ETL任务集群调度方法
2018-11-22李磊
李 磊
(北方工业大学 计算机学院,北京 100144)
0 引 言
ETL(transformation and loading,extraction)技术是构建数据仓库的基础技术,也是批量数据交换的基础技术[1]。ETL是将数据从源抽取、转换、整合、清洗并加载到目标的过程。ETL过程是构建数据仓库的重要环节,甚至占到了整个构建过程的80%[2]。随着时间变化,数据仓库中ETL任务增多,数据量也不断增多。若在单机上运行,任务执行花费大量时间,数据的时效性、可用性将严重受限。因此,研究ETL任务集群调度算法十分必要。如何将大量的ETL任务分配给集群中每个节点来获得数据仓库构建的最小执行代价,是ETL任务集群调度方法中主要研究的问题。数据仓库中的任务由于受到多种因素的影响,导致ETL任务执行时间不一,所以设计算法保障每个作业都能获取到执行的机会也是必要的。
文中基于贪婪调度算法[3]的思想,根据ETL任务数据源数据量的大小来合理分配任务,让集群中工作节点的负载达到均衡,使得总的任务执行时间最短。使用高响应比优先调度算法[4]动态调整任务的优先级,保障任务在节点上公平执行。
1 问题描述
1.1 传统ETL流程分析
首先,数据从数据源(例如:文本文件、关系数据库、XML文件、非结构文档等)抽取出来。其次,合适的转换、清洗、交集或并集等活动处理抽取的数据,使它们满足目标结构的需求。最后,加载处理过的数据到数据仓库[5]。
Kettle工具把ETL工作流实现为一个可以在Java虚拟机上执行的文件,也即是Kettle把上述工作流映射为相应的操作组件,组合为一个完整的ETL任务,由Kettle引擎调度工作流中的各活动。文中ETL调度不再考虑各个活动之间如何调度执行。通常由Kettle工具生成的作业文件依赖于操作系统的调度工具调度,例如Windows的任务计划、Linux的crontab,调度必须手动配置,无法满足工程需求。
1.2 ETL任务集群调度约束条件
ETL任务定义:ETL就是一个或多个数据源输出,经过加工处理,再输出到一个或多个数据源构成的流程[6],文中要调度的ETL任务就是Kettle工具生成的以上流程。
ETL任务集群调度定义:中心调度节点负责分配ETL任务到集群中的执行节点执行。
每个Kettle作业包含若干作业或者转换,它们之间具有指定的先后次序关系,Kettle转换包含的操作组件遵循的是并行执行的原则,Kettle引擎负责每个操作组件之间的调度[7]。集群中所要调度的就是能够并行执行的Kettle作业。
每个Kettle作业同一时刻只能有一个运行在集群中。不同的Kettle作业可以同时运行在同一台机器或不同机器。
集群中每个Kettle工作节点执行能力相同。
文中选取影响任务执行时间最重要的源数据的数据量大小,作为ETL任务分配的依据。
1.3 ETL任务集群调度目标函数
通常ETL任务执行考虑执行时间的代价、占用资源的代价以及两者相结合的代价[8]。文中选择执行时间代价。
T(kij):表示i任务在j机器上的执行时间代价,1≤i≤n,1≤j≤N。
T(mk):表示机器mk的执行时间代价,1≤k≤N。
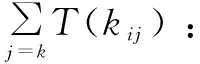
T(task):ETL任务在所有机器上执行的最长时间。
T(task)=max(T(mk))
ETL任务集群调度的目标函数可以定义为:
2 ETL任务集群调度方法
ETL调度系统由调度模块与执行模块组成。调度模块(调度中心)负责管理调度信息,把所有的调度任务抽象为一个任务,按照调度配置发出调度请求,自身不承担业务代码。调度系统与具体任务解耦,提高了系统的可用性和稳定性。执行模块(执行器)负责接收调度请求并执行任务逻辑。
调度流程如图1所示。批量ETL任务,使用基于贪婪调度算法把ETL任务分配到执行器,把任务添加到Quartz调度器[9]定时执行,抽象的Quartz任务调用远程的执行器接口,当此执行器接收到新任务的执行调用时,会启动本地线程运行ETL任务。使用高响应比优先调度算法计算任务优先级,分配到执行器上的任务按照优先级获取线程资源运行ETL任务。

图1 集群调度总体设计
贪婪算法是一种解决最优解的近似算法。在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,所做出的是在某种意义上的局部最优解[10]。假设有一个任务集合S={s1,s2,…,sn},S中每个任务所对应源数据量的大小W={w1,w2,…,wn},m台工作节点U={u1,u2,…,um}。该算法把S中的任务依据源数据量的大小平均分配到工作节点U中,求解总的任务执行时间最短的分配方法。假设每台机器分配到所有任务的源数据量总和越平均,硬件资源的负载越均衡,总任务执行时间代价越小。
贪婪分配算法具体步骤如下:
(1)对任务集合S按数据量从大到小排序,存入队列A。A={(si,wi)…(sj,wj)},其中wi≥wj,1≤i,j≤n。
(2)从队列A中取出队首的任务,计算各个节点任务数据量的总量,把该任务分配到ui,1≤i≤m。ui为当前工作节点中数据量总量最少的节点。
(3)重复步骤2直到队列空,算法结束。
高响应比优先调度用在ETL调度系统中来动态调整ETL任务的优先级。ETL作业的特点也即运行时间长短不一,如果动态调整ETL任务的优先级,有利于任务都能有机会获得资源运行。
将该算法应用到调度框架的执行器模块,主要设计如图2所示。执行器不断从调度中心接收到调度请求,然后缓存到优先级队列,在线程组资源充足的情况下,优先级队列的任务都能获得线程执行。当线程组资源不能满足需求时,一些ETL任务由于等待时间变长而优先级变高,如果有空闲资源,这些高优先级的任务将优先获取到执行机会。为避免有些任务占用时间过长,导致其他任务获取不到执行的机会,设计任务动态优先级调整任务的执行顺序,使用典型的消费生产者模型,优先级队列为生产者的缓冲区,任务监控线程为消费者代理(负责任务分配),线程组的线程为消费者。
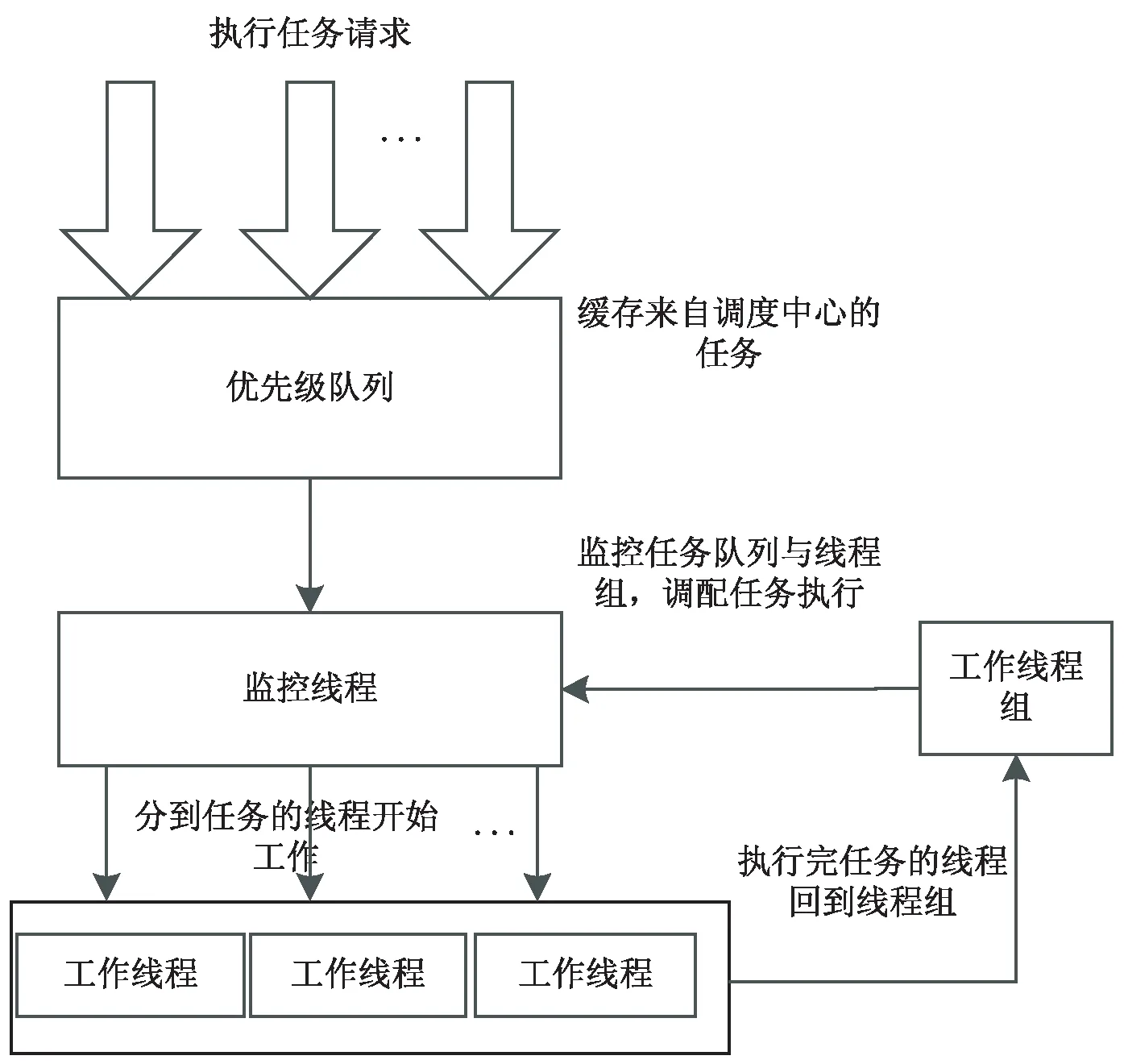
图2 执行器任务执行策略
3 实验结果与分析
3.1 实验描述
实验中模拟35个ETL任务,其中10个10万,10个20万,10个50万,5个100万条源表记录全量抽取任务,定时时间设置为每16分各个任务运行一次,记录10次全部任务运行完成各工作节点所需时间,求每台工作节点全部执行完的平均时间作为本节点的执行时间记录。实验使用4台虚拟机,1台调度中心,3台工作节点。配置见表1。
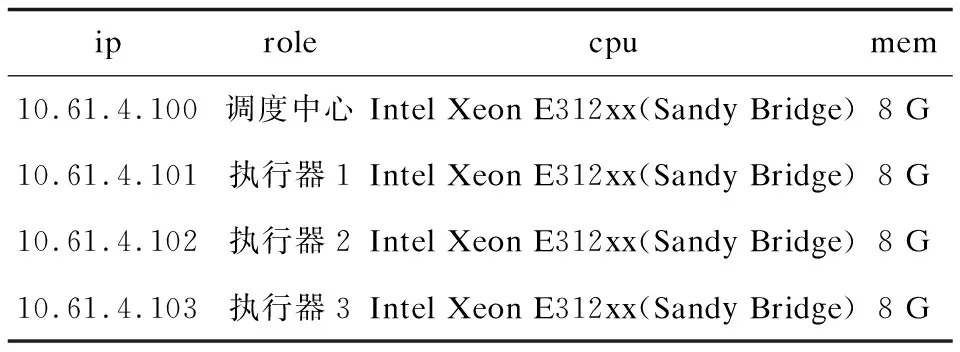
表1 集群配置表
3.2 实验结果
这35个任务按照贪婪分配原则分配之后的结果是:执行器一分到3个10万,3个20万,3个50万,2个100万数据量的任务,执行器二少分配一个20万,多分配一个10,相比于执行器一,执行器三分配到3个10万,5个20万,4个50万与1个百万数据量的任务。其他几次测试分配情况就不一一列举。使用ETL中基于贪婪算法的任务调度方法研究中,基于任务的平均时间分配得到的分组结果为:5个100万与10个50万与10个10万结果同上,30万101多一个,102多一个,103少2个。分组结果基本上与按源表数据量大小分配相同。任务为35个时,各个执行器使用贪婪算法与轮转算法的资源利用率如图3、图4所示。任务分别为10、35、45个时,使用贪婪、轮转分配算法执行完所有任务消耗的时间如图5所示。

图3 各执行器CPU使用率

图4 各执行器内存使用率
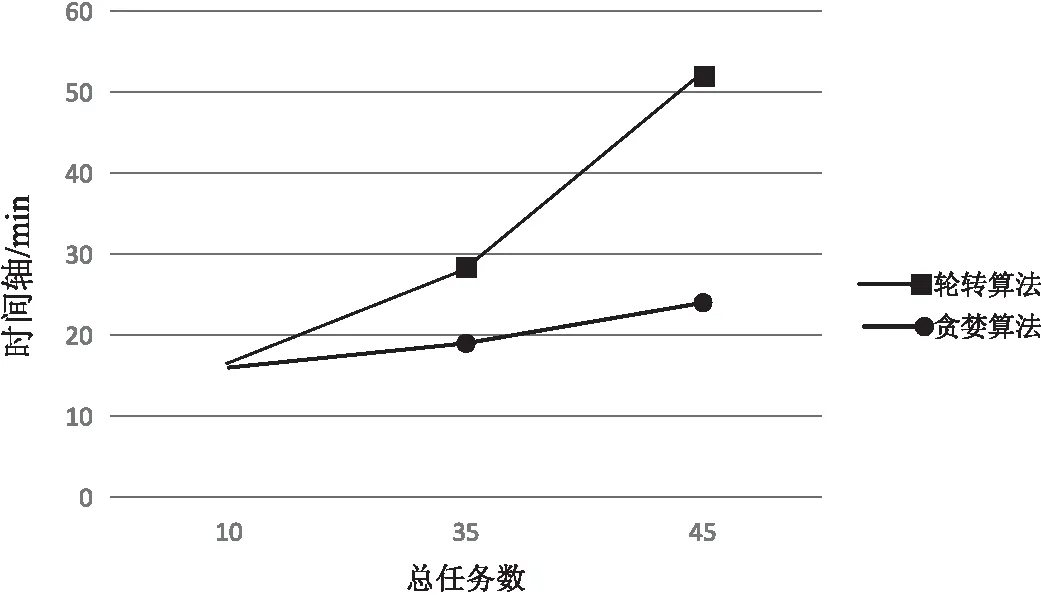
图5 执行任务的总时间
3.3 实验分析
轮转调度算法是以轮询的方式依次将作业分配到不同的服务器,即将所有服务器组成一个循环队列,每次取头服务器分配。从任务数量上看是平均分配到各个服务器,但是由于任务执行时间的大小不等,很大可能造成服务器负载的不均衡[11]。实验中通过比较轮转与贪婪调度算法所使用资源的情况,可以看出贪婪调度算法要优于轮转调度算法。比较相同任务条件下,轮转算法总耗时多于贪婪算法。轮转只考虑了任务的数量,并未考虑任务的其他特性,造成负载的不均衡[12]。而贪婪算法考虑ETL任务中关键因素任务数据量的大小,以达到负载相对均衡的目的。对于ETL中基于贪婪算法的任务调度方法,文中按任务平均时间作为分组凭据,同样使用相同数量任务的测试,得到的分组结果基本相同,但是分别测试每个任务的执行时间增加更复杂的步骤。同时为了保证所测试时间的准确性,还需要连续测试多天的数据,选择同一任务时间相近的数据作为最终分组的凭据。
4 相关工作
现有的ETL调度算法主要集中在ETL工作流逻辑转换的过程优化,通过减少处理过程数量或改变过程执行顺序来减少ETL工作流的执行代价[13],或者根据ETL活动的分配和调度而建立数据仓库ETL任务调度模型。如基于粒子群算法分布式ETL任务调度[14],设计ETL任务调度模型,将连续空间域映射为离散整数域解决工作调度问题,利用启发式算法找到最佳调度策略;基于遗传算法的ETL任务调度[15],采用同层划分的思想进行模型化求解。这些ETL任务调度算法,不适合现有成熟ETL工具生成的任务调度。
5 结束语
分析了ETL任务的特点,设计与优化ETL集群调度框架,加入批量ETL任务分配算法和动态优先级算法。贪婪调度算法依据ETL任务特点实现集群负载均衡,优点是把ETL中任务数据总量均匀分配到各个执行节点,减少任务执行时间。高响应比算法,优点是在任务执行时动态调整任务的优先级,以避免ETL任务获取不到运行资源。结合两种算法,文中设计的ETL集群任务调度系统具有高效稳定的特点。同时也存在不足:由于ETL任务执行涉及到数据量、网络带宽、数据转换复杂度等诸多不确定因素[16],实现负载均衡任务分配只从数据量单方面考虑,做不到准确,所以设计一种能衡量一个完整ETL任务权重的算法十分必要;由于贪婪调度算法是一种静态的分配算法,在分配任务完之后,如果有工作节点的资源使用率过高,不能做到动态调整,所以下一步设计动态调整任务的工作节点,以达到资源使用率的均衡,从而达到所有任务执行总时间最短的目的。
