基于多字典和稀疏噪声编码的图像超分辨率重建
2019-01-22王真真朱松岩周大可
王真真,杨 欣,朱松岩,周大可
(1.南京航空航天大学 自动化学院,江苏 南京 210016;2.江苏工程技术学院,江苏 南通 226000)
图像超分辨率重建技术的目的是恢复图像细节得到更高质量的图像.近年来,基于稀疏性的超分辨率技术已成为一种主要的图像重建技术,文献[1]显示稀疏编码已经作为一种常用的机器学习技术用于图像处理.文献[2]中,通过提高稀疏编码系数的精确度来提高重建方法的性能.通过学习词典,稀疏性的方法试图找到低分辨率和高分辨率的示例图像之间的一些映射关系作为先验知识,以更好地重建.Zeyde等[3]采用基于主成分分析(PCA)进行降维,并且利用OMP算法进行K-SVD字典训练,对Yang模型[4]在计算时间和重建质量方面进行了改进;此外,Zhang等[5]利用基于PCA的子空间字典训练来对Yang模型进行扩展和延伸,并且用非局部均值(NLM)约束代替反投影约束.与此同时,图像的自相似性也被广泛使用,文献[6]中把自相似学习和基于实例学习相结合,从输入的图像自身和它们的退化版本训练字典,并且设计了一个渐进的放大框架与自学习字典相兼容,证明了自相似学习的有效性;在文献[7]中,利用图像间的冗余信息,根据图像自相似性构造l1范数正则项补偿对,抑制稀疏系数噪声提高重建效果.
但针对用于学习的字典单一、图像退化(噪声、模糊和下采样等)的问题,传统的稀疏模型不足以精确地重建原始图像.因此,本文提出一种多字典学习和稀疏编码约束项相结合的SISR算法.训练过程中,利用聚类结果训练得到不同类别的子字典,以便为重建图像块选择合适的子字典;求解α时,引入稀疏编码噪声,利用图像非局部自相似性来获得原始图像稀疏编码系数的良好估计,然后将观测图像的稀疏编码系数集中到那些估计中,作为约束项来去除噪声的影响.
1 字典训练
图像重建中选择合适的字典是一个关键的问题,但传统的字典学习并没有在最佳的稀疏域[8-9],所有的图像块重建均使用同一个字典,针对此问题,本文在字典训练时,利用图像的特征将它们合理地划分成若干个簇,然后每个聚类训练生成子字典对,通过特征提取和隶属度计算确定最佳字典对,获得更好的重建目标.具体步骤如下:
1)k-means聚类.重建的精确度和有效性取决于合理的特征聚类,在进行聚类时,利用波长、颜色、相位等特征将图像块分为不同的类.将原始的HR图像分为小的图像块{xi},i=1,2,…,p,利用Gabor滤波器对图像块进行特征提取用于聚类,最优的聚类数在2~6,实际的聚类过程由k均值聚类算法[10-11]完成.随机选择K个像素作为初始聚类的中心Ck,计算每个像素到聚类中心的Euclidean距离,将其分为K类,在此过程中,利用式(1)对Ck进行更新,
(1)
其中,Di为簇内像素间距离的平均值,n为簇内像素的个数.第k类中,当Di最小时,相对应的第i个像素被更新为新的聚类中心,若更新后的聚类中心和被替换的聚类中心之间的距离相差较小,则聚类结果对于训练分类字典对是可行的,否则重新进行聚类.
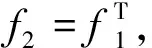
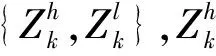
2 改进的SISR模型
2.1 传统的稀疏模型
稀疏重建模型是一个将训练得到的字典中的原子进行线性组合的过程,包括训练字典和求解稀疏表示系数.其模型可表示为下面的约束函数:
(2)
传统模型中,字典(如DCT、小波字典等)的学习并没有在最佳的稀疏域,稀疏过完备字典编码是不稳定.式(2)中的稀疏正则项是为了选择合适的稀疏域,而本文中,用于训练的图像块利用聚类的方法被分成k个类别,训练得到k对子字典,重建的图像块可以选择最优的子字典,使该图像块的编码系数在其他子字典上为0,因此‖α‖1可以删除.
2.2 引入稀疏噪声约束项

(3)
其中αy是所有αy,i的级联.
为了获得更好的IR,就期望式(2)得到的稀疏码αy尽可能接近原始图像的真实稀疏码αx,但由于图像退化过程中,模糊、噪声等的影响,求得的稀疏码αy总会和αx存在偏离,即为稀疏编码噪声υα=αy-αx,图像重建的质量依赖于噪声稀疏编码的水平.由于稀疏编码αx是未知的,所以很难直接计算υα,但若可以对αx进行合理良好的估计即β,则αy-β即为υα的良好估计,随着迭代次数的增加,抑制υα(提高αy)即可以增加重建图像的精确度.
根据稀疏编码系数之间的强非局部相关性,从相似的自然图像块中学习估计β.基于图像的冗余性,从原始HR图像块中获得同尺度的相似图像块数据集;对原始图像以sI(s=2;I=0,-1,-2,-3,-4,-5)倍缩减得到图像金字塔,从图像金字塔中得到多尺度相似图像块数据集,两数据集中图像块大小相同,共同构成相似图像块集Ψ.采用最近邻搜索法来缩短搜索时间,得到Ρ块最近邻的图像块,在搜索的过程中,与图像块xi间的欧氏距离大于设定阈值时既舍弃.搜索得到图像块xi的非局部相似图形块集Ψi,可利用Ψi中图像块的稀疏编码对βi进行加权平均估计.
αi,k为Ψi中图形块xi,k的稀疏编码,Ψi中的图像块大小与xi相同,则对αi的良好估计(即βi)可以通过计算αi,k(l=1,2,…,Ρ)的加权平均值得到:
βi=∑k∈Ψiωi,kαi,k.
(4)
其中ωi,k是权重系数,利用非局部均值[12]的方法,设定权重与图像块间距离成反比:
(5)
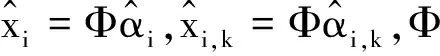
引入稀疏编码噪声后得到的目标函数模型为:
(6)
3 总体算法
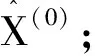
步骤2:通过k-means和PCA训练得到字典Φ;
步骤3:利用最近邻搜索法得到同尺度和多尺度的相似图形块集Ψi,通过公式(5)获得权重矩阵;
步骤4:利用式(4)估计计算βi;
步骤5:将式(4)和式(5)以及求得的子字典Φi代入式(6),利用梯度下降法迭代求解稀疏系数;
4 实验结果与分析
为了验证本文算法的有效性,我们选择图像重建中常用的7幅图进行实验.字典训练时,将7×7网格划分为5个簇,对5个字典对进行训练,字典大小为512,参数λ=0.1.原始HR图像通过模糊降采样(降采样因子为3,加标准差为1.6的7×7高斯噪声)得到LR图像作为输入.重建过程中参数为:图像块为3×3,重叠1个像素,相似图像块的个数取Ρ=10,权值矩阵中h值为10,迭代次数l(l=1,2,…,L),L=240.将本文的算法与ASDS[13]和SSIM[14]进行对比,在主观判断的同时,也通过峰值信噪比(PSNR)和结构相似性(SSIM)来比较重建结果.
图1~2中显示了不同方法的视觉重建结果.图1中(b)和(c)重建结果较为模糊,并且可以观察到沿边缘的锯齿状痕迹,但本文算法中,选择合适的子字典在最佳稀疏域上进行重建,字典中的原子线性组合得到的重建结果更好;在引入稀疏噪声的过程中,去噪的同时,也间接的将自相似性用到了图像的重建中,因此本文重建结果获得了较为清晰的图像边缘,和更为丰富和清晰的图像细节;同时从表1中也可以看到,本文算法的PSNR和SSIM值基本上均高于其他两种算法.
图2中对于带有噪声的图像,通过表2,可以发现由于噪声的影响,其重建效果均低于不带有噪声图片的重建,但本文算法的PSNR和SSIM值依旧高于其他2种算法.对于输入带有噪声的图像,算法通过引入稀疏噪声编码来抑制噪声的影响.图2(b)和(c)虽然也能恢复图像的大部分细节,但边缘仍受锯齿效应的影响,本文算法由于引入了稀疏噪声编码约束项,利用非局部自相似性获得原始图像稀疏编码系数的良好估计,抑制噪声的同时也引入非局部自相似,减小块效应带来的影响和重建时产生的人工痕迹,获得较为清晰的边缘,并且对噪声具有一定的鲁棒性.
从表3可以看出,重建效果并没有随着σ的增大而越来越差,并且σ=20和σ=100相比,PSNR(db)和SSIM几乎没有差别,即在噪声增大的同时,噪声对图像重建结果的影响越来越小,因此可以看出本文算法可以抑制噪声的影响,对噪声具有鲁棒性.
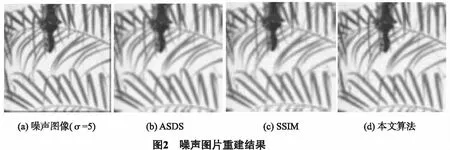
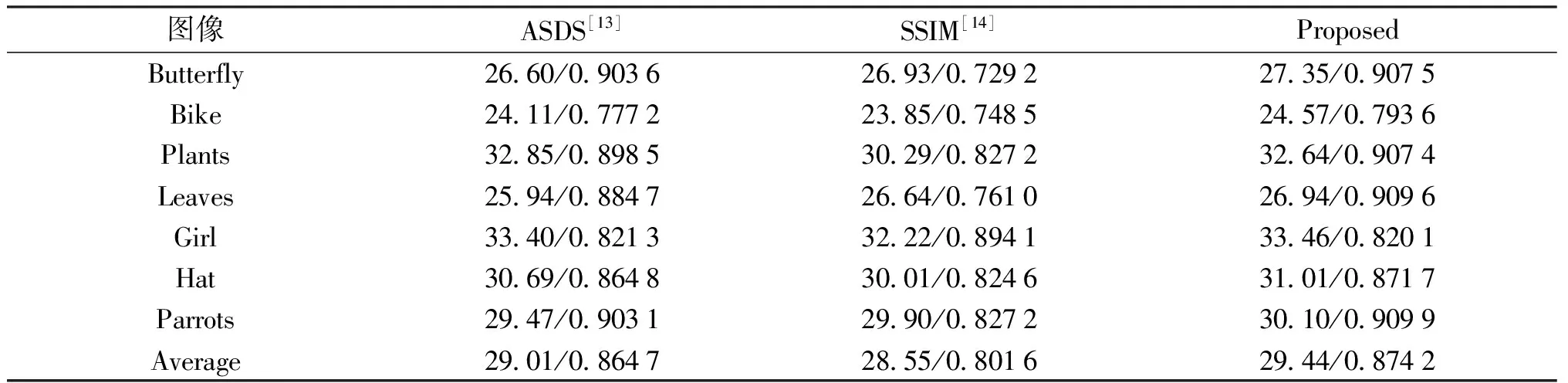
表1 无噪声图像重建结果的PSNR(db)和SSIM对比
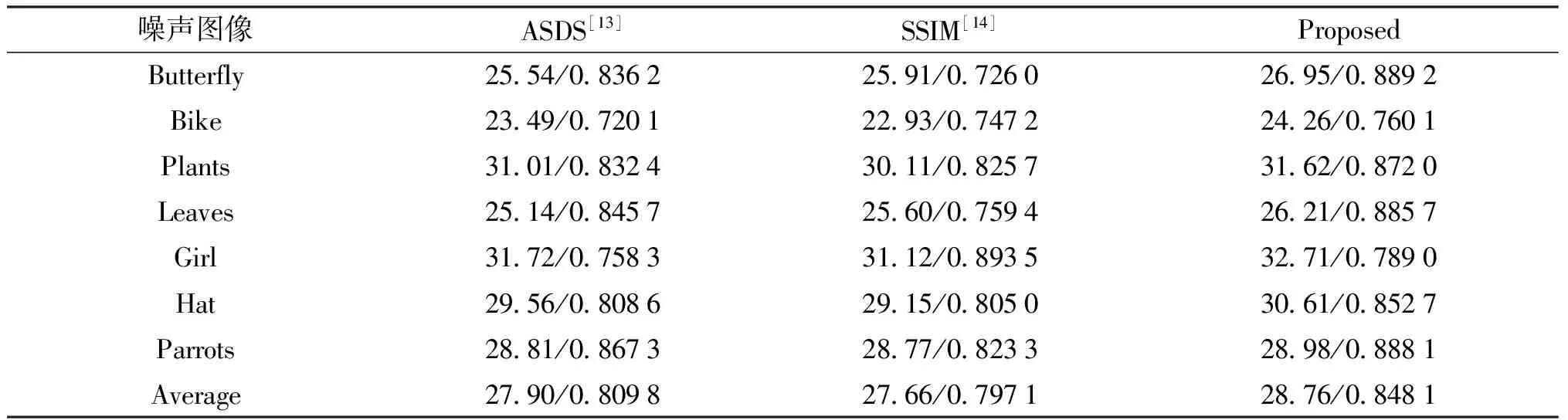
表2 带有噪声图像(σ=5)重建结果的PSNR(db)和SSIM对比
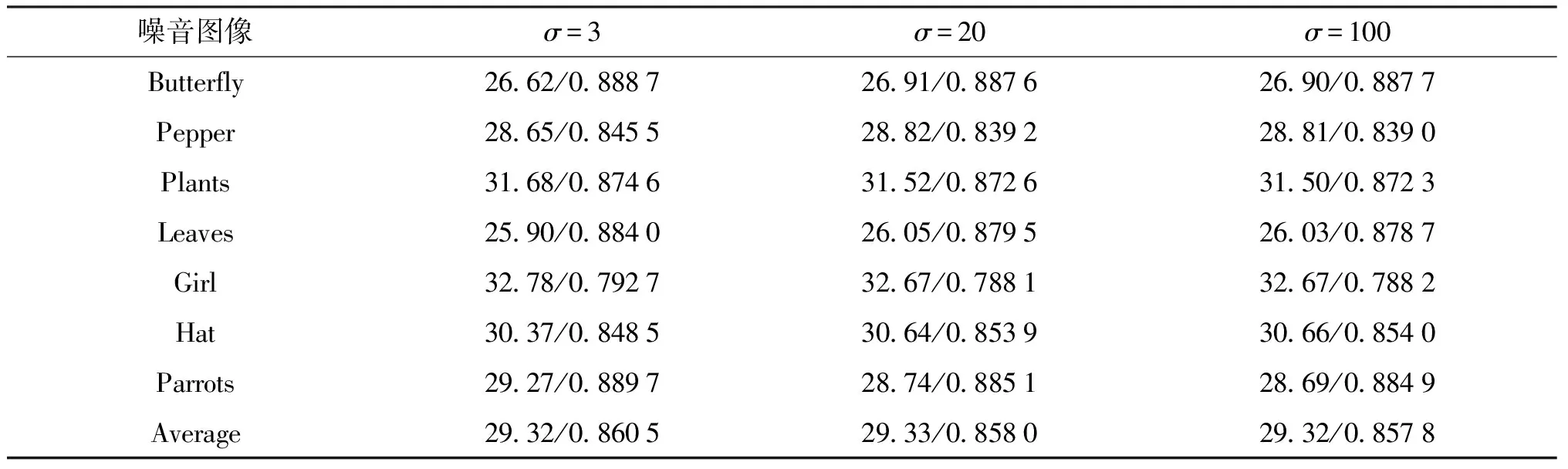
表3 不同σ重建结果的PSNR(db)和SSIM对比
5 结语
本文通过聚类之后训练生成子字典对,并且利用图像非局部自相似性来获得原始图像稀疏编码系数的良好估计,引入稀疏编码噪声.实验表明,与ASDS算法[13]和SSIM算法[14]相比较,本文算法有更好的重建结果,获得了更丰富的图像细节和更清晰的边缘,并且本文的算法对噪声具有一定的抑制作用.
