基于文本情感分析的共享单车用户满意度研究①
2019-01-18冒小栋
冒小栋, 范 涛
(华东交通大学 经济管理学院, 南昌 330013)
近年来, 网络口碑以用户评论真实客观的优点逐渐替代了传统的口碑. 相比于通过线下调研方法获取消费者对产品的态度, 网络口碑能够帮助企业在更短时间内以更低成本获取到目标消费群体的反馈信息.随着互联网经济的迅猛发展, 滴滴等网约车平台解决了人们打车难的问题, 共享单车无桩车的出现有效地解决了“最后一公里”难题. 共享单车是共享经济的模式创新, 它正处于“青春期”, 仍然面临着众多挑战. 通过网络口碑研究共享单车用户满意度, 有助于把握用户真实和潜在的需求及期望, 并为改进单车的服务水平提供依据.
目前, 对于网络口碑的研究, 李刚等学者利用依存句法分析设计情感标签抽取模型, 通过情感极性对情感标签进行过滤, 获得具有较高的抽取准确率和召回率的情感标签抽取方法[1]. 魏慧玲通过构建情感词典,并结合语义相似度算法, 对小米手机的在线评论进行情感分类, 实现对人工汇总的主要商品特征的情感判断[2]. 徐勇等人借鉴相关学者的研究结果, 建立电子商务商品评价指标结构模型; 通过机器学习, 利用文本情感分析中语句情感标签抽取与标注的方法, 对淘宝网站商品进行模糊综合评价[3]. 吴江等学者采用LDA模型对小米、华为和Fitbit智能手环在线评论的主题进行挖掘, 了解用户对不同品牌的关注点; 通过对网站上三种品牌智能手环的评论分值进行独立样本t检验来比较三种品牌智能手环的用户满意度[4]. 李勇敢等学者基于依存句法和无监督主题情感模型设计出一个可自动批处理中文微博信息的情感分析系统, 并且验证该方法具有准确率高、自动化程度高、系统效率高的优点[5]. 对于共享单车的研究, 谭袁学者提出了共享单车的各种违规现象与运营商之间的“底线竞争”有直接的关系, 并要求运营商制定自律性规范并严格执行来解决该问题[6]. 黄国清, 陈雪两位学者将UTAUT模型与情景感知理论相结合, 通过问卷调查的方式, 探究共享单车用户使用意愿的影响因素[7].
查阅相关文献, 发现鲜少有学者通过网络口碑研究用户满意度, 利用LDA模型和文本情感分析相结合对用户满意度进行模糊综合评价的文献更少. “摩拜”单车为目前较受欢迎的共享单车. 因此, 本文基于LDA模型构建“摩拜”共享单车用户满意度结构模型, 设计情感标签抽取算法, 利用HowNet情感词典和语义相似度算法判断评价对象的情感倾向, 并利用模糊综合评价法探究“摩拜”单车的用户满意度.

图1 探索共享单车用户满意度流程图
1 数据来源及研究方法
1.1 网络评论语料库的建立
本文以“摩拜”单车评论为研究对象, 从360手机助手、应用宝以及华为手机助手三个网站上利用网络爬虫获取“摩拜”单车2017年8月至9月共23 306条评论数据. 为了保证数据的有效性, 除去包含特殊符号、英文字符、与评论无关以及重复的数据. 通过对清洗后的评论数据进行观察分析, 利用“摩拜”评论中出现的专属词汇及新型词汇构建用户词典, 然后进行jiebeR中文分词及词性标注, 进而建立“摩拜”单车用户满意度的网络评论语料库.
1.2 LDA模型
本文用LDA模型对网络评论语料库中的文本数据进行挖掘, 识别出文本数据中蕴含的共同主题信息,建立共享单车用户满意度结构模型. LDA是一种无监督的文档主题生成模型, 用来识别大规模文档的潜在主题信息. LDA模型可视为一个三层贝叶斯概率模型,将每一篇文档表示为一个主题的概率分布, 又将每一个主题表示为一个词语的概率分布, 形成文档-主题-词语三层概率分布, 即:

文档主题分布P(topic|document), 指不同主题在同一个文档中所占比重. 文档词语分布P(word|topic), 指每个主题中不同词语出现的概率. 文档词语分布P(word|document),指每个文档中不同词语出现的概率.在计算LDA模型的相关分布时, 我们需要剔除网络评论语料库中的停用词. 在应用LDA模型时, 需要确定三个参数: 主题数量K, 超参数α和β. 我们通过计算困惑度及多次实验对比, 最终设定K=16,α=0.1,β=0.05,循环迭代次数为5000次, LDAvis可视化展示见图2.图中的参数λ用来调整词语与主题之间的相关性, 如果λ越接近1, 则会显示在该主题下出现最频繁的词语, 可通过这种方式了解该主题下用户讨论的热点词汇; 如果λ越接近0, 那么结果中会显示在该主题下更特殊、更独有的词语, 则可以了解到该主题下区别于其他主题的独有词语. 本文设置λ=0, 显示主题下更独有的特殊词语, 更好地体现主题之间的差异.

图2 LDA模型挖掘文本主题
1.3 基于依存句法分析的情感标签抽取算法
文本情感分析, 就是对产品评论中的文本数据进行挖掘, 识别出消费者对评论信息的观点、喜恶、情感等. 情感标签抽取的任务就是识别产品网络评论语句中意见持有者对于一个或多个评论对象的具体评价,并将其按照对应的关系细粒度地抽取出来[2]. 情感标签由评价对象、程度副词、否定词和情感词组成. 情感标签的抽取规则如下:
规则一. 通过依存句法分析抽取产品评论语句中的评价对象词及情感词. 依存句法分析能够识别句子中各单位成分之间的修饰关系. 从生成的句法依赖关系树, 筛选出符合条件的修饰关系[3], 并依据评价对象与情感词抽取规则(表1), 提取评价对象词及相应的情感词.

表1 评价对象与情感词抽取规则
规则二. 查找产品评价语句中依赖于情感词的否定词及程度副词. 为了避免分词时将部分情感词中的否定词与情感词分开, 如可能将“不喜欢”分为“不”和“喜欢”, 导致情感发生错乱. 因此, 我们建立否定词库V, 依据否定词抽取规则 (表2), 若存在否定词修饰情感词时, 应该给予“评价对象—情感词”对否定标记. 同时,筛选出HowNet情感词典程度集中类别为“极其、最”、“很”下的程度副词, 建立程度副词库G, 依据程度副词抽取规则(表2)判断是否有程度副词依存于情感词, 并给予“评价对象—情感词”对相应的程度副词标记.

表2 否定词与程度副词抽取规则
按照规则一、规则二抽取出语句情感标签, 接下来, 需要判断用户对评价对象的情感倾向值. 用户对评价对象的情感倾向值由情感词、程度副词及否定词三部分组成. 其中, 情感词的分值采用HowNet情感词典和基于同义词林的词语相似度算法[8]来判断. 如果情感词为褒义, 情感词值为“1”; 如果情感词为贬义, 它为“-1”. 当存在程度副词修饰情感词时, 用户对评价对象的情感强度被加强, 变为原来的2倍. 若“评价对象—情感词”对存在否定标记, 用户对评价对象的情感极性发生变化. 最后, 用户对评价对象的情感倾向值有4 种可能, 分别为-2, -1, 1 和 2.
2 基于层析分析法的模糊综合评价
本文选取模糊综合评价法来评价共享单车的用户满意度. 模糊综合评价法是以模糊数学为基础, 应用模糊关系合成的原理, 能够将定性评价定量化, 依据用户对评价指标满意程度的隶属度建立模糊评价矩阵, 结合层次分析法确定用户的整体满意度. 模糊综合评价法的建模步骤如下:
(1)确定模糊综合评价指标体系. 在对LDA挖掘出的文本主题进行命名时, 我们发现主题间并不是完全独立的, 存在多个主题描述单车特征不同方面的情况. 因此需要先对文本主题进行归纳, 然后进行主题命名, 建立共享单车用户满意度评价指标体系, 如图3. 其中, 用后心情描述了用户在使用单车后的整体体验, 不是针对具体的某个方面, 是整个使用过程的一种总结性感受; 单车押金反响包括用户对使用共享单车所需交付的押金的金额、退还速度的反响情况; 软件整体性能指用户使用共享单车APP的整体感受, 涉及的情感标签如: “操作简单”, “界面流畅”, “软件不错”等.

图3 共享单车用户满意度结构模型
(2)确定评语集. 在评价共享单车的用户满意度时,将产品特征的情感倾向得分: “-2”、“-1”、“1”、“2”,与“很低”、“较低”、“较高”、“很高”4 个水平等级对应. 评语集可表示为:V={很低、较低、较高、很高}.
(3)确定评价指标的权重. 共享单车用户满意度模糊综合评价是基于多指标、多层次的综合性评价, 是由10个指标形成的评价体系. 综合性评价最重要的环节就是决策每层的每一个指标对共享单车用户满意度的影响程度, 并将各指标的影响程度作为该指标的权重.本文选择层次分析法[9]确定各指标的权重, 其步骤如下:
第一步: 构建两两比较判断矩阵. 层次分析法的计算基础是两两比较判断矩阵, 判断矩阵体现了各指标的相对重要程度, 对决策结果的影响至关重要. 本文决定采用共享单车用户满意度评价指标体系中每个指标提取的特征情感词对数量, 作为构建两两比较判断矩阵的依据.
第二步: 计算指标权重及一致性检验. 首先, 计算两两比较判断矩阵的最大特征根 λmax及其对应的特征向量x=(x1,x2,···,xn)T, 对该特征向量进行归一化处理, 得到评价指标的权重向量. 其中, 所有的两两判断矩阵的CR值均接近于0<0.1, 说明一致性检验通过.
(4)确定模糊评价矩阵
本文在确定模糊评价矩阵时选用模糊统计的方法,与其他学者选用主观确定、比较法、专家法等方法来确定模糊评价矩阵相比, 这里提出的方法可以更好的反映客观事实. 采用模糊统计的方法, 若某指标下的评价对象数为n, 该指标隶属于V中某等级评语的隶属度:

隶属度rm表示对于某个指标, 有1 0 0rm%的用户将它评为m等级. 最后, 依据隶属度确定若干指标对应的模糊评价矩阵.
(5)共享单车用户满意度综合评价值
在模糊评价矩阵和权重向量确定之后, 用模糊评价矩阵和权重向量进行综合, 即可得到“摩拜”单车用户满意度评价体系的准则层和目标层下各指标的模糊评价矩阵. 假设准则层下的各指标的模糊评价矩阵为(i=1,2,3,4), 指标层下的指标权重向量为Wi(i=1,2,3,4),准则层下各指标的模糊评价矩阵为Ri(i=1,2,3,4). 其中,i表示准则层的第i个指标;由准则层下各指标对应的指标层下各指标的隶属度组成. 本文的模糊算子均采用加权平均算子, 则假设“摩拜”单车用户满意度评价体系的目标层的模糊评价矩阵为S.W代表准则层下指标的权重向量,R代表目标层的模糊评价矩阵. 其中评价体系中指标Aij的用户满意度为:指标的得分为:; 单车用户满意度的综合得分
3 实证分析
对“摩拜”单车的用户满意度进行实证分析. 首先,利用情感标签抽取算法识别产品网络评论语料库中的评价对象及其相对应的程度副词、否定词和情感词.将HoweNet情感词典与语义相似度算法相结合, 判断评价对象的情感倾向值. 然后, 将情感标签中的评价对象与“摩拜”用户满意度结构模型的10个指标对应的关联词语进行匹配并归类, 对未成功归并的词语再进行人工判断. 接下来, 结合用户对评价对象的情感倾向,采用模糊综合评价法对共享单车用户满意度进行评价.
(1)共享单车用户满意度评价. “摩拜”单车的用户满意度综合分值为0.6877. 其中, 用户的整体体验、单车的性能、用户使用单车的经济成本、摩拜公司的运营服务四个指标的分值依次是1.1651、0.5791、0.5880和0.1062. 这里的整体体验不针对具体的某方面, 是用户使用单车后的总结性感受. 从整体看, 四个指标值都是正向的, 且用户使用单车的整体体验分值最高, 表明用户对“摩拜”单车总体较满意. 具体表现为:
第一, 在单车性能方面, 单车硬件在10个指标中的排名第二, 用户满意度较高. 这里的单车硬件主要指除车锁外, 自行车的各个组成部件、骑行的舒适度、外观及质量. 然而, “摩拜”单车的车锁得分接近于 0, 满意度较差, 问题主要集中在扫描二维码时出现闪退, 开锁失败等.
第二, 在经济成本方面, 单车费用及优惠指标的满意度较高, 表明对于消费者来说, “摩拜”的使用费用合理, 深受用户的青睐. 但是消费者对单车所需支付押金的反响不好, 支付押金多及不能及时退还致使用户的满意度较差.
第三, 在公司运营服务方面, 用户的满意度排名居后. 其中, 单车投放量、单车维修情况及软件的定位三个指标的得分值为负, 表明“摩拜”公司仍应注意用户对单车的需求量, 加强工作人员对车辆的定期维护工作. 同时, 公司要在APP上加大科技投入, 加强对GPS定位系统的维护, 除去不存在定位系统的车型. 这里的单车维修情况主要体现在消费者使用单车时, 故障车出现的频率; 客服对用户的回应指客服咨询电话是否通畅及服务态度; 软件整体性能指“摩拜”APP的操作流畅性以及软件界面设计.
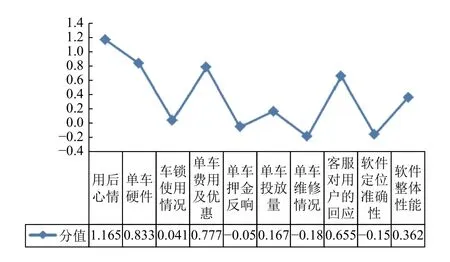
图4 用户对“摩拜”单车各项指标的满意度
(2)结果可靠性的验证分析. 为了验证结果的可靠性, 本文对“摩拜”单车用户满意度结构模型指标层中表现突出的指标进行反查, 即分析10个指标中分值较低和较高的指标所对应的具体评论内容. 结果表明表现突出的指标所对应的评论内容与满意度结果一致.以“摩拜”单车硬件为例, 图 5 中, 字数越大, 说明其出现的频率越高. 从图中可以看出, 从整体来看, 单车硬件指标下的的评价对象情感倾向值大多为正向的, 且出现频率较高的评价对象的情感得分值都为正, 得分为2的情感标签也比较多, 表明验证结果可以通过.

图5 “摩拜”单车硬件的情感标签及情感倾向值
4 结论与展望
网络口碑保证了用户评论的真实性和客观性, 能够帮助企业在更短时间内以更低成本获取到消费群体的反馈信息, 通过网络口碑来研究用户满意度为我们带来了极大的便利. 本文将文本挖掘与模糊综合评价法相结合来分析用户满意度, 这种方法同样适合于其他领域基于网络口碑的用户满意度研究. 针对本次研究, 提出以下几方面的展望: ① 进一步优化分词方案;② 进一步完善共享单车用户满意度结构模型, 适当加入一些评论内容之外的指标, 比如: 网络评论的数量;③ 研究不同时间段的用户满意度, 并进行显著性分析来检验它们之间的差异; ④ 将不同品牌共享单车的用户满意度进行横向比较研究, 以期各品牌能够相互借鉴、取长补短.
