高效LDPC译码器的优化与FPGA实现
2018-12-19王建新
薛 文 余 海 王建新 束 锋
(南京理工大学电子工程与光电技术学院, 南京, 210094)
引 言
LDPC码是一种接近香农极限的好码,广泛应用于卫星通信、深空通信及无线通信领域。欧洲第2代卫星电视标准[1]就采用了LDPC码作为前向纠错码。国际空间数据系统咨询委员会[2]也在其近地及深空通信的标准选择LDPC码作为纠错编码之一。LDPC码是由Gallager于1963年提出的[3],起初没有得到重视,直到20世纪90年代末期Mackay等“再发现”了LDPC码,并提出了和积算(Sum-product algorithm, SPA)[4],使得LDPC码真正成为了一种实用的接近香农极限的好码。和积算法从纠错性能角度来说是一种最优的译码算法,但是考虑到硬件实现时复杂度还是较大。文献[5]中针对译码算法中的校验节点更新算法,提出了一种简化算法,用比较运算代替了SPA中的非线性运算,叫做最小和算法(Min-sum algorithm, MSA)。这种算法不仅降低了算法复杂度,同时还是一种不需要信道估计的算法。MSA的纠错性能相比SPA有比较明显的下降。针对这个问题,文献[6,7]中给出了两种修正算法,分别叫做规范化最小和算法(Normalized min-sum algorithm, NMSA)和偏移最小和算法(Offset min-sum algorithm, OMSA)。这两种修正算法对简化过的校验节点更新算法进行了修正,使其计算结果更接近于SPA中的结果,从而在略微增加了计算复杂度的前提下大大改善了译码性能,使得修正后的MSA能够很接近SPA的性能水平。
除此之外,通过对LDPC码译码迭代方式的改进也可以影响译码性能。Mansour等借鉴Turbo码的译码方式,提出了另一种迭代译码方式,叫做Turbo译码消息传播(Turbo decoding message passing, TDMP)[8,9]方式,也被称为分层译码(Layer decoding)。研究表明,达到同样的译码性能,TDMP所需的迭代次数要远小于两相消息传播(Two phase message passing,TPMP)。国内针对准循环LDPC码硬件实现工作也较多,文献[10]提出了一种基于IR-UWB系统的高速准循环LDPC编解码器,其设计思路值得参考。评价一个LDPC译码器的优劣也并没有一个简单的标准。正如在文献[11]中提到的,译码器的好坏要从资源消耗、吞吐率和纠错能力这3个方面来进行综合考量。
1 译码算法选择
本文的设计需求是设计一个高效的FPGA实现硬件译码器。目前适合高效实现的LDPC码主要是一些准循环的Block-LDPC码,本文选择了802.16e(WiMAX)标准中定义的准循环LDPC码作为实现目标。
1.1 校验节点更新算法
对几种常用校验节点更新算法及其改进算法,SPA,MSA,NMSA和OMSA,利用密度进化原理进行了性能估计。图1是上述几种算法的估计性能比较图。实际通信中接收信号的信噪比是未知的,考虑估计误差,以上几种算法性能估计如图2所示。在不考虑信噪比估计误差时SPA性能最佳,MSA最差,NMSA与OMSA基本相当,考虑信噪比估计误差,SPA性能恶化,而MSA,NMSA和OMSA的性能几乎不变。其原因主要是校验节点更新算法的差异性,MSA中校验节点更新算法的表达式为
(1)
其中主要运算为求最小值的运算,比较运算的结果对于输入数据的绝对大小并不敏感。进一步比较NMSA和OMSA,发现NMSA更加适合于硬件实现。这两种算法对校验节点更新结果的修正方式为
(2)
L(rji)=sgn(L(rji))·maxL(rji)-β,0
(3)

图1 几种典型算法的性能估计及比较 图2 考虑噪声估计误差后的性能估计结果
Fig.1 Performance estimation and comparison Fig.2 Performance estimation result considering noise
of typical algorithm estimation errors
可以看出,式(2)中的运算效果与校验节点更新值的绝对大小完全无关,但是式(3)中的偏移因子β如果设定好后,其被修正值一定要与之对应,如果被修正值的绝对大小发生改变,则修正效果将会改变。因此从这个意义上来说,NMSA虽然消耗的资源略多,但是NMSA显然更加实用。
1.2 迭代译码方式选择
最初Mackay提出的译码算法中迭代方式都采用了TPMP方式即迭代过程分为水平迭代和垂直迭代两个基本步骤,TDMP方式的译码流程和TPMP方式有很大不同。这种译码迭代方式主要适用于准循环LDPC码。准循环LDPC码一般都是Block-LDPC码,其校验矩阵的是一个分块矩阵。
(4)
式中Pi,j是z×z的子矩阵,一部分为全零阵,另一部分为单位置换阵,单位置换阵是指单位阵进行循环移位所得到的矩阵,其特点是行重和列重均为1,这个特性很适用于TDMP译码。一般在表示校验矩阵时,常用特定的数字替代式(4)中的子矩阵,这样得到的矩阵称为母矩阵(Base matrix),可用来表示结构相同但码长不同的一类准循环LDPC码。母矩阵中每行所对应的校验矩阵称为一个块行,每列对应的校验矩阵称为一个块列。为了叙述方便先定义一些变量。定义Pi为一个n维数组,其中n表示LDPC码的码长,用于存放变量节点的后验概率。定义Qi为一个n维数组,用于存放传递给校验节点的消息。定义Rij为一个Mb×n的数组,用于存放各层校验节点更新的结果。
(1) 初始化
(5)
(2) 子迭代
第p次迭代中,第m次子迭代中的第s个节点更新的表达式为
Q(1:Nb)(s)=P(1:Nb)(s)-Rp,(1:Nb)(s)
(6)
Rp,(1:Nb)(s)=fQ(1:Nb)(s)
(7)
P(1:Nb)(s)=Q(1:Nb)(s)+R(1:Nb)(s)
(8)
其中函数f表示校验节点更新的计算公式,可以选择各种不同的算法。对于每个子迭代要完成z个节点的更新,每次迭代要完成Mb次子迭代。
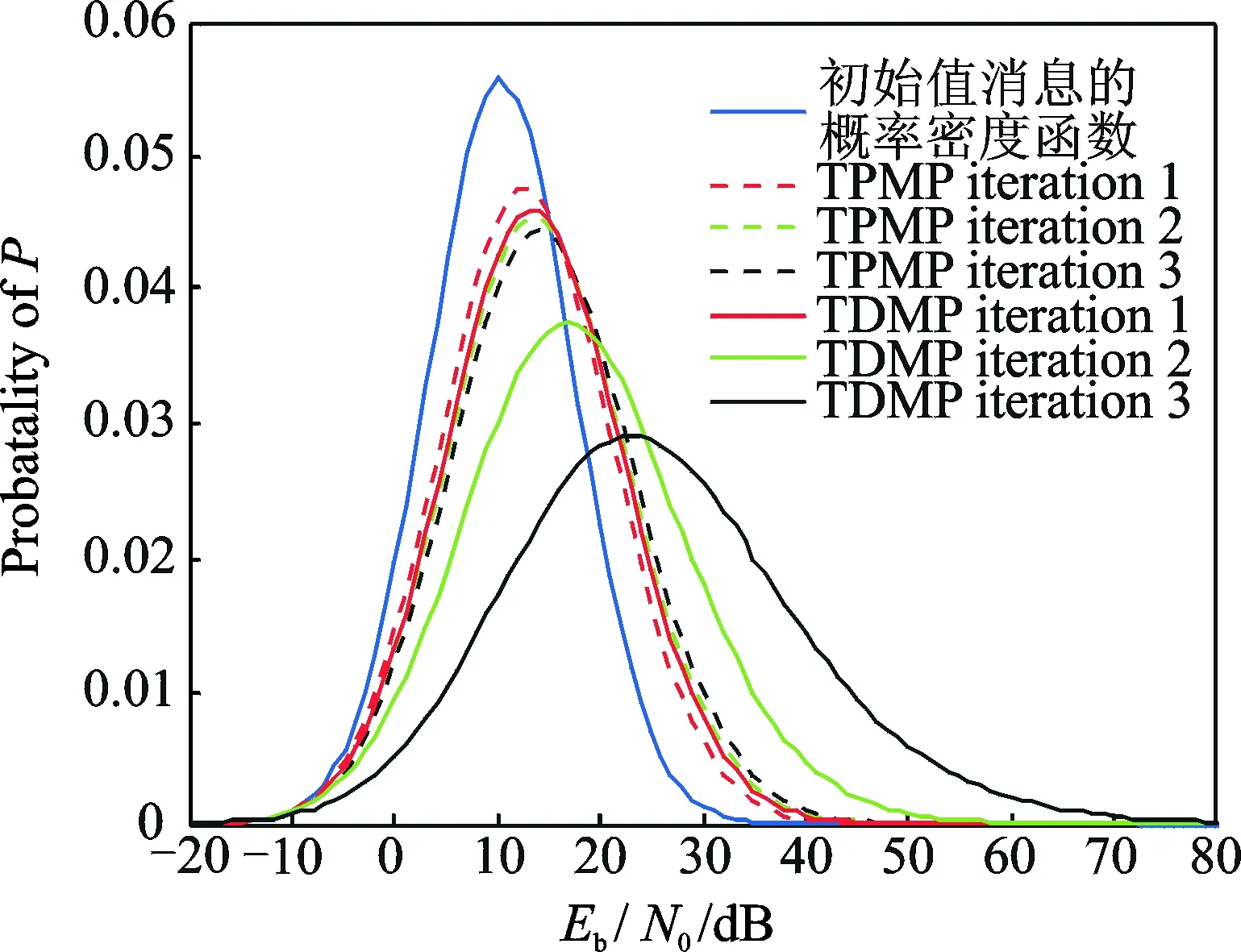
图3 TDMP与TMPM变量节点后验概率的概率质量函数的进化Fig.3 Evolution of variable node posterior probability probability mass function for TDMP and TPMP
(3) 判决与停止迭代条件
每完成一次迭代可以对后验概率Pi进行判决,判决结果若满足校验矩阵则译码成功,否则返回步骤(2),直到达到最大迭代次数退出。
利用离散密度进化的思想,给出了准循环LDPC码的TDMP离散密度进化算法。图3是各变量节点P消息的概率质量函数随迭代次数增加的进化过程。同样的迭代次数下,TDMP译码的密度进化过程明显更快,其相应的误比特率也较TPMP更低,所以实现高速译码器,应该选择TDMP方式。
2 译码算法相关参数的优化
目前大多数译码器采用定点实现,一般经定点化后性能会有不同程度的下降。译码算法进行定点化时需要考虑输入的初始化信息的量化精度和迭代译码过程中消息在进行运算时的量化精度。
利用TDMP的离散密度进化算法先对输入初始消息的量化精度进行优化。分别采用不同的输入量化精度,并采用离散蜜度进化算法对译码性能进行估计。图4是输入消息不同量化精度下利用密度进化得到的误比特率性能估计结果。量化精度为5 bit时最差,而量化精度为6 bit和7 bit时在较低信噪比下性能相当,但是高信噪比时量化精度高的性能反而更差。从图4中可以看出,P消息值随迭代次数增加而增加,因此会出现限幅效应,相比之下,输入消息量化为6 bit时初始值较小因此限幅效应影响较小。将输入消息量化为7 bit时,中间量化位宽调整为8 bit,再次使用离散密度进化算法进行性能估计,结果如图5所示。此时输入位宽为7 bit的性能略好于输入为6 bit,但是差距很小。不妨将输入消息的量化精度暂定为6 bit。改变迭代中间过程中消息的位宽,估计性能,结果如图6所示。当位宽为6 bit时性能较差,位宽采用7 bit和8 bit时性能几乎一致。综上所述,输入消息的量化位宽选择设定为6 bit,而迭代中间过程消息的量化位宽选择为7 bit是比较合理的设定。利用离散密度进化对硬件实现时的具体参数进行优化设计,取代原有的靠仿真确定具体实现参数的方法,大大提高了效率,且最终实现结果也证明这种优化方法达到了较好的效果。
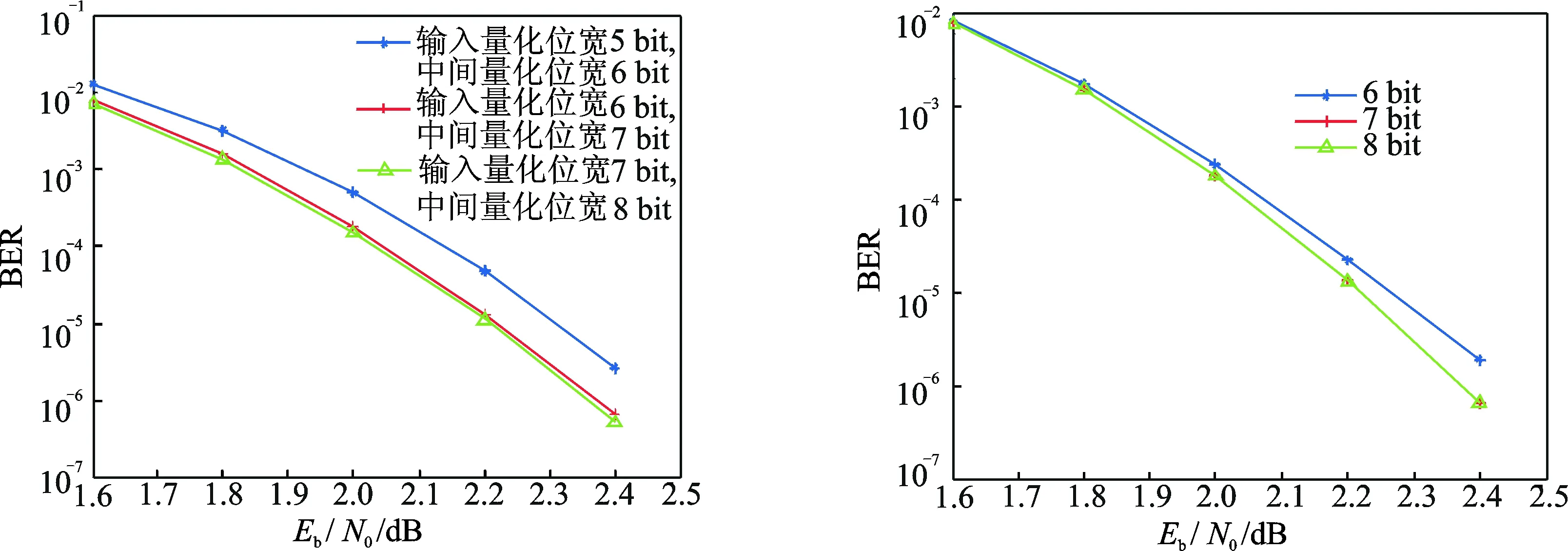
图5 不同输入量化位宽和中间量化位宽下的性能比较 图6 不同中间消息位宽下的性能比较
Fig.5 Performance comparison of different input Fig.6 Performance comparison of different
quantization bit width and intermediate intermediate message widths
quantization bit width
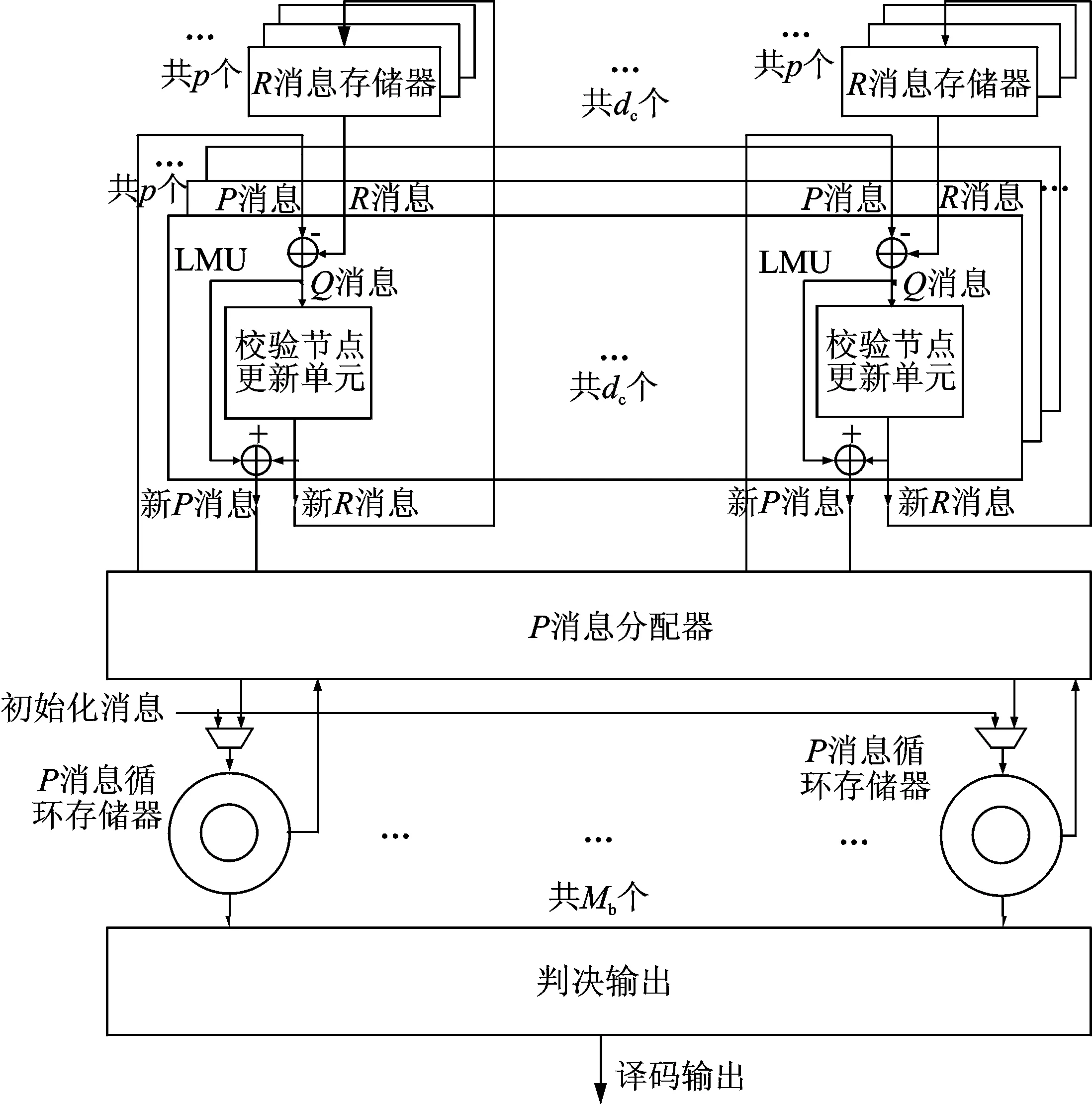
图7 LDPC译码器实现框图Fig.7 LDPC decoder implementation block diagram
3 译码器的FPGA实现
高效译码器的FPGA实现过程中有几个关键点:高效的迭代译码结构、设计结构更加优化的译码器功能模块、合理的存储结构以及合理的流水线结构。其中节点更新单元及存储结构的设计是难点,本文采用了基于TS结构的高效节点更新单元,并提出了一种适合码字结构的P消息存储单元结构,较好解决了这两个难点问题。
3.1 译码器总体框架
1.2节中给出了TDMP的译码具
体流程,按照这个实现流程,译码器的实现框图如图7所示。译码器可以分成以下几个主要部分:
(1)分层消息处理单元:
分层消息处理单元(Layer message processing, LMU)是主要的运算模块,主要完成变量节点后验概率值(P消息)和校验节点消息(R消息)的更新运算。
(2)P消息循环存储器
这是本文提出的一种重要的实现结构,其功能是高效存储上一次子迭代得到的P消息,并且能高效地读出提供给下一次子迭代,相当于一个交织器。
(3)R消息存储器
该模块用于存储每一层更新的R消息。由于每次子迭代时都需要利用上一次迭代中该层对应的R消息,因此在每次迭代中每一层的R消息都必须保留以备下次迭代时调用。
(4)P消息分配器
由于校验矩阵中每层中都存在一些全零阵,因此每次进行分层消息处理时只是将部分P消息存储器(非零子矩阵所对应的P存储器)中的消息传递给分层消息处理单元,所以需要对P消息进行分配。
(5)判决输出模块
对P消息进行判决,并通过校验决定是否停止迭代。
3.2 分层消息处理单元
分层消息处理单元在实现时先完成式(1)中的运算,然后再根据式(2)进行校正得到最终计算结果。式(1)中运算的硬件实现过程为
(9)
式中:Minpos表示最小值所对应的消息标号,Min2表示求序列中次小值的函数。文献[12]中对求解一个序列的最小值和次小值的问题进行了详尽论述,并给出了一种称为树形结构(Tree structure, TS)的高效实现结构,如图8所示。
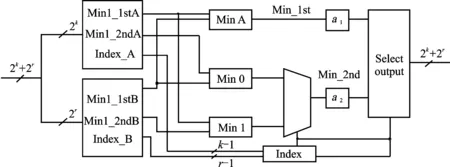
图8 校验节点更新单元的实现结构Fig.8 Implementation structure of check node renew unit
3.3 P消息循环存储器

图9 P消息循环存储器结构图Fig.9 P message cycle memory structure
该模块是译码器中的核心模块。该循环存储器将每个变量节点对应的P消息存于其中。根据校验矩阵的结构分为Nb块,每块的深度为z。译码时先将所有的初始化消息写入存储器中,由于准循环码的每个非零矩阵都是单位置换阵,因此每个存储器都是循环存储结构。每次子迭代选择该层中非零子矩阵所对应的存储块,从这些存储块中按照该子矩阵的偏移量确定起始位置,并以并行度p从每个存储块中一次同时读出p个消息,读出的消息经过分层消息处理单元进行更新后以并行度p写回到循环缓冲区中的原来存储位置。这个循环存储器关键就是要实现从任意一个起始地址开始一次同时读出或者写入p个消息,其结构如图9所示。
文献[13]采用了图10所示结构来实现同样的功能。这种结构依靠Benes网络来实现数据交织,即实现从任意起始位置同时读出p个消息,而存储消息则是采用寄存器存储。采用这种结构在码长较短时还是比较高效的,但是随着码长的增加其资源消耗会越来越大。采用RAM存储消息,虽然由于实现结构的问题,不适合使用大容量的块状随机存储器(Block RAM , BRAM),但是如果使用分布式RAM实现存储器,相比采用触发器会大大节省资源消耗。Benes网络的实现复杂度也相当高,即使像文献[13]中那样对Benes网络进行了简化,当规模较大时其资源消耗依然很可观。因此本文提出的这种结构更加高效,更适合于FPGA实现,且在码长增加时,所消耗的资源基本与码长呈线性关系。
3.4 R消息循环存储器
由于R消息更新时只对非零矩阵进行,对于每个层来说,全零矩阵对应的R消息永远是零,因此在存储时,每一层只需要存储非零子矩阵对应的R消息即可。R消息存储器的具体结构如图11所示。考虑到译码器实现的并行度p,要求R消息存储器每次能够同时并行输出p个消息,当R消息更新计算完成后也能够同时并行输入p个消息,因此可以将存储器的位宽设置为wp位,其中w表示R消息的量化精度。

图10 基于Benes网络的P消息存储器 图11 R消息存储器结构
Fig.10 P message memory based on Benes network Fig.11 R message memory structure
3.5 校验模块
常规的校验方法是将判决结果代入校验矩阵中计算校验值。文献[13]提出了一种更为实用的方法,即对比本次迭代的译码结果和上次迭代的译码结果,如果发现两次相同则认为译码已经完成,否则继续迭代直到达到最大迭代次数。这种方法是基于译码算法的收敛性,即当译码正确后再次进行迭代,其结果也应该是正确的,这样电路实现的复杂性就降低了。
3.6 译码流程控制
译码整个流程可以用图12所示有限状态机进行控制,说明如下:
(1) 消息初始化
译码器一开始处在空闲状态,当检测到有效数据到来时进入初始化变量节点的状态,译码器需要等待所有节点初始化完成后才可以开始译码。
(2) 分层消息处理
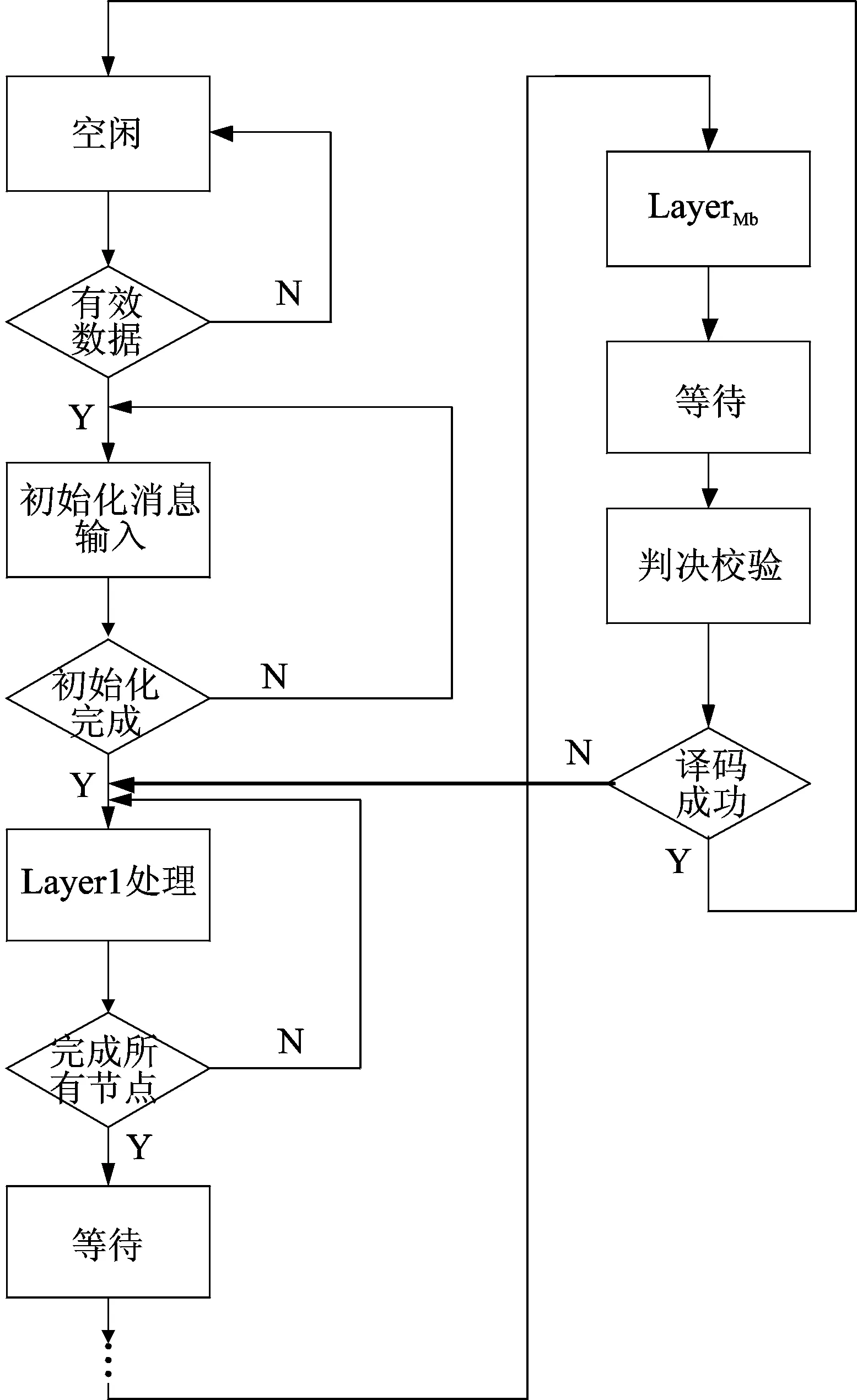
图12 译码器的有限状态机Fig.12 Finite state machines for decoder


图13 子迭代过程的流水线结构Fig.13 Pipeline structure of sub-iterative process
如果只考虑主要迭代过程所消耗的时钟个数,则可以大概估计出译码器的吞吐率为
Rateth=k/(z/p)Mbfclk
(10)
式中k表示码字中信息位的长度,fclk表示FPGA工作时钟频率。
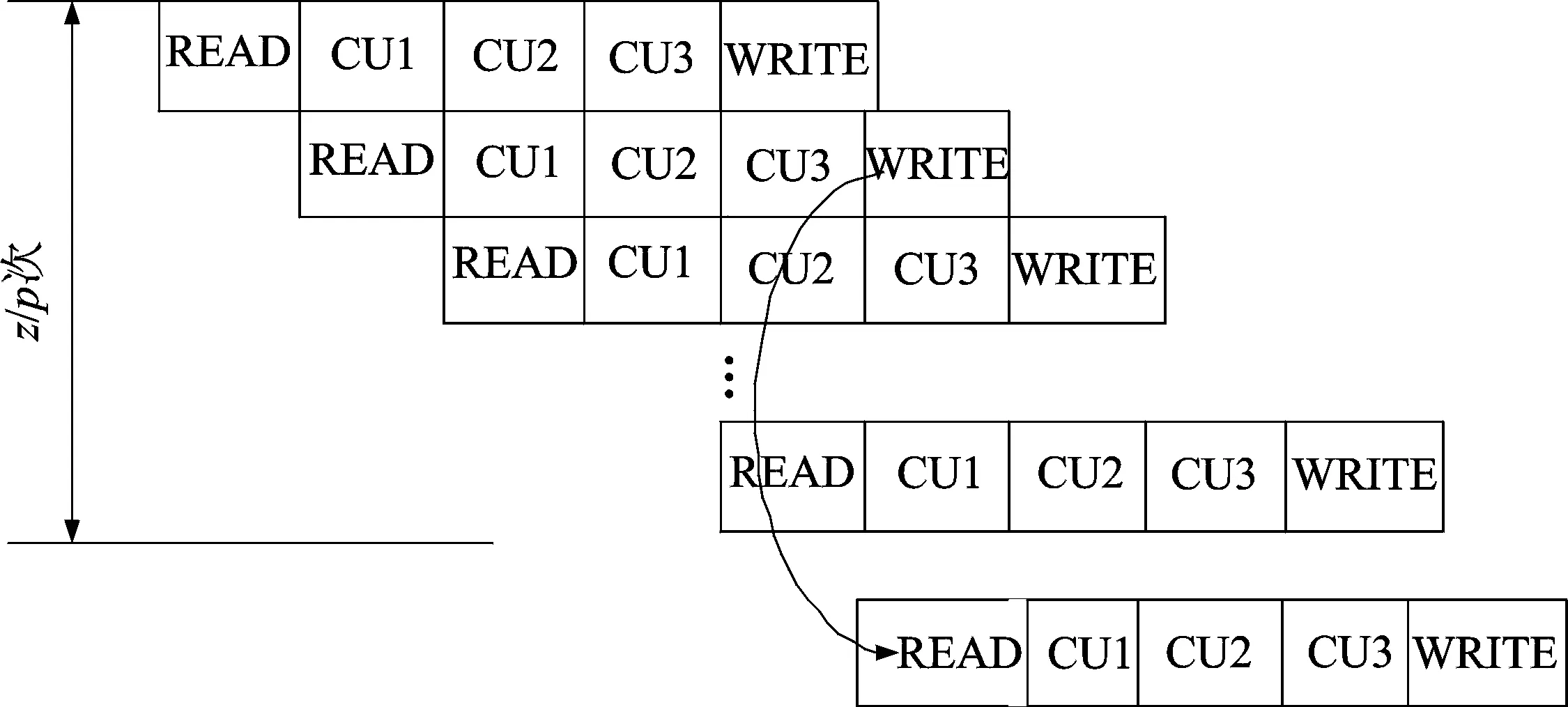
图14 读写旁路时序图Fig.14 Read and write bypass timing diagram
3.7 FPGA实现结果与比较
根据设计思路,在Xilinx公司的XC6VLX130T FPGA平台上对各个主要模块进行了实现,资源消耗见表1,基保FF表示触发器,Slice为FPGA的一种组成单元,LUT表示查找表。

表1 各主要模块资源消耗
图15是分层消息处理单元在FPGA平台上利用Chipscope软件抓取的输入输出数据的实际数。利用分布式RAM和读写控制逻辑在FPGA上实现了P消息循环存储器,存储容量为64 Byte。可以实现在循环存储器中任意起始位置开始同时读写连续8个消息。其中每个消息位宽为7 bit。单个P消息循环存储器在FPGA平台上。
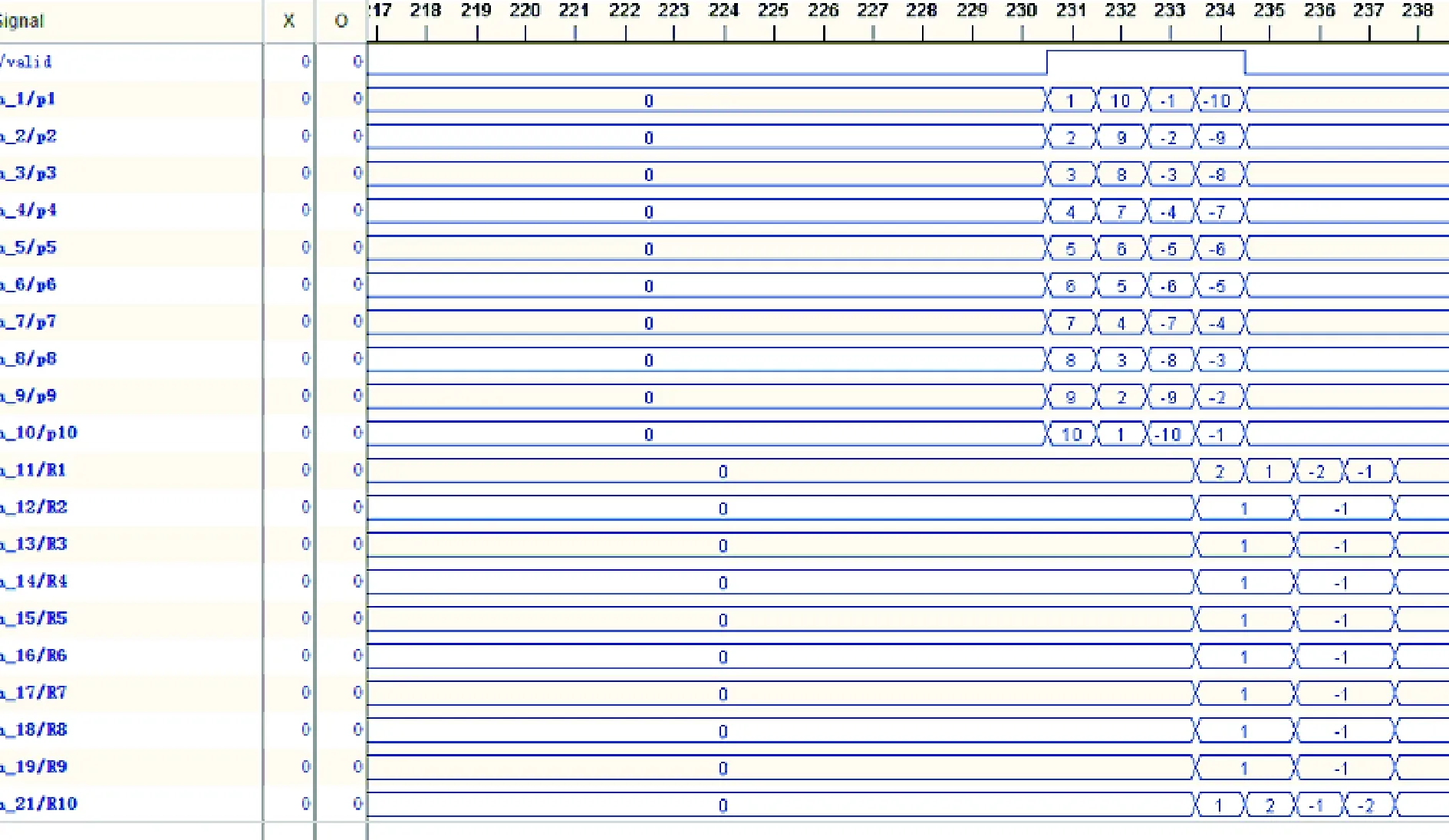
图15 分层消息处理单元在FPGA实现平台上验证波形Fig.15 Verify waveform on FPGA platform of layer message processing unit

图16 P消息循环存储器在FPGA平台上的验证波形Fig.16 Verify waveform on FPGA platform of P message cycle memory
实现的资源消耗见表1。图16是P消息循环存储器在FPGA平台上利用Chipscope软件抓取的实际数据流。由于并行度p=8,消息位宽为7 bit,因此每次需要同时写入或读出分层消息处理模块的R消息位宽为56 bit。分层消息处理模R消息需要每层都要保存,RAM的深度为z/p×Mb,考虑到整个译码器实现中其他部分并未用到BRAM,因此这样采用BRAM实现R存储器可以节省其他资源的消耗。表2是整个译码器的总资源消耗,以及参考文献中译码器的资源消耗。选择几个FPGA实现的译码器,校验矩阵都是WiMAX协议定义的类型。比较结果表明,本文中实现的译码器消耗的触发器资源明显更少,而吞吐率在参考文献中的几个译码器中较高。综合后最大工作时钟可以达到98.7 MHz,根据计算在这个时钟速率下对2/3码率可以达到157 Mbps的吞吐率,对3/4码率译码可以达到236 Mbps的吞吐率;与文献[13,14]相比具有较明显优势;与文献[15]相比,由于该译码器适应Wimax的所有码率,如果与同码率情况相比本文的译码器在吞吐率上也具有一定优势。将设计的硬件译码器下载到FPGA平台上进行测试,将编码后的信号经过加噪量化后逐帧送入译码器进行译码,并测试其误比特率性能,其实测性能曲线如图17所示。结果表明LDPC硬件译码器的性能与浮点数值仿真的结果相差不大,在中低信噪比下译码性能只比浮点仿真时差0.1 dB左右。该译码器应用于某实际数字通信系统中,性能表现良好,与未编码的情况进行比较,其编码增益在误码率为10-5时大于6 dB。

表2 译码器总资源消耗比较

图17 实测FPGA误比特率与浮点仿真误比特率比较Fig.17 Comparison of bit error rate between floating-point simulation and FPGA decoder
4 结束语
本文首先采用离散密度进化原理对译码器设计过程中的算法选择及实现参数进行了优化,相比直接采用数值仿真进行优化的方法,极大地提高了效率,且经过优化的译码器与纯浮点仿真相比译码性能仅仅相差0.1 dB,由于采用了经过优化的实现参数,使译码器在进行硬件实现时有更高的实现效率。在具体实现中,本文提出了一种基于分布式RAM和读写控制的循环P消息存储器,相比传统的采用Benes网络和寄存器的实现结构大大减小了 逻辑资源的消耗,由于采用Xilinx公司的FPGA特有的分布式RAM使得RAM的使用效率大大提高。针对流水线结构进行了优化,解决了流水线冲突问题,并通过读写旁路技术进一步缩短了迭代时间,降低了功耗。最终达到了157 MHz的较高吞吐率及较好的译码性能。测试性能表明与几种典型的同类型译码器相比,本文提出的硬件译码器结构和实现方案在消耗较少硬件资源的前提下可以获得更高的吞吐率和更接近浮点仿真的性能,较好地解决了译码器硬件实现过程中在性能资源和吞吐率之间的矛盾,是一种高效的LDPC码硬件译码器。
