面向车辆检测的扩张全卷积神经网络①
2019-01-18程雅慧
程雅慧, 蔡 烜, 冯 瑞
1(复旦大学 计算机科学技术学院, 上海 201203)
2(上海视频技术与系统工程研究中心, 上海 201203)
3(复旦大学 上海市智能信息处理实验室, 上海 201203)
4(物联网技术研发中心, 上海 201204)
车辆检测[1]在计算机视觉领域是一个很重要的研究课题, 如智能交通, 自动驾驶等. 近年来, 业内已提出了很多基于深度学习的车辆检测算法, 实际应用表明,基于深度学习的方法比传统手工提取特征方法更加有效.
基于区域的卷积神经网络(Region-based Convolutional Neural Network, RCNN)是一种典型的基于深度学习的目标检测算法, 在车辆检测领域被广泛使用. 基于RCNN框架, 通过卷积神经网络提取给定的候选目标区域特征, 用于预测目标类别和目标位置. Faster-RCNN算法通过在RCNN最后一层卷积层提取出的特征同时用于候选目标框的生成和最终的目标检测.
研究发现, 随着网络层数的不断增加, 卷积神经网络(Convolution Neural Network, CNN)能很好地学习低层特征和高层语义特征. 高层卷积层在分类任务方面比定位任务具有更好的性能, 有学者[2,3]试图结合多种低/高层卷积层用于目标检测, 尽管这些方法不同程度上改善了目标检测性能, 但是在有不同尺度的车辆检测方面, 多个不同尺寸的车辆检测精度无法达到平衡. 特别地, 相对于大尺寸目标, 这些方法在小尺寸目标检测方面表现不尽人意.
本文提出了一种适用于小尺寸车辆的检测算法,即基于组合目标框提取结构的扩张全卷积神经网络(Dilated Fully Convolutional Network With Grouped Proposals, DFCN-GP). 图 1为 DFCN-GP的算法框架,算法包括用于图像特征提取的扩展卷积网络(Dilated Convolutional Network, DCN)、组合目标框提取网络(Grouped Region Proposal Network, GRPN), 以及用于车辆检测的全卷积网络(Fully Convolutional Network,FCN)三部分.
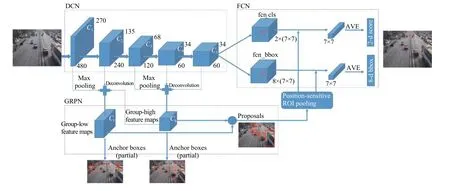
图1 DFCN-GP算法框架图
本文方法的主要贡献为: 1)提出了两组组合方式,即混合从低层到高层卷积层的特征图, 并将两组混合特征应用到区域目标框提取网络, 同时生成候选车辆区域. 与现有方法不同, 这种组合结构更多地聚焦低层卷积层的特征. 2)将低层和高层特征产生的目标候选框进行融合, 有利于收集不同尺度的候选目标框, 降低目标丢失率. 3)将最后一层卷积层改成扩张卷积层并把步长改为1, 使最后一层卷积层的特征图拥有更大的尺寸和感受野, 可同时用于目标框提取网络和车辆检测网络, 进而在候选目标框的生成和最终目标检测中更多的细节信息. 上述改进可使模型能有效检测图像中较小的车辆目标.
在实验部分, 将本文提出的网络模型与现有最新的网络模型在UA-DETRAC车辆数据集上进行对比.实验结果显示, 本文方法取得了71.56% mAP, 超越了现有最好方法的结果. 此外本文提出的网络模型同样通过控制变量对比试验, 证明了组合特征提取方式和扩张卷积设置的有效性.
本文论文剩余部分安排如下: 第1节讨论了提出的算法模型, 第2节对本文算法进行了实验并对结果进行了分析, 第3节为总结全文.
1 算法原理
本文提出一种用于车辆检测的端到端学习网络(DFCN-GP), 可从不同的卷积层级中实现候选目标框的提取和车辆检测. 如图1所示, 网络的前向路径包括以下几个步骤:
Step1. 图像特征提取. 利用Resnet-101和扩张卷积层提取输入图像的特征, 用于后续目标框的提取和车辆检测.
Step2. 区域候选目标框提取. 提出一种两组组合方式, 即从不同卷积层生成候选目标框.
Step3. 车辆分类和定位. 利用多任务学习方式, 在最后一层扩张卷积层同时判别候选框是否为车辆以及估计车辆的位置.
1.1 图像特征提取
通过DCN从输入图像中提取车辆信息特征. 具体地, 本文的特征提取网络基于改进的ResNet-101[4]结构. 与传统卷积神经网络训练不同, ResNet利用残差结构实现更为有效的模型训练, 在图像分类和目标检测任务中性能优异.
如图1所示, 本文的特征提取网络包括5个残差结构, 分别标注为根据原生ResNet-101的设置, 每个残差块会连接步长为2的卷积层. 因此, 原生ResNet-101网络中每个残差块的特征图步长分别是 {2 ,4,8,16,32}, 即给定X×Y大小的输入图像, 则最后的卷积层的特征图, 输出大小为X/32×Y/32. 当用于目标框提取和车辆检测时,C5的尺寸相对于原始图像的细节信息过小, 而且容易丢失小目标.
为了解决上述问题, 考虑从一下两个方面对网络进行改进: 1)改变后的卷积层步长, 将步长2改为步长1, 进而增加最后一层卷积层的特征图大小. 通过这样方式,直接接在后面, 不加任何下采样处理. 2)基于文献[5]的思路, 应用扩张卷积的思想, 增加的感受野, 最终网络的5个残差块的步长变为
1.2 区域候选目标框提取
在此步骤中, 算法从提取的特征图中产生候选的目标框, 这个过程由区域目标框提取(Region Proposal Network, RPN)这样的子网络完成. 正如文献[6]中讨论的那样, 较高层的特征图包含更多的高级语义信息, 而较低层的特征图包含更多的细节信息. 为了更好地发现图像中不同尺度的车辆目标, 本文旨在探索不同级别的特征图所包含的信息以及更多地聚焦在小目标检测上. 为了这个目的, 本文发明一个基于组合的区域目标框提取网络, 用来结合两组卷积特征图. 这两个组分别被命名为group-high和group-low. 在每个组中,RPN网络在两个不同尺度级别上同时生成固定框(anchors).
上述用于目标框提取的网络模型对现有方法进行了优化和提升: 原生RPN网络仅从最后一层卷积层上计算目标框, 同时也使用了多尺度的anchors. 有研究[2,3,7]提出结合形成特征图, 即超-特征(Hyper Feature), 然而, 尽管 Hyper Feature 结合了低层和高层的信息, 但对车辆检测, 尤其是对小目标车辆的检测性能不佳, 本文提出的“两组”策略在车辆检测任务中会带来更高的召回率.
1.3 车辆分类和定位
在前述步骤的基础上, 可通过FCN判别提取框是否为车辆, 并估计估计车辆的准确位置坐标. 为此, 模型首先通过PS-ROI pooling[8]操作在上裁剪出感兴趣区域, 然后再接上两个分支的全卷积网络. 第一个分支实现分类, 即对裁剪出的区域打分. 第二个分支实现位置预测, 即对有目标的区域生成一个8维的向量(前景/背景).
在模型训练阶段, 本文的目标是最小化多任务损失函数, 包括分类和定位两个部分. 具体为给定标签值和预测值 {s,s∗}和候选框的补偿值{t,t∗}, 目标检测损失函数定义如下:
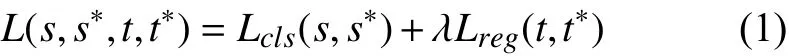
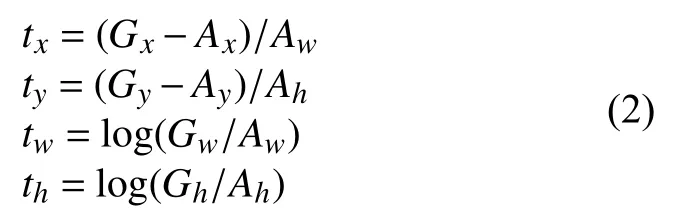
在公式(2)中,A=(Ax,Ay,Aw,Ah)由anchor计算得到, 而G=(Gx,Gy,Gw,Gh)是代表标签的目标框. 根据文献[9]中的设置, 平衡的缺省值为1.
相对于常规Resnet-101模型,本文模型直接预测车辆是通过改良的具有大尺寸和大感受野的特征图. 我们发现在改良过的上预测会比Hyper Feature效果更好.
2 实验部分
2.1 数据集和实验设置
在实验部分, 首先设计控制变量对比实验验证本文网络各组成部分的有效性, 然后将本文模型与其他典型模型进行对比. 算法模型在UA-DETRAC[10]数据集上训练模型, 该数据集由10个视频组成, 视频由Cannon EOS 550D的摄像机在中国北京和天津两座城市共24个不同的位置录制而成. 视频每秒25帧且像素为960×540, 数据集总共超过14万帧. 数据集中共有8250个车辆, 121万个车辆矩形框被标注.
对输入数据, 首先将训练图片归一化, 将图片短边归一化为540. 提取图像特征的共享卷积层初始参数设置为在Imagenet上训练的Resnet-101参数, 其余层的初始参数采用0均值, 0.01方差的高斯随机数.
在区域目标框提取网络训练阶段, 本文将与任何标签框面积重叠比率(Intersection-Over-Union, IOU)大于0.7的候选提取框设置为含有目标的候选框. 将与任何标签框的IOU小于0.3的候选提取框设置为不含目标的框.
在目标检测网络训练部分, 本文将与任何标签框的IOU大于0.6的候选提取框设置为含目标的候选框.将与任何标签框的IOU小于0.6的候选提取框设置为不含目标的框. 在测试阶段, 目标检测网络部分应用NMS来合并有重叠的候选框.
在训练过程中, 将批大小设置为128, 总迭代次数设置为9万轮. 学习率初始值为1e-3, 每3万轮迭代乘以系数0.1. 在算法效率方面, 本文的模型在测试阶段处理一张图像(9 60×540)需0.4 s.
2.2 控制变量对比试验
对于区域提取目标框网络和检测网络来说, 输入设置对最终检测效果至关重要. 下面针对不同特征图的结合方式设置了几组控制变量对比试验, 并讨论其效果.
2.2.1 区域提取目标框网络输入设置
本文尝试了不同卷积层的结合对目标框提取的影响. 表1为使用不同卷积层作为RPN的输入对应的提取框召回率, 以及其最终的检测率. 目标包括小/中/大车辆尺寸. 最后一列为最终的检测精度(Average Precision,AP). 行(a)是将结合在一起作为RPN的输入.通过设置6种提取框的尺度, 分别为从结果可以看出, 小目标的召回率明显小于中等目标和大目标的召回率. 行(b)是将C3,C4,C5结合在一起作为RPN的输入, 同样也是设置6种提取框的尺度. 从结果可以发现大目标的召回率明显提升,但小目标及中等目标的召回率大幅度下降. 和行(b)相比, 行(c)简单地结合低层特征C1,C2来预测小目标和中等目标框. 本文对于高层的融合特征图设置5种目标框尺度为 {3 22,642,1282,2562,5122}, 对于低层融合特征设置2种目标框尺度为 {1 62,322}. 从结果可以看出,中等和小目标的召回率有了轻微的提升, 但是没有融合高层语义特征使得小目标并不能正确的分类出来.最终在行(d)中, 本文提供了自己提出网络的结果. 同样对高层融合特征设置5种目标框尺度, 对低层融合特征设置2种目标框尺度. 最终发现本文的融合策略可以大幅度改善小目标和中等目标的召回率, 并且维持大目标的召回率基本不变. 本文提出的融合方法在目标框提取中对于寻找各种尺寸的目标框达到一个很好的平衡. 另外, 最终本文方法的检测精度(行(d))也同样高于其它模型.

表1 不同卷积层特征图的结合方法作为RPN网络的输入在UA-DETRAC验证数据集上目标的召回率
2.2.2 全卷积检测网络的输入设置
这部分实验了不同卷积层的特征会怎样影响最终的检测结果. 平均检测精度(AP)结果如表2所示. 行(a-d)直接在单个卷积层C1,C3或上检测目标. 从表中可以发现, 利用高层特征(行(c, d))作为输入比利用低层特征特征作为输入要取得更好的检测效果. 这样说明相比于低层特征, 高层特征在检测任务中更加有效. 注意到行(d)是本文提出网络的设计, 和行(c)不同点仅在于的特征图尺寸和感受野要大. 行(d)比行(c)结果更好证明了将步长改为1以及扩张卷积思想的引入是非常有效的. 行(e)也例举了C1-C3-C5(Hyper Feature)融合特征作为检测网络输入的结果. 结果显示改良的(×16)能更好地检测目标, 同时也说明在检测网络中引入低层特征可能会带来更多噪声, 并不适合检测任务.

表2 经过ROI池化操作后不同的卷积特征图作为最终全卷积检测网络的输入在UA-DETRAC验证数据集上平均精度
2.3 和现有模型比较
将本文的模型与其他现有目标检测模型对比(UA-DETRAC测试集). 用来对比的检测模型包括DPM[11], ACF[12], R-CNN[13], Faster-RCNN[14],CompACT[15]和EB. ACF和DPM是经典的目标检测方法. ACF基于一种加速框架而DPM基于SVM(支持向量机). R-CNN和Faster-RCNN都是基于区域提取的目标检测卷积神经网络. CompACT通过一种级联的方式检测目标. EB是基于Faster-RCNN的改良算法, 增加一个额外的精调网络.
表3列出了不同方法在不同子测试集上的检测精度. 之前最好的检测网络是EB(获ICME2017最佳论文), 通过对比发现, 本文方法在全集上的AP为71.56%.注意到本文提出的方法在不同子类别上的检测精度也是最高的. 图2展示了不同检测方法的精度-召回率曲线图. 这同样说明相比于其他方法, 本文方法具有明显的优越性. 图3图形化展示了一些方法在UA-DETRAC数据集上的检测结果, 可以看出本文方法对于不同尺度的车辆以及不同的天气条件下都具有出色的检测效果.
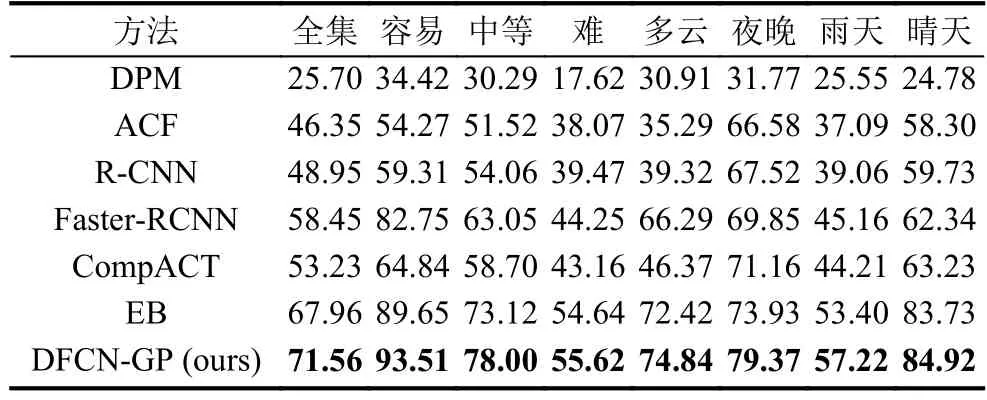
表3 和其他先进的方法在UA-DETRAC测试集上的检测结果
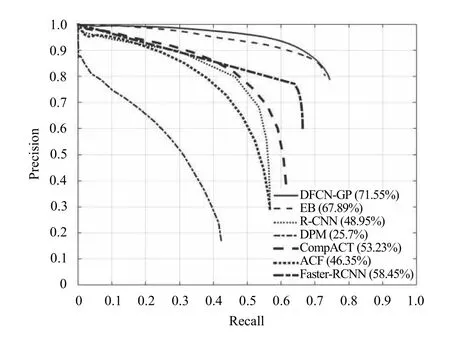
图2 对比检测算法在UA-DETRAC测试集上的精度-召回率曲线

图3 本文提出的车辆检测算法在UA-DETRAC测试集上的结果(红色框标出)
3 总结
本文提出了一种新的车辆检测算法DFCN-GP. 通过在目标框提取和车辆检测中引入了两组卷积层特征图和扩张卷积层, 实现了小目标车辆检测精度的大幅度提升. 控制变量对比试验和与先进模型对比的实验结果验证了本文算法的有效性.
