一种基于用户群的高铁专网断点定位方法与实践
2018-12-21张璐岩贾磊
张璐岩,贾磊
(中国移动通信集团陕西有限公司,西安 710077)
截至2017年底,我国高铁运营总里程接近30 000 km,全年运送旅客约17.13亿次,同比增长18.7%。即时通信、网页浏览、流媒体视频、手机网游等业务是当下高铁旅途中旅客打发时间消遣的主要方式。为保证用户网络体验感知,高效、准确、低成本的识别高铁用户、优化高铁网络就显得至关重要。
1 高铁网络优化现状
用户在高铁环境下对移动网络业务体验的需求随时考验着我们高铁移动网络建设和优化成果。以目前的高铁网络优化情况来看,仍面临着以下几个主要问题。
传统高铁网络优化工作主要依靠人工仪表拉网测试、获取数据进行分析,测试时间成本、资源成本较高,且网络分析对优化人员能力要求较高。
识别高铁用户的成本较高,当前高铁用户识别的主流方法是利用多普勒频移、切换序列等方法实现,复杂度较高、硬件设施要求严格。
用户群共性问题不易体现,多数体现为测试机及所在位置的网络问题,不能代表真实用户感知。
为满足当下高铁网络优化的需求,急需一种全新的优化手段来代替传统的优化方式。
2 基于用户群的高铁专网断点定位方法
为节省优化成本,需将大量重复性的人工工作转化为自动优化。本文从识别高铁用户群体出发,利用相关网络数据判别出公专网频繁切入切出问题,运用聚类算法发现问题高发区域,建立自动优化体系并应用于实践。
2.1 基于大数据的高铁用户识别
高铁用户的行为特征是在一定时间内具有相同的运动轨迹。利用该特点及MR采样数据,可从时间及空间两个维度联合判定,识别符合高铁用户特点的用户信息。
其中,上述MR采样数据来源为UE侧物理层上报无线信号的测量结果,用于移动性管理中切换/重选事件的触发,包含采样时间、小区ID、MME-UES1AP-ID、RSRP等信息。
下面将从时间、空间维度分别分析,并描述高铁用户识别的具体原理。
在高铁G站的用户从时间和空间维度可分别表示为:
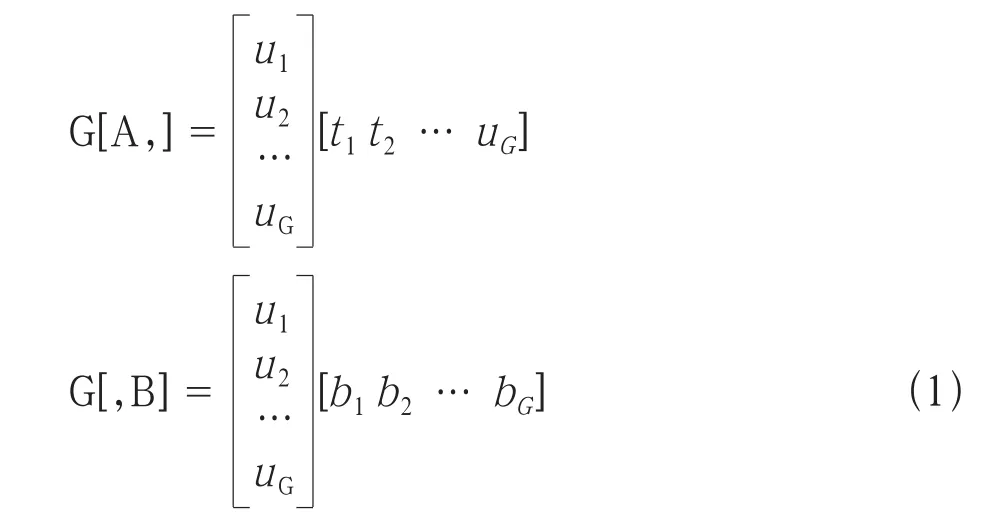
其中, G为表示高铁G站时间、空间的二维矩阵,A与B分别为表示时间及空间维度的矩阵。
时间(A):从时间维度,MR数据采集时段需在高铁停运时间之外,建议冗余为15 min。如当高铁列车从A站至B站,发车时间为9:00,到站时间为9:35,则考虑到用户在高铁站等枢纽滞留时间,数据采集时间建议为8:45~9:50。当用户占用G1站高铁小区时间与占用G2站高铁小区时间差等于列车从G1站至G2站的时间,则认为从时间维度该用户符合高铁用户特点。
空间(B):选取高铁车站覆盖小区进行比对,当某用户占用过不同高铁站的覆盖小区时,认为该用户从空间维度符合高铁用户特点。
将时间、空间结合运算,取二维矩阵G1与G2的交集,即当某一用户同时占用过两个不同高铁车站的覆盖小区,且该用户占用两高铁站专网小区的时间间隔与两个车站间列车的行驶时间相符,则该用户为高铁用户。
2.2 结合MR+OTT数据与聚类算法实现问题区域锁定
将高铁用户的MR数据通过OTT实现地理位置定位,采用比对算法分析占用小区合理性,甄别公专网切入切出的网络问题,并记录问题采样点,借助K-means聚类算法不断进行聚合、锁定出专网问题的高发区域。
其中,运营商为保障用户能够获得良好的业务感知,在重点交通道路沿线建设专网进行覆盖,用户在使用专网信号时,因某种原因脱离专网信号进入公网的现象,称之为出专网问题。高铁问题区域识别方法流程如图1所示。
2.2.1 基于信令中OTT关联实现MR数据定位
OTT定位指依托互联网向用户提供的各种应用服务,基于APP软件获取用户的位置信息。通过采集用户S1-U接口中的HTTP原始码流来获取对应用户此时刻的OTT应用信息,先后经历数据清洗、数据筛选,获得有用的位置信息;同时,基于时间和MME-UES1AP-ID信息将MR数据与OTT定位经纬度位置信息进行关联,实现此时刻的 MR数据定位。MR经纬度关联算法示意如图2所示。
2.2.2 基于MR数据判别出专网问题
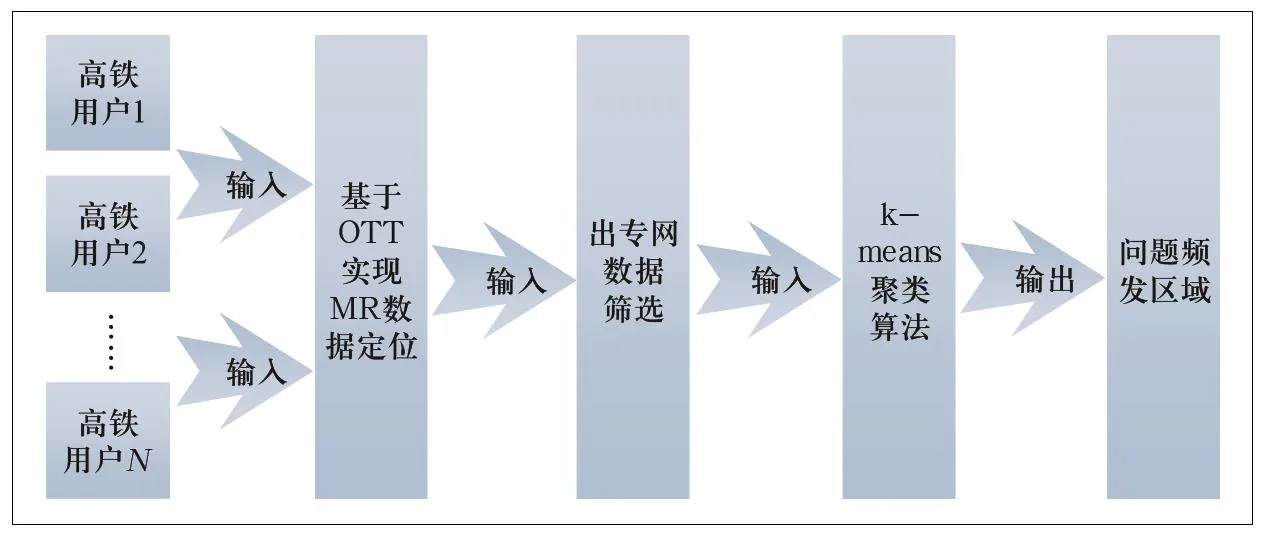
图1 高铁问题区域识别方法流程图
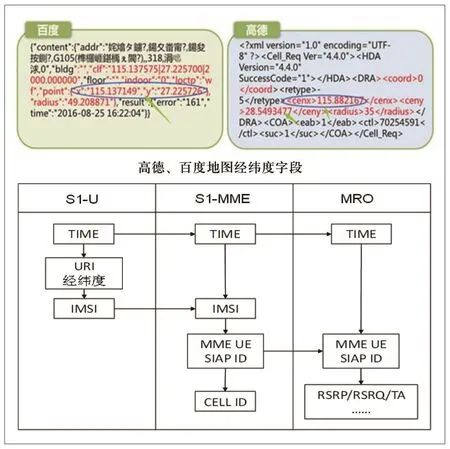
图2 MR经纬度关联算法示意图
提取MR数据中每个高铁用户的占用小区信息,将高铁专网小区(按行驶方向排列)与用户占用小区(按时间序列排序)进行匹配,若连续序列中长时间、多次出现占用非专网的小区,则判定为出专网事件。由于每个用户在乘坐高铁时可能存在多次出专网事件,故回到专网后需继续匹配,并记录出每一次专网的MR采样点。高铁专网问题识别流程如图3所示。
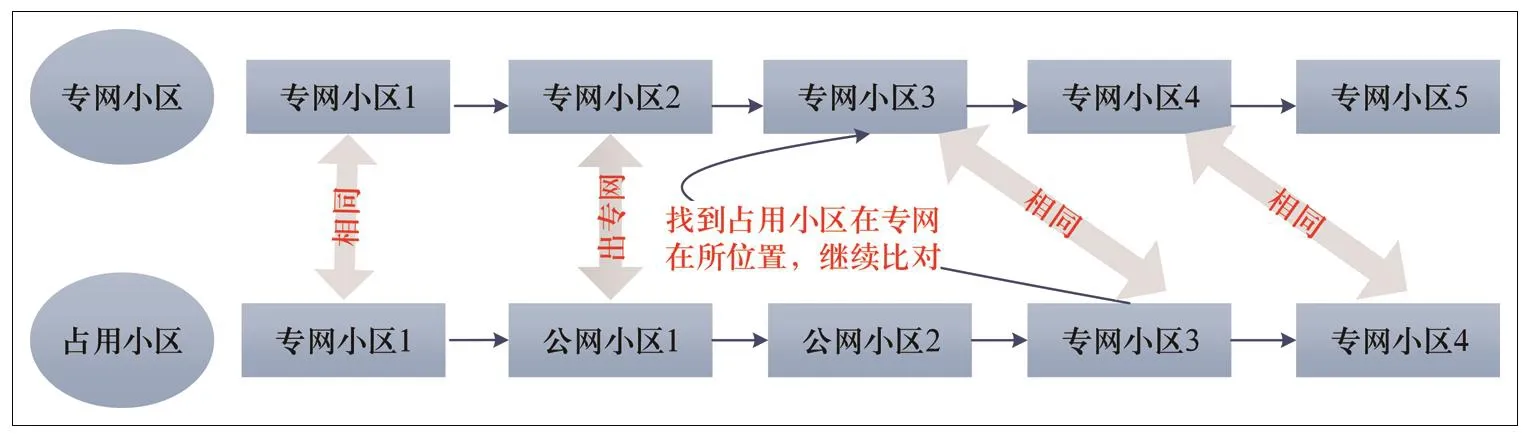
图3 高铁专网问题识别流程图
2.2.3 借助K-means聚类算法锁定问题高发区域
如图4所示,基于高铁场景的K-means算法描述如下。
(1)选取K个出专网MR采样点作为初始聚类中心。可根据高铁小区覆盖能力,间隔一定距离(如2 km)取K个经纬度作为初始中心点。
(2)将所有出专网MR采样点按最小距离原则分配到最邻近聚类。上述最小距离,由每个采样点与初始中心点经纬度的欧几里距离计算,即对于第i个出专网的MR采样点,其与第k个初始中心的距离可表示为dik=,若 min(dik)=,则采样点i此次归于k(k∈K,表示迭代过程中的中心点之一)聚类族中。
(3)根据聚类的结果,对于K个分组,取每个分组的经纬度的均值,重新计算K个聚类的中心,并作为新的聚类中心。
2.3 基于结果校正的自动分析优化

图4 借助k-means聚类算法锁定问题高发区域示意图
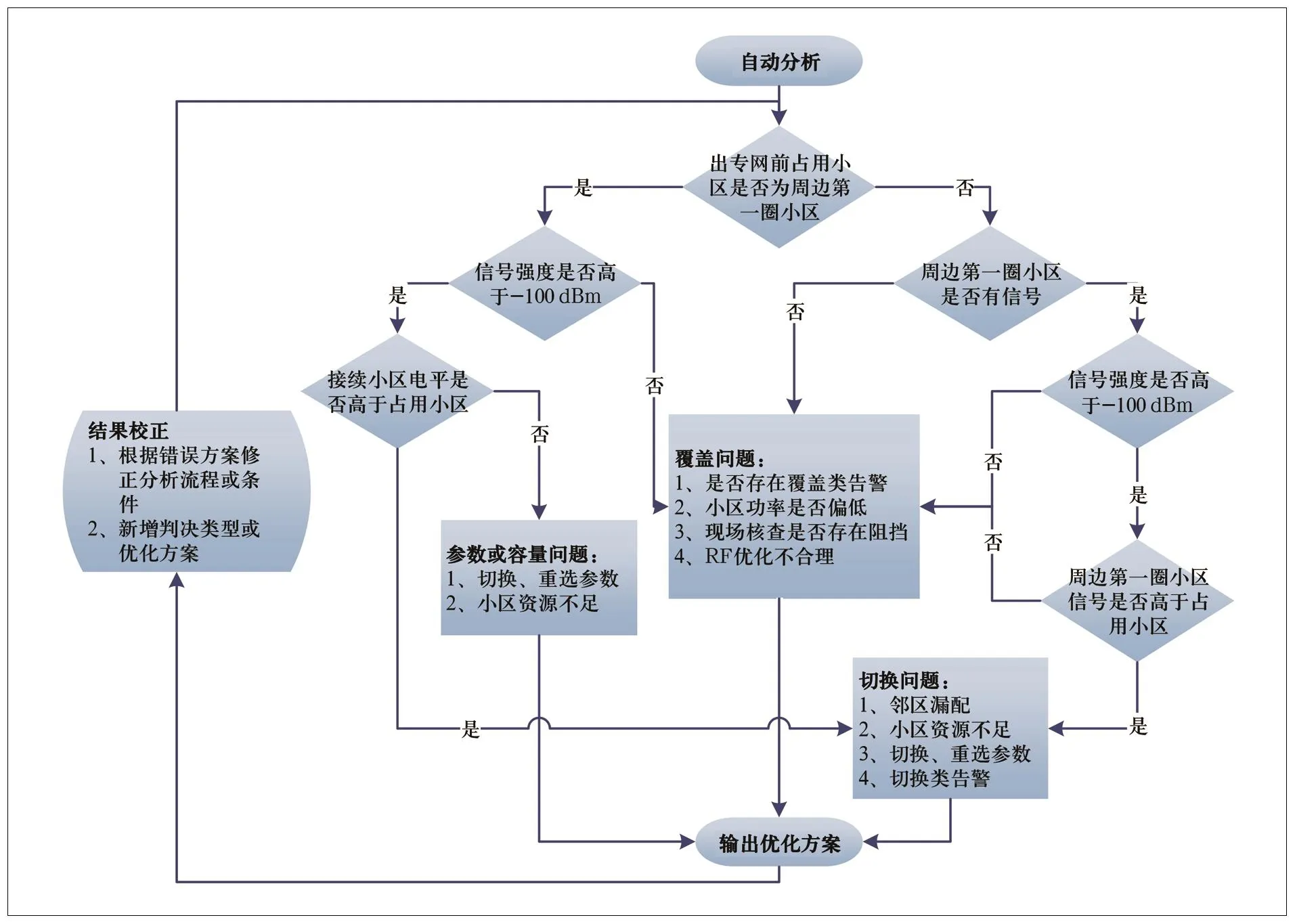
图5 高铁断点问题自动分析的流程图
导致高铁用户出专网的问题主要原因有基站故障、切换参数不合理、RF优化不合理、小区拥塞等,结合问题原因的优化方案及日常优化工作经验模拟人工分析问题思维形成一套自动分析优化体系,同时根据实际情况检验方案的准确性,针对判决条件有误的流程及时修改,提高分析问题的精准度。
建议的自动分析优化流程如图5所示。
3 基于用户群的高铁专网断点定位优化实践
为说明本文所提基于用户群的高铁专网断点定位方法的有效性,通过仿真和实际工作验证了所提算法的性能。
(1)随着用户数增长,所提算法的准确率增高且逐渐接近于100%。
(2)以月为粒度,所提方法获取的有效采样点数高达百万级,全面体现了用户群共性问题;而传统优化方法获取的有效采样点数为十万级,只能体现测试机及所在位置。
(3)本文所提方法依托于现有数据采集平台进行自动分析,几乎无成本;而传统优化方法需消耗大量人力、车辆费用、设备费用和话费,大中级地市每年优化成本近百万。
由上述可知,本文所提算法能在消耗更少资源的情况下实现与传统优化方法相近的效果。
为更好说明所提算法在实际工作中的效果,选取某高铁试点应用。提取MR、信令等相关数据,参照基于大数据的高铁群用户优化方法识别高铁用户并整理筛查出专网问题,汇聚后自动分析并输出优化方案。现场验证优化方案,智能分析准确率高达95%以上。详细过程如下。
确定覆盖某始发客站、某到达客站及沿线的高铁小区清单。
查询高铁客运表该线路运营时段为7:30~23:59,两车站间的运行时间为1 h。
提取连续3天的信令数据,统计某高铁用户约1.5万人。
(4)提取相应时段高铁用户的MR数据,通过关联信令数据获得当时刻点的MR经纬度信息。
(5)与某高铁小区匹配,共筛查出频繁切入切出专网问题2 700多条。
(6)将切入切出专网问题点经纬度和10个初始聚合中心输入K-means聚类算法,得到4个切入切出专网频次较高的密集区域。
(7)把密度较高的4个区域内的小区问题按照自动分析优化体系进行分析,最终将问题定位为集中的6个高铁小区的故障告警和参数设置不合理所致。
4 总结
基于大数据的优化方法数据来源广、反映问题全、更贴近用户真实感受,可有效挖掘网络共性问题,解决用户需求。相比传统优化手段,数据采集自动化、数据分析自动化,大幅降低人力成本和提升工作效率。本文提出的网络优化方法不仅适用于高铁场景,也可用于高速、景区等区域特征明显的场景,后续工作中可进一步推广至其它场景。
