基于数据挖掘的图书馆读者借阅行为分析
2019-01-10崔金环解海
崔金环 解海
关键词: 数据挖掘; 图书馆读者; 借阅行为; Jaccard相似系数; 对称矩阵; 喜好指数
中图分类号: TN911.1?34; G252.0 文献标识码: A 文章编号: 1004?373X(2019)01?0166?05
Abstract: The traditional hybrid attribute method based on rough set has the problems of low utilization rate of library readers′ borrowing behavior and inaccurate analysis of readers′ book borrowing behavior. Therefore, the data mining based behavior analysis method of library readers is proposed. The clustering algorithm based on similarity coefficient matrix is used to analyze the borrowing behavior of library readers. Jaccard similarity coefficient is used to measure the similarity of high?dimensional borrowing data of library readers to reduce the dimensions of borrowing data of library readers. The new matrix is constructed while building the clustering algorithm. If all the elements in the new matrix are greater than the initial threshold, the data clustering process is completed. The construction of clustering algorithm can realize the effective classification of library readers′ behavior data, and design the recommendation service of personalized exclusive books for readers. The practical application process of the proposed method is analyzed, and the book borrowing information data of library readers is preprocessed to analyze the readers′ borrowing behavior. The experimental results show that the proposed method can improve the utilization rate of library readers′ borrowing behavior data, and has high execution efficiency and CPU utilization rate, and strong ability of book borrowing analysis behavior of readers.
Keywords: data mining; library reader; borrowing behavior; Jaccard similarity coefficient; symmetric matrix; preference index
0 引 言
随着科学技术的迅猛发展,读者对图书借阅信息水平要求也有所提高,这就要求图书馆为读者提供个性化和智能化的图书借阅体验,人们正处在数据爆炸的时代,读者借阅图书信息呈几何式增长[1],数据挖掘技术的广泛应用,可以从海量错综复杂的读者借阅行为信息数据中将有利用价值的数据提取出来,供读者和图书馆使用。因此采取合适的数据挖掘手段解决海量的读者借阅行为信息很有必要。
针对传统基于粗糙集的混合属性方法存在对图书馆读者借阅行为数据的利用效率低、图书馆图书分类效果差的问题,本文提出基于数据挖掘的图书馆读者借阅行为分析方法,提高读者图书借阅行为数据的利用率,增强读者的阅读体验。
1 基于数据挖掘的图书馆读者借阅行为分析方法
数据挖掘技术中常用的数据分析方法为聚类分析,通过聚类分析可实现对特定目标进行不同特征类别的划分。本文基于数据挖掘的图书馆读者借阅行为分析方法,通过构建一种基于相似系数矩阵的聚类算法,对图书馆读者借阅行为实施分析,其基于相似系数矩阵进行数据聚类,将读者按族群划分更清晰[2],且从中挖掘出的图书馆读者借阅行为特点更具有代表性。


对收集的高校图书馆读者借阅图书的原始数据实施数据清洗,即数据预处理过程。本文根据《中图法》对表1中借阅图书的图书编号的部分信息进行提取[7];根据读者就读专业获取专业信息;从原始数据中获取读者借阅图书的月份,并将其转换为周信息;根据读者的入学信息得到读者入学日期及借阅图书时所在年级信息。表2为对高校图书馆读者借阅图书信息的数据预处理结果[8]。将原始数据进行离散化操作,转化为normal的数据形式,便于挖掘隐含的读者借阅行为数据关系,数据转化为删除一些不必要的数据内容,将数据聚类所需的读者学号、图书编号和院系信息等提取出来,获取完备的图书借阅行为数据。
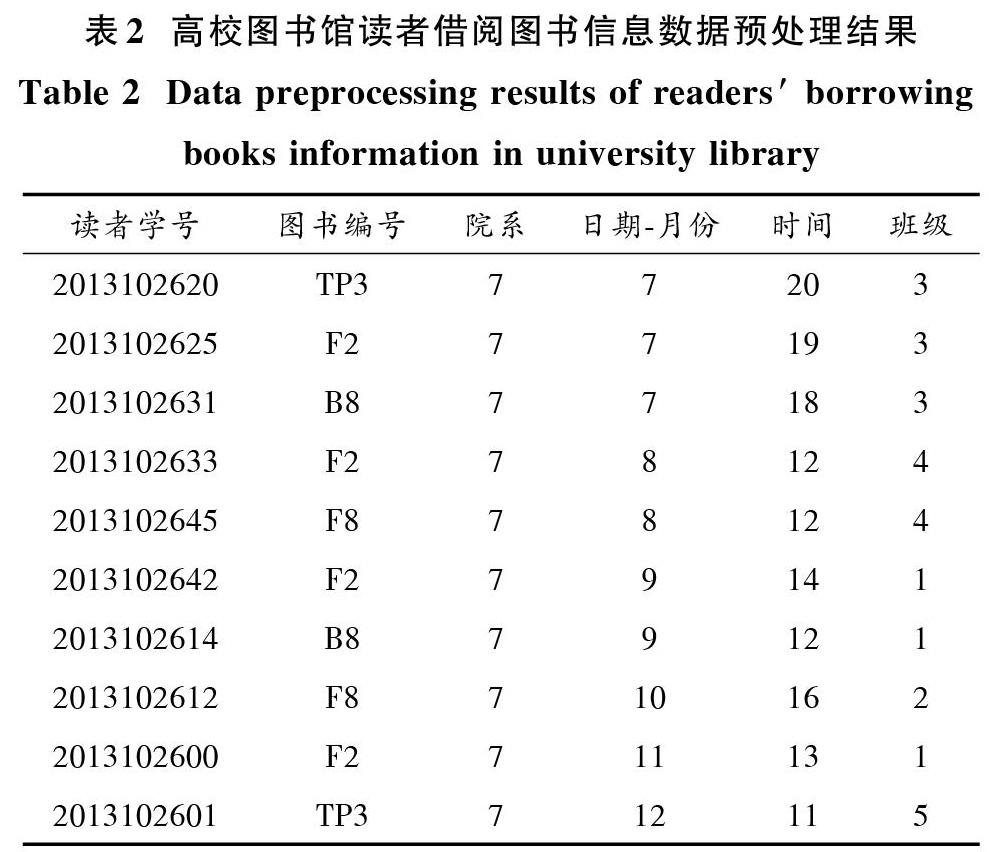
1.2.2 读者借阅行为分析
本文采用上述对图书馆读者借阅图书信息数据预处理结果对读者阅读行为进行分析,对读者图书馆图书借阅行为实施定义,其中读者图书借阅行为包括图书借阅的频率、图书借阅的喜好等。本文方法将借阅频率用[Tb]表示,即在单位时间内读者借阅图书的次数,通常以月或季度为单位;读者阅读喜好用[Tc]表示,即在单位时间内读者借阅某一类图书的次数,由此得出读者借阅图书的喜好指数RI:
[RI=TcTb] (4)
RI的值越大表明读者对该图书的借阅率就越高。本文对图书馆读者借阅图书的喜好有如下规定:若该喜好指数在[0,0.1]之间,认为读者的借阅喜好偏小;若该值在[0.1,0.4]之间,说明读者借阅喜好一般;若该值在[0.4,0.6]之间,说明读者的借阅喜好偏中上等;读者对图书借阅水平最高是RI在[0.6,1]之间。表3为该校图书馆整理和计算后的图书借阅数据库记录。
从表3整理后的数据库中随机选取50条记录用于对读者借阅行为实施分析。依据相关的数据统计方法,对50条数据记录进行数据分析和挖掘,针对专业和读者借阅频率、借阅喜好三者关系进行分析,设置本文方法相似度系数是0.05。表4为本文方法下读者就读专业与图书借阅频率的相关性分析结果,对其实施相似度聚类分析得出,就读专业与图书借阅频率并无较大关联[9],学生经常跨专业借阅图书,非文学专业的学生也会到图书馆借阅文学类的图书。
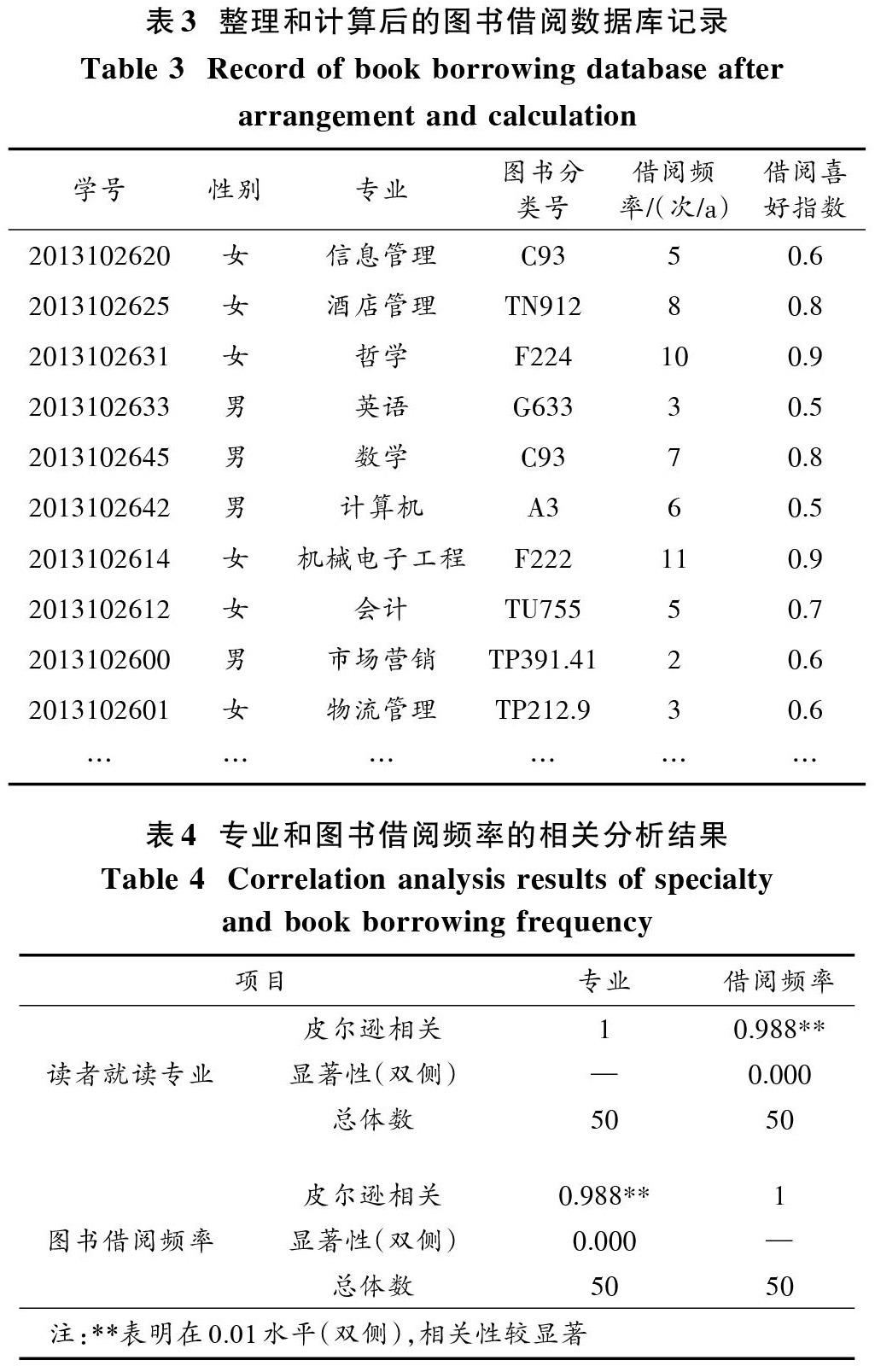
從表5专业和读者图书借阅喜好相关分析结果可知,两者的相关性较显著,显著性(双侧)为0.14与0.05较接近[10],出现这种现象的原因是专业的跨度导致读者对图书借阅喜好的差异较大。
通过对上文本文方法的读者借阅行为分析结果可以看出,读者借阅图书行为与读者就读专业无明显关系,与读者对图书的个人喜好有关。
2 实验分析
实验采用本文方法对某校随机选取的100位读者的图书借阅行为数据进行聚类,划分为12个类别,这些类别都是基于中图分类号进行划分,每位读者都至少借阅一本书为数据划分的主要特征,50人以上借阅过的图书为次要特征。平均值为类中借阅图书的均值,对实验选取的图书借阅行为数据的聚类结果如表6所示。
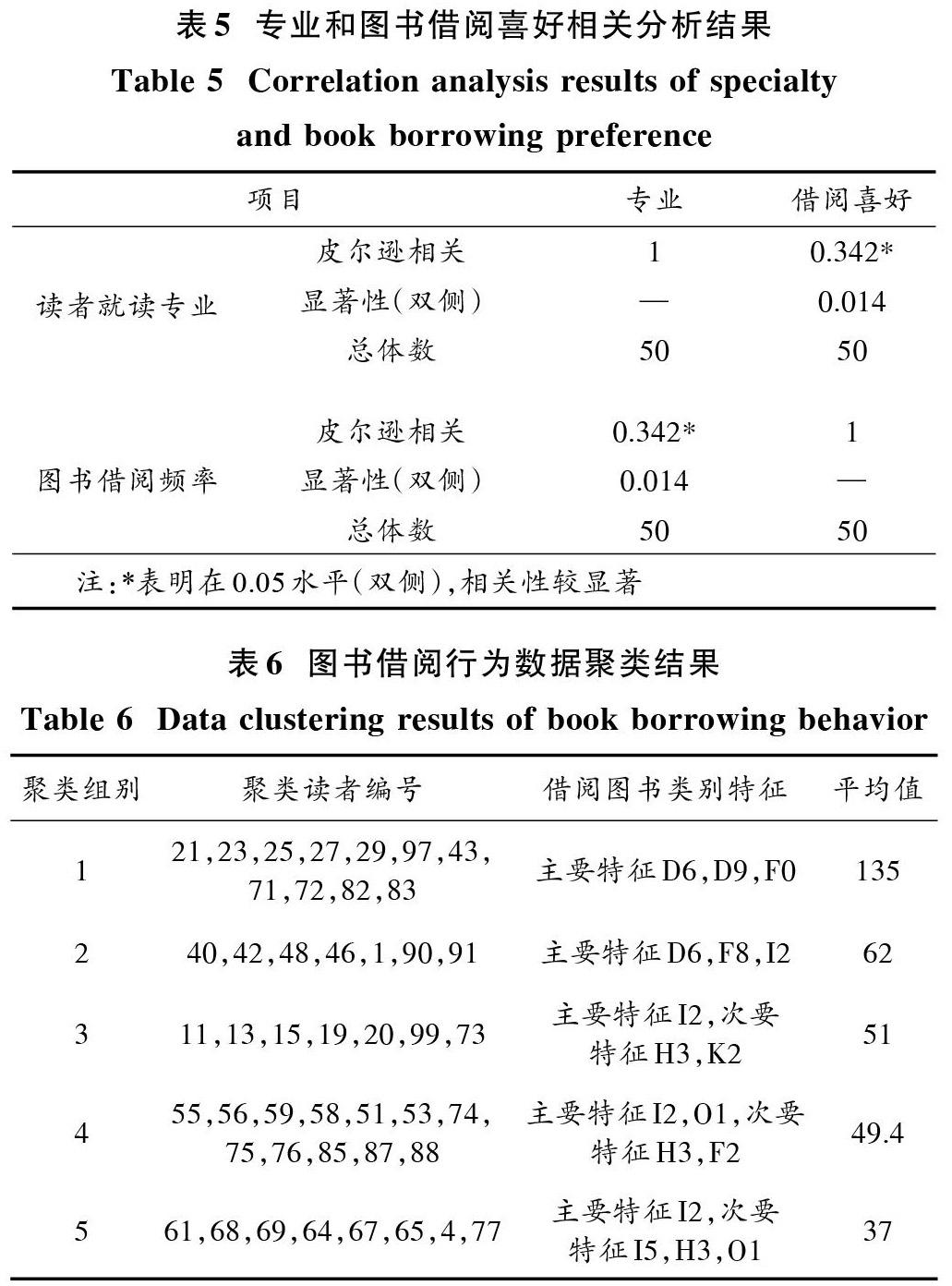
由表6可以看出,读者借阅图书的类别特征和平均值中一些借阅均值较大,说明该图书类别应用面较广。从聚类组1中可以看出,有11个读者借阅的图书借阅均值为135,图书类别囊括了D6(中国政治)、D9(法律)和F0(经济学),从读者借阅图书的类别特征能得出读者阅读行为的特点,在对这些读者推荐图书时应优先推送这些书籍。从聚类组2中,7个读者的平均图书借阅量为62本,图书类别包括D6(中国政治)、F8(金融)和I2(世界文学)。聚类组3中7个读者以及组4中12个读者,借阅图书的均值分别是51和49.4,组3中读者对世界文学(I2)更为感兴趣,对常用外国语(H3)以及中国史(K2)等图书感兴趣度一般;组4中读者对世界文学(I2)以及数学(O1)更为感兴趣,对外国语(H3)以及经济计划与管理(F2)等图书感兴趣度一般。
综合分析这些结果说明,采用本文方法可提高读者借阅行为数据的利用率,对读者借阅行为分析能力强,针对不同读者的借阅行为向其推送可能感兴趣的图书,增强读者的阅读兴趣。
为验证本文方法的性能,在Inter[?] CoreTM 2 Duo CPU,主频为2.1 GHz,内存容量为2 GB,硬盘扩展容量为550 GB的电脑端进行实验。实验依据Visual Studio 2010编程实现,分别采用本文方法和传统基于粗糙集的混合属性算法对上文高校图书馆读者借阅行为的原始数据实施分析。实验设置本文最小的支持度为Min_sup=10%,选取的图书馆读者借阅行为原始数据规模从10~50 KB,实验对不同数据规模下两种方法的执行时间和CPU利用率进行比较,结果分别如图1,图2所示。
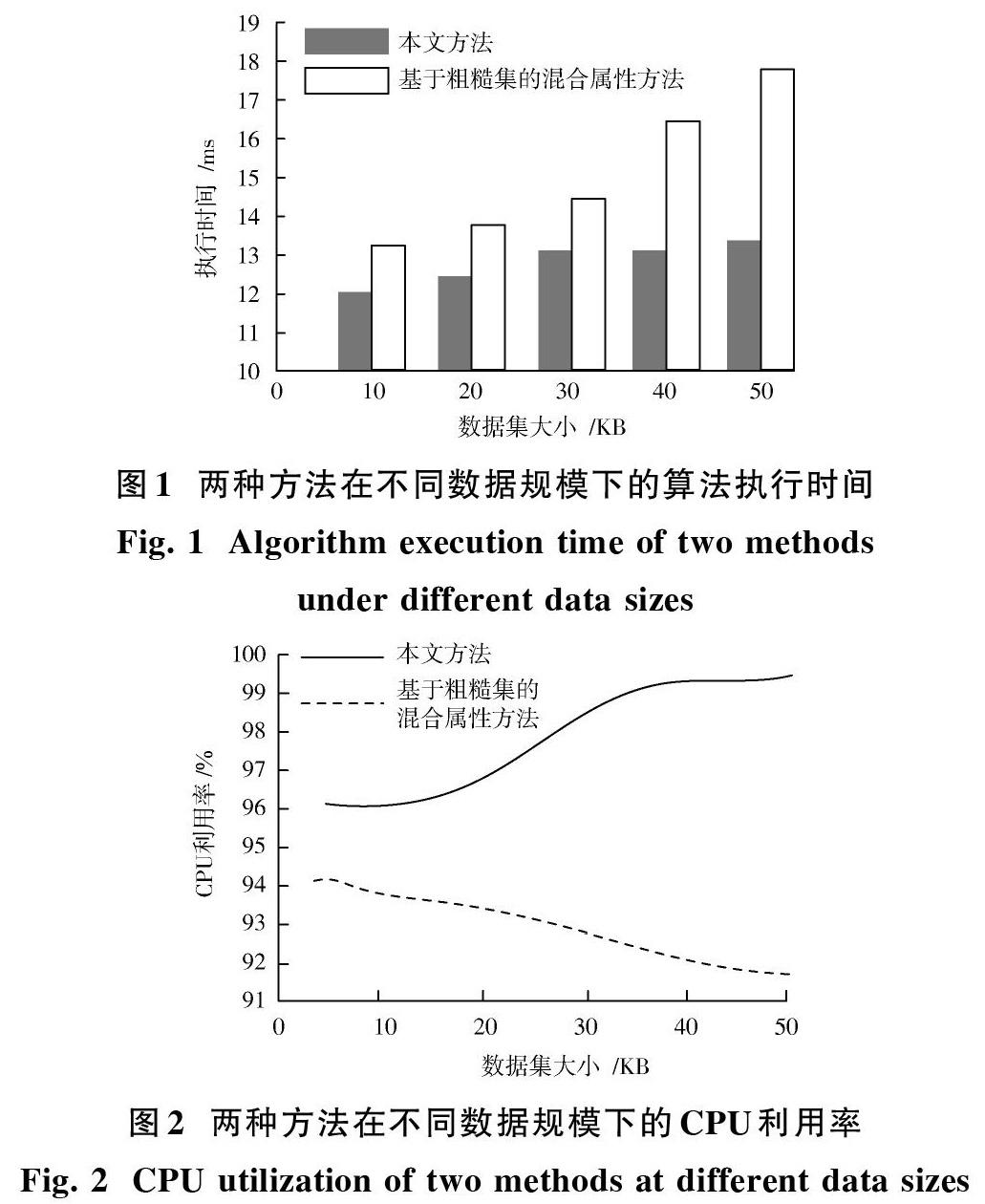
从图1中可以明显看出,两种方法执行时间随着数据量的扩大而增加,但本文方法的用时在12~13 ms之间,当数据增加到一定规模后,方法用时趋于稳定,展示了方法良好的运行能力。而传统的基于粗糙集的混合属性方法从运算初始用时就较长,随着数据规模的扩大,方法执行用时也不断增加,明显高于本文方法。由此可以得出,当图书馆读者借阅行为数据较大时,采用本文方法对数据处理用时较短,执行效率高,满足读者的实时使用需求,提高了图书馆的图书借阅效率。
由图2可以看出,本文方法的CPU利用率随着数据规模的扩大,CPU利用率也越来越高在95%以上,传统方法的CPU利用率随数据规模的扩大而减小,说明方法的执行速度越来越慢,因此本文方法能提高CPU的利用率,缩短数据任务执行时间。
3 结 语
本文提出的基于数据挖掘的图书馆读者借阅行为分析方法,能有效地提高图书馆读者借阅行为数据的利用率,明确读者图书借阅行为,并针对读者的阅读爱好向其推荐感兴趣的图书。
参考文献
[1] 茹文,忻展红.图书馆借阅数据分类信息的关联性研究[J].北京邮电大学学报(社会科学版),2016,18(1):14?19.
RU Wen, XIN Zhanhong. Associations between different classifications of library circulation data [J]. Journal of Beijing University of Posts and Telecommunications (social sciences edition), 2016, 18(1): 14?19.
[2] 朱会华.基于读者借阅数据的馆藏结构合理性分析[J].现代情报,2015,35(2):128?132.
ZHU Huihua. An analysis of rationality library collection structure based on reader borrowing data [J]. Modern information, 2015, 35(2): 128?132.
[3] 孟德泉,董颖,沙娅弘,等.基于OPAC统计数据的借阅率提升策略探讨[J].大学图书馆学报,2014,32(5):73?78.
MENG Dequan, DONG Ying, SHA Yahong, et al. The promotion strategy of lending rate based on the statistical data of OPAC [J]. Journal of academic libraries, 2014, 32(5): 73?78.
[4] 许桂菊.新加坡国家图书馆管理局阅读推广活动可持续发展探析[J].国家图书馆学刊,2015,24(2):95?103.
XU Guiju. Analysis on the sustainable development of library reading promotion activities of the National Library Board Singapore [J]. Journal of the National Library of China, 2015, 24(2): 95?103.
[5] 韩晗.“互联网+”与市民阅读的形成:以2015年中国十大公共图书馆借阅排行榜为例[J].出版科学,2016,24(6):57?59.
HAN Han. ″Internet Plus″ and citizen reading′s formation [J]. Publishing journal, 2016, 24(6): 57?59.
[6] 都蓝,肖丽萍,李宾.基于数据平台的图书馆毕业季服务实践研究:以暨南大学图书馆为例[J].图书情报工作,2015,59(22):79?83.
DU Lan, XIAO Liping, LI Bin. Research on the graduation season service in the academic library based on data platform: a case study of Jinan University Library [J]. Library and information service, 2015, 59(22): 79?83.
[7] 周伟,陈立龙,宋建文.基于增强现实技术的图书馆导航系统研究[J].系统仿真学报,2015,27(4):810?815.
ZHOU Wei, CHEN Lilong, SONG Jianwen. Research on augmented reality of library′s navigation system [J]. Journal of system simulation, 2015, 27(4): 810?815.
[8] 李善青,赵辉,宋立荣.基于大数据挖掘的科技项目查重模型研究[J].图书馆论坛,2014,34(2):78?83.
LI Shanqing, ZHAO Hui, SONG Lirong. Study on detection model of similar scientific project based on big data mining [J]. Library tribune, 2014, 34(2): 78?83.
[9] 郑祥云,陈志刚,黄瑞,等.基于主题模型的个性化图书推荐算法[J].计算机应用,2015,35(9):2569?2573.
ZHENG Xiangyun, CHEN Zhigang, HUANG Rui, et al. Personalized book recommendation algorithm based on topic model [J]. Journal of computer applications, 2015, 35(9): 2569?2573.
[10] 夏翠娟,刘炜,陈涛,等.家谱关联数据服务平台的开发实践[J].中国图书馆学报,2016,42(3):27?38.
XIA Cuijuan, LIU Wei, CHEN Tao, et al. A genealogy data service platform implemented with linked data technology [J]. Journal of library science in China, 2016, 42(3): 27?38.
