基于GDBN网络的文本情感倾向分类算法①
2019-01-18陈颖熙廖晓东苏例月
陈颖熙, 廖晓东,2,3, 苏例月, 陶 状
1(福建师范大学 光电与信息工程学院, 福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室 福建省光子技术重点实验室, 福州 350007)
3(福建师范大学 福建省先进光电传感与智能信息应用工程技术研究中心, 福州 350007)
1 引言
近年来, 随着互联网信息技术的高速发展, 各种社交平台和电子商务平台的兴起使得门户网站上的评论信息呈指数增长, 用户通过移动网络可以方便、自由的对人或事进行评价与分析, 表达自己的看法、观点以及情感倾向[1]. 面对线上各大平台的大量无规律的评论词语和文本内容, 有必要利用自然语言处理技术建立一种智能高效的文本情感分类模型对文本所表达的情感倾向(正向、负向、中立)进行分析判断, 从海量无规律的文本数据中提取重要的信息.
目前, 互联网上的信息大多以短文本的形式存在,例如淘宝商品评论、搜索引擎的搜索结果、微博、豆瓣、文档文献摘要等. 其中在微博评论中就有明确规定字数必须限制在140字以内. 由于短文本具有特征稀疏性、实时性、动态性、交错性、不规则性等特点[2],传统的文本情感分类方法对其分类的准确率较低, 无法达到理想的结果.
短文本在搜索引擎、论坛信息交流等方面具有重要作用, 因此对短文本情感分类的研究具有一定的实用价值并且得到了广泛的关注. 近些年国内外学者们提出了许多在文本情感倾向性分类的有效的方法, 大致可分为三大类, 即基于规则的方法、基于机器学习的方法和深度学习方法.
基于规则的方法最早是由麻省理工媒体实验室的Picard教授提出[3], 它通过将文本中表达情感倾向的词语与已建立的情感词典对比然后进行评估打分, 进而通过计算分数实现文本情感倾向性分类. 由于该方法过分依赖于人工构建的词典, 所以存在一系列缺点, 如词典覆盖面窄、易丢失部分有挖掘价值的文本数据、易受到一词多义的影响等,并且该方法难以捕捉到深层次特征.
基于深度学习的文本情感分类方法是近几年的研究热点, 它广泛应用于计算机视觉领域和音频领域, 近几年才被引用到自然语言处理领域中, 其中深度置信网络(Deep Belief Networks, DBN)[4]是最经典的深度学习神经网络之一, 它弥补了机器学习方法的局限性, 可以通过网络模型自动地学习提取文本的深层次特征,但是存在隐层单元个数的选择问题. 深度置信网络的隐层单元个数通常依据经验进行认为选择, 且一旦选定则无法修改. 当隐层单元数超过所需个数时, 多余的隐层单元会增加网络的复杂度, 使得计算量变大从而导致训练时间呈指数增长; 当隐层单元数低于所需个数时, 由于网络无法满足训练所需规模, 从而导致达不到理性的训练结果. 因此, 本文提出了GDBN网络(Genetic Deep Belief Networks), 通过利用遗传算法 (Genetic Algorithm, GA)[5]的全局快速寻优的能力对DBN的隐层单元个数自动进行设定. 实验结果表明, 本文所提出的GDBN网络在文本情感倾向性分类中能取得较好的分类效果.
2 相关工作
2.1 深度置信网络
深度置信网络(Deep Belief Networks, DBN)最初是由Hinton等学者于2006年提出的一种由多层RBMs堆叠和一层反向传播(Back Propagation)网络组成的深度学习神经网络[4]. DBN的主要任务是实现对数据从底层到高层的特征提取, 帮助系统将数据分类成不同的类别. 其网络结构如图1所示[6].
DBN的训练步骤分为两步: 第一步为预训练, 对网络中RBMs采用逐层无监督的方法来学习各层参数, 使得每层RBM达到最佳特征表示; 第二步为微调,将BP网络输出数据和标准标注信息进行对比, 对从下往上的认知权重w和从上往下的生成权重进行反向微调, 以得到更好的生成模型.
近些年来学者们在DBN模型上提出了一系列的改进, 使得改进后的模型能够更高效的应用于文本检测. 例如, Mleczko等[7]在DBN模型的基础上引入粗糙集理论(RDBN), RDBN模型主要用于识别与分类具有缺失文字的文本信息. Jiang等[8]提出将采用不同参数优化算法的Softmax分类器与DBN模型结合, 利用分类器对DBN所提取到的文本数据特征进行分类, 该模型能有效地提高分类精度.
2.2 RBM预训练过程
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[9]是以玻尔兹曼机为基础的改进算法, 它是一种具有快速学习和简单网络结构的无监督训练特征提取器. 其结构模型如图2所示.

图2 RBM结构模型图

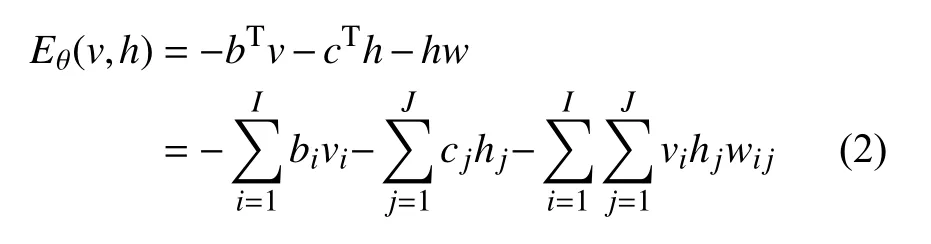

(2) Gibbs采样. 通过Gibbs采样得到
训练时, 采用逐层无监督的方法来学习参数. 进而完成DBN的预训练过程.
2.3 BP网络微调过程
RBM训练中无监督学习方法只能使得该层单元状态达到局部最优, 然而并不能使模型整体效果最优,因此, 采用BP网络[12]对整个网络的参数进行微调. 在RBM完成预训练后, 将RBM训练好的数据正向传播,做为BP网络的输入, 当输出数据和标准标注信息有误差时, 利用BP网络的误差反向传播的特性, 对从下往上的认知权重w和从上往下的生成权重以及偏置进行微调, 让整个网络的单元状态达到全局最优, 以得到更好的生成模型.
3 GDBN情感分类算法
本文提出的基于GDBN网络的文本情感倾向性分类算法的主要工作有: 首先通过网络爬虫程序从微博平台上采集实验所需文本数据, 之后对文本数据进行预处理, 然后通过遗传算法来改进深度置信网络模型, 并以此模型进行深层建模与特征提取, 最后通过反向传播网络对提取到的特征进行情感倾向性分类.
3.1 GDBN理论基础
遗传深度置信网络(GDBN)是结合遗传算法(Genetic Algorithm, GA)[5]和深度置信网络(Deep Belief Networks, DBN)[4]的学习方法, 它利用遗传算法的全局寻优搜索能力对DBN的隐层单元个数进行自动寻优,结合DBN强大的数据特征提取和处理高复杂度的非线性数据的能力, 使网络模型效果更接近于其上限.GA具有较强全局寻优搜索能力, 然而它最大的缺点就是易出现“早熟”现象, 即容易陷入局部极值, 导致神经网络参数质量不高, 所以在设计GDBN算法的遗传操作中, 增大交叉率和变异率. GDBN算法设计如下:
(1)编码
(2)适应度函数
GDBN网络模型中可见层和隐层之间表现为层内无连接, 层间全连接, 隐单元的状态只与可见单元有关, 所以在函数设计时不但要考虑样本的似然程度还要考虑维度对模型训练的影响.
本文采用重构误差[13]的方法来评价样本的似然程度, 所谓重构误差就是通过Gibbs采样重构的单元与训练样本原始数据的平方差, 其具体流程如下:


式中,I为可见单元个数,S为样本维度, 根据适应度的大小对个体进行选择, 当适应度值越大时, 则个体越好,即该个体对应的GDBN模型似然度最高.
(3)遗传操作
在遗传算法(GA)改进网络模型后, 进一步优化精调真个模型, 其算法流程如图3所示.

图3 算法流程
3.2 框架实现
(1)文本预处理: 将通过爬虫得到的数据内容进行处理, 将其中涉及到个人隐私、url链接或敏感信息的内容删除.
(2)分词、去停用词: 由于中文评论无法像英文评论一样直接通过空格来分隔单词, 所以本文采用Jieba工具, 进行中文分词, 并去掉停用词, 如“的”、“和”等一些出现频率高但无情感意义的词, 为特征提取提供较为准确的基元.
(3)特征提取: 通过GDBN网络模型进行深层建模与特征提取.
(4)情感分类: BP网络对提取到的特征进行情感倾向性分类.
4 实验验证及结果分析
4.1 实验环境与数据
本文具体实验环境如表1所示.
为了验证本文所提出的分类算法的有效性, 本文基于三个中文文本数据集进行实验验证. (1)使用中科院谭松波教授的酒店评论语料(D1), 该语料采集于携程网, 规模为 10 000 篇, 被整理成 4 个子集, 1、ChnSentiCorp-Htl-ba-2000: 平衡语料, 正负类各 2k; 2、ChnSentiCorp-Htl-ba-4000:平衡语料, 正负类各 4k; 3、ChnSentiCorp-Htl-ba-6000: 平衡语料, 正负类各 3k; 4、ChnSentiCorp-Htl-ba-10000: 非平衡语料, 其中正类为7k. (2)使用COAE2014微博观点数据集, 在该数据集中随机抽取30 000条作为实验数据集, 对其中部分训练数据进行不同情感倾向的人工标注, 主要情感有开心、愤怒、厌恶、低落四个类别. (3)通过网络爬虫程序从微博平台上采集的50 000条微博数据(D3), 其中标注的积极微博有25 000条, 消极微博有20 000条,中性微博有5000条. 考虑到其中部分能容可能含有用户隐私, 删除了数据集中的url链接等信息.

表1 实验环境
4.2 实验设计
实验方案总体过程如图4所示.

图4 实验方案
首先对训练数据进行预处理, 生成文本特征向量,然后将训练后的GDBN情感分类模型用于测试数据分类并检验分类效果.
4.3 性能评估
precision主要体现模型对负样本的区分能力, 通常用P表示, 设TP为分类正确的文本数,N为样本总数,其计算公式如下:

recall主要体现模型对正样本的识别能力, 通常用R表示, 设N+为某一类的样本总数, 其计算公式如下:

F1值为两者的综合, 当F1值越高时证明模型越好. 其计算方法如下:

4.4 实验结果与分析
为了验证本文提出的基于GDBN网络的文本情感倾向性分类算法的有效性, 将SVM、DBN与本文算法进行对比, 其对比实验结果如表2所示. 且作出GDBN算法用于三个中文文本数据集(D1、D2、D3)的迭代曲线图如图5所示, 其结果表明, GDBN算法较于DBN和SVM算法更能有效的对文本情感倾向进行分类.
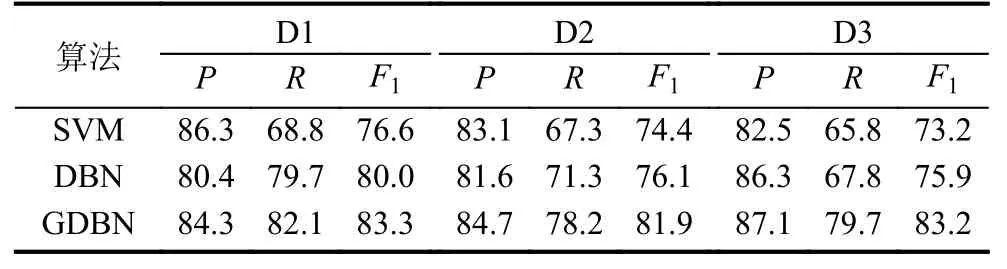
表2 实验结果对比(单位: %)

图5 GDBN迭代曲线图
本文对三种分类算法做ROC曲线进行模型评估,如图6所示. ROC曲线下面积越大代表模型性能越好,由图6可知基于GDBN算法的文本情感分类模型具有更高的分类性能.
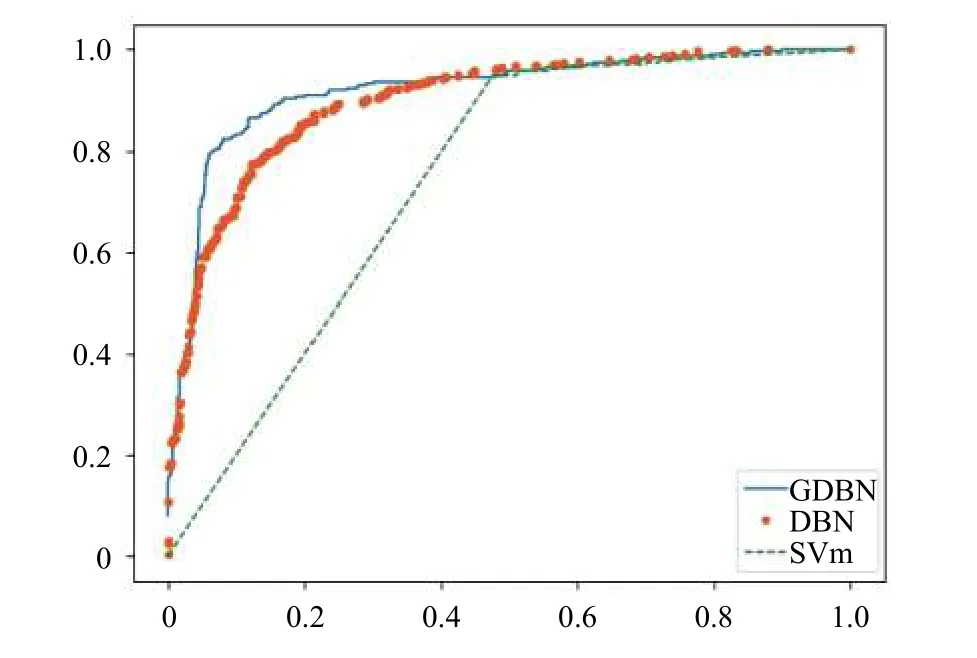
图6 ROC曲线图
5 结语
为了更好的解决中文文本情感分类问题, 本文基于深度学习算法构建了一个GDBN网络模型, 针对DBN网络人工进行隐层单元个数选择从而导致模型性能存在极大不确定性的问题, 引入具有强大全局寻优搜索能力的遗传算法, 根据实验输入数据自行对隐单元个数寻优, 取得当前模型的适宜值. 经实验验证可得, 本文所提方法在分类准确性和降低模型复杂性上均有提升, 能取得良好的效果, 但仍存在不足. 在今后的工作中, 将继续改进本文算法, 比如在对提取到的特征进行分类时候, 针对BP网络存在的网络“震荡”等问题, 采用XGBoost算法来进行分类, 进一步提高模型情感分类的精度.
