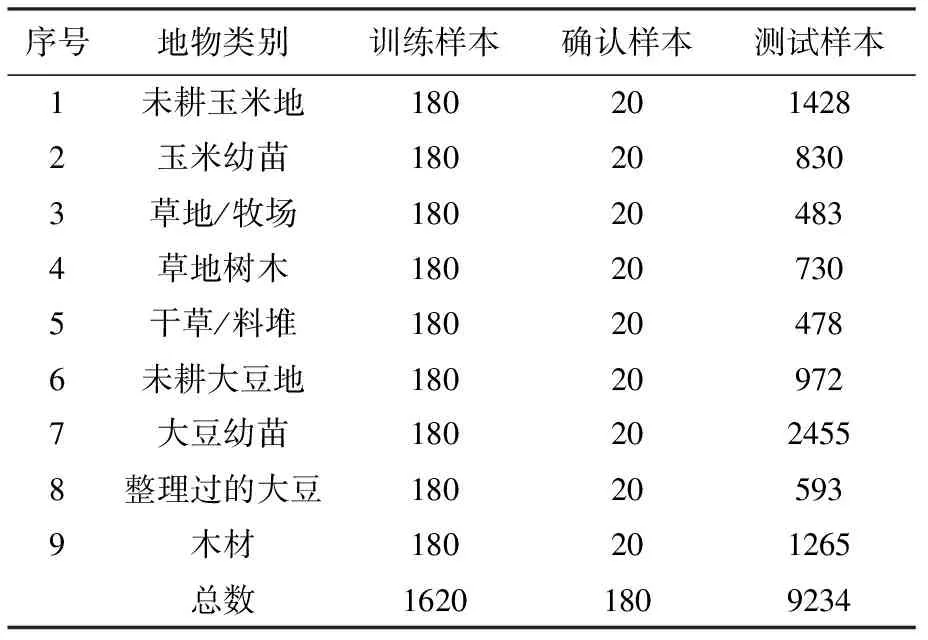
表3 IndianFines数据集样本信息
2.2 试验结果与分析
深度三维卷积网络(Res-3D-CNN)结构的设计参考了计算机视觉领域CNN设计的一般经验,即在更高的卷积层,使用更多的卷积核,例如第1个卷积层中使用8个卷积核,在第2个卷积层在使用16个卷积核。在一个残差结构中所有卷积层使用的卷积核数量相同,以确保捷径和主径特征维度相同。表5给出了不同数据集第一个卷积层使用不同数量的卷积核对应的总体分类精度。表6给出了不同数据集第一个卷积层使用不同数量的卷积核对应的训练时间。由表5—6可知,参数数量随着卷积核数量增加而增加,因此使用更多的卷积核需要更多的训练时间;但分类精度在某个数量的卷积核处达到饱和,继续增加卷积核数量,反而会加剧网络退化现象,从而导致分类精度下降。由于不同传感器获取高光谱数据的光谱维度不同,因此,不同传感器高光谱数据的最优卷积核数量也有所不同。根据表5,对于ROSIS传感器获得的Pavia大学数据最优的卷积核数为32,而对于AVIRIS传感器获得的Indian Pines和Salinas数据最优的卷积核数量为16。
网络结构确定后,利用均值为0、方差为0.1的截断正态分布对卷积层和全连接层的权重进行随机初始化,偏置均初始化为0.1。Dropout参数设置为0.5(即随机关闭隐藏层50%的节点)。采用Adam[26]优化器对网络进行训练,初始学习率设置为0.001。网络训练最大迭代次数为200次,图4给出了训练过程中损失函数和总体分类精度在确认样本上的变化情况,最后选择在确认样本上分类精度最高的模型对测试数据进行分类。每个样本空间邻域大小参照文献[15]设置为9×9,即输入到网络中的每个样本为9×9×B数据立方体,其中为B波段数。

表5 不同卷积核数量对应的总体分类精度
为验证Res-3D-CNN的有效性,分别与SVM、EMPs[25](Extended morphological profiles)、1D-CNN、去除残差模块的浅层三维卷积网络(S-3D-CNN)、与本文网络结构相同但未加入残差结构的三维卷积网络(3D-CNN)进行对比分析。其中不同分类算法的训练数据、确认数据、测
试数据数量均相同,即每个类别地物随机选取200个样本作为训练数据,再从训练数据中随机选取10%作为确认数据集。SVM的核函数为高斯径向基核函数,核函数参数和惩罚系数采用交叉验证的方法在确认数据集上选取最优参数。1D-CNN网络结构与文献[6]中设置相同。EMPs参数设置与文献[25]中设置相同。2D-CNN网络结构与文献[9]中设置相同。1D-CNN、2D-CNN、S-3D-CNN、3D-CNN和Res-3D-CNN均选取在确认数据集上分类精度最高的模型对测试数据进行分类,并与真实地物标记对比评价精度。
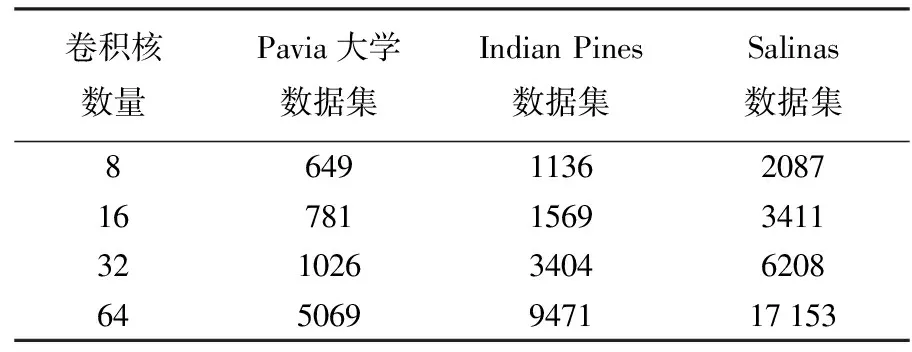
表6 不同卷积核数量对应的训练时间

图4 训练过程中损失函数和总体分类精度在确认样本上的变换情况Fig.4 The loss function and the overall accuracy on the validating sample during the training procedure
表7—9分别给出了3组数据集对应的分类结果。SVM和1D-CNN仅使用光谱特征进行分类,但由于训练样本数量有限的原因,1D-CNN的分类精度低于SVM。EMPs和2D-CNN均能够综合利用空-谱特征进行分类,因此总体分类精度(overall accuracy,OA)、平均分类精度(average accuracy,AA)和Kappa系数较SVM和1D-CNN有较为明显的提升。这是由于单纯利用光谱特征分类存在“同物异谱,异物同谱”问题,而综合利用空-谱特征进行分类,加入了空间约束,因此能够改善分类效果。使用2个三维卷积层、2个池化层和一个全连接层的S-3D-CNN在3组数据集上,较EMPs和2D-CNN算法在总体分类精度、平均分类精度和Kappa系数均略有提升,这说明使用三维卷积网络能够更好地利用高光谱影像的三维空-谱特征,但由于训练样本数量较少,精度提升效果不明显。进一步增加三维卷积层数,使用7个三维卷积层、2个池化层和一个全连接层的深层网络(与本文网络层数相同,但未引入残差结构),3D-CNN的网络结构相比于S-3D-CNN更复杂,但分类精度反而下降。这说明在训练样本有限的情况下,用于高光谱影像分类的三维卷积网络也存在退化现象。为克服网络退化现象对分类精度的影响,同时利用深层网络提取更加抽象的特征来改善高光谱影像的整体分类效果,本文在深层网络中引入残差学习,构建了Res-3D-CNN,并在3组数据集上,OA、AA和Kappa系数相比于其他方法均有明显提高,例如Pavia大学数据集,Res-3D-CNN的OA相比SVM、EMPs、1D-CNN和2D-CNN分别提高了7.14%、5.30%、10.13%和4.19%;Indian Pines数据集,Res-3D-CNN的OA相比SVM、EMPs、1D-CNN和2D-CNN分别提高了6.76%、5.87%、10.45%和3.10%;Salinas数据集,Res-3D-CNN的OA相比SVM、EMPs、1D-CNN和2D-CNN分别提高了3.86%、1.92%、7.83%和1.99%。

表7 不同算法在Pavia大学数据集的分类结果

表8 不同算法在Indian Pines数据集的分类结果

表9 不同算法在Salinas数据集的分类结果
图5—7给出了不同数据集上不同算法的分类图,Res-3D-CNN分类噪声相比于其他方法更少,获得了最好的分类效果。事实上,图5—7的结果与表7—9的结果是一致的。虽然Res-3D-CNN在OA、AA和Kappa系数上相比于其他方法均有明显提高。但对于不同数据集中易于区分的地物类别,Res-3D-CNN分类效果与其他方法相当。如Pavia大学数据集中的第4、5、9类地物,Indian Pines数据集中的4、5、9类地物,Salinas数据集中的除了第8和15类的其他地物类别,这些地物类别的特征与其他地物类别之间区分较为明显,即使使用SVM对光谱特征进行分类也能取得很好的分类效果。Res-3D-CNN对于特征相近容易误分的地物类别的分类精度提升较为明显,因此能改善总体分类效果。
2.3 训练样本数量对分类精度的影响
深度网络已经被证明对于大规模数据的分类识别非常有效。但相对于高维的数据结构,高光谱影像通常能够提供的标注样本较少。为分析训练样本数量对本文算法的影响,从每类地物中分别随机选取50、100、150、200个样本作为训练数据(仍然从训练样本中随机选取10%的样本作为确认数据)进行试验。不同分类算法在不同数据集上的总体分类精度如图8—10所示。由图8—10可知在进一步减少训练样本数量的情况下,Res-3D-CNN的总体分类精度仍高于SVM、EMPs、1D-CNN和2D-CNN算法。

图5 各算法在Pavia大学数据集上的分类结果图及其对应的总体分类精度Fig.5 Classification maps and overall accuracy with different methods on the University of Pavia dataset

图6 各算法在Indian Pines数据集上的分类结果图及其对应的总体分类精度Fig.6 Classification maps and overall accuracy with different methods on the Indian Pines dataset

图7 各算法在Salinas数据集上的分类结果图及其对应的总体分类精度Fig.7 Classification maps and overall accuracy with different methods on the Salinas dataset

图8 Pavia大学数据集:不同训练样本数目对应的总体分类精度Fig.8 Overall accuracy with different number of training samples on the University of Pavia dataset

图9 IndianPines数据集:不同训练样本数目对应的总体分类精度Fig.9 Overall accuracy with different number of training samples on the Indian Pines dataset
为进一步证明Res-3D-CNN在小样本情况下的有效性,从每类地物中随机选取20个样本作为训练数据(仍然从训练样本中随机选取10%的样本作为确认数据)进行试验。表10给出了不同算法的总体分类精度,Res-3D-CNN仍然能够获得最高的分类精度。这也说明了与SVM和现有的基于深度学习的高光谱影像分类方法相比,本文算法即使在小样本的情况下仍然能够有效提高分类精度。但此时EMP和2D-CNN在Pavia大学数据集和Salinas数据集上的分类精度已经接近Res-3D-CNN的分类精度,进一步减少标记样本数量,则无法保证所设计网络模型的优势。因此,为保证Res-3D-CNN的分类效果,分类时每类地物随机选取的标记样本数量不应少于20个。

图10 Salinas数据集:不同训练样本数目对应的总体分类精度Fig.10 Overall accuracy with different number of training samples on the Salinas dataset
众所周知,深度学习需要大量的训练样本,Res-3D-CNN主要从3个方面来解决训练样本数量较少时的深度网络训练问题。首先,大量研究表明在高光谱影像分类过程中充分考虑空间信息对最终分类结果的影响,有助于降低分类的不确定性,从而提高分类精度。为此,Res-3D-CNN利用三维卷积网络来充分利用高光谱影像的空-谱信息。然后,深度学习模型通常需要较多的训练样本,且经常面临梯度弥散问题,即采用反向传播算法传播梯度的时候,随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。为此,Res-3D-CNN在三维卷积网络中引入残差学习结构,来有效缓解梯度弥散问题,使网络的训练变得更加容易。最后,针对训练样本数量较少时,深层网络容易出现的过拟合现象,Res-3D-CNN采用Dropout[27]正则化方法降低过拟合风险。

表10 3组数据集中每类随机选取20个训练样本对应的总体分类精度
3 总结与展望
本文针对高光谱影像分类高维和小样本的特点,利用三维卷积提取高光谱影像的三维空-谱特征,并利用残差学习模块构建深层网络对高光谱影像进行分类。采用Pavia大学、Indian Pines和Salinas 3组高光谱影像数据集进行试验验证。试验结果表明:①三维卷积网络能够直接以高光谱数据立方体作为输入,不需要事先降维预处理,是一种有效的利用高光谱影像空-谱特征的方法;②在选取较少的训练样本的情况下,残差学习模块能够较好地解决深层网络在高光谱影像地物分类时的退化问题,因此,本文构建的深层三维卷积网络能够有效改善整体分类效果。
虽然本文构建的深层三维卷积网络能够在训练样本有限的情况下改善高光谱遥感影像地物分类精度,但改善效果随着训练样本数量的减少而下降。进一步的研究工作将结合样本增强和半监督学习方法,以期使用更少的训练样本数量,获得更高的分类精度。
