基于SVM-BiLSTM-CRF模型的财产纠纷命名实体识别方法①
2019-01-18周晓磊赵薛蛟1刘堂亮宗子潇王其乐里剑桥
周晓磊, 赵薛蛟1,, 刘堂亮, 宗子潇, 王其乐, 里剑桥
1(中国科学院大学, 北京 100049)
2(中国科学院 沈阳计算技术研究所, 沈阳 110168)
3(辽宁省人民检察院沈阳铁路运输分院, 沈阳 110001)
4(东北大学, 沈阳 110000)
5(沈阳市第三十一中学, 沈阳 110021)
6(大连理工大学, 大连 116621)
随着国家法制建设不断进步, 人们的法律意识不断增强, 在遇到社会、经济生活中的纠纷时会自然的诉诸于法律审判. 这类案件虽然简单易断, 但由于数量急剧增多使得基层法院承受着十分沉重的工作压力.因此对于简单的财产纠纷案件做到自动审判不但可以缓解基层法官的工作压力使得同类型案件审判一致,更能增强民众用法律武器维护自身权利的动力. 而财产纠纷案件中命名实体的正确识别是完成自动化审判的非常重要的一步.
命名实体识别的目标是从语料中准确识别出专有名词或有意义的数量短语并加以归类[1]. 早期的命名实体识别主要是基于规则和字典的, 这种方法在处理复杂场景时会耗费人们的大量精力而且移植性差. 为了解决这些问题, 又出现了基于机器学习的方法, 但这些方法对特征选取的要求比较高. 而相比于上述的两类方法, 深度学习方法兼具泛化性和较少依赖人工特征的特点, 因此近年来, 深度学习在通用的命名实体识别领域运用广泛. CNN-CRF例如: Collobert等[2]提出了一种模型, 在CNN结构上运用CRF算法将标签转移得分加入到目标函数中. 在CONLL2003语料上取得了比较好的成绩. Huang等[3]通过人工设计拼写特征提出训练了一种BiLSTM-CRF模型, 该模型在CONLL2003语料上的F1值达到了88.83%.
财产纠纷裁判文书的关键实体主要包括案件涉及的财产形式、财产数额等. 经过分析实际的裁判文书后发现, 难点主要在于: (1)纠纷涉及财产形式多样.(2)裁判文书中包含法院认定的涉及纠纷的财产在整篇文书中出现比重较小. (3)财产描述形式多样. 由于BiLSTM-CRF模型在通用领域的效果突出, 于是使用该模型对样本进行了模型训练, 但结果发现实际的输出并不理想. 在分析原因后发现是由于上述第二个难点导致了训练数据的不平衡. 为了解决这一问题, 本文提出一种基于SVM-BiLSTM-CRF的财产纠纷裁判文书命名实体识别模型. 以提高对财产纠纷裁判文书中涉案财产的识别精度.
1 数据集构建
本文通过从中国裁判文书网下载大量财产纠纷裁判文书, 在进行适当的数据预处理并手工标注后构建财产纠纷的语料库. 其中一半作为训练集进行模型训练, 另一半则作为测试集用于评价模型的性能.
1.1 数据预处理
裁判文书是一种半结构化的文本, 通常的结构如图1所示.

图1 裁判文书的结构图
由于审判结果和审理查明的事实与证据存在直接关系, 所以从审理查明的事实和证据中提取的财产命名实体具有研究价值. 通过统计发现, 在审判文书中描述审理查明的事实的起始句包含以下说明词: “经审理查明”, “经审理认定”, “经开庭审理查明”, “经开庭审理认定”, “审理中查明”, “审理中认定”, “确定如下事实”,“认定如下事实”, “认定以下事实”, “查明如下事实”,“查明以下事实”, “本案事实如下”, “查明事实如下”,“确定事实如下”等. 同时, 在需要说明的问题部分起始句包含“本院认为”, 审判结果部分起始句包含“判决如下”. 通过这些触发词, 将审理查明的事实提取出来进行分句、分词、去停用词等处理.
1.2 数据标注
1.2.1 财产类别
我国的《民法通则》对财产有如下定义:财产是指拥有的金钱、物资、房屋、土地等物质财富:国家财产、私人财产, 具有金钱价值、并受到法律保护的权利的总称[4]. 根据上述定义, 将财产分为三种, 即动产,不动产和知识财产. 据此, 本文将审判案件中涉及的财产分别标注为以下几个类别:
动产: 由于财产纠纷案件涉及金钱纠纷比例较大,所以将动产的标注类别细分为money与nonmoney.
不动产: 标注为realestate
知识财产: 标注为intelpropert.
1.2.2 四词位法
在汉语语言文字中, 每个词都是由一个或多个字组成的. 例如: “现金”是两字词, “上轿礼”是三字词. 组成词语的每一个汉字在一个特定的词语中都占据一个特定的构词位置, 即词位. 词位的种类根据研究的需要可以自行定义. 在已有的工作中常用的有四词位标注集(B、M、E、S)和六词位标注集(B、B1、B2、M、E、S)[5]. 在本文中, 采用的是四词位集, 用B表示词的开始, M表示词的中部, E表示词的结尾, O表示其他非财产的字, 并结合财产类别进行标注. 表1是一个标注例子.
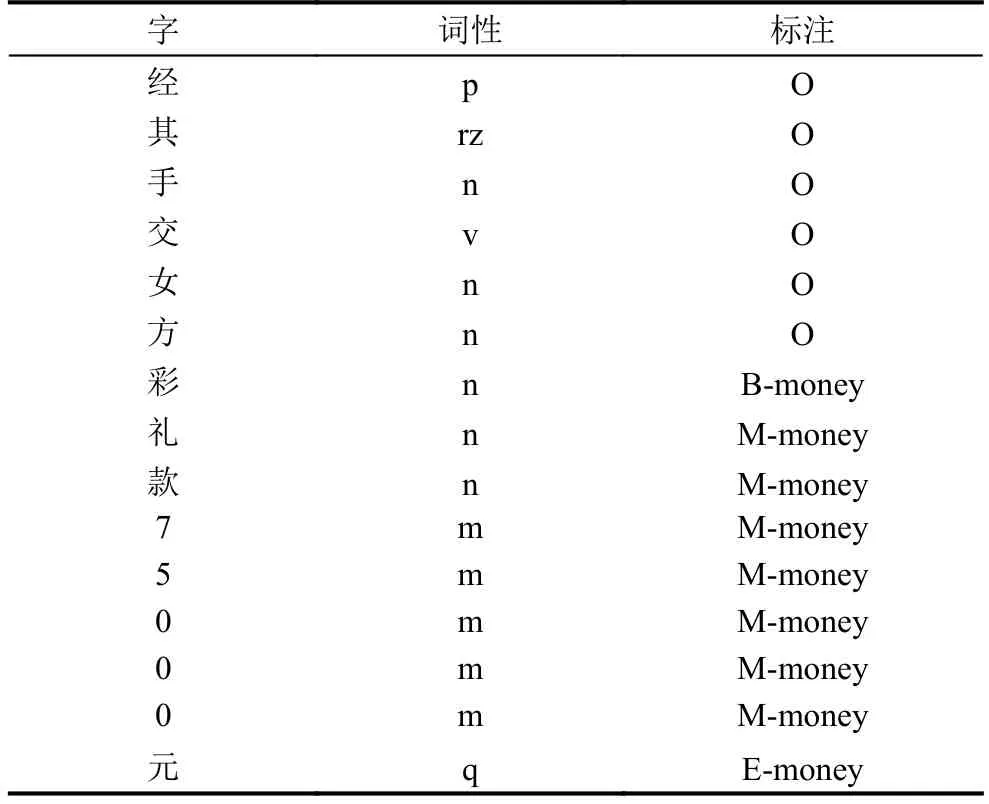
表1 标注实例
2 SVM-BiLSTM-CRF模型
2.1 模型整体框架
SVM-BiLSTM-CRF模型由三个模块组成: SVM模块、BiLSTM模块和CRF模块. 整体模型框架图如图2所示. 首先通过查询词向量表将输入的语句转换成相应的词向量序列, 然后输入SVM进行判断. 如果不含财产实体, 则将所有的字标记为O, 否则则通过查询字符向量表获得相应的字符向量序列. 并将这些字符向量序列输入BiLSTM进行实体识别. 最后CRF模块将BiLSTM的输出进行处理得出一个最优的标记序列.
2.2 SVM模块
支持向量机(SVM)是在VC维理论和结构风险最小化原理基础上建立起来的机器学习方法[6]. 它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器, 在解决小样本、非线性和高维模式识别问题方面表现出特有优势[7]. 因此, 为了解决包含财产实体的句子占案件描述句子的比重不高的问题, 本文使用SVM将无用的句子直接筛除, 使得包含财产实体的句子中进行进一步的标注训练可以保持训练数据的平衡.

图2 财产纠纷案件命名实体识别的SVM-BiLSTM-CRF模型
在训练开始, 首先将训练样本经过分词, 去停用词,在不影响分类精度的情况下利用tf-idf进行特征降维形成词向量表=特征维度. 对于一个句子句子长度, 经过词向量表处理, 形成一个特征向量, 利用核函数与标签一起加入到式(1)中.
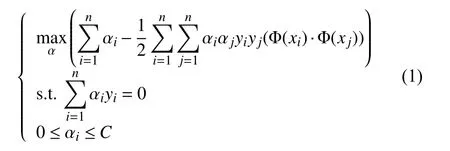
其中,C是惩罚系数,为拉格朗日乘子向量. 这是线性不可分的线性支持向量机的学习问题转化而成的对偶问题. 但是由于求解复杂度过高, 本文采用SMO算法来进行求解.
SMO是John C. Platt于1996年提出一种启发式算法, 其思想是要将原问题分解成一系列小规模凸二次规划问题, 从而获得原问题最优解的方法. SMO算法在每次迭代时选择两个拉格朗日乘子并同时固定其他乘子, 针对选择的乘子构建一个目标函数值更小的二次规划问题, 因为子问题可以通过解析方法求解, 所以可以大大提高整个算法的运算速度. SMO算法的伪代码如算法1.

算法1. SMO算法1) 创建一个并初始化为0向量.2) 当迭代次数小于最大迭代次数时执行循环, 否则跳出循环返回结果.3) 循环遍历数据集中的每一个数据向量, 如果该向量可以被优化, 则随机选择另外一个数据向量, 并同时优化这两个向量. 如果两个向量不能被优化, 则退出循环.4) 如果所有向量都没有被优化, 则增加迭代次数, 进入下一次循环.否则将迭代次数置0, 重新进行迭代.
2.3 BiLSTM模块
长短时记忆网络(Long Short-Term Memory, LSTM)是由Schmidhuber于1997年提出的. 它是一种具有特殊结构的RNN网络, 但是与传统RNN不同, 它解决了由于序列过长而产生的的长程依赖(long-term dependencies)问题. 网络模块示意图如图3所示. 其中包含四层神经网络, 最上面的一条线贯穿所有串联在一起的LSTM单元, 使得LSTM状态从第一个单元开始一直移动到最后一个单元, 在这个过程中只存在少量的线性干预和改变. LSTM采用独特的门结构来控制LSTM单元对信息流中信息的添加和删减. 门结构一共有三类, 分别是输入门 (input gates), 忘记门 (forget gates)和输出门(output gates)[8]. 如果t时刻用、、、分别表示三种门和细胞状态, 则有:


图3 LSTM网络模块示意图
而双向长短时记忆网络(Bidirectional Long short-Term Memory, BiLSTM), 其原理是将两个时序方向相反的长短时记忆网络结构连接到同一输出, 以此来获取历史和未来信息. 因此相比于其他的RNN网络需要等到后面的时间节点才能获取未来信息, 该网络结构可以更充分的利用上下文信息. 我们利用该网络结构这一优势, 用LSTM对每个句子进行前向和后向的计算, 然后将得到的两个结果向量进行拼接得到最终的隐层表示.
2.4 CRF模块
由于单独使用BiLSTM生成的结果可能在标注序列并不是全局最优, 为方便后续通过标注提取完整的命名实体, 提高实体识别的正确率和召回率, 所以本文在BiLSTM层上加上一个线性CRF模块. 通过分析相邻标签的关系以获得一个全局最优的标记序列. 对于一个经过BiLSTM处理后的输出矩阵P,P的大小是, 其中是句子中包含的词数,表示标签的种类.其中为该句第i个词映射到的非归一化概率, 然后引入状态转移矩阵, 其中表示时序上从第i个状态转移到第个状态的概率, 则对于一个观测序列的对应的标记序列, 定义分数为:
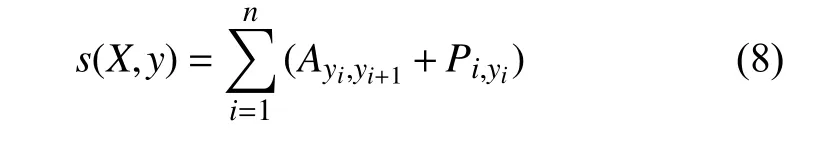
3 结果
3.1 评价指标
本文分别使用准确率、召回率和F1值三个评价指标来对实验结果进行评价. 三种评价指标的表达式分别为:

其中, 准确率(Precision)为测试样本中识别正确的命名实体数量占总的命名实体数量的比例. 召回率(Recall)为正确识别为财产命名实体的数目占实际财产命名实体总数的比例.F1值则是当beta为1时对上述两个评价指标的加权平均.
3.2 实验比较
为了有效验证本文提出模型的合理性并证明模型中每个模块的必要性, 在仿真实验中得到SVMBiLSTM-CRF模型的相关数据后, 又分别进行了BiLSTM-CRF模型、SVM-LSTM-CRF模型以及SVM-BiLSTM模型在测试集上的性能评价实验. 并通过整合四次实验的结果, 进行了数据对比. 对比结果如表2所示.

表2 对比实验结果(单位: %)
3.3 结果分析
(1) 移除SVM模块结果分析
由于提取出的财产纠纷案情包含财物命名实体的比例并不大, 所以会有大量标注为O的实体存在, 在未包含SVM模块的模型中, 训练得到的模型由于标注为O的实体占比过多, 造成了虽然准确率非常高但是召回率很低的情况. 而本文提出的模型比不包含SVM模块的模型的F1值高出36%, 精确度高出13%.
充分证明SVM模块在本模型中的重要作用.
(2) 替换BiLSTM模块结果分析
从SVM-LSTM-CRF模型与SVM-BiLSTM-CRF模型的结果数据对比中可以看到, 本文所提出的模型比使用LSTM的模型准确度高4%, 召回率高7%. 结果表明双向长短时记忆网络通过提取句子的上下文信息, 对结果产生了积极作用.
(3) 移除CRF模块结果分析
在本文提出的模型中, 线性CRF模块的主要作用就是根据相邻标签之间的关系优化神经网络输出的结果标签. 从实验数据中可以看到, 有CRF模块会比无CRF模块F1高2%, 召回率高4%. 在结果分析中发现,CRF对长度较大或带有形容词的实体识别性能较高,诸如“彩礼人民币九万九千五百元”、“‘海尔’牌电冰箱一台”等都能被SVM-BiLSTM-CRF正确识别, 但是SVM-BiLSTM则无法正确识别. 由此可见线性CRF模块的加入有助于提高模型的识别精度.
4 结论
本文针对财产纠纷审判文书中的财产实体识别问题进行了研究, 提出了通过SVM首先进行筛选判断是否包含财产实体, 然后通过神经网络和CRF进行进一步识别的方法. 为了训练模型和验证模型的有效性, 构建了裁判文书标注数据集. 实验最后的结果表明, 本文提出的SVM-BiLSTM-CRF模型在对财产纠纷审判文书中的关键实体识别有非常高的准确率和召回率, 从而能够为后续的财产纠纷审判案例自动判决工作奠定基础.
