分布式环境下遥感影像数据存储方法
2018-11-16王卓琳高心丹
王卓琳, 高心丹
(东北林业大学 信息与计算机工程学院, 哈尔滨 150000)
0 引 言
随着遥感技术的发展,遥感数据逐步呈现多源,多尺度,多时相,全球覆盖和高分辨率特征,数据量爆炸性增长[1]。遥感以其能够表达大容量数据的特点广泛应用在对地、军事、勘探、水污染防治、林火防治以及庄稼病虫害监测等有空间大范围数据量需求的领域。如何能高效地存储和查询遥感影像数据,在海量的信息中有效提取所需信息,已成为地理信息科学领域日益关注的热点问题[2-3]。
传统的数据管理方式为文件系统方式,存在读写速率低,传输速率慢等缺点。随着数据库技术的发展,逐渐提高了数据的共享性,减小了数据的冗余,提高了数据的一致性和完整性。在此基础上,文献[4]中提出了一种线性四叉树技术的影像金字塔模型快速索引机制,该机制可以根据用户需要以不同分辨率进行存储与显示,但是海量影像数据的存储性能低下。文献[5]中提出了一种基于影像块组织的遥感数据分布Key-Value存储模型,结合开源分布式文件系统HDFS[6],实现了影像数据的分布式高效存储与空间区域检索,有效地解决了传统的关系型数据库技术不能满足存储和管理海量数据的性能需求和海量数据在单节点存储的效率和可扩展性不足等缺点。但是这种方法无法实现快速随机访问数据,因此文献[7]中研究基于HBase的分布式存储,釆用网格法对地理空间进行划分,构建索引表,计算出每个网格单元对应的ID,设计行键和列族方案,提高了存储和查询效率。在金字塔构建部分,文献[4,8]中都采用降采样方法来构建金字塔,但在金字塔构建中却耗费了很长时间,因此文献[9] 在文献[4,8]的基础上采用分布式网格金字塔生成算法(Distributed Grid Pyramid Generation Algorithm,DGPG)并行构建金字塔,节约了金字塔构建时间,提高了效率,但同样存在金字塔构建中上层分辨率降低,导致金字塔上层影像重要内容的清晰度和存储性能降低的问题。
为在构建影像金字塔过程中降低分辨率的损失,作者采用寻优算法替代降采样。在经典寻优算法中,遗传算法[10]搜索速度较为缓慢,不能很好进行局部搜索;粒子群算法[11]在算法后期不能很好的跳出局部最优;蚁群算法[12]引入了信息素,加大了算法的时间复杂度,降低了算法效率(尤其是在样品较多的情况下)。为解决上述问题,本文实验中引入了一种新型的用于解决图像问题的群体智能算法—猫群算法[13-14],并结合MapReduce[15]并行框架构建金字塔;然后使用HBase[16]存储影像数据,设计了一种结合地物标识码和四叉树索引ID两种信息的行键方案进行索引查询,大幅提高查询的处理速度。
猫群算法是建立在猫的行为模式和群体智能基础上的一种非数值优化计算方法。该算法将猫群分为两种工作模式,在搜寻模式下,通过对自身位置的复制,之后再对复制副本应用变异算子,加深了对自身位置周围的搜索,有效地提高了问题的求解性能; 在跟踪模式下,利用最优解的位置来不断的更新猫的当前位置,使得解不断地向着最优解的方向逼近,最终达到全局最优解。影像金字塔结合了分块和细节层次模型LOD两者的特点,以原始图像作为底层,通过对原始图像采用重采样的方法,建立一系列地理覆盖范围相同但详尽程度和分辨率不同的多个影像。为了提高影像金字塔各层的分辨率,本文采用猫群算法对金字塔下层寻优来获得上一层,进而构建金字塔。
1 高分辨率影像金字塔的并行构建
影像金字塔最初用于机器视觉和图像压缩。一幅影像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始影像的影像集合[17-18]。其通过猫群算法寻优获得,直到达到某个终止条件停止。金字塔的底部是待处理影像的高分辨率表示,而顶部是低分辨率的近似。将一层一层的影像比喻成金字塔,层级越高,则影像越小,分辨率越低。
在浏览影像数据时,需要根据当前显示的影像数据的分辨率来抽取金字塔相应层的数据。设原始影像数据的分辨率为R0,倍率为2,则第I层栅格数据的分辨率为:
RI=R0×2-I
(1)
设影像分块为X×Y个像素,影像数据的像素为宽×高,则金字塔等级层数I的计算式为:
I=[log2max(Width/X,Height/Y)+1]
(2)
I级金字塔水平方向总块数H和垂直方向总块数V的计算式分别为:
(3)
(4)
式中:[]表示取整;| |表示向下取整。
本文釆用线性四叉树对地理空间进行划分,将划分好的每个网格单元进行编码,然后利用MapReduce并行计算框架结合猫群算法构建金字塔。
1.1 线性四叉树编码
影像金字塔的线性四叉树编码实质就是用线性四叉树的数据结构来表示多分辨率遥感影像的索引[19],影像金字塔与线性四叉树的映射关系如图1所示。

图1 影像金字塔与线性四叉树的映射关系
由图1可以看出,I-2层第1行第2列的编码可以表示为:000001;I-2层第1行第3列的编码可以表示为:000100;I-2层第2行第2列的编码可以表示为:000011;I-2层第2行第3列的编码可以表示为:000110,以此类推。
1.2 猫群算法寻优构建金字塔
因以2倍率构建金字塔,所以金字塔上层的每一块影像只需在其下一层中找到该层每4个相邻的影像块及其附近的一块能代替该4个影像块即可。假设原始影像可以分成4类,分别用C1、C2、C3、C4来表示。构建中可能出现4种情况,现将它们分为2组来讨论,4种情况的示意简图如图2所示。


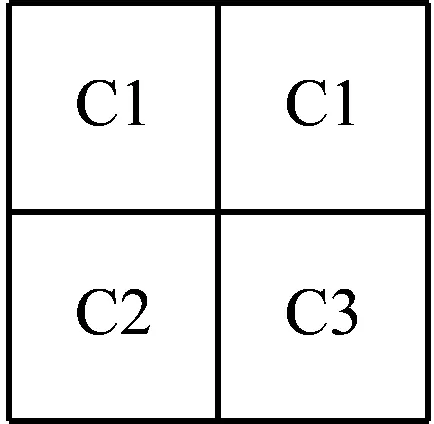


(a)(b)(c)(d)
图2 金字塔下层每4个相邻的影像块情况
若每相邻的4个影像块中有3块或4块的影像属于同一类,上一层的影像就用该类中的一个影像块代替,该影像块根据特征相似度在4个影像块同类中最大,不同类中最小的原则选取。如图2中的(a)和(b)所示,则用C1类代替,具体用C1类中的哪个块代替,则根据计算的相似度决定。如果是图2中(c)和(d)的情况,则运用猫群算法进行搜索寻优,找到能代替该4个相邻影像块数据的那个影像块,用其构建金字塔上一层。设f为找出搜索范围内影像块特征相似度在该类中较大的,在不同类中较小的影像块且影像块数最多的目标影像块,x为目标影像块。搜索范围以C1影像块为例如图3所示,其余3个影像块的搜索范围同C1。

图3 猫群算法搜索范围
图3中C1影像块的搜索范围为以C1为中心的八个方位上搜索。图中红色+蓝色区域为搜寻一次的搜索范围,若该区域不能找出最优解,则搜寻范围扩充为红色+蓝色+黄色区域,以此类推。
猫群算法中各术语代表如下:
猫算法中的一个解,对应金字塔构建问题中的一个影像块解。
猫群金字塔构建问题中的所有影像块解。
适应度猫所处位置的适应度,在算法中表现为猫所处位置的优劣,在金字塔构建问题中代表影像块解的特征相似度和影像块数。
记忆池(smp) 在搜寻模式下,记忆池的大小代表猫能够搜索的地点数量,通过变异算子,改变原值,使记忆池储存了猫自身的邻域内能够搜索的新地点。猫将依据适应度的大小从记忆池中选择一个最好的位置点。
个体上每个基因的改变范围(srd):在算法开始之前设定,在本文算法中代表影像块解每一特征的变异概率。
每个个体上需要改变的基因的个数(cdc):在算法开始之前设定,在本算法中代表影像块解可变异的特征数。
分组率(mr):分组率将猫群随机分为跟踪模式和搜寻模式2组,指的是跟踪模式的猫在猫群中所占的比例,通常为较小的数。
跟踪模式是来模拟猫处于跟踪状态下建立的模型。在该模式下,通过改变猫的每一个特征的速度来改变猫的位置。跟踪模式可以通过以下2步来描述。
(1) 速度更新。.每只猫都有自己的一个当前速度,记为Vi={Vi1,Vi2,…,Vil},每只猫根据式(5)来更新自己的速度。记Xbest(t) 为当前猫群里经历的最优位置,即适应度最好的猫。

d=1,2,…,l
(5)
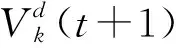
(2) 位置更新。每只猫根据下式更新自己的位置:
(6)
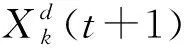
搜寻模式是模拟猫在四处搜索并寻找下一个地点所建立的模型。猫复制自身副本,在自身邻域内加一个随机扰动到达新的位置,再根据适应度函数求取适应度最高的点作为猫所要移动到的位置点。其副本的位置更新函数为:

(7)
式中:srd=0.2,即每个猫个体上的特征值变化范围控制在0.2之内,相当于是在自身邻域内搜索。
设猫群为X={Xi,i=1,2,…,n},Xi为D维模式向量,代表第i个猫(影像块)总特征,内部可拥有表示光谱信息的DN值,反射率值、波段相关系数、表示空间信息的像素位置、大小等。如扩展开,还可加入颜色特征信息,纹理信息、煽、能量等。该小节问题就是要找出搜索范围内该影像块特征相似度在同类中相似度较大的,在不同类中较小的那个影像块且所占影像块数最多的。设任意 2个猫的同一基因(特征)分别为:X1=(x11,x12,…,x1d),X2=(x21,x22,…,x2d),其中d为基因中分量的个数。C[X1,X2]为X1与X2的基因属性值的集合,那么X1与X2之间的距离为:
(8)
假如定义其光谱特征距离为D1,采用特征空间网格划分方法得到的纹理和形状特征距离分别为D2和D3,则光谱特征为:
(9)
由式(9)进一步可得,图像空间的2个猫(网格)N1和N2,设它们的相似性为S,则相似性为:
(10)
式中:ωi为经验权值;ω1,ω2,ω3为3个影像块特征的权重;ω1+ω2+ω3=1。
由式(8)~(10)可得猫群算法的适应度函数为:
Cat(i).fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k))
(11)
式中:i为目标影像块;k为某类影像块的集合;N为搜索范围内所有影像块的集合。max[sum(class)(N)]是指搜索范围内所有影像块中某类影像块数量占总影像块数量(1/4以上)最多的,max(S(i,k))是指该寻找的目标影像块与某类影像块集合相似度(大于50%)最大的,min(S(i,N-k))是指该寻找的目标影像块与其他类影像块集合相似度最小(小于10%)的。以上各参数值是根据实际数据类别数量和具体情况经过反复实验得到的。
算法实现伪代码如下:
猫群算法寻优构建金字塔伪代码
%初始化猫的数目N,记忆池大小smp,个体上每个基因的改变范围srd,每个个体上需要改变的基因的个数cdc,分组率mr,猫的初始位置X、初始速度V和初始适应度Cat(1).fitness=0
%if跟踪模式
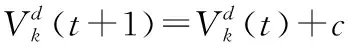
%适应度计算
Cat.(i)fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k));
%最优解,直接退出
%else搜寻模式
%将自身位置复制smp份,同自身一起存入记忆池
forn=2:smp
current_Cat(N)=Cat(i);
end
%对记忆池复制的位置进行改变
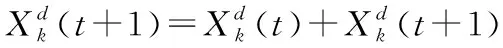
%适应度计算
current_Cat.fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k));
%最优解,直接退出
%记录搜寻的最好位置
max_Cat=current_Cat(1);
for n=2:smp
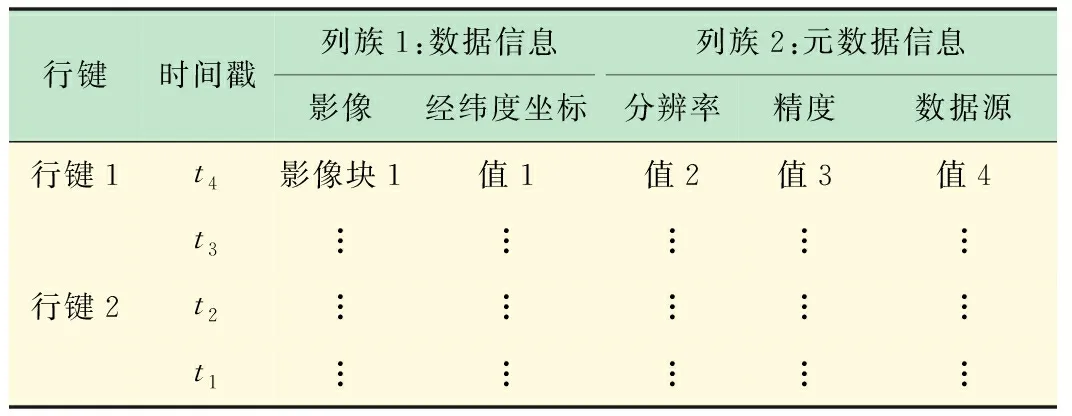
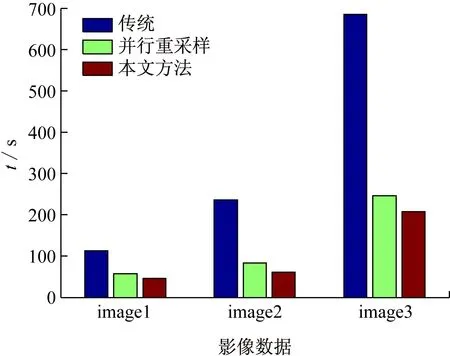
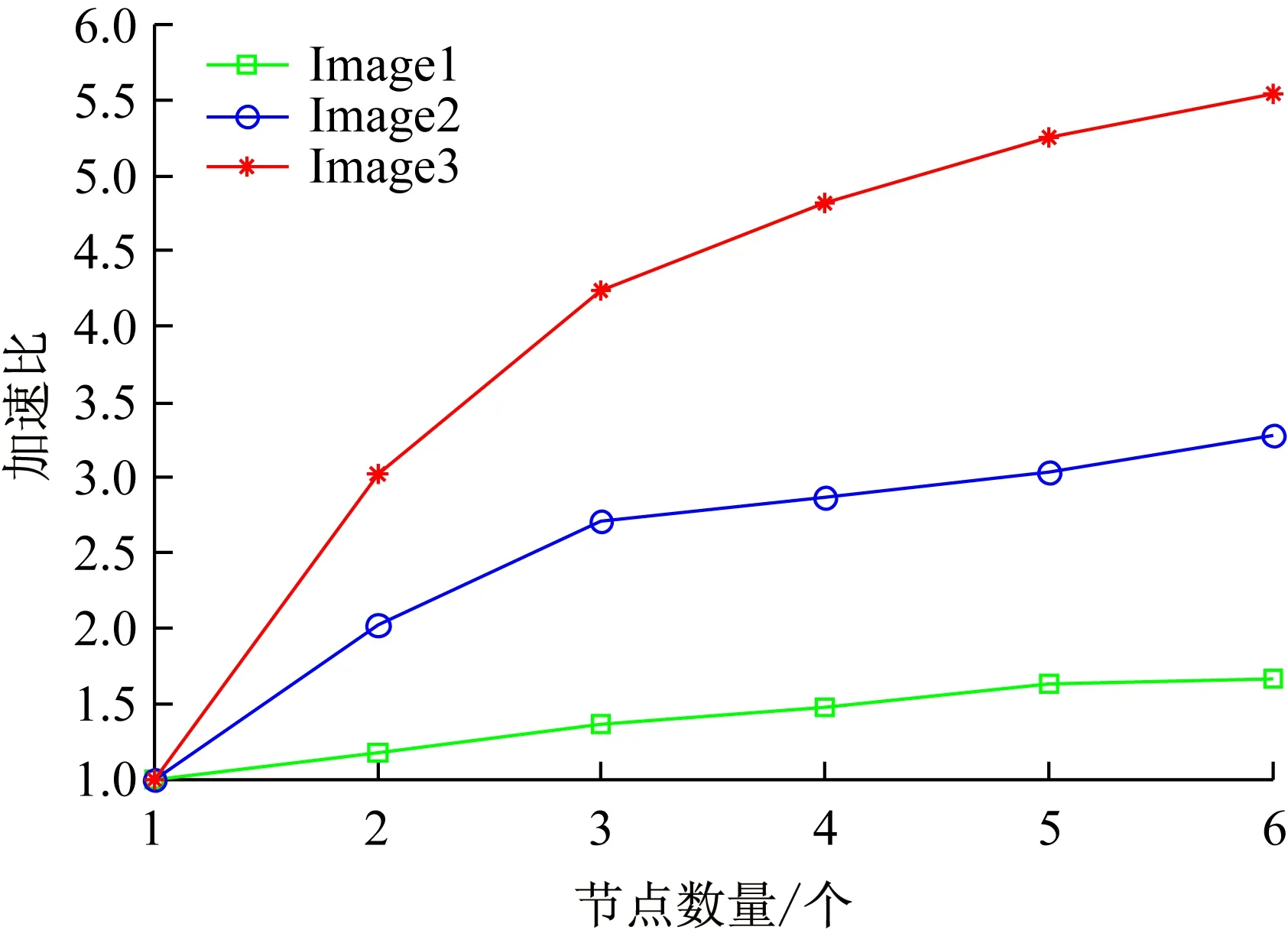
if max_Cat.fitness max_Cat =current_Cat(N); end end Cat(i) =max_Cat; end 为了提高金字塔的构建速率,本文使用MapReduce并行计算框架,通过对金字塔的每一层分别使用MapReduce来解决传统的串行方法构建金字塔效率低下的问题。在原始图像已经分好类的前提下,以原始图像作为金字塔的最底层即第0层,然后依次从最底层出发通过2I×2I→1(I为金字塔的层数)影像块的映射关系运用MapReduce得到金字塔第1层、第2层...第I层。但是这只是在满足图2中(a)、(b)两种情况下的映射关系,如若不是这两种情况则需要结合猫群算法寻优,第0层均采用如图1~3 所示的红色+蓝色+黄色区域,即(21+4)2个影像块作为寻优范围来找出金字塔第1层所对应的一个影像块,金字塔的第1层均采用如图4 所示的蓝色+黄色+绿色区域,即(22+4)2个影像块作为寻优范围来找出金字塔第2层所对应的一个影像块......以此类推,金字塔的第I-1层均采用(2I+4)2个影像块作为寻优范围来找出金字塔第I层所对应的一个影像块。 图4 并行构建中金字塔第1层到第2层映射范围 如图4所示,C1-C16→1为金字塔第0层到第2层的块数映射关系,但是结合猫群算法后实质的映射关系为蓝色+黄色+绿色影像块区域→1,即猫群算法在此区域内寻优找到所对应的一个影像块。 Map 函数读取影像分块并计算它们对应的上层金字塔对应的编码号,键为影像分块的编码号,值为影像分块文件;Reduce函数结合猫群算法对构成该层金字塔的影像分块进行抽样处理生成新的影像块。总的来说就是通过(2I+4)2→1影像块的新映射关系运用MapReduce得到金字塔第1层、第2层...第I层。其中总体的并行构建流程如下图5所示。 图5 影像金字塔并行构建的MapReduce算法 图5所示的是金字塔并行构建的核心流程,从图中可以看出所有寻优范围的金字塔第0层的相邻影像块都经Map函数写入并计算它们对应的上层金字塔对应的编码号(这里仅列出金字塔第1层4个影像块的构建过程),然后通过Reduce函数合并,再结合猫群算法最终得到金字塔第1层影像。 HBase的基本存储单元cell是由行键RowKey、时间戳TimeStamp、列族ColumnFamily组成。其中行键是确定行的标识符,时间戳是保证cell的时间版本特性,列族是预先定义的,并可以根据自己的实际需求定义[20]。由于HBase是按列存储的,即按Key-Value的形式存储,而且对影像数据进行查询时,按照行键、列族和时间戳的顺序进行定位,因此想要快速查询所需要的影像信息,行键RowKey的设计是至关重要的。本文将表的行键设计为,地物标识码+四叉树索引ID,其中地物标识码即不同地物用不同的二进制编码来表示,如树木:00,河流:01,建筑物:10。具体地物标识码用几位二进制表示,可以根据实际需要将影像分为了几种类别来确定。下面是行键这样设计的原因: (1) 设计地物标识码+四叉树索引ID的行键方案,是针对实际中需要快速定位特定影像数据的需求,比如在林火防治领域就需要找到可燃物、水源、道路等,来提前设计好林火扑救方案,以免森林火灾一旦发生,造成扑救不及时而带来的不必要的损失。 (2) 行键和空间对象一一对应,设计地物标识码+四叉树索引ID可以让行键和地物最大限度的对应。 (3) 根据行键长度设计的原则,结合遥感影像数据的特性,将行键的长度定义为32 B(8 B的整数倍),其中ID占16 B。例如某一个空间对象的ID为0001100010010101,地物为建筑物,假如其地物标识码为011(共分为5类,针叶林000、阔叶林001、河流010、建筑物011、其他100)则它的行键设计为:0001100010010101011。 HBase的表结构设计见表1。 表1 HBase的表结构设计 表1中列族1为遥感影像数据信息,包括影像块和经纬度坐标;列族2为存储遥感影像数据的元数据信息,其中包括分辨率、精度和数据源。 HBase数据库是按列存储的,而按列存储的本质含义就是按照Key-Value的形式进行存储。所以本文通过HBase与MapReduce相结合来实现影像数据的并行入库,从而提高入库效率。本文HBase键值对中不同字段的排列如图6所示。 图6 HBase键值对中不同字段的排列 由图6可以看出本文的键Key依次由行键、列族和时间戳组成,值Value就是cell所对应的值。 本实验采用虚拟软件XenServer6.2将3台曙光 I450-G10塔式服务器(InterXeon E5-2407四核2.2 GHz处理器,8GB内存)虚拟成6台主机,一台HP Compaq dx2308(Intel Pentium E2160 1.8 GHz处理器,1GB内存)作为Master。具体的软件配置见表2。 本文实验数据来源有两个:其中1幅高分辨率影像数据来自于国产卫星高分二号GF-2,研究区位于大兴安岭,大兴安岭全长1 200 km,宽200~300 km。此遥感影像包括0.8 m的全色单波段和3.2 m分辨率的多光谱波段,具有4个标准波谱段( 红、绿、蓝、近红外) 。其地理位置是:东经123°76′31.81″~124°16′10.30″,北纬 50°02′10.21″~50°27′02.73″。该一景图像成像时间为2015年7月14日02∶57。它的全色中心波长为0.814 0 μm,多光谱:蓝光波段(Band1)中心波长0.502 0 μm,绿光波段(Band2)中心波长0.576 0 μm,红光波段(Band3)中心波长0.680 0 μm,近红外波段(Band4)中心波长0.810 0 μm;另一幅影像来源于Landsat 8卫星,研究区位于河南信阳。地理位置是:东经113°32′12.10″~114°25′12.33″,北纬 31°43′20.33″~32°38′36.94″。成像时间为2016年4月27日08:52。此遥感影像包括9个波段,空间分辨率为30 m,其中包括一个15 m的全色波段,成像宽幅为185 km×185 km,其中光谱信息为:Band5波段为(0.845~0.885 μm),全色波段Band8波段范围较窄,蓝色波段Band 1波段为(0.433~0.453 μm) ,短波红外波段Band 9波段为(1.360~1.390 μm) 。 表2 软件配置表 在数据的完整性实验中,本文选取大兴安岭和信阳影像的1/64大小(706×706像素)的且已经标记好地物的遥感影像图。为了验证研究方法的完整性,本文分别对2幅影像进行128×128、256×256、512×512、1 024×1 024分块,然后利用猫群算法分别得到368×353像素大小的影像,其原始影像和猫群寻优后的影像分别如图7所示。最后在各影像中随机选取100个点和原始图像对应的100个点进行相似度比较,重复3次,取平均值。发现影像分块越精细,数据的完整性就越好,实验结果图如8所示。 (a)(b)(c)(d) 图7 猫群算法寻优后影像图 图7(a)为大兴安岭地区的1/64大小的且已经标记好地物的遥感影像图,图7(b)为(a)经过猫群算法以1∶4的比例构建出来的影像,图7(c)为河南信阳地区的1/64大小的且已经标记好地物的遥感影像图,图7(d)在(c)基础上经过猫群算法以1∶4的比例构建出来的影像。 由图8(a)、(b)可以看出,运用猫群算法对金字塔进行构建不会损失大量的数据,数据的完整性可以得到保证;并且随着影像分块数目的增多,猫群算法寻优构建金字塔的完整性也越来越好。运用猫群算法后信阳地区的数据完整性明显高于大兴安岭地区的原因经分析是类别比较集中且每个类别范围相对较大。 在数据的存储实验中,本文选取3幅高分二号卫星的遥感影像图,经处理影像数据的大小分别为623 MB、1.49 GB和3.21 GB。分别对上述3幅影像进行并行金字塔的构建和数据的并行写入实验。 为了验证本文提出算法的有效性,分别对不同大小的遥感影像进行并行的构建金字塔。由图9可知,本文提出的并行构建金字塔的方法所需时间要远远小于传统方法。当数据量逐渐增加时,传统构建金字塔的方法所需时间增加幅度较大而本文的并行构建方法时间虽然有所增加但是幅度较小,由此可看出本文提出的方法有效地减少了金字塔构建所需的时间。 在金字塔创建完成后,为了验证本文提出方法的可扩展性分别对上述3幅图像进行数据的导入。研究在随着处理节点的增加,本文采用的并行处理方法加速比的差异,其中加速比为: speedup=T1/Tp (12) 式中:T1为单处理器下的运行时间,Tp为p个处理器的并行运行时间。变化趋势如图10所示。 图9 影像金字塔并行构建 图10 加速比对比图 由图10的实验结果可知,当实验数据较少时并行算法的加速比效果并不是很理想,数据导入时间几乎不变,但是随着数据的增大加速比逐渐增大,数据写入的时间减少,本文提出的并行方法效率提高。这主要是因为,数据量较少时在HBase上存储时需要划分的region数量较少,数据只存在固定的几个节点中,从而导致数据导入时间变化不大。但是,随着数据量的增大HBase需要的region数量增多,这时不同的节点均可写入到HBase中,并行算法加速效果比较明显。 在进行数据的查询实验时,本文选择image3影像中分辨率最高的一层中地物标识为针叶林的影像块作为查询对象,分别将整幅影像占比为10%~70%作为输入的查询范围,测试数据包含的文件数量从6 554张到45 875张。实验结果如图11所示。由图可见,在查询范围较少时本文改进行键的设计方法和行键中不加地物标识码的方法查询时间相差不大,并且后者的查询性能要优于本文方法。但是随着查询范围的增加本文方法的查询时间增长较慢,且查询时间要低于后者的方法。 以HBase分布式数据库为工具,采用线性四叉树构建影像金字塔来解决遥感影像大数据的存储效率低及查找速度慢等问题。实验中为减小金字塔构建中分辨率的损失,利用猫群算法和MapReduce并行处理架构相结合来构建金字塔,不仅相对提高了金字塔上层影像的清晰度,同时还提高了数据的存储性能。实验通过对RowKey的设计,有效地提高了数据的读取性能。本研究将为遥感影像的存储及特征识别等应用提供借鉴和参考。 图11 索引改进前后实验对比图1.3 MapReduce并行构建金字塔


2 影像数据的分布式存储

3 实验分析与评估
3.1 实验环境及数据

3.2 数据完整性比较



3.3 影像数据的并行存储
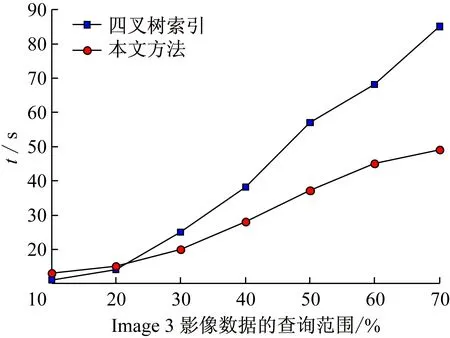
3.4 影像数据的并行查询
4 结 语