基于Q-Learning算法的建筑能耗预测①
2019-01-18陈建平陈其强吴宏杰傅启明
陈建平, 陈其强, 胡 文, 陆 悠, 吴宏杰, 傅启明
(苏州科技大学 电子与信息工程学院, 苏州 215009)
(江苏省建筑智慧节能重点实验室, 苏州 215009)
(苏州市移动网络技术与应用重点实验室, 苏州 215009)
1 引言
建筑作为能耗占比最大的领域, 虽然自身拥有巨大的节能潜力, 但是, 随着经济的高度发展, 建筑面临的高能耗低能效的问题也日益严峻. 近年来, 我国在建筑节能领域取得了明显进展, 但从能耗预测的角度看,建筑能耗预测仍然存在很多不足之处[1]. 构建建筑能耗预测模型是预测建筑未来时刻能耗、在线控制能耗以及获取能耗运行最优策略的前提和核心[2-4]. 但是, 建筑具有面积大、能耗大和能耗复杂等特点, 并且建筑自身是一个包含多种系统, 设备相互连接的复杂非线性系统. 因此, 研发精度高、适应性强的能耗预测模型并非是件容易的事. 从建筑自身来说, 其能耗受到多种外界因素的影响, 例如外界气候、建筑物自身结构、内部设备运行特点、人员分布动态特征等, 这些因素使得建筑物能耗变得更加复杂, 也加剧了能耗预测的难度. 近年来, 国内外许多业界学者和专家的主要关注点在于如何在提高建筑能耗预测的准确性并简化能耗预测模型的同时, 实现在线控制及优化建筑能耗. 建筑的完整生命周期包括很多环节, 如设计、建造、运行、维护等, 其中每个环节运用的节能方法或者技术都能够对实现节能的目标产生重要影响, 因此, 能耗预测在建筑节能中就显得势在必行. 与此同时, 建筑在自身运行中产生的一大批真实能耗数据被搁置或者直接丢弃, 并没有真正实现任何价值, 对节能而言, 又是一种资源浪费.
强化学习在智能建筑领域, 尤其是在建筑节能问题上已经引起国内外相关学者的广泛关注. Dalamagkidis等人提出设计一种线性强化学习控制器, 可监督控制建筑热舒适度、空气质量、光照需求度、噪音等, 与传统Fuzzy-PD相比, 其效果更优[5]; Yu等人提出了一种用强化学习在线调整低能耗建筑系统的监督模糊控制器的无模型方法, 其中用Q-learning算法监控建筑物的能源系统[6]; Bielskis等人利用强化学习方法构建室内照明控制器, 通过强化学习方法自适应调节照明系统, 进而节约能源消耗[7]; Li等人提出一种多网格Q-learning方法, 通过近似建筑环境模型求解近似节能优化策略, 并将初始策略用于精确建筑模型, 在线学习最优控制策略, 加快算法求解实际问题中的收敛速度[8];Liu等人提出基于强化学习Q-learning算法监督控制建筑热质量, 进而节约能源消耗[9]; Yang等人提出基于强化学习方法的建筑能耗控制方法, 该控制方法运用表格式Q学习和批量式Q学习在Matlab平台上实现建筑能耗控制, 实验结果表明, 该方法较其他方法多节约百分之十的能耗[10]; Zamora-Martínez 等人给出一种利用位置环境在线预测建筑物能耗的方法, 该方法从一个完全随机的模型或者一个无偏的先验知识获得模型参数, 并运用自动化技术使得房屋适应未来的温度条件, 达到节能的效果[11]; Nijhuis等人提出一种基于公开可用的数据开发住宅负载模型, 该模型运用强化学习中蒙特卡罗算法, 基于时间使用规律对家庭居住房屋进行建模, 该模型中主要影响能耗的相关因素为天气变量、领域特征和人员行为数据, 通过对100多个家庭每周的用电量进行验证, 实验结果表明, 该方法的预测性能较其他类似方法更精确[12]; Liesje Van Gelder等人基于强化学习中蒙特卡罗方法提出一种整合影响建筑能耗诸多不确定因素的概率分析和设计方法, 该方法可以合并原模型, 取代原始模型, 并检查潜在情景的优化结果[13].
本文利用DBN将建筑能耗初始状态映射至高维特征空间, 结合强化学习中Q-learning算法, 将输出的状态特征向量作为Q-learning算法的输入, 实现对建筑能耗的预测. 实验表明, 运用强化学习进行能耗预测是可行的, 并且改进后的能耗预测方法精度更高, 这充分说明了强化学习在建筑能耗预测领域具有很大的研究潜力.
2 相关理论
2.1 马尔可夫决策过程
能成功保留所有相关信息的状态信号就是具有马尔科夫性(Markov Property)的, 而只要具有马尔可夫性的强化学习问题就被称为马尔可夫决策过程(Markov Decision Process, MDP). 马尔可夫性可作如下定义: 假设强化学习问题中, 状态和奖赏值的数量都是有穷的,在问题中, 学习器(Agent)与环境交互, 在t时刻执行动作后, 会在时刻获得一个反馈, 在最普通的情况中,这个反馈可能是基于前面发生的一切, 因此, 这种环境动态性可以通过概率分布来定义, 如公式(1)所示:
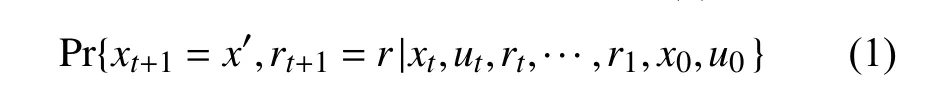
然而, 如果状态信号也是有马尔可夫性的, 那么Agent在t+1时获得的环境反馈就只取决于Agent在t时刻的状态和动作. 在此情况下, 这种环境动态性可以通过公式(2)来定义:
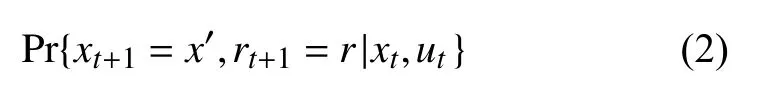
MDP可以用来对强化学习问题进行建模, 其通常被定义为一个四元组其中表示状态集合;表示动作集;表示奖赏函数是指Agent在状态时采取动作所获得的回报值;是状态转移函数,是指Agent在状态下 采取动作后转移到状态的概率.
强化学习的最终目标是要学习到一个能够获得最大期望累计奖赏的最优策略, 并利用该策略进行决策.然而, 由于最终计算获得的最优策略可能是一个动作,也可能是某个动作被选择的概率, 因此, 策略被分为确定策略(deterministic policy)和随机策略(random policy)两种. 其中, 确定策略表示 Agent在某一状态下执行某一动作, 例如表示Agent在状态下执行动作; 随机策略表示Agent在某一状态下执行某一动作的概率, 例如表示Agent在状态下执行动作的概率. 在本文中, 策略直接用表示, 策略是每个状态和动作在状态下执行动作的概率的映射. 假设当前时刻为, 当前状态为, 策略为, 而Agent依据当前状态和策略执行动作后, 在时刻, Agent通过环境反馈, 获得的立即奖赏为Agent在强化学习问题中, 不断地重复上述过程, 并且与环境不断交互,学习到最优策略, 并达到获取最大期望累计奖赏的目的.
对Agent在给定一个状态或者状态动作对时, 为了评估该状态或者状态动作对的好坏程度, 在强化学习中给出值函数的定义. 几乎所有强化学习算法都是通过值函数对策略进行评估, 而值函数有状态值函数Vk(x)和动作值函数Qk(x,u)两种. 其中,Vk(x)表示Agent在当前状态下遵循策略的期望回报; 而Qk(x,u)表示Agent在当前状态动作对(x,u)下遵循策略h所 能获得的期望回报.Vk(x)和Qk(x,u)是相应Bellman公式的不动点解, 如公式(3)和公式(4)所示:
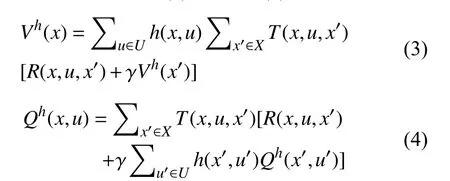
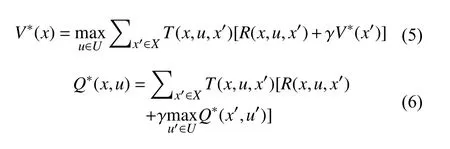
上述两个公式也被称作最优Bellman公式.
2.2 Q-learning算法
Q-learning是一种经典的离策略算法, 其更新准则:, 即Q-learning是利用基于行为策略所选择的实际动作来更新目标策略Q值的. Q-learning算法具体流程如算法1所示[14].

算法1. Q-learning算法3. 初始化4. Repeat(for each step of episode)1. 随机初始化2. Repeat(for each episode) 5. 利用从 中得到的策略在中选择 6. 采取动作 , 得到 7.8.9. 直到是终止状态10. 直到 最优
3 基于Q-learning算法的建筑能耗预测方法
3.1 建筑能耗状态表示
DBN可以应用在多种领域的问题中, 例如执行非线性维数减少、图像识别、视频序列和动作捕捉数据等问题. 此外, DBN可以根据不同的抽象层将学习任务分解成相应的子问题.
DBN由很多限制玻尔兹曼机堆叠在一起, DBN是一个时滞神经网络, 主要分为可视层和隐层, 每一层之间存在相关链接, 但每一层内的单元之间不存在相互链接. 隐层每个单元的作用主要在于获取可视层单元的输入数据所具有的高阶数据的特征, 因此, 由可视层和隐层链接配置的能量被定义为:

其中,i表示可视层节点,表示隐层节点,表示第i个可视单元与第个隐层单元之间的权重. 此外和表示第i个可视单元与第个隐层单元的状态,和表示可视层与隐层的偏置向量.表示隐层和可视单元之间的输出与它们的相关权重的乘积和分别表示可视层和隐层的输出. RBM定义了一个联合的概率p(v,h), 覆盖了隐层和可视层.

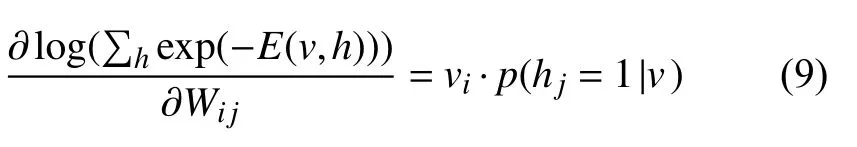
在RBM中隐藏层和可视层被激活的概率可以用下面的公式来表示:
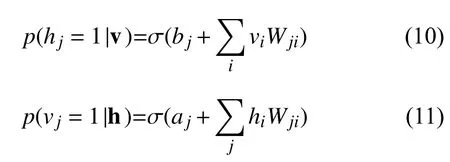
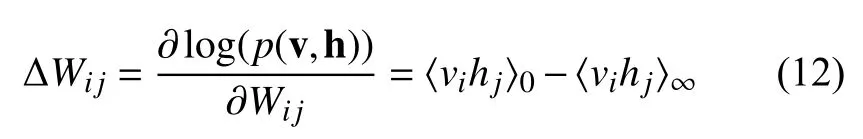
总的来说, 一个深度信念网络是由一个任意的数字给出的. 其中, 可视层(输入向量)和l层隐层的之间的联合分布的定义如公式(13)所示:

如图1所示, 一个DBN包含1个可视层和3个隐层, 其中,层是可视层;是隐层. 可视层的每个单元代表真实值, 隐层的每个单元代表2进制的神经元. DBN可以通过贪心无监督的方法进行训练, 通过从下到上的顺序分别训练其中的每一个RBM, 使用隐层的输出作为下一个RBM的输入, 直到最后一个RBM被训练结束. 此外, DBN通过在模型的底层修改初始状态以此推断出最顶层的隐藏层, 从而将从环境中获取的初始状态映射到二值状态空间.

图1 DBN框架图
3.2 环境建模

3.3 基于Q-learning算法的建筑能耗预测算法
DBN将从环境中获取的初始状态映射到一个二值状态空间, 并且将获得的状态作为Q-learning算法的输入, 基于Q-learning算法的建筑能耗预测算法具体流程如算法2所示.

算法2. 基于Q-learning算法的建筑能耗预测算法X 4. For each 1. 初始化 DBN, 输入状态集2. For each RBM in DBN 3. Repeat x∈X 5. 令RBM可见层6. 执行RBM, 训练出RBM的参数7. 更新RBM的权重及各个节点的偏置, 固定RBM的参数RBMvisible=x

8. End for 9. Until converge x∈X 10. For each 11. 令RBM可见层RBMhidden RBMvisible=x 12. 推断出RBMhidden 13. 将 作为下一个RBM的可见层14. End for 15. End for X 16. 将最后计算出的 作为Q-learning算法的状态集Q(s,a)17. 随机初始化 ;18. Repeat(for each episode)s s∈X 19. 初始化20. Repeat(for each step of episode)Q 21. 利用从 中得到的策略在 中选择α s α 22. 采取动作 , 得到 ,Q(s,a)←Q(s,a)+α[r+γmaxQ(s′,a′)-Q(s,a)]r s′23.24.25. 直到是终止状态26. 直到最优s←s′
4 实验及结果分析
4.1 实验设置
为了验证本文所提出的建筑能耗预测方法的有效性, 本章节采用的实验数据是美国巴尔的摩燃气和电力公司记载的建筑能耗数据, 具体时间为2007年1月至2017年12月. 本节以其中General Service(< 60 kW)部分数据为实验数据集, 如图2所示, 子图1表示2017年9月共30天的能耗数据, 子图2展示的是2017年9月23日至9月29日共一周7天的能耗数据, 图2中数据采集的步长为1次/1 h. 在所有实验中,数据集分为两部分, 一部分用于模型的训练, 一部分用来评估该能耗预测方法的性能, 学习速率 α =0.4, 折扣因子 γ =0.99.

图2 能耗实际值
4.2 实验结果分析
图3 和图4主要展示了Q-learning、基于DBN的Q-learning算法对一个星期的建筑能耗预测值与实际值的对比图, 横坐标表示时间, 纵坐标表示建筑能耗.在实验过程中, 每个算法都被独立执行20次, 图中的数据即20次实验的平均值. 从两幅图中可以看出, 两种算法都可以预测出未来一周的建筑能耗值. 因此, 用DBN构建能耗动态模型, 并采用Q-learning算法进行建筑能耗预测的方法是可行的. 此外, 从图中可以清晰地看出, 改进的基于DBN的Q-learning算法的能耗预测准确性较经典Q-learning算法更高, 主要原因是通过DBN构造高维特征向量, 进一步提高函数逼近器的泛化能力, 提高算法预测的准确性.

图3 Q-learning算法能耗预测值与实际值对比

图4 基于DBN的Q-learning算法能耗预测值与实际值对比
表1主要表示了DBN隐藏层神经元个数不同时,不同算法对能耗预测的性能分析. 表格中的数据表示建筑能耗实际值与预测值的均方根误差, 表格中的数据是算法被独立执行20次的平均值. 从表1还可以看出相同算法在不同隐藏层神经元的个数下, 算法的性能也不一致, 当隐藏层神经元个数为 5, 10, 20, 50,100时, 建筑能耗的预测值与实际值的均方根误差分别为 0.325, 0.225, 0.122, 0.127, 0.138. 由此可以看出, 神经元个数越少, 预测的准确性越差, 而神经元个数越多时, 预测的准确性越好, 但是当神经元数量足够多时,预测的准确性几乎保持一致, 甚至准确性变差. 由此可见, 为了提高建筑能耗预测的准确性, 选择合适的隐藏层神经元个数是有必要的, 由表 1 可知, 本文中, 隐藏层神经元个数取20.

表1 神经元个数对基于DBN的Q-learning算法预测性能的影响
表2主要表示了不同α值以及在不同数据步长对基于DBN的Q-learning算法预测性能的影响分析. 表格的第一行表示α的不同取值, 表格的第一列表示数据的步长, 即每个数据之间的时间间隔分别为1 h, 1 day, 1 week和1 month. 表格中的数据表示建筑能耗实际值与预测值的均方根误差, 都是算法被独立执行20次的平均值. 由表2可以清晰地知道, 当数据步长为1 h时, 尽管α的取值在不断变化, 建筑能耗的预测值与实际值的均方根误差总是比较稳定, 预测的准确性较高; 当数据步长为 1 week 时,α取值越大, 建筑能耗的预测值和实际值的均方根误差越小, 预测的准确性相对较低; 而当数据步长为1 week和1 month时,α取值越大, 建筑能耗的预测值和实际值的均方根误差越大, 预测的准确性更低. 同样的, 当α(α≥0.4)取值一致时, 数据的步长越小, 建筑能耗的预测值和实际值的均方根误差越小, 预测的准确性越高; 数据的步长越大,建筑能耗的预测值和实际值的均方根误差越大, 预测的准确性越低. 综上所述, 为了最大化能耗预测的准确性, 这里我们选取数据步长为1 h,α取值我们选取0.4.
表2 不同 值及不同数据步长对基于DBN的Q-learning算法预测性能的影响

表2 不同 值及不同数据步长对基于DBN的Q-learning算法预测性能的影响
数据步长 α值0.2 0.3 0.4 0.5 0.6 0.7 1 h 0.136 0.132 0.122 0.119 0.129 0.135 1 day 1.233 1.156 0.985 0.912 0.685 0.843 1 week 1.312 1.114 1.109 1.112 1.698 1.723 1 month 1.205 2.209 2.352 2.417 2.423 2.436
5 结束语
本文提出一种基于Q-learning算法的建筑能耗预测模型. 该模型通过深度置信网自动提取特征, 并利用贪心无监督的方法自下而上地训练深度置信网中的每一个RBM. 所提出的模型将隐层的输出作为下一个RBM的输入, 实现对能耗状态的预处理, 并以此构建高维状态向量. 此外, 该模型将能耗预测问题建模为一个标准的马尔可夫决策过程, 将深度置信网的输出状态向量作为Q-learning算法的输入, 利用Q-learning实现对能耗的实时预测. 为了验证模型的有效性, 本文采用美国巴尔的摩燃气和电力公司记载的建筑能耗数据进行测试实验, 实验结果表明, 所提出的模型可以有效地预测建筑能耗, 并且基于DBN的Q-learning算法较传统的Q-learning算法有较高的预测精度. 此外, 本文还进一步分析了相关参数对算法性能的影响.
本文主要对单一固定建筑能耗进行预测, 下一步,将考虑对多样变化的建筑能耗进行预测和迁移研究,同时不断完善模型, 更好地实现建筑能耗预测, 进一步达到建筑节能的目的.
