大数据智能运维运营系统在运营商的设计与应用
2019-01-06王巍
王巍

摘 要:在运营商某融合通信系统中,传统的Hadoop海量文件批处理速度慢,数据库面对海量数据存储及全文检索能力弱,无法应对日常运维需要。处理海量业务日志且提升实时性,技术选型flume+Kafka+Spark+ElasticSearch,改造为流式计算大数据技术架构。文章结合业务诉求,基于领域模型全新设计,DashBoard分层递进,渐进明细地实时发现故障—初步分析—根因分析—定界定位,大幅提升系统运维运营能力和时效性的同时,还降低了人力成本。
关键词:大数据;智能运维;Kafka;Spark;ElasticSearch
运营商某融合通信运维系统原本选型Hadoop,该技术架构尽管能处理海量业务日志,但因为基于文件传输和MapReduce的批处理延迟较大,每批次处理最快也要20 min左右才能入库查询。运维讲求时效性,业务故障后几分钟内就要及时发现并分析定位解决,Hadoop文件批处理技术架构往往在用户投诉上来后,日志还在下一批次的处理入库中,无法满足日常运维需要。数据库面对海量日志存储和各种组合查询力不从心,同时,系统业务设计单一,只有业务上报的告警和日志查询,运维能力过于单薄。
1 架构设计
针对上述运维诉求的痛点,急需设计一套能实时处理大容量日志、支持海量日志存储且可组合检索、贴近运维运营诉求、统计分析简约易用的大数据运维运营系统。
1.1 逻辑架构
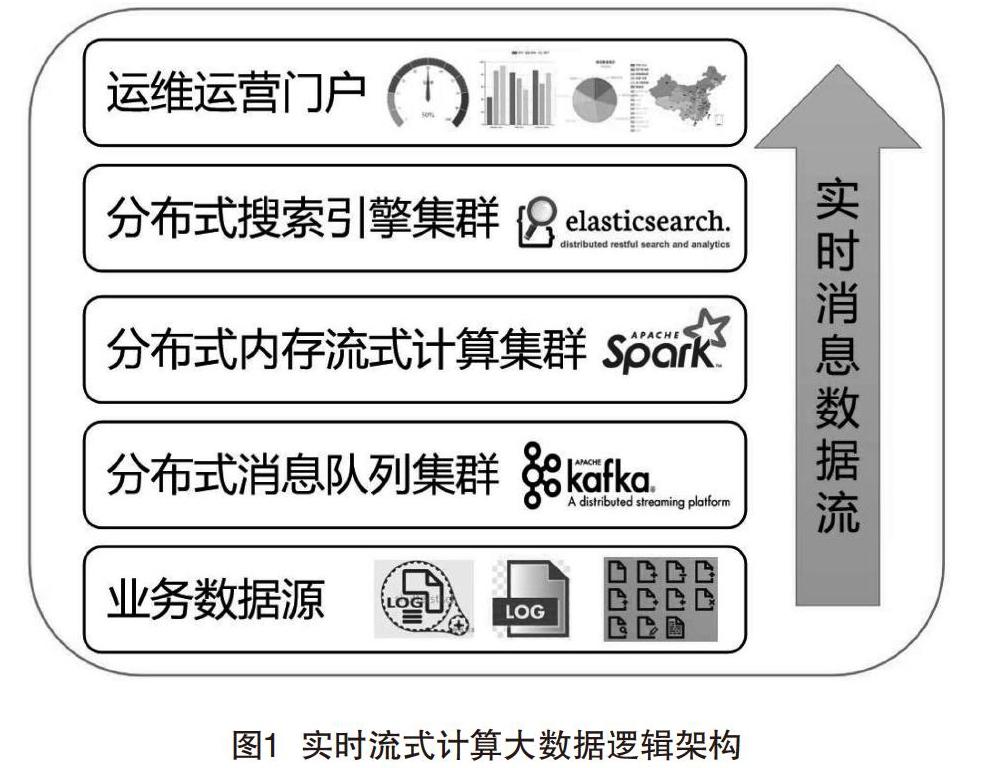
首先,从逻辑架构出发,结合业务痛点,逐层梳理设计并技术选型。实时流式计算大数据逻辑架构如图1所示。
(1)业务数据源。原本由自身业务系统生成日志文件SFTP定时采集,改造为日志消息接口实时发送;原本第三方系统生成日志文件SFTP定时采集,改造为flume或logstash实时采集。
(2)分布式消息队列集群。该层用于前台业务和后台运维运营系统消息异步处理,系统间隔离解耦,同时避免多套业务系统日志对后台运维运营系统的流量冲击,进行削峰。最终选型Kafka,因为Kafka是一个基于发布/订阅模式的分布式消息队列,完全满足上述特性要求,且对记录2 KB以内的日志,单模块处理性能经测试就可達近10万TPS,还支持持久化,是业界实时大数据日志处理MQ的事实标准组件。
(3)分布式内存流式计算集群。该层用于从Kafka实时消费各个topic的日志数据流,进行实时流式计算,如实时日志清单入库、实时分组统计多维度的业务量、失败量等可累加指标;同时也要具备海量数据的批处理能力,用于从持久化到HDFS的数据批量计算不可实时统计的日活用户排重、top失败等指标。最终选型Spark,因为Spark是一个同时支持流式计算(Spark Streaming)和批量计算(SparkSQL/RDD)的大数据处理系统,完全满足上述特性要求,且可无缝对接Kafka和ElasticSearch集群。Spark Streaming相当于mini batch的RDD批处理,也就是说流式计算和批量计算的开发方法基本相同,且对各类分组、排序、排重等常用统计进行了函数封装,大幅降低了研发学习和开发成本。业界也有很多成功应用案例。
(4)分布式搜索引擎集群。该层用于存储海量日志清单,同时需要支持多维度组合条件查询分析。最终选型ElasticSearch,因为ElasticSearch底层是基于lucence索引的分布式搜索引擎,完全满足上述特性要求,相对solr可以支持更大数量级的日志存储和检索,提供了各类Rest接口的API,方便进行分组、聚合等轻量级快速、灵活查询分析,还支持全文检索。业界也有很多成功应用案例。
(5)运维运营门户。该层需要结合业务设计,DashBoard多维度展现各类统计分析监控指标,支持钻取、联动分析等。业界有Grafana、Kibana可以使用。最终选型是自身的Web管理平台,原因是自身的Web管理平台还具备权限管理、操作日志、告警界面展现等,并支持菜单集成挂载链接到Grafana,Kibana等。
1.2 技术架构
在逻辑架构和已选型的组件基础上,进行了架构细化、业务功能设计与组件实现相对应,让数据流在整套系统内流转起来,并在实验室部署调试验证组件功能和性能,从无到有搭建,小步快跑逐步实现了整套系统。实时流式计算大数据技术架构如图2所示。
2 业务设计
2.1 故障告警专题
告警是运维系统监控发现故障问题的重要手段,是整套运维系统的最先切入点。
传统的告警功能是业务触发告警一一对应。本专题设计了3层灵活组装模型:基础指标—组合指标—告警策略,只需要向业务获取基础指标。本运维系统基于基础指标和算术表达式,可灵活定义配置出新的组合指标;基础指标和组合指标又可以任意逻辑组合,灵活定义配置出新的告警策略。举例如下:
基础指标,每分钟业务量、每分钟成功数。
组合指标,在运维系统配置即可新增“业务成功率(%)组合指标”=每分钟成功数/每分钟业务量×100%。
告警策略,系统配置新增“平日夜间告警策略”。
时间范围:周一至周五,22:00—5:30。
优先级:1。
告警策略:(每分钟业务量>10)AND(业务成功率(%)组合指标<95(%)。
可以看出,该专题设计大幅减轻了业务系统的告警工作,转由本运维系统灵活配置快速组装承载,降低了研发人力的同时,还增强了运维能力。
2.2 业务质量专题
故障告警专题钻取联动的下一级是业务质量专题:当运维人员发现系统业务告警后,点击告警,系统自动钻取联动跳转到对应的业务质量界面,在故障发生时间点粒度内,结合界面的时间趋势图等DashBoard,多维度分析,初步判断故障发生的业务类型、地域、终端类型、终端版本、APP版本等。
2.3 质量分析专题
业务质量专題钻取联动的下一级是质量分析专题:运维人员在业务质量对故障发生的业务类型、地域、终端类型、终端版本、APP版本等维度有了初步判断,界面点击,系统自动钻取联动跳转到相同维度的质量分析界面,在故障发生时间点粒度内,对应维度的业务内部错误码、外部失败响应码按出现次数TOP倒排分析,让运维人员迅速得知故障根因。
2.4 故障定位专题
质量分析专题钻取联动的下一级是故障定位专题:运维人员在质量分析界面点击出现次数TOP的业务内部错误码、外部失败响应码,系统自动钻取联动跳转到相同维度条件的详单查询并自动查询,展现出来受此影响的用户和波及业务详单记录,让客服提前做好准备解答客户问题。
2.5 资源占用专题
仪表盘、时间趋势图实时展现当前系统各类业务资源、缓存资源、CPU、内存、存储资源的占用和访问情况等。
2.6 用户分析专题
运维之外,系统还具备分地域、分终端,各APP等维度的已开户用户数,日活、周活、月活用户数,当前在线用户数等用户运营分析指标、发展趋势、占比分析等。
3 结语
本大数据运维运营系统目前已在运营商某融合通信系统成功上线商用,运维人员从担心用户投诉,手工采集日志打包反馈研发耗时、耗力,到系统自动业务告警及时发现故障,运维人员钻取联动自行初步判断、根因分析、故障定界定位、实时监测系统和业务资源占用等,运营人员自助报表分析用户行为,大幅提升了运维运营能力的同时,从过去的几十人运维团队降低到10人以内,得到了客户、运维、运营、研发的一致认可。
[参考文献]
[1]李祥池.基于ELK和Spark Streaming的日志分析系统设计与实现[J].电子科学技术,2015(6):674-678.
[2]毛开梅.大数据智能运维系统设计及应用[J].网络与信息工程,2018(14):62-63.
Design and application of big data intelligent operation and maintenance system in operators
Wang Wei
(Zhongxing Telecommunication Equipment Corporation Co., Ltd., Nanjing 210012, China)
Abstract:In a converged communication system of the operator, the traditional Hadoop mass file is slow in batch processing speed, and the database faces massive data storage and full-text retrieval capability, so that the daily operation and maintenance needs cannot be met. In order to deal with the massive business log and improve the real-time performance, the technology type-type flume+Kafka+Spark+ElasticSearch is transformed into a stream-type large-scale data technology architecture in this paper. Based on the new design of the domain model and the new design of the domain model, the real-time discovery of the DashBoard hierarchical progression and the progressive details is based on the analysis of the position of the analytic hierarchy, and the operation and maintenance of the system is greatly improved. While operating ability and timeliness, it also reduces the cost of manpower.
Key words:big data; intelligent operation and maintenance; Kafka; Spark; ElasticSearch
