基于KL散度的驾驶员驾驶习性非监督聚类∗
2018-12-12蒋渊德邓伟文
朱 冰,蒋渊德,邓伟文,杨 顺,何 睿,苏 琛
(吉林大学,汽车仿真与控制国家重点实验室,长春 130025)
前言
深入理解和准确辨识驾驶员驾驶习性是设计先进驾驶员辅助系统(advanced driver assistance system,ADAS)和人性化无人驾驶车辆的前提和基础。但驾驶员驾驶习性纷繁复杂且动态变化,不同年龄、不同性别、不同性格、不同驾龄和不同驾驶熟练程度等都会对驾驶习性产生显著影响[1]。因此,驾驶员驾驶习性研究已经引起越来越多的关注和重视。
在个性化ADAS设计方面,当前的研究主要包括在线学习控制算法和离线系统设计两类。清华大学张磊将驾驶员纵向加速度决策建模为跟车时距(time headway,THW)和碰撞时间倒数(inverse of the time to collision,TTCi)的线性函数,通过模型参数对驾驶员纵向驾驶习性进行表达,进而实现了基于最小二乘法的在线学习纵向控制算法[2]。文献[3]中认为车辆纵向加速度决策是车间距、相对车速和主车速度等特征变量的线性函数,能够在一定程度上反映驾驶员的纵向驾驶过程。然而,在线学习策略受工况选择和传感器测量噪声影响很大。离线系统设计方案在离线状态下针对不同驾驶习性进行控制策略设计,具有较高可靠性[4]。而如何理解驾驶员驾驶习性是这两类方法的基础性问题,是个性化驾驶系统的设计前提。针对这一问题,文献[5]中以设计考虑不同驾驶习性的个性化自适应巡航系统(adaptive cruise control,ACC)为研究内容,对驾驶员纵向驾驶行为进行了研究。南加州大学的学者将驾驶员换道所需时间视为驾驶习性的表征参数,利用高斯混合模型(Gaussian mixture model,GMM)对其进行估计,设计了个性化换道模型[6]。文献[7]中将驾驶员类型辨识视作一个分类问题,利用支持向量机将驾驶员分为激进型和温和型。吉林大学的研究人员通过GMM对驾驶员驾驶习性类别进行了辨识[8]。此外,神经网络模型和学习型模型预测控制等方法在个性化ADAS设计中也得到了广泛应用[9-10]。
在这些相关研究中,如何准确表征不同驾驶员驾驶习性之间的差异是首先需要解决的基础问题。文献[11]中利用冲击度分析,将驾驶员分为不同的类型。文献[12]和文献[13]分别基于驾驶数据和统计数字特征对不同类型的驾驶员进行了聚类。然而,人类驾驶员作为一个复杂的强随机性个体,单一数字特征指标难以准确地表征不同的驾驶习性,也无法从驾驶数据的整体分布情况来考虑不同驾驶员之间的相似性。
为深入研究驾驶员驾驶习性的特征规律和差异性表征方法,本文中构建了驾驶员实车道路试验采集系统,采集了84名驾驶员在典型纵向跟车工况下的驾驶数据;将每名驾驶员的驾驶数据视为一个高维连续空间下的GMM,以不同分布之间的KL散度(Kullback-Leibler divergence,又名相对熵)作为驾驶员差异性的衡量标准;为解决两个GMM之间KL散度没有解析解的问题,引入蒙特卡洛算法进行近似求解;从而创新性地实现了基于KL散度的驾驶员驾驶习性非监督聚类。
1 驾驶员驾驶数据采集
1.1 驾驶员驾驶数据采集平台
为采集驾驶员在实际驾驶状态下的驾驶数据,建立了驾驶员驾驶数据实车道路试验采集平台,如图1所示。

图1 驾驶员驾驶数据采集平台
数据采集平台包括一辆主车和一辆交通车。主车和交通车上各安装有一套Oxford Technical Solutions公司的RT3002和RT-Range惯导系统,该系统通过固定参考站GPS Base Station和车辆移动站进行差分定位,能精确地确定车辆位置。另外,惯导系统还能够精确测量车速、航向角和加速度等车辆状态信息。两个RT-Range之间通过无线局域网通信,主车能够实时接收交通车状态信息,对两车间的相对距离、相对车速等相对状态信息进行采集。试验过程中,前方交通车由一个技术熟练的驾驶员驾驶,被测驾驶员驾驶主车跟随前车行驶,通过CANoe从主车CAN总线实时采集被测驾驶员的操控信息,包括加速踏板行程、主缸压力和转向盘转角等。由于各采集信号均可通过CAN网络输出,所以各信号之间容易保持时间同步。
1.2 被测驾驶员
为充分考虑被测驾驶员的随机性,面向社会广泛招募了84名不同职业、年龄和驾龄分布的驾驶员,如表1所示。其中,既包括普通非职业驾驶员,也包括若干职业驾驶员(如出租车驾驶员、代驾驾驶员和职业赛车手等)。样本中共有61名男性驾驶员和23名女性驾驶员,平均驾龄为5.71年(标准差SD为5.16)。
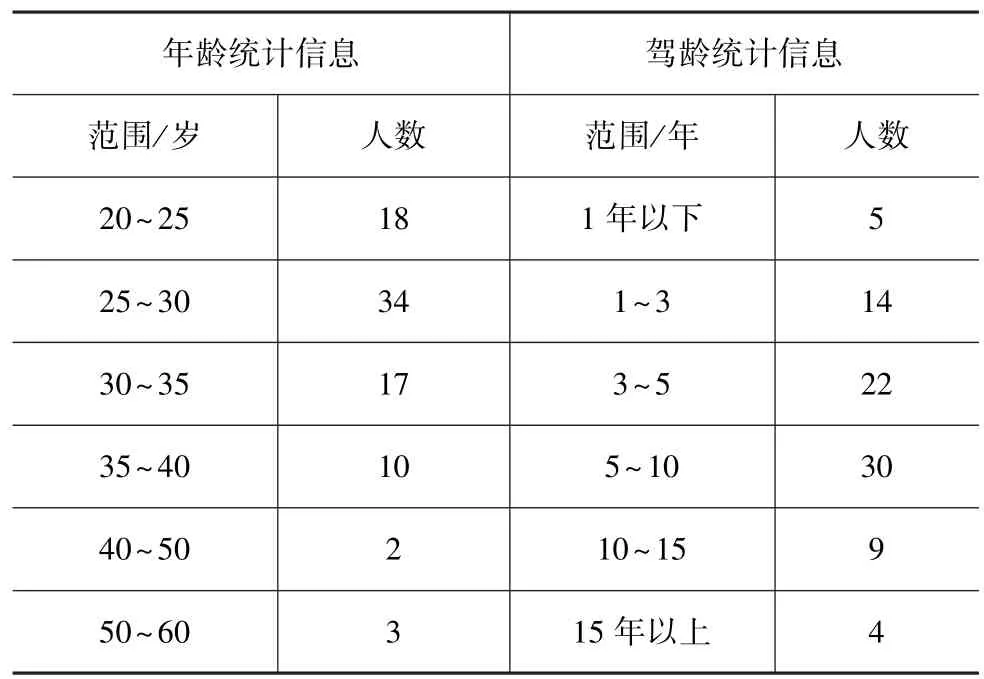
表1 驾驶员统计信息
1.3 驾驶员驾驶数据采集试验设计
选取长春国际汽车公园附近的丙十二路(图2(a)),对84名驾驶员在真实驾驶场景下的驾驶数据进行了采集。

图2 试验场地和工况
为对驾驶员纵向驾驶习性进行测试,设计了纵向跟车行驶试验工况,前方交通车按照0-20km/h-50km/h-70km/h-50km/h-20km/h-0的速度行驶,期间包括加速、减速和匀速等不同的行驶状况,加/减速时间为2s左右,以利用较大加/减速情况激励主车驾驶员驾驶习性,图2(b)为部分试验中的实际前车行驶速度曲线。
2 基于GMM的驾驶数据统计建模
为表征纵向驾驶过程,选择特征变量集合f=(s,Δv,vh,ah,vp,ap)对跟车过程进行描述。 其中,s为两车之间的相对距离,Δv为相对车速,vh和vp分别为主车和前方交通车速度,ah和ap分别为主车和前方交通车加速度。
在传统的驾驶习性聚类算法中,通常以各样本点或其数字特征作为聚类对象,将样本之间的几何距离作为驾驶员之间的相似性表征。然而,驾驶员在实际驾驶过程中存在着很强的随机性,从统计角度看,每个驾驶员的驾驶数据有独特的统计分布,难以用单一数字特征参数对其进行表征。以纵向驾驶为例,保守型驾驶员可能在车间距较大时就以较小的减速度减速接近前车,而激进型驾驶员可能在相距较近时才开始减速,两种情况下的统计样本均值差别不大,而各自的分布情况差异明显。针对这一问题,本文中将每个驾驶员的驾驶数据视作一个独特的高维空间下的连续分布。
GMM能够对任意分布规律的概率密度函数进行拟合,在图像和语音等领域得到了广泛应用。因此,引入GMM对驾驶数据的统计分布进行表达。
在d维特征空间中,每个基本高斯概率密度函数为
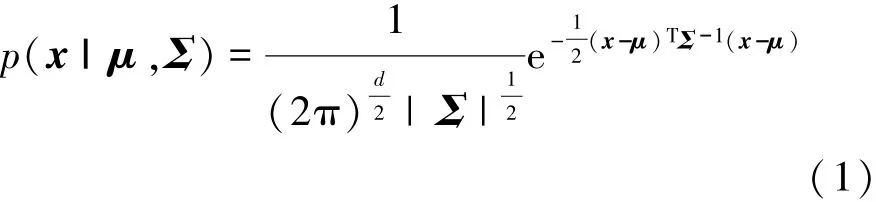
式中:μ为均值向量;Σ为协方差矩阵。
GMM将观测到的数据视为若干基本高斯概率密度函数的线性组合:

式中:k为基本高斯概率密度函数的个数;αi为第i个高斯成分的混合系数
利用采集得到的驾驶数据对GMM进行训练,即对式(2)参数进行估计,可得到不同驾驶员驾驶数据的分布规律。本文中采用最大期望迭代法(expectation-maximization,EM)对GMM参数进行估算。记数据集为 D={x1,x2,…,xN},假定这些数据点是独立地从概率分布中采样而得,根据GMM的模型函数可得对数似然函数如下:

EM算法的目标是均值、协方差和混合系数等参数的最大化似然函数。对参数进行初始化后,算法主要包括E步骤和M步骤。
E步骤,根据当前参数计算后验概率,即驾驶数据xn由第i个高斯分布产生的概率为
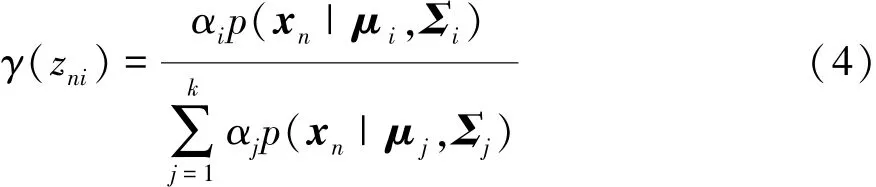
M步骤,利用当前的后验概率对参数进行重新评估:

本文中选择k=3。以Driver02的GMM建模为例,其参数估计结果如表2所示。
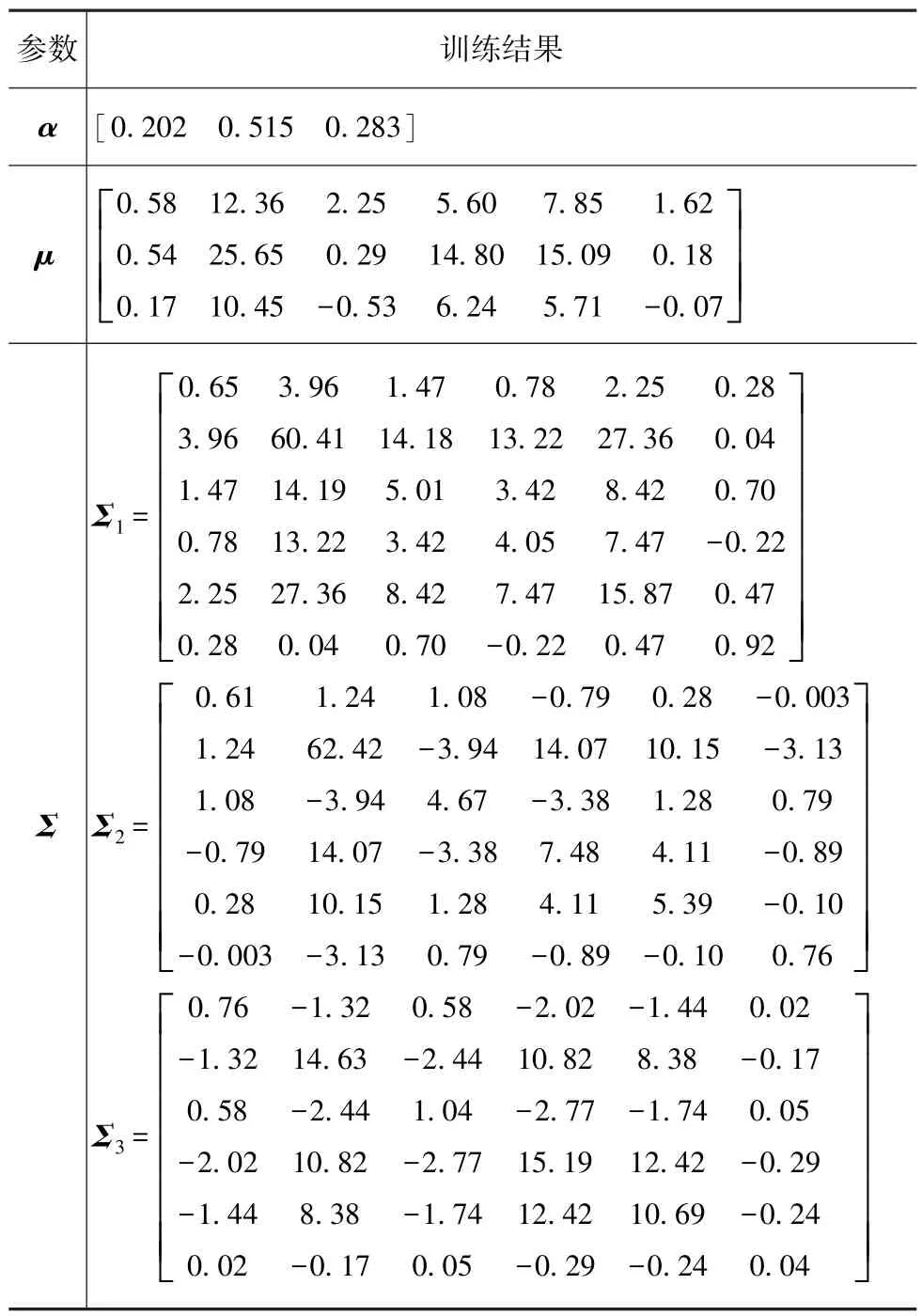
表2 GMM参数估计示例
3 基于KL散度的驾驶习性聚类算法
聚类的主要任务就是将相似的数据对象聚为一类,因此如何度量数据对象之间的相似性是聚类分析中的核心问题,决定了聚类效果。传统的样本相似性度量方式包括欧氏距离、余弦相似性及Jaccard等,这些方法能对各样本点之间的距离进行衡量[14]。然而,这些传统的距离度量方式难以对上述不同驾驶员GMM分布之间的相似性进行表达。
KL散度可作为两随机变量之间的距离表征,能有效描述不同分布之间的相似性,在信息论中得到了广泛应用[15]。因此,本文中采用KL散度作为各驾驶员GMM之间的相似性度量,以实现对驾驶员进行聚类。
3.1 KL散度
设原始随机变量为X,信息瓶颈理论(information bottleneck,IB)通过引入附加变量Y来间接地确定X的距离度量,通常Y所描述的是与X相关的特征空间。IB算法的目标为寻找X的聚类表示X^,使X^含有的信息量尽可能少,同时使Y包含的信息量最大化。其目标是使所有特征分布与其所在类别的均值分布之间的KL散度之和最小。KL散度是两个概率分布之间差异性的一种度量,分布f对g的KL散度定义为
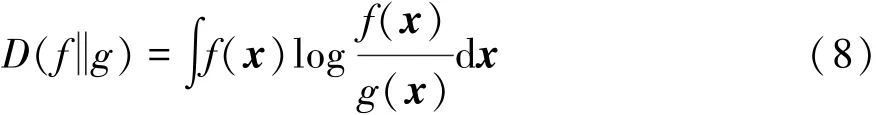
假定当前时刻得到某一类别驾驶数据的GMM分布为

待聚类驾驶员通过以下GMM进行描述:
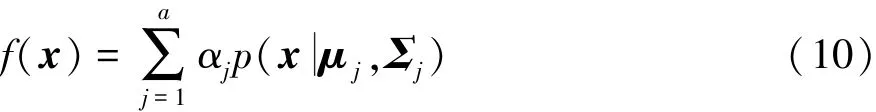
式中b和a分别表示分布g(x)和f(x)的基本高斯概率密度函数的个数。则该驾驶员与该类别统计分布之间的相似性通过KL散度进行衡量为

式(11)没有解析解,为此引入蒙特卡洛方法对上述两个连续GMM分布之间的KL散度进行近似。蒙特卡洛方法以采样的方式从概率分布f中进行采样,每次以概率分布α随机选择其对应的某一基本高斯分布,然后通过采样获得样本点xi,组成样本点集{xi}。据此,可以将KL散度的计算问题转化为求取期望:

3.2 基于KL散度的非监督聚类
参考k-means聚类框架,得到基于KL散度的非监督聚类算法伪代码如表3所示,其中分布gk代表相应类别k在特征空间上的统计分布。该算法以最小化驾驶员特征分布与其所在类的统计分布之间的KL散度之和为目标进行聚类。

表3 基于KL散度的非监督聚类算法
4 聚类结果
通过各GMM之间的KL散度能够定量地表达驾驶员之间的差异性,如图3所示。
图中任一方格表示两驾驶员之间的KL散度大小,如图3(a)中(i,j)表示驾驶员i与驾驶员j之间的KL散度D(fifj)。在此选取10名驾驶员样本为例,任意两驾驶员之间的KL散度分布如图3(b)所示。据此,能够实现不同驾驶员之间差异性的定量比较,为驾驶员习性聚类奠定基础。
通过上述非监督聚类方法,可将驾驶员驾驶习性聚类为3种类型。图4为各类典型驾驶数据在相对距离-相对车速-主车加速度三维空间下的分布情况,为便于直观理解不同类型驾驶数据的分布,对主车加速度与相对距离之间的关系作图,如图5所示。按照每类驾驶员在跟车过程中的相对距离和相对车速不同,可将3类驾驶员分别定义为激进型、一般型和保守型。可以看出,保守型驾驶员在跟车过程中趋向于保持较大的相对车距,车辆加速度绝对值相对较小;而激进型驾驶员的跟车间距较小,且加速度绝对值较大;一般型驾驶员的跟车行驶数据介于二者之间。
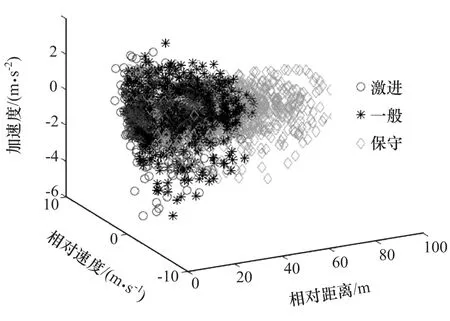
图4 聚类后的相对车速-相对距离-加速度分布图

图5 聚类后的相对距离-加速度散点图
图6 为每种驾驶习性下的相对车速-相对距离百分比分布统计。由图6可知:激进型驾驶员的行驶车速相对较大,绝大部分情况下相对车速为负值;保守型驾驶员的行驶车速相对较小;一般型驾驶员介于二者之间。
3类驾驶员跟车过程中跟车距离与车速关系如图7所示。图中散点表示真实跟车数据,可以看出车间距随着车速的升高而增加。利用最小二乘法可得到3类驾驶员的2阶车间距模型和固定时距车间距模型,分别如图中的实线和虚线所示。如图可见,3类驾驶员中,保守型驾驶员的跟车距离最远,激进型跟车距离最近。固定时距车间距模型与2阶车间距模型的结果非常接近,而模型参数更少,有利于后续进行ACC算法设计。

图6 每种驾驶习性下的相对车速-距离统计分布
图8 为各类驾驶员的跟车时距(定义为THW=s/vh)和主车加速度统计结果。图中显示了3类驾驶员跟车时距和加速度的第5百分位数、均值和第90百分位数。可以看出,从激进型到保守型,3类驾驶员的跟车时距呈上升趋势,平均跟车时距分别为1.6,2.0和3.1s。而在加速度统计方面,3类驾驶员的均值加速度都在0附近。但是激进型驾驶员的最大减速度较大,而保守型驾驶员更趋于将车辆加速度控制在较小范围内。

图7 跟车距离-车速关系图
5 结论
提出了一种基于KL散度的驾驶员驾驶习性非监督聚类算法。将每个驾驶员的实际驾驶数据视为一个高维连续高斯混合分布,并利用EM算法对其参数进行估计;以每个驾驶员统计分布模型与典型类别分布之间的KL散度作为其相似性的度量,据此对驾驶员进行聚类。

图8 各类驾驶员跟车时距和加速度统计
采集了84名随机驾驶员的驾驶数据,基于对聚类后各类别驾驶员驾驶数据的统计分析,将驾驶员分为激进型、一般型和保守型3种类别,得到了各类驾驶员跟车距离和行驶车速的统计特点。
本文中提出的非监督聚类方法优势在于:以GMM表达驾驶员的真实驾驶数据统计分布,基于不同分布之间的相似性实现聚类,而非以数据的单一数字特征作为聚类样本,能够对驾驶数据分布进行总体考虑。
