基于模型组合法的我国能源消费需求趋势预测
2018-11-22王翀
王 翀
(1.中国矿业大学管理学院,江苏 徐州221000;2.淮北师范大学 数学科学学院,安徽 淮北 235000)
0 引言
我国是能源消费大国,随着工业化和城市化不断推进,能源消费需求也不断提高。而与日俱增的能源消费需求,不仅影响我国能源自身安全,而且会对全球能源生产与供给产生一定影响。因此,走绿色低碳的可持续发展道路,不断减少对能源的依赖,是未来经济社会发展所必须遵循的规律。对未来能源消费需求趋势进行把握,对我国能源战略的制定实施以及保障经济社会持续发展都具有重要意义。
本文尝试采用三种单一预测方法得到的预测精度存在较大差异,从侧面验证了组合预测的必要性;在采用协整分析预测时,根据我国经济情况分别设定了三个GDP增速进行预测,使预测结果更加精确;通过一定模型方法对三种单一预测模型赋予权重,使最终预测结果充分体现单一预测结果包含的信息。
1 样本数据说明
根据本文的研究需要,共涉及到两个变量,分别为能源消费总量和地区生产总值,两个指标分别记为EC和GDP。考虑到数据获得性,本文选取的时间序列跨度为2000—2016年,数据来源于历年的《中国统计年鉴》。
根据表1的数据样本,可得到我国能源消费需求的现状变化趋势。
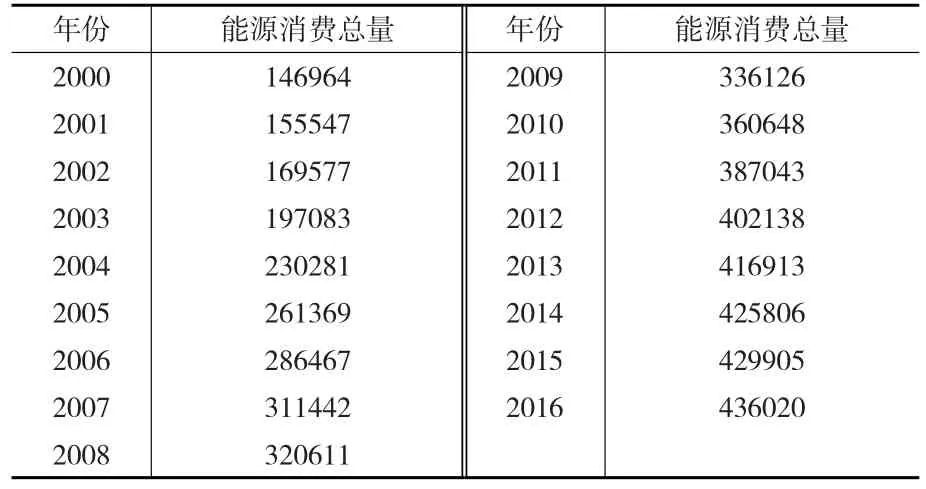
表1 2000—2016年我国能源消费量一览表 (万吨标准煤)
2 三种传统预测方法对我国能源消费需求预测
主要采用协整分析、灰色关联分析、指数平滑法三种方法,分别对我国能源消费需求趋势进行初步预测。
2.1 基于协整分析的我国能源消费需求预测
为了通过协整分析方法对我国能源消费需求趋势进行预测,选择能源消费总量和地区生产总值两个指标,通过构建协整方程模型进行计量分析。首先需要对能源消费总量和地区生产总值两个指标序列进行平稳性检验。为了增强序列平稳性,对能源消费总量和地区生产总值均做对数处理,处理后的指标分别记为LnEC和LnGDP。根据单位根检验法,得到两个指标的平稳性检验结果,如表2所示。
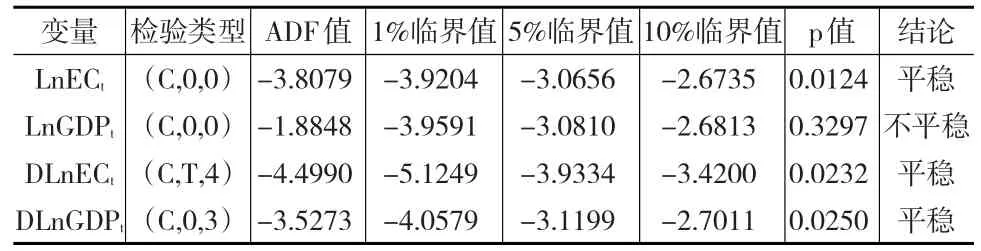
表2 LnEC和LnGDP的单位根检验结果
由表2可以看出,LnEC和LnGDP两个变量均在一阶差分后通过ADF显著性检验,即满足一阶单整。根据平稳性检验结果,LnEC和LnGDP满足了协整分析的前置条件。构建LnEC和LnGDP之间的协整关系计量模型如下:

其中,α和β均为待估计参数,εt为模型的随机误差项,下标t为年份。
采用Eviews软件,采用线性回归方法对式(1)进行估计,结果如下:
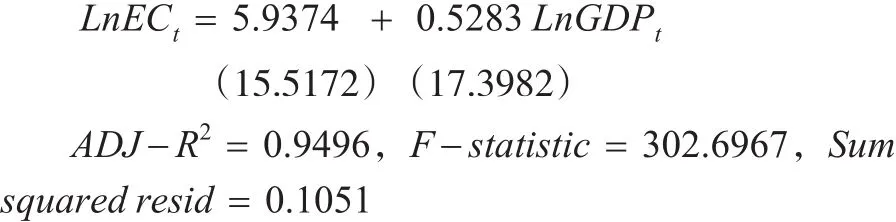
对得到的残差序列采用单位根检验,结果如表3所示。

表3 残差项的单位根检验结果
根据协整分析得到的模型回归结果,拟合得到2001—2016年历年的能源消费量的估计值,结果如表4所示。
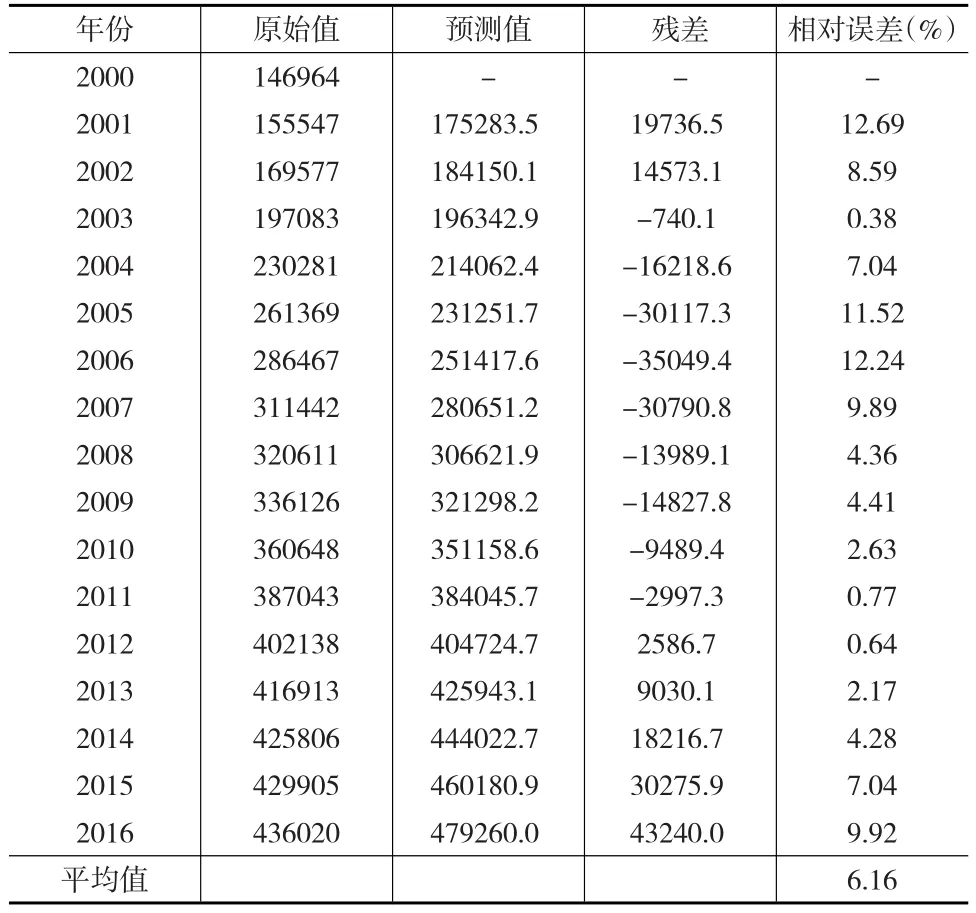
表4 基于协整分析的能源消费需求预测结果(万吨标准煤)
我国“十三五”规划中对地区生产总值提出了6.5%的增速,而且国家提出了6.5%应作为经济增长的底线。2016年,我国地区生产总值的同比增速为6.7%,2017年上半年同比增速达到6.9%,均高于6.5%的增速底线。按照变化趋势和业界相关专家预测,这里对2017—2025年地区生产总值年均增速分别按照6.5%、6.8%和7%进行预测,结果见表5所示。
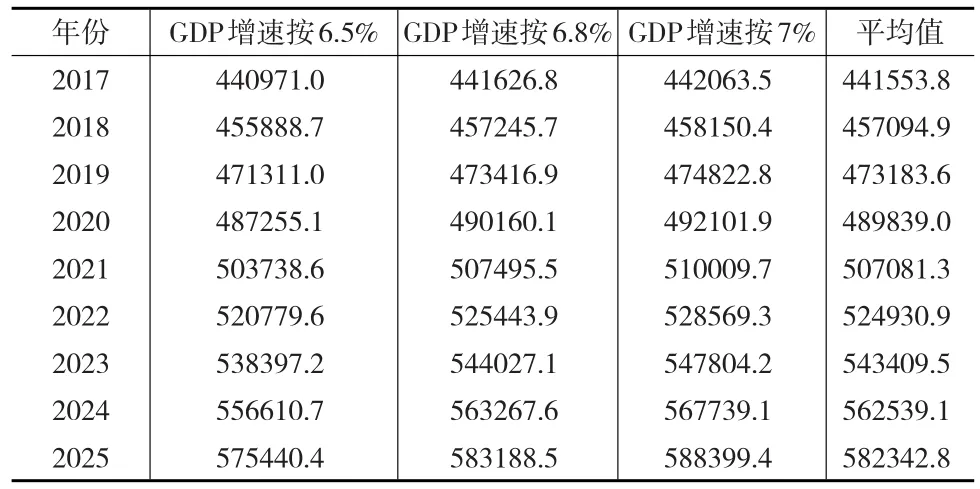
表5 2017—2025年能源消费需求趋势预测(万吨标准煤)
2.2 基于灰色关联分析的我国能源消费需求预测
灰色关联分析是一种现实的、动态的分析预测方法,具体的步骤如下:
对于给定原始序列x0=(x0(1),x0(2),…,x0(n)),可从原始序列中选择不同长度的连续数据作为子序列。
于是可生成序列x1(k)=x2(1)+x0(2)+…… +x0(k),(k=1,2,…,n)。
构造如下矩阵B和向量Yn:
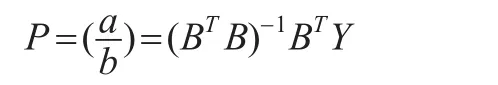
根据得到的系数a,b,可构建GM(1,1)模型如下:
x(1k+1)=(x(01)-b/a)e-ak+b/a
x(0k+1)=x(1k+1)-x(1k)
求解灰色预测模型GM(1,1)可得到预测结果。
运用上述模型,可得能源需求的灰色预测模型为:
x(1k+1)=3991116e0.0585k-3856127
经测算,得到模型预测及误差情况如表6(见下页)所示。
计算残差均方差与原始值均方差的方差比C,可得:
C=10833.1/95478.8=0.1135,平均相对误差绝对值为3.18%。由此可知,计算的能源消费预测的GM(1,1)模型拟合度较好,对能源消费预测具有一定的参考价值。
2.3 基于指数平滑法的我国能源消费需求预测
指数平滑法,是根据预测对象的历史数据,通过一定的加权平均进行数据拟合。从2000年以来我国能源消费总量的变化趋势可以看出,我国能源消费需求呈现一定的线性趋势,因此,本文采用二次指数平滑法对我国能源消费需求趋势进行预测。二次指数平滑法的计算模型如下:
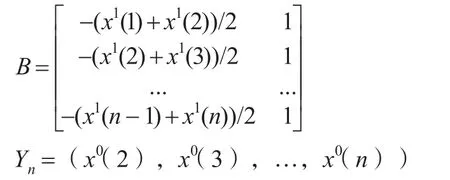
于是,可由最小二乘估计得到系数a和b:
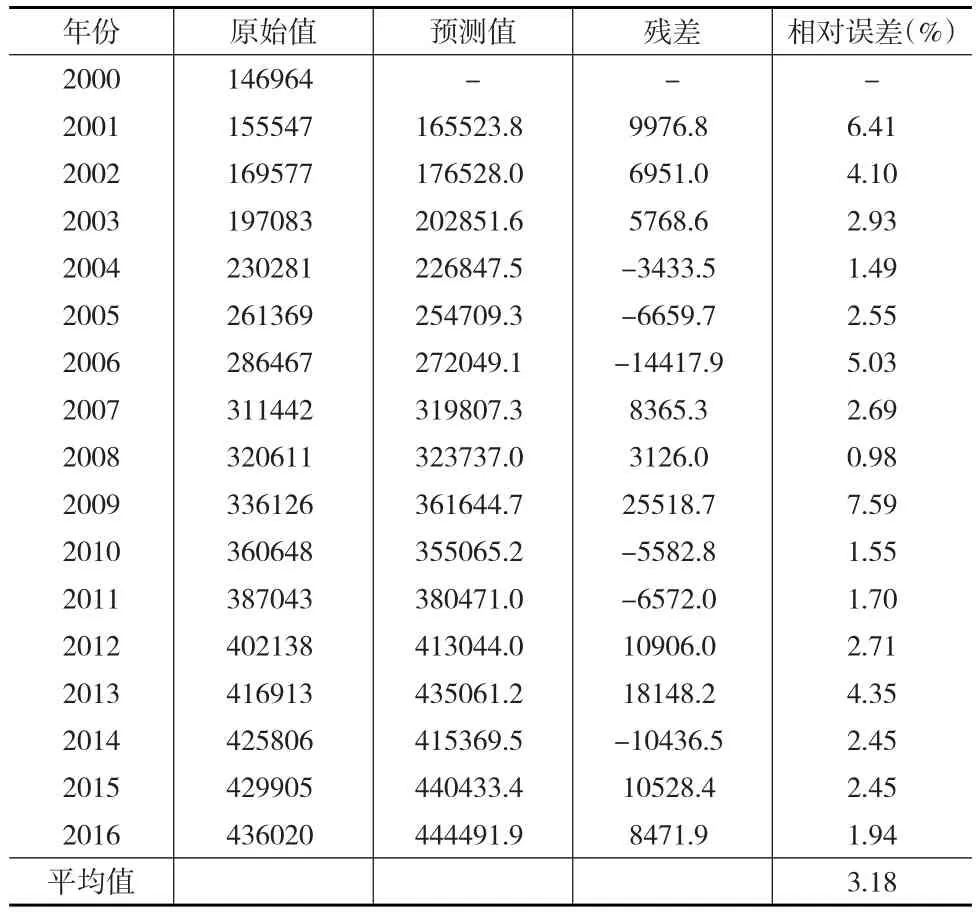
表6 基于灰色关联分析的能源消费需求预测结果(万吨标准煤)
其中,Sn(1)为一次平滑值,Sn(2)为二次平滑值,α为平滑常数经过反复测算比较,发现α取0.3时最优。这里取初始平滑值为原始值前三年的平均值。
经测算,得到模型预测及误差情况如表7所示。
表7 基于指数平滑法的能源消费需求预测结果(万吨标准煤)
由指数平滑法预测结果可以发现,平均相对误差绝对值为4.06%,拟合效果也较好,但精度相比灰色关联法较弱。
3 基于Shapley方法的我国能源消费需求组合预测
3.1 Shapley方法基本思路
设存在n种预测方法,集合为I={1,2,…,n},对其中任意子集s,t,E(s)、E(t)分别为各自组合的误差。设yi为第i种预测方法最终分配误差,对于n种方法组合预测带来的总误差E(n),会在这n种单项预测中完全分摊,即有:
又设i种方法相对误差的均值为Ei,组合预测法的总误差为E,则:
Shapley方法赋权法则为:
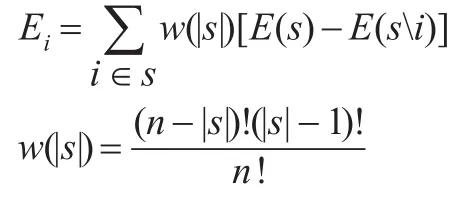
其中,w为单个预测方法i的边际贡献,(si)为组合中除去i,Ei为i种方法分摊误差,|s|为组合中单一预测方法的个数。
第i种预测方法的权重计算如下:
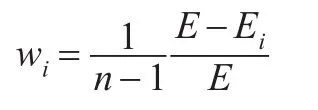
3.2 基于Shapley方法的我国能源消费需求预测
根据前面三种预测方法,可求得组合预测的总误差值为(6.16+3.18+4.06)/3=4.467。按照Shapley方法,参与组合预测的成员集合为I={1,2,3},其中任意子集的误差即包含元素的误差的平均值。于是,得到误差分摊结果如表8所示。

表8 误差分摊结果
按照Shapley方法计算模型,可求得各个成员的Shapley值:
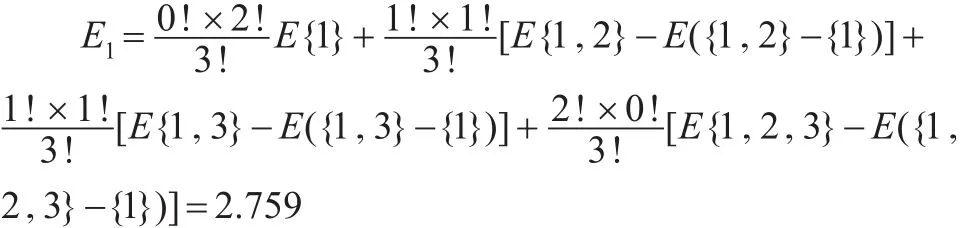
同理,可解得E2=0.671,E3=1.184。于是,三个成员的总分摊值为4.613,加权平均计算,得到各个参与的预测方法的权重分别为0.598,0.145,0.257。因此,可得到组合预测模型如下:
y’t=0.598y’1t+0.145y’2t+0.257y’3t
结合全面三种方法得到的拟合值,可以综合求得Shapley方法组合预测值,结果如下页表9所示。
3.3 模型比较及未来趋势预测
比较表4、表6、表7和表9可以发现,采用Shapley组合预测方法得到的2001—2016年能源消费需求预测结果的平均相对误差3.05%为最小。因此,可以认为采用Shapley组合预测方法得到的预测结果具有较高的精度,是相对最为有效的。
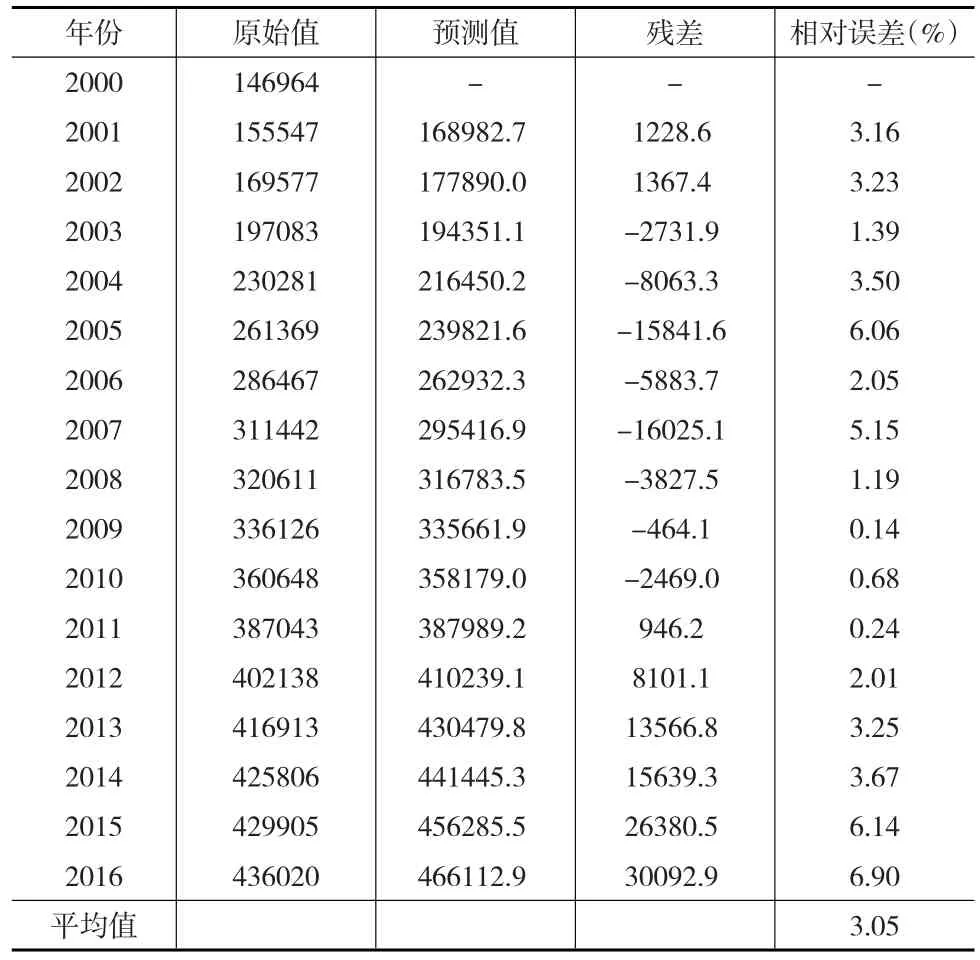
表9 基于Shapley组合预测法的能源消费需求预测结果(万吨标准煤)
为了对2017—2025年我国能源消费需求趋势进行综合预测,根据组合预测模型,首先采用前面三种单一的预测方法进行分年度预测,再根据各个预测方法的权重值进行加权平均,最终得到综合预测值。结果如表10所示。
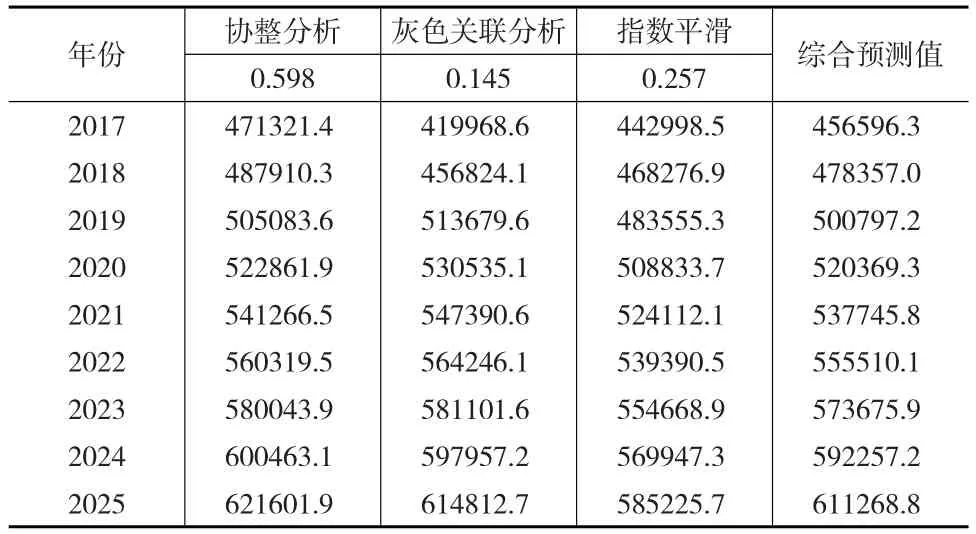
表10 2017—2025年能源消费需求综合预测结果(万吨标准煤)
根据表10结果,绘制2017—2025年能源消费需求的变化趋势图(图1)。由图1可知,未来几年我国能源消费需求将持续增长,但增速在经历了未来5年的有所上升之后,在2021—2025年逐步趋于放缓。到2025年,预计能源消费需求量达到57.3亿吨标准煤左右,同比增速在3%左右。
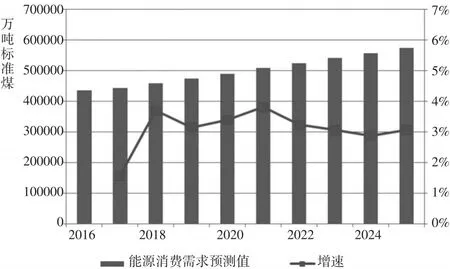
图1 2017—2025年我国能源消费需求趋势预测
4 结论
本文在三种单一预测方法的基础上,构建了一种赋权的组合预测模型,对我国能源消费需求进行预测。组合预测模型充分考虑了不同单一预测模型的优势。通过不同预测方法比较可知,本文的组合预测模型具有相对较高的精度,因此本文也为能源消费需求预测以及理论预测方法的改进提供了一种新的思路。根据最终预测结果,到2025年我国能源消费增长总体趋缓,增速不断趋于3%。但是,本文的组合预测模型是基于三类不同预测模型,而对于这些单一预测模型的选择仍然是一门重要学问。如何通过进一步优化梳理各种预测模型的优势,通过构建更为精确的组合模型进行预测,将是今后要努力的方向。
