自适应嵌入的半监督多视角特征降维方法
2019-01-07孙圣姿
孙圣姿,万 源,曾 成
(武汉理工大学 理学院,武汉 430070)(*通信作者电子邮箱wanyuan@whut.edu.cn)
0 引言
当数据从不同数据源获得或者由不同的特征集来共同表示,这类数据称为多视角数据。比如图像可以由灰度值、尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)特征[1]、方向梯度直方图(Histogram of Oriented Gradients, HOG)特征[2]等多种特征来表示;网页可以由网站地址、网站名称等多种特征表示。多视角数据的各个视角之间通常能够提供互补和相关的信息,而传统方法并不考虑这一点,因此如何有效提取不同视角的特征且保留各个视角之间的相关性来实现特征降维成为机器学习和数据挖掘近年来的研究热点。基于结构信息保持的特征提取方法通过最大程度上保持原始数据的结构,包括全局结构[3-4]和局部流形结构[5-6]来实现特征降维。这些结构可以通过图约束模型来表示,如样本成对相似图[4]、K最近邻(K-Nearest Neighbors,K-NN)图[7]、局部判别模型[8]、局部线性嵌入(Locally Linear Embedding, LLE)[3]等。在近年来的研究进展中,嵌入矩阵被广泛引入到各类特征提取方法中[9-10],这些方法通过重构各数据点与全局信息之间的关系,来保留原始的结构。但是将这些方法应用于多视角特征提取时,它们大多只是单独对单视角的特征进行选择,然后将各视角直接相连,导致了各个视角间特征的相关性和部分原始信息的缺失。
在实际应用中,收集到的数据存在少量标签数据和大量无标签数据是非常常见的。对数据加注标签信息会耗费大量时间精力,因此半监督特征降维方法通过同时使用有标签和无标签两类数据,来保留原始的结构信息。近年来半监督特征降维已取得一些研究成果。半监督判别分析(Semi-supervised Discriminant Analysis, SDA)方法[11],使用带标签的数据点来最大化不同类别之间的可分离性,通过标记数据点来估计数据的固有几何结构。Xu等[12]通过最大化不同类别之间的分类边界来选择特征,利用几何概率分布来生成标记的和未标记的数据,并将其转化成凸凹优化问题。Coelho等[13]提出了一种基于单变量相关性度量的半监督特征选择方法,在Pareto最优集合中决策最优解的过程中,尝试最大化每个特征的相关性指标,确定最小的相关特征集,同时确定最优模型。
然而这些方法直接应用于多视角数据进行特征降维效果并不理想。多视角问题中,针对全局结构的保持项,非监督自适应性特征选择(unsupervised Feature Selection with Adaptive Structure Learning, FSASL)方法[14]提出了一种多视角下自适应性的全局结构保持方法,通过稀疏重构来保留数据的原始结构。将各个视角的数据信息映射到一个最优稀疏组合权重矩阵。同时,一些改进的半监督模式下的多视角学习方法被相继提出。半监督多视角特征选择(Semi-supervised Multi-view Feature Selection, Semi-MFS)方法[15]通过将多个数据点分解成多个有意义且不相关的组别来生成不同的视图,每个组别代表一个视角,每个视角描述一个数据特征。Sun等[16]提出一种通过遗传算法构建多视图的特征选择方法,用于寻找可能的特征子集。多视角黑赛半监督低维特征选择(Multi-view Hessian Semi-supervised sparse Feature Selection for multimedia analysis, MHSFS)方法[17],利用多视图学习来揭示和利用不同视图间的相关和互补信息,从而直接实现多视图稀疏特征选择。Zhu等[18]提出了一个新的多视角半监督学习框架,利用图像中伪标签包含的信息提高图像分类的预测性能。
这些方法仍然存在两个主要问题:1)嵌入思想类似于单视角问题的研究。大多数已有方法在各个单视角下引入的嵌入矩阵都是相同的,并未考虑到不同视角间特征的差异性。2)一些半监督特征降维方法,仅仅局限于局部结构的保持项,并未考虑到全局范围的特征降维,且部分方法由于缺乏对降维后的低维矩阵的稀疏约束,无法避免噪声和其他不相关特征的影响。
针对以上两个问题,本文提出了一种自适应嵌入的半监督多视角特征降维方法(Semi-Supervised Adaptive Multi-View Embedding method for feature dimension reduction, SS-AMVE),将嵌入思想直接引入到多视角问题中,考虑各视角下特征的差异性,将投影从单视角下相同的自适应矩阵扩展到多视角间不同的矩阵。在半监督模式下引入全局结构的保持项,将不含标签信息的数据利用无监督模式方法进行嵌入投影;对于含有标签的数据,结合分类的判别信息进行线性投影。然后,将多投影映射到一个统一的低维空间,使用组合权重矩阵保留全局结构,并引入正则化参数。实验结果表明,所提方法较好地保留了多视角间特征的相关性,捕获了更多的具有判别信息的特征。
1 相关工作
相关学者相继提出各种多视角特征降维方法[19-20]。对于多维特征,通过引入嵌入思想,构建各视角间的相似性矩阵来保留原始的结构信息,已经取得了一定的研究成果。FSASL方法[14]提出了一种多视角下自适应性的全局结构保持方法,通过稀疏重构来保留数据的原始结构。将各个视角的数据信息映射到一个最优稀疏组合权重矩阵,并在重构过程中引入行变换矩阵W,具体表达式如下:
(1)
s. t.Qii=0,WTXXTW=I
式中:X={x1,x2,…,xn}∈Rd×n为原始的数据矩阵;α为约束低维矩阵的正则化参数;Q为全局特征投影到低维空间下的组合权重矩阵。约束WTXXTW=I可以避免受到小样本量数据的影响。l1范数正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,用于特征提取使得特征系数变为0。
在半监督模式下,多视角间局部特征结构的保持显得尤为重要。对于有标签和无标签的数据,一个统一的半监督特征降维框架(a unified framework for Semi-Supervised Dimensionality Reduction, SSDR)方法[21]提出利用两者在投影空间中的正则化项,可以以一种共同的方法来提取视角的局部结构信息,在一定程度上保留原始结构信息和成对约束信息。最终得到以下正则化目标函数:
(2)
式中:Mij为相似性矩阵;L为拉普拉斯矩阵。
进一步,半监督模式下,对于正则化线性判别(Regularization Linear Discriminant Analysis, RLDA)方法及正则化最大距离准则(Regularization Maximum Margin Criterion, RMMC)方法,投影矩阵W的求解可以分别通过以下形式得到:
(3)
(4)
其中,类内散布矩阵Sw和类间散布矩阵Sb定义为:
(5)
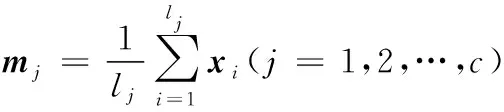
2 半监督模式下多视角特征降维框架
在半监督模式下,以上提到的FSASL方法没有考虑各单视角投影矩阵的差异。SSDR方法在特征降维时仅仅引入局部结构的保持项,且由于缺乏对低维矩阵的稀疏约束,有时无法避免噪声和其他不相关特征的影响。因此,针对以上问题,本文提出了SS-AMVE。目标函数可以分成两个部分,分别为全局结构保持项和局部结构保持项。同时,对每个视角上的投影矩阵添加行稀疏约束,具体的流程如图1所示。
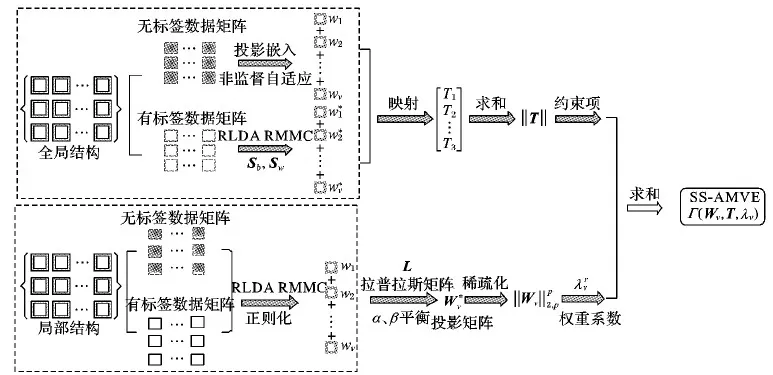
图1 SS-AMVE流程Fig. 1 Flow chart of SS-AMVE
2.1 保持局部结构的半监督多视角学习
设第v个视角上的投影矩阵为Wv=[Wv1,Wv2,…,Wv,dn]∈RDn×dn,则第v个视角上的低维嵌入为WvTXv,由此得到表达式:
(6)
对各投影矩阵添加稀疏性约束,局部保持项的目标函数变为:
(7)

同样,在有标签和无标签的数据信息同时存在的条件下,本文针对多视角半监督模式下的RLDA方法及RMMC方法中的投影矩阵进行具体的求解,以保留局部的流形结构信息。
2.1.1 半监督多视角RLDA局部结构保持
将RLDA方法由单视角推广到多视角问题,各视角下投影矩阵的表达式为:
(8)
式(8)通过最大限度地减少类内特征的分散性,来保留局部的流形结构。参数α、β则用来平衡正则化的形式。

2.1.2 半监督多视角RMMC局部结构保持
类似的,将正则化最大距离准则(RMMC)方法推广到多视角半监督特征降维,各视角下投影矩阵的表达式转化为:
(9)

2.2 保持全局结构的半监督多视角自适应嵌入
2.2.1 无标签数据信息的全局结构保持
对于不含标签的数据,可以直接将其看作非监督模式下的特征降维。非监督自适应性特征选择(FSASL)方法,并未考虑不同视角特征的差异性,认为得到的投影矩阵都是相同的。对此,进行一定程度上的推广与改进。
对每个视角分别定义一个行稀疏特征选择和变换矩阵Wv∈Rd×c。为了保留更多的特征,将各单视角下得到的投影求和作为最终选定的特征空间。对于每个特定的单视角,得到以下的结构保持项:
s. t.WTW=I,Tii=0
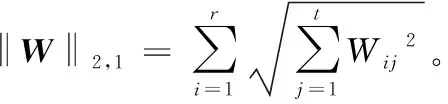
进一步,将其推广到多视角问题,对各个视角下提取出的特征进行求和,得到多视角下全局结构的表达式:
(10)
s. t.WvTWv=I,Tii=0

与成对相似性相比,稀疏表示具有一定的识别性:在所有的候选样本中,它选择距离目标最近的样本,舍掉所有其他不够紧凑的候选样本。由此,可以进一步优化对嵌入矩阵的求解。
2.2.2 含标签数据信息的全局结构保持
在半监督学习模式中,对于包含标签的一些数据,需要结合标签信息,对不同视角下的特征投影进行说明。在此,同样对正则化线性判别(RLDA)方法及正则化最大距离准则(RMMC)方法在半监督模式下的特征投影矩阵进行具体的求解。类似的,不同视角下的特征存在差异性,需要对单视角的投影矩阵分别进行定义。
考虑数据的标签信息时,对于正则化线性判别(RLDA)方法,在特定的第v个视角下,投影矩阵的定义如式(8)。对于正则化最大距离准则(RMMC)方法,在第v个视角下,投影矩阵定义如式(9)。
2.3 多视角半监督模式下的自适应嵌入特征降维
由此,将嵌入思想直接引入到半监督多视角问题中,同时对各个视角下的数据进行特征降维,完成了整体特征的重构以及局部特征的保持,最终得到目标函数:
(11)
3 算法求解
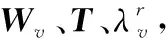

LT=(I-T)(I-T)T
L=LT+Lv
目标函数变为:
又由于μ‖T‖为独立项,与Wv无关,可转化为:

(12)
其中Dv是一个对角矩阵,对角线上的元素为:
(13)
s. t.WvTWv=I
交替迭代更新式(12)即可得到Wv对应的特征向量。

变量T只存在于第一项中,当固定其他变量时,已知约束条件Tii=0,故可由求解以下问题来对T进行优化:
s. t.Tii=0
对T求偏导,有:
μ=0
通过求解得到:
(14)
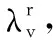

为方便表示,定义:
优化函数可以表示为:
利用拉格朗日方程,得到以下等式:
其中,σ为拉格朗日系数,化简得:
根据约束条件:
则:
(15)
由此,本文分别得到了三个变量的优化表达式,具体的更新过程如算法1所示。
算法1 自适应嵌入的半监督多视角特征间降维方法(SS-AMVE)。
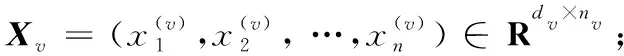

初始化:



迭代更新:
Forv=1 ToV(循环v个视角)
计算各视角下的Sw,Sb;


s. t.WvTWv=I
通过交替迭代得到Wv对应的特征向量;
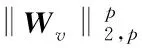

对于多视角正则化线性判别(MV-SSLDA)方法,根据式(8),计算特征值及特征向量;
对于多视角正则化最大距离准则(MV-SSMMC)方法,根据式(9),计算特征值及特征向量;
直到收敛。
分别对v个视角下Xv的特征进行排序,选取前kv个特征作为结果。
4 实验结果及分析
本文设计了4组实验来验证自适应嵌入的半监督多视角特征间降维方法(SS-AMVE)的性能和效果。
4.1 实验数据集和实验设置
在实验中,本文使用4个图像数据集,来测试自适应嵌入的半监督多视角特征间降维方法( SS-AMVE)的性能。具体包括:Yale face(http://www.oalib.com/references/9283312),Handwritten digits(http://yann.lecun.com/exdb/mnist),WebKB(http://www.cs.umd.edu/~sen/lbc-proj/LBC.html),Labelme(http://labelme2.csail.mit.edu/Release3.0/index.php),以上分别为不同领域下不同类别的图片资源。
图2给出了部分样本图像。具体的图像提取信息如表1所示。其中,维度是标签的一种属性。每个样本的标签信息,可以表示一个特定维度的数据标识;而对于多视角特征提取,标签通常代表多种含义。因此对于同一个样本,本文选取多个维度进行数据集的测试实验。对于4个数据集,随机将每个数据集中的数据分为含标签信息的数据和不含标签信的数据。将本文方法与拉普拉斯得分(Laplacian Score, LS)、半监督判别分析(SDA)、半监督特征降维框架(SSDR)、多视角半监督特征降维(Multiple View Semi-Supervised Dimensionality Reduction, MVSSDR)四种方法进行对比,各方法内容介绍如下:
1)LS方法[7]:该方法通过计算特征对于原始结构的局部保持能力,根据得分大小选择与最高分相对应的特征。
2)SDA方法[11]:该方法使用带标签的数据点来最大化不同类别之间的可分离性,通过标记数据点来估计数据的固有几何结构。
3)SSDR方法[21]:半监督降维方法中,通过成对约束矩阵平衡每个视角的嵌入投影。同时,引入线性变换使得不同视角下的不同嵌入特征矩阵具有可比性。
4)MVSSDR方法[22]:该方法将SSDR方法引入到多视角数据中,且利用稀疏正则方式进行半监督多视角特征降维。

图2 部分样本图像Fig. 2 Some sample images表1 样本数据集信息Tab. 1 Information of sample datasets
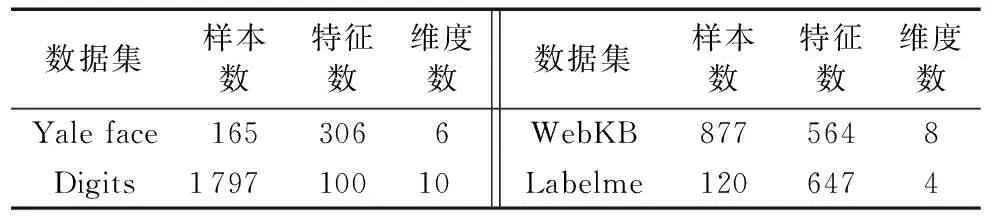
数据集样本数特征数维度数数据集样本数特征数维度数Yale face1653066WebKB8775648Digits179710010Labelme1206474
在4种方法LS、SDA、SSDR、MVSSDR中设置最近邻个数为5,参数β、γ通过格点搜索来确定。同时,将本文方法中的参数μ设为1,设定各个视角上所选特征数总数为100。对于单视角特征选择算法LS,仍按各个视角上特征数的比例来决定各个视角上要选择的特征的数量,采用逐个视角上特征降维的策略。对于MVSSDR方法,在数据上运行算法,得到各个视角上的投影矩阵来选择特征。进一步,改变含标签信息的数据量,本文对所有算法进行了15次实验,并记录了聚类准确率(ACC)的平均值和标准差。考虑到聚类性能随初始聚类中心的选择而变化,本文在4种算法中调节谱聚类形式20次。
4.2 实验结果与分析
4.2.1 半监督模式下不同方法的聚类结果
对于LS方法,采用逐个视角上特征降维的策略,通过调整各个视角上特征数的比例来确定各个视角上要提取的特征的数量。对于SSDR和MVSSDR方法,通过各个视角上的投影矩阵得到提取结果。改变含标签信息的数据量,比较含标签信息的数量不同的情况下特征降维的结果。
对于半监督的方法,利用所有可见数据集合,包括有标签数据和无标签数据,对其进行训练。5种算法和基线的聚类准确率(ACC)结果如表2所示。
从表2可以看出,除了数据集Digits外,本文提出的SS-AMVE在其他数据集中都优于其他4种方法。在WebKB数据集上,SS-AMVE比其他方法的最佳结果增加了10%以上。在Labelme数据集上,SS-AMVE平均的提升比例也接近9%。与SDA和SSDR方法相比,SS-AMVE整体上能够得到更好的结果。应用本文方法SS-AMVE,人脸图像可以被映射到由“半监督特征面”构成的半监督判别子空间中。可以看出,SS-AMVE考虑了不同视角下的投影矩阵的差异,并将其统一映射到一个组合空间中,通过引入低维矩阵可以消除不相关特征的影响。而对于Digits数据集的ACC结果,SS-AMVE虽未达到基准线,但仍然优于其他方法。

表2 不同算法聚类准确率(ACC)的平均值和标准偏差 %Tab. 2 Average and standard deviation of different algorithm clustering accuracy (ACC) %
4.2.2 不同特征数下各方法的性能比较
为了更直观地观察不同方法之间的性能差异,对于4个数据集,5种算法在不同数量特征下的聚类准确率(ACC)如图3所示。
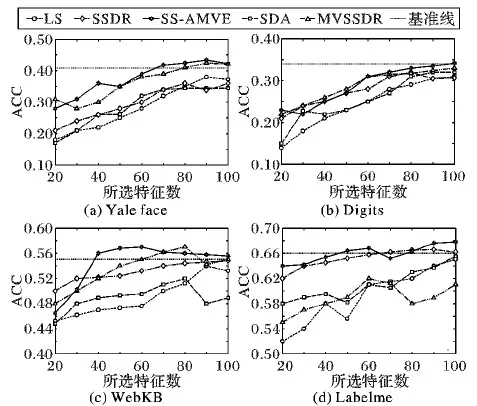
图3 不同特征数下不同方法的ACCFig. 3 ACC of different methods under different feature numbers
从图3(a)可以看出,随着所选特征数量的增加,本文方法的聚类准确率呈现平稳上升趋势,除了所选特征数为50时,本文方法都有最高的聚类准确率,且当特征数大于80时,本文方法的准确率基本趋于稳定。
从图3(b)中可以看出,对比的4个方法整体上均呈现平稳上升的趋势,并当特征数大于70时保持稳定,当所选特征数量为60~100时,本文方法虽然略低于基准线,但都有最高的聚类准确率。
从图3(c)可以看出,本文方法在处理WebKB数据集时有很好的聚类准确率,在所选特征数量是40~100时均优于基准线,并且准确率较稳定。
从图3(d)可以看出,本文方法的聚类准确率整体上变化幅度很小,当所选特征数量为20~60和80~100时能得到最优的聚类准确率。
由上述分析可知,在大多数情况下,SS-AMVE的聚类准确率优于其他方法。一方面,在选择的特征数量相同的情况下,本文的方法可以更加紧凑地保留数据的结构信息;另一方面,SS-AMVE可以实现更高效的降维,特别是在数据集WebKB中。
在Digits和Labelme中,自适应嵌入的半监督多视角特征间降维方法( SS-AMVE)的ACC值很接近或者有时略大于半监督特征降维框架(SSDR)方法,而在其他数据集中则不是很接近这种情况,表明SS-AMVE在处理部分数据方面有其自身的优势。
当特征数量较大时,SSDR有着更好的聚类性能,表明SSDR方法能有效地获得原始数据的全局和内在几何结构,从而获得更多的判别信息。
4.2.3 不同平衡程度下的样本集结果比较
在数据集WebKB和Labelme中,不同平衡程度下SS-AMVE样本集结果如表3可知。由表3可以看出,两个数据集中,在有无标签比例为1∶1时,本文方法的聚类准确率(ACC)最高,且均大于50%。由此可见本文提出的半监督方法,更适用于一些特定的数据集;当有无标签比例改变时,SS-AMVE聚类准确率稍有变化,但仍大于50%,具有一定的普适性。

表3 不同平衡程度下SS-AMVE样本集结果Tab. 3 Sample set results of SS-AMVE at different equilibrium levels
4.2.4 算法灵敏度分析
本文进行了大量的实验来测试参数的灵敏度,并选定WebKB和Labelme作为实验数据集。当β固定为1,改变γ取值时,本文方法SS-AMVE在数据集上的ACC结果如图4所示。当γ固定为1,改变β取值时,本文方法SS-AMVE在数据集上的ACC结果如图5所示。由图4~5可以发现,相较于参数β,SS-AMVE对参数γ更为敏感。在图4中, 在数据集WebKB中,当γ=1时,SS-AMVE有较高的ACC值。在图5中, 对参数β而言,SS-AMVE的ACC值相对稳定,尤其在数据集WebKB中;值得注意的是,在Labelme数据集中,当β=1时,SS-AMVE的ACC值几乎是不变的。
4.2.5 算法收敛性
自适应嵌入的半监督多视角特征间降维方法(SS-AMVE)在数据集WebKB和Labelme下的收敛性曲线如图6所示。由图6可以看出,目标函数值在迭代期间不增加,并最终收敛到固定值,SS-AMVE在10次迭代内收敛,表明了该方法具有较为快速的收敛速度。

图5 SS-AMVE在不同特征数和β下的ACC(γ=1)Fig. 5 ACC of SS-AMVE under different feature numbers and β (γ=1)
4.2.6 算法复杂度


图6 不同迭代次数下SS-AMVE的目标函数值Fig. 6 Objective function values of SS-AMVE under different iterations
5 结语
本文提出了一种半监督特征降维方法,即自适应嵌入的半监督多视角特征间降维方法(SS-AMVE),直接将嵌入思想引入到多视角中,并将从各个视角提取的特征映射到一个统一的空间,以保持整体的全局结构。考虑到不同视角下的特征可能不同,本文将各单视角下相同的嵌入投影矩阵推广到多视角间的不同矩阵。对于有标签与无标签的信息同时存在的高维数据,在局部特征得到保留的基础上,增加了全局结构的保持项。将不含标签信息的数据利用无监督模式方法进行嵌入投影;对于含有标签的数据,结合分类的判别信息进行线性投影。使用组合权重矩阵来保留全局结构,很大程度上消除了噪声及不相关因素的影响。实验结果表明,自适应嵌入的半监督多视角特征间降维方法(SS-AMVE)是保持全局和局部结构的有效方法,在半监督多视角问题中可以更好地提取出具有判别信息的特征。
本文所提方法涉及到了特征值分解,而这一过程的时间复杂度对于计算机的内存要求大,且时间效率不够高,因此需要寻求更好更快的解决方法。同时,方法中参数的设定值影响提取效果,而如何确定参数的最优值,是进一步需要研究的方向。
