增量式关联规则挖掘算法的研究
2018-11-28亓文娟
亓文娟
(1.武夷学院数学与计算机学院;2.认知计算与智能信息处理福建省高校重点实验室,福建 武夷山 354300)
0 引言
关联规则挖掘(Association Rule Mining)是数据挖掘中的重要研究内容,用于发现数据库中项集之间的关联关系。关联规则中的经典算法Apriori算法以最小支持度、最小置信度和数据库中元组数都不变为前提,注重于静态数据的挖掘,但实际情况下,数据挖掘却是一个动态的交互过程,需要不断调整最小支持度、置信度两个阈值或者数据库中的数据不断地发生更新,这时候需要寻找真正感兴趣的规则,就必须重新进行挖掘,如果继续采用Apriori算法,不仅效率非常低,还浪费了以前挖掘出来的信息。因此为了能快速更新关联规则,降低重新扫描数据库的代价,在此实际需求的驱动下,注重于动态数据挖掘的增量式关联规则挖掘成为关联规则挖掘的一个重要研究方向。
1 增量式关联规则
增量式关联规则挖掘的主要思想是在更新的数据库或参数上,充分利用原有挖掘规则,发现满足条件的新规则,删除失效的旧规则,目的是尽量减少计算量。增量式关联规则挖掘算法主要解决以下三类问题:①即在原始数据库D不变,最小支持度和置信度发生变化时,如何生成D中新的关联规则;②在最小支持度和置信度不变,数据库发生更新时,如何生成新数据库D∪d或D-d的关联规则;③在原始数据库发生更新的同时,最小支持度和置信度同时发生变化时,如何生成新数据库在新支持度下的关联规则。冯玉才等人提出了IUA算法和PIUA算法[1]针对第一类问题进行了研究,针对第二类问题,D.W.Cheung等人对新数据库D∪d的情况提出FUP算法[2]和 FUP2算法[3],其中FUP2算法同时考虑了新数据库D∪d和D-d的情况。徐文拴等[4]针对第三类情况中数据集增加和最小支持度同时变化的关联规则更新问题进行了研究。本文重点研究关联规则增量式更新算法FUP算法的思想,算法的优缺点及改进,为增量式关联规则挖掘奠定理论基础。
1.1 FUP算法的基本思想
当数据库中的数据发生变化时,为了获取更新后的关联规则,最简单的办法是重新运用Apriori算法对数据库进行挖掘,但是这样做不仅效率较低,而且没有充分利用以前挖掘的结果,在众多的增量式关联规则挖掘算法中,D.W.Cheung等提出的FUP算法最为典型,它是Apriori算法的改进算法,与Apriori算法的框架一致[5],主要解决在支持度和置信度不变,数据集增加的情况下,如何生成新的频繁项集的算法。
设原始数据集为D,新增数据集为d,则变化后的数据集为(D+d),假设已经采用Apriori算法获得原始数据集D的频繁项集L(D),则FUP算法的基本思想是:
1)利用Apriori算法生成新增数据集d的频繁项集L(D),比较L(D)和L(D),根据某一项集t在D中为频繁项集,在d中也为频繁项集,那么该项目集在(D+d)中也为频繁项集的理论,找出相同部分,将其放入(D+d)的频繁项集L(D+d)中。
2)对于项集t∈L(d)且t∉L(D)的情况,扫描D得到t在D中的支持度supportD,再根据d中以求出的支持度supportd,求出t在(D+d)中的支持度supportD+d,如果supportD+d≥minsup,则把t放入(D+d)的频繁项集L(D+d)中,否则t不是频繁项集。

3)对于项集t∈L(D)且t∉L(d)的情况,扫描d得到t在d中的支持度supportd,再根据D中以求出的支持度supportD,求出t在(D+d)中的支持度supportD+d,如果supportD+d≥minsup,则把t放入(D+d)的频繁项集L(D+d)中,否则t不是频繁项集。
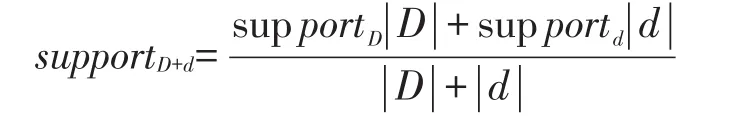
4)如果某一项集t在D中为非频繁项集,在d中也为非频繁项集,那么该项目集在(D+d)中也一定为非频繁项集。
1.2 FUP算法的描述
FUP算法执行如下:

1.3 FUP算法实例分析
已知原始数据集D,新增数据集d,设最小支持度为0.4,图1是FUP算法寻找频繁项集的过程。

图1 FUP算法寻找频繁项集过程
在图1(1)中L(D)表示从原始数据集D中获得的频繁项集;(2)中利用Apriori算法生成新增数据集d的频繁项集L(d);(3)中比较L(D)和L(d),找出相同的频繁项集{C、D}放入到事务数据库(L+d)的频繁项集L(D+d)中;(4)中对于属于D中频繁项集,但非d中频繁项集{A、A,D}的情况,则扫描d得到项集在d中的支持度分别为supportd={2/6,2/6},再根据项集在D中的支持度supportD={5/10,5/10},求出它在(L+d)中的支持度supportD+d={7/16,7/16},由于supportD+d大于最小支持度0.4,则把项集{A、A,D}也放入事务数据库(L+d)的频繁项集L(D+d)中;(5)中对于属于d中频繁项集,但非D中频繁项集{E、D,E}的情况,与(4)类似,重新扫描D,确定是否是频繁项集,由于项集{E、D,E}在(L+d)中的支持度supportD+d={4/16,3/16}均小于最小支持度,因此是非频繁项集。(6)为新数据集的频繁项集。
1.4 FUP算法的优缺点
FUP算法在新增数据集d与原始数据集D相差不大的情况下,较Apriori算法在效率方面有了很多的提升,主要体现在Apriori算法需要多次扫描数据库,而FUP算法只有在确定项集t∈L(d)且t∉L(D)的情况下,才需要扫描原始数据集;通过对K项集在原始数据集和新增数据集中是否频繁的分析,可以过滤掉许多候选项集。FUP算法虽然对原始数据集挖掘结果进行了使用,但是对于一些大数据集而言,该算法也存在着不足:由于候选项集的生成由Apriori连接来获得,即使用L'k-1生成Ck,产生新增数据集的候选项集规模是巨大的,在处理这些候选项集时耗费大量时间,而且其中有很多是非频繁项集,影响了算法的效率;对候选项集进行模式匹配时需要对整个数据库进行多次重复扫描,代价很大;算法对新增项目不敏感。
2 算法的改进
针对FUP算法只考虑了支持度和置信度不变,数据集增加的情况,以及该算法存在的不足,众多学者对该算法进行了改进。文献[4]针对数据库和最小支持度同时发生变化的情况,提出了哈希增量更新算法HIUA,该算法结合hash定位以及链表插入、删除的高效性,不生成候选项集,只扫描原始数据集一次,充分利用了原有的挖掘信息,算法效率较高。文献[6]提出了基于临时表的改进算法MFUP,该算法适用于原始数据库规模大,新增数据集相对小的情况,通过建立临时表,来存放新增数据集的频繁项集,充分利用原始数据集挖掘的结果,大大减少了对数据的重复扫描,提高了算法的效率。文献[7]提出了IFU算法,用于解决数据库和最小支持度都发生改变时关联规则的增量式更新问题,该算法减少了对原始数据集和新增数据集的扫描次数,提高了算法的效率,但由于该算法使用了一次IUA算法,所以如何减少对原始数据集D的扫描次数有待进一步研究。文献[8]提出了一种基于矩阵的增量式关联规则挖掘算法IUBM,充分利用原始数据集挖掘的结果,采用数组和位运算,不管支持度如何变化,仅扫描一次新增数据集,不需要扫描原始数据集,同时在挖掘的过程中加入了剪枝算法,减少了大量不必要的比较和计算,该算法的时间复杂度和空间复杂度大大降低。
3 总结
增量式关联规则挖掘算法大致分为基于Apriori算法的增量更新算法和基于FP-tree的增量更新算法两类。本文对基于Apriori算法的增量式关联规则算法FUP算法的基本思想,优缺点进行了探讨,并通过具体实例说明发现频繁项集的方法,最后针对算法不足指出了改进算法,为增量式关联规则挖掘奠定理论基础。下一步工作的重点是根据数据库中不同数据项的重要性不同问题,结合增量式关联规则更新和多支持度的局限性,提出基于多支持度的增量式关联规则挖掘算法。
