基于改进极端随机树的异常网络流量分类
2018-11-20韦海宇柯文龙
韦海宇,王 勇,,,柯文龙,俸 皓
(桂林电子科技大学 a.计算机与信息安全学院; b.信息与通信学院; c.广西高校云计算与复杂系统重点实验室; d.广西可信软件重点实验室,广西 桂林 541004)
0 概述
随着计算机网络服务技术的迅速发展,计算机网络安全已经成为一个备受关注的问题,如何快速、准确地发现网络中的异常流量已经成为目前网络安全管理的主要研究内容。异常网络流量通常定义为偏离正常的网络连接,主要包括网络扫描、网络攻击、病毒感染等[1]。检测、监控网络安全状态,进行网络流量分类十分有必要,但是在海量的网络流量数据下,异常网络流量相对来说非常少,因此,识别少量异常流量样本是一项具有价值的研究。
近年来,机器学习算法快速发展,并被广泛应用到网络流量分类中。机器学习分类是一种有监督学习,首先需要提取数据样本,根据标签从数据集中学习,通过训练生成分类模型,然后将新的数据导入到分类模型中进行自动分类,分类的效果取决于分类样本的特征属性和分类模型的训练。本文提出一种基于改进极端随机树的异常网络流量分类方法,以期在大量网络流量情况下提高对少量异常网络流量样本的识别率。
1 相关工作
文献[2]提出一种基于C4.5决策树和支持向量机(Support Vector Machine,SVM)检测异常流量的组合算法。首先根据C4.5算法对异常网络流量进行分类,将其分为正常网络流量和异常网络流量,然后使用SVM算法对异常的网络流量进行细分类,将其分为不同攻击类别。该算法在KDD CUP 99数据集上能够获得较好的效果,但该数据集存在大量的重复数据,对模型的结果影响较大。
为了减少分类模型的训练时间,文献[3]首先根据主成分分析(Principal Component Analysis,PCA)方法对数据进行降维,然后使用随机森林对异常网络流量分类。虽然PCA能够有效地减少网络流量特征,但也会在一定程度上丢失一些重要数据特征。
文献[4-5]通过设计基于C4.5的决策树对异常流量数据进行分类。该方法简单、计算速度快、分类结果较好,但对新的网络环境适应性比较差。
文献[6-7]基于层次聚类方法对数据进行特征选择,其中文献[7]基于低维数据使用SVM算法对流量数据进行分类,该方法在NSL-KDD数据集上可得到95.2%的分类准确率,但是在少量样本的U2L类别上分类结果相对较差。
文献[8]提出PSO-Random Forest的异常流量检测算法,首先根据粒子群优化(Particle Swarm Optimization,PSO)算法获得最优的特征组合,然后使用随机森林算法对这些特征进行分类。该算法在KDD CUP 99数据集上能够获得很好的效果。
在异常网络流量分类的问题上,研究者关注分类准确率和时间效率,致力于结合各个算法的优点提高分类的精度,减少分类模型训练时间。
文献[9]首先提出一个基于密度比的数据特征转换算法以获得更好的特征表示,然后基于SVM实现网络流量的分类。该方法在NSL-KDD数据集上得到了99.28%的准确率。
文献[10]提出超图遗传算法和SVM算法的组合算法,其中超图遗传算法对模型和数据特征选择进行参数优化。该文在实验中对使用特征选择算法后的数据和原始数据进行分类结果比较,结果表明特征选择可以更好地提高分类检测率。
文献[11]提出基于词袋模型聚类的异常流量识别方法,首先根据K-Means算法对流量做均值聚类,得到网络流量的关键特征,然后利用SVM、C4.5等分类算法进行识别,平均识别率达到90.9%。
文献[12]研究集成学习方法在异常网络流量中的应用,重点介绍Adaboost算法、Boost算法等,该文总结得出集成方法在异常网络流量分类中效果更为明显,能达到81%左右的准确率。
文献[13]首先根据分类与回归树(Classification and Regression Tree,CART)算法将网络流量分为异常流量和正常流量2种流量类型,然后比较SVM、Naive Bayes、Neural Network在攻击类别分类中的效果。利用该方法在NSL-KDD数据集上对DoS、R2L和Probe的分类获得了96%的准确率,但该文未研究U2R攻击类别的分类。
综上所述,目前的异常网络流量分类方法研究主要集中在决策树、SVM等机器学习方法,但是仍存在一些问题。多数研究只考虑在整体上评估分类效果,而对于少量样本的类别并没有过多关注。此外,决策树对少量样本类别的数据容易过拟合,或者是算法模型复杂、训练时间长、使用的实验数据存在样本重复等。针对以上问题,本文提出一种基于极端随机树的改进算法(IET)。本文的创新点在于:1)结合极端随机树(ET)和随机森林算法(RF)的优点,改进分类模型的训练方法和最后的投票决策[14]过程;2)更全面地训练少量样本的类别,同时保持算法模型基分类器的随机独立性。
2 极端随机树算法
文献[15]提出极端随机树算法,该算法是一种集成算法,用{T(K,X,D)}表示,其中,T表示最后的分类器模型,D为数据样本集,K为基分类器的数量,每个基分类器根据输入样本X={x1,x2,…,xM}产生预测结果,最终通过投票确定最后的分类类别。ET算法的具体步骤如下:
步骤1给定原始数据集D、样本数量N、特征数量M,在极端随机树的分类模型中,每个基分类器使用全部的样本进行训练。
步骤2根据CART决策树算法生成基分类器。为增强随机性,在每个节点分裂时随机从M个特征中选择m个特征,对每个节点选择最优属性进行节点分裂,分裂过程不剪枝。对分裂产生的数据子集再迭代执行步骤2,直至生成一棵决策树。
步骤3重复步骤1和步骤2迭代K次,生成K棵决策树以及极端随机树。
步骤4对生成的极端随机树使用测试样本生成预测结果,对所有基分类器的预测结果进行统计,利用投票决策的方法产生最终的分类结果。
ET算法具有如下优点:1)是一种集成学习算法,其通过投票决策产生预测结果,具有更好的泛化能力;2)使用全部数据样本训练基分类器,使得所有样本都被训练;3)在节点分割上随机选择分割属性,增强了基分类器间节点分裂的随机性。但是该算法也有些不足,表现在每棵决策树都使用全部样本进行训练模型,这使得决策树间的随机性有所降低,对结果预测造成影响。为既能保证模型得到充分训练,又能提高基分类器间的独立性,本文提出改进的极端随机树算法。
3 改进的极端随机树算法
本文在训练分类模型的过程中,对一部分基分类器采用全部样本构建决策树,另一部分基分类器采用经过重采样的样本来构建决策树,同时在最后投票结果中,对于使用重采样样本进行训练的基分类器,采用加权投票方法,优化分类器的投票过程,形成改进的极端随机树算法。具体算法框架如图1所示,其中分类过程包括3个部分:特征选择,装配训练模型,投票代理决策。

图1 改进的异常网络流量分类算法框架
3.1 特征选择
特征选择的具体步骤如下:
步骤1特征预处理。首先将数据的空值特征进行替换,在本文中,将空值特征用0替换,消除网络流量类型偏差的影响;其次,为统一数据格式,本文将网络协议、服务类型、网络状态等名义变量映射为数值索引,例如协议内容包括{icmp,tcp,udp},对应的索引地址为{0,1,2}。
步骤2计算特征值的信息增益率。例如设定A为网络协议的某个特征,数据集D中特征A的信息增益率gainRation(D,A)根据式(1)计算。
(1)
要求得特征A的信息增益率,应已知该属性的信息熵gain(D,A)和信息分裂度量splitInfo(D,A)。gain(D,A)根据式(2)计算。
(2)
其中,pa为特征A各类划分的频率,entropy(D)和entropy(A)的计算方法如式(3)所示。
(3)
在式(3)中,C表示在数据集D有C种类别,本文中C取{0,1,2,3,4},分别表示DoS、Probe、R2L、U2R和Normal,pc表示C=c在总样本中的占比,该表达式表示关于第c个分类的信息度量。相应地,在求entropy(A)时,C表示在特征A上可划分的类别,pc表示该类别数据子集与总数的占比,最后求得关于特征A的信息熵。
根据式(4)计算特征A中的分裂信息度量:
(4)
步骤3特征排序和选择。根据样本特征的信息增益率对其进行排序,选择相关性较大的特征,同时去除相关性较小的特征,在本文中根据阈值选择网络流量特征。
3.2 改进的训练模型
本文算法主要是改进训练方法和模型,具体步骤如下:
步骤1选择特征向量。计算数据样本特征值的信息增益率,并对其建立特征值的索引信息。
步骤2生成字典对象,在训练极端随机分类树时使用字典保存基分类树模型。
步骤3装配训练模型。采用与其他算法不同的组装方法,在构建的训练模型中,一部分基分类器使用全部的训练样本,另一部分基分类器使用重采样的方法产生训练样本。该过程的目的是既能全面训练少量样本,又能增强基分类器间的独立性,以达到更好的预测结果。本文首先生成10以内的随机整数,对2求余,若为0,则采用抽回样本进行训练;若为1,则采用全部样本进行训练。在训练过程中,使用字典T←{t1,t2,…,tk}记录每棵决策树的训练,其中ti表示每个基分类器的分类规则,同时记录训练样本的信息。
步骤4训练分类器。如果输入样本低于节点最低样本或者经过规则可以确定分类类别,则生成叶子节点,否则随机选择若干个候选属性A←{a1,a2,…,am},产生相应的候选样本子集Dm={D1,D2,…,Dm}。
步骤5选择分裂的属性值,该过程与CART的分裂规则一致,但是在选择节点分裂的特征值时根据分裂分数最高,即max(score(A,D))的属性进行分裂,产生2个数据子集数据。评估分裂分数是特定归一化后的信息增益计算方法,通过式(5)计算。
(5)

步骤6分别对左子树和右子树迭代执行上述步骤,生成决策规则,直到满足条件为止。
步骤7对上述步骤重复K次。
3.3 改进的投票方法
在改进的分类器模型中,对于使用重采样数据进行训练的基分类器采用加权投票表决方法。在抽回采样中,使用bagging方法从原始训练集中有放回地抽取样本,形成新的样本子集,该样本被称为Out-of-Bag(OOB)数据。对于原始数据样本,每个未被抽取的概率为:
(6)
将当前决策树的OOB数据记为Ot,由于决策树训练过程是有监督的,通过比较当前分类器的分类结果和真实样本,得到Ot中分类正确的样本个数,记为Ott。由此,可得到当前决策树t的分类准确率:
(7)
将决策树OOB数据的分类准确率pt作为对应分类决策树的权重,对样本x的分类结果进行加权统计,对于预测的类别投票记为:
(8)
其中,Tt,x表示分类正确或者错误,取值1或者0,最后得票最多的即为最后的分类结果。
4 实验与结果分析
4.1 实验数据
KDD99数据集于1999年产生,由于该数据集重复样本比较多,因此本文使用NSL-KDD数据集[16]。该数据集是在KDD99数据集上进一步整理得到的数据集,共有41个网络流量特征,包括连接特征、时间特征、数据包统计等信息。从数据类型上看,该数据集有3个名义数据、6个二分类属性和32个数值类型。协议类型有ICMP、UDP、TCP 3种;状态类型有OTH、REJ、RST、OS0等16种;服务类型有IRC、FTP、whois等70种;攻击类型有DoS、Probe、R2L和U2R 4种。该数据集的攻击类别信息如表1所示。

表1 NSL-KDD数据集攻击类别
本文对NSL-KDD数据进行混洗后按6∶4划分进行实验,即训练集占总数据的60%,测试集占40%。在本文中,所有对比的实验结果都是基于同组数据的情况下进行,数据样本分布如表2所示。

表2 实验数据样本分布
实验的硬件配置为IntelCore(TM) i5-4210H@2.90 GHz,4 GB RAM,软件配置为Windows 10 64位操作系统,Scikit-Learn 0.18。
4.2 分类性能评估方法
在特征选择过程中,主要是计算流量特征的信息增益率,根据信息增益率值从大到小进行排序和筛选。
为有效评估分类效果,实验中对于分类结果的评价指标使用精确率和召回率。分类精确率计算公式如下:
(9)
其中,TP表示在正样本中分类正确的样本,FP表示将负样本分为正确的样本,FN表示正样本数分为负样本数。召回率计算公式如下:
(10)
4.3 特征选择结果
本文实验计算属性的信息增益率,并对其进行排序,图2列出了数据集中各个特征信息增益率的值以及排序的结果。从图2中可以看出:将信息增益率阈值调整到0.01时,最后获得39个数据特征;将阈值调整到0.1时,获得33个数据特征,其中srv_serror_rate的信息增益率最高,达到0.507,而num_outbound_cms和is_host_login的信息增益率为0。

图2 特征选择排序结果
4.4 分类结果对比
根据不同的数据集验证极端随机树(ET)、随机森林(RF)和本文提出的改进极端随机树方法(IET),比较这三种集成算法的分类效果,从各个网络流量类别分类的精确率、召回率和时间上进行比较,最后验证基分类树个数与精确率的关系以及基分类器与时间的关系。本文提出的算法基于开源机器学习库Scikit-Learn[17],对其中的极端随机树算法进行改进并编码实现。
将本文算法同其他集成算法的分类结果相比较,取Scikit-Learn中的极端随机树和随机森林算法作为对比,分别计算未经特征选择的数据、特征的信息增益率大于0.01的数据,以及数据特征的信息增益率大于0.1的数据,比较同类数据集下3种算法的精确率p和召回率r。
从表3~表5中可以看出,对于5种流量类别的分类结果,3种算法对DoS、Probe这两种攻击类型的数据集上分类结果总体相差不大,精确率都能达到0.99,主要是该类数据的训练样本比较多,训练过程比较充分,而R2L和R2R这两类数据样本则有所不同,具体数据比较如表中加粗部分所示。
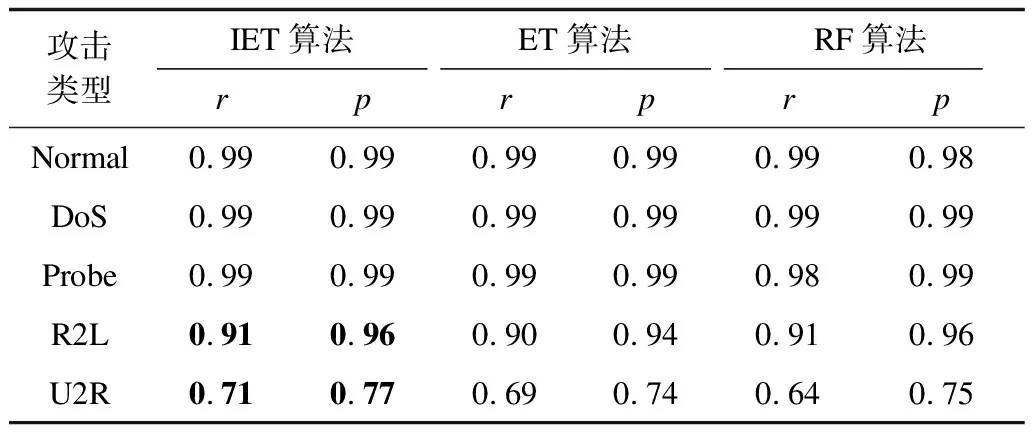
表3 3种算法在未经特征选择的数据集上的结果

表4 3种算法在信息增益率大于0.01数据集上的结果

表5 3种算法在信息增益率大于0.1数据集上的结果
由表3可见:对于攻击类别为R2L的网络流量类型,本文算法召回率达到0.91,精确率达到0.96;对于U2R类型的攻击类别,本文算法召回率达到0.71,精确率达到0.77,分别为该网络类别最好的划分结果。
由表4可见:对于攻击类别为R2L的网络流量类型,本文算法召回率达到0.92,精确率达到0.96;对于U2R类型的攻击类别,召回率达到0.52,精确率达到0.86;在U2R上,IET算法的表现介于ET算法和RF算法之间,RF算法的精确率要高于IET算法,但是IET算法的召回率要高于RF算法,而IET算法与ET的算法相比,召回率稍低,但是精确率较高。
由表5可见:在R2L类别上,本文算法召回率达到0.92,精确率达到0.97;在U2R类别上召回率为0.46,精确率为0.86。
在建模时间上,本文算法和原始算法在使用实现4个线程同时工作时,设定基分类器的个数为180个,选不同的数据集进行实验,训练时间和预测时间的时间控制在1 min以内,结果如图3所示。可以看出,本文算法建模时间始终保持在极端随机树和随机森林之间,能够保证算法在时间上的可行性。

图3 3种算法在不同数据集上的建模时间
图4显示了特征维度与总体分类精确率的关系。可以看出,本文算法在阈值为0.01的数据上,整体分类准确率的表现比原始数据维度的结果更优,达到0.995 6,而当筛选的阈值为0.1时,分类结果相比于原始数据与阈值为0.01时略差一些。

图4 基分类器个数与精确率的关系
图5显示了基分类器个数与时间的关系。可以看出,本文算法在设定阈值为0.01时,建模时间相对更短,比选择筛选阈值为0.1的数据建模时间更长,表明在异常网络流量的特征选择过程中,使用信息增益率进行特征选择是有效且可行的。

图5 基分类器个数与建模时间的关系
5 结束语
为提高对少量异常网络流量样本的分类准确率,本文提出一种基于改进极端随机树的分类方法。首先在特征选择部分约减数据维度,除去不相关的数据特征,然后基于改进的极端随机树构建异常流量分类模型。实验结果表明,本文方法在重组的NSL-KDD数据上可达到0.995 6的分类精确率,在异常流量分类中相对于其他集成分类方法准确度更高,同时在少量样本条件下的分类结果表现更优。
本文算法尚有一些改进的地方,例如在原始数据样本上与其他算法相比,算法的鲁棒性相对较好,但不显著,原因在于数据分布很不均衡。未来将在实际的网络流量上验证本文算法,进一步提升模型的分类性能,同时对其进行并行化训练和预测,减少训练和预测时间。
