基于网格筛选的大规模密度峰值聚类算法
2018-11-13丁世飞孙统风廖红梅
徐 晓 丁世飞 孙统风 廖红梅
(中国矿业大学计算机科学与技术学院 江苏徐州 221116) (xu_xiao@cumt.edu.cn)
信息技术的飞速发展以及互联网的普及,使得数据更新速度快、数据源多样、数据量以空前的速度增长.面对大规模数据存储难、计算复杂度高等一系列的问题,如何对大规模数据集进行有效的数据挖掘、快速获取有价值的信息,已经成为人们研究的焦点[1].聚类学习是一种重要的数据分析技术,能从复杂的数据中发现有用的信息[2-3].可以先对数据进行聚类,根据数据对象的相关特征,将相似的对象归到同一类中,而差别较大的对象划分到不同类中,找到数据之间的内在联系,为决策提供支持.聚类分析在市场分析、模式识别、基因研究、图像处理等领域具有一定的应用价值[4].
2014年Rodríguez和Laio[5]提出了一种新的密度峰值聚类算法(density peaks clustering algorithm, DPC).聚类中心具有2大特点:1)聚类中心本身的密度较大,即被密度均不超过它的邻居包围;2)聚类中心与其他密度更大的数据点之间的“距离”相对更大.DPC利用上述2大特点绘制决策图,找到聚类中心,然后对剩余的点进行高效分配[6].由于聚类中心是密度和距离2个属性值均较大的点,所以称之为密度峰值,该算法称为密度峰值聚类算法.密度峰值聚类算法可以用于不同形状数据的聚类分析,不需要预先设定类簇数,通过决策图快速发现密度峰值,得到比较满意的聚类结果.
尽管密度峰值聚类算法在规模较小的数据集上表现很好,但是它依旧存在多方面不足:1)在计算局部密度时没有采用统一的密度度量标准,参数dc的选取对聚类结果影响较大.2)如果数据点的个数n很大,密度峰值聚类算法将会把所有点都作为选取聚类中心的候选数据点.计算n个点的局部密度和距离属性都依赖于点与点之间的相似度矩阵,需要的时间复杂度为O(n2),时间开销会严重降低聚类的处理效率.同时,存储相似度矩阵需要的空间复杂度也是O(n2),因此,对于密度峰值聚类算法而言,可供使用的内存空间将是其处理数据规模的上限.对于通常的计算设备来说,内存空间毕竟有限,这将使得密度峰值聚类算法失去处理较大规模数据的能力.
当前,在密度峰值聚类算法研究领域,针对第1个弊端的研究居多.Du等人[7]提出DPC-KNN聚类算法,其将KNN的概念引入到密度峰值聚类算法中,dc的选取不局限于局部,使局部密度的计算有另一选择.Xie等人[8]利用样本点的KNN信息定义样本局部密度,搜索和发现样本的密度峰值,以峰值点作为初始类簇中心来改进密度峰值聚类算法.Zhou等人[9]提出一种名为3DC的聚类算法,是密度峰值聚类算法的改进版本.3DC算法由分治策略和DBSCAN框架中密度可达性概念驱动,考虑数据的全局分布,递归地找到正确的簇数.但是对于第2个弊端的研究甚少.仅在2015年巩树凤和张岩峰[10]提出一种高效的分布式密度中心聚类算法(EDDPC),它利用Voronoi分割与合理的数据复制及过滤,避免了大量无用的距离计算开销和数据传输开销.Zhang等人[11]提出一种在MapReduce上聚类大数据集的高效分布式密度峰值聚类算法,利用局部敏感Hash进行分区数据的近似算法,执行本地计算,并聚合局部结果近似最终结果.然而,采用分布式虽然在一定程度上解决了大规模高维数据的计算复杂度问题,但在每次迭代过程中,节点间传送大量的数据带来巨大的通信代价,其远远大于计算代价,总体效率较低[12].同时,分布式计算涉及多台计算机,而且都依赖网络通信,因此1台或者多台计算机,1条或者多条网络出现故障都将影响分布式系统,而且一旦出现问题不易排除[13-14].对于大规模数据的处理任务,抽样的策略是通常的选择,然而随机抽样往往会产生糟糕的聚类结果,同时抽样的规模多大才能覆盖原数据集的所有自然簇等问题难以解决[15].SVM通过挑选位于分类超平面附近的训练样本作为最终的训练集,从而在确保分类器准确率的情况下实现训练过程加速,本文受此启发[16],设计一种新颖的基于网格筛选的方法.先利用网格化方法筛选去除密度稀疏的点,然后计算剩余点的局部密度和距离属性寻找聚类中心.由于密度稀疏与聚类中心局部密度大的特点违背,去除的点一定不会是聚类中心,不会影响聚类中心的选取.然后在筛选后的数据集上绘制决策图选取聚类中心,有效降低聚类的计算复杂度.基于此,提出一种基于网格筛选的密度峰值聚类算法(density peaks clustering algorithm based on grid screening, SDPC),并从理论上证明该算法可以有效提高密度峰值聚类算法的运行效率,获得令人满意的聚类结果.
1 密度峰值聚类算法原理
密度峰值聚类算法是一种新提出的聚类算法,该算法可以创建任意形状的集群,而不考虑它们被嵌入的空间维度并且有效地排除异常值,应用前景广泛[17-18].算法中心思想基于这样一个假设:对于一个数据集,聚类中心被一些低局部密度的数据点包围,而且这些低局部密度的点距离其他高密度的点的距离都比较大.算法首先对每一个数据点i赋予2个属性:点的局部密度ρi和该点到具有更高局部密度的点的距离δi,局部密度ρi定义为
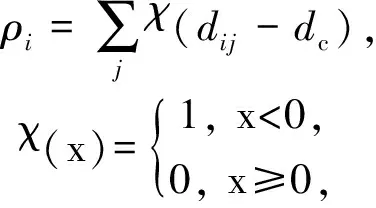
(1)
其中,di j表示数据点xi和xj的距离.dc表示截断距离,是密度峰值聚类算法的唯一输入参数,在作者的代码中定义为
dc=dNd×2%,
(2)
其中Nd属于每2个点之间的所有距离的集合,其以升序排序.因此,ρi等于与点i的距离小于dc的点的个数,其也被定义为所呈现的代码中的高斯核函数:
(3)
数据点i的δi是点到任何比其密度大的点的距离的最小值,即:

(4)
对于密度最大的点,我们可以得到:

(5)
DPC算法选择ρi和δi均大的值作为聚类中心.例如图1(a)表示嵌入二维空间中的28个数据的分布,数据点按照密度递减的方式排列;图1(b)是密度峰值聚类算法根据图1(a)中数据绘制的决策图.根据图1(b),我们把密度和距离都较大的点1和点10作为聚类中心.

Fig. 1 Decision graph of the density peaks clustering algorithm图1 密度峰值聚类算法决策图
DPC算法具体步骤如算法1所示:
算法1. DPC聚类算法.
输入:数据集X={x1,x2,…,xn}、参数dc;
输出:聚类结果Y.
Step1. 计算所有点与点之间的距离di j,构建相似度矩阵;
Step2. 基于Step1构建的矩阵和用户输入的参数dc,计算每个数据点的局部密度ρi和高密度距离δi;
Step3. 依据Step2计算的数据点属性绘制决策图,并根据γi=ρi×δi选择2个属性都大的点作为聚类中心;
Step4. 剩下的点按照“最近邻”算法,将“当前点”归于密度等于或者高于“当前点”的最近点一类;
Step5. 去除当前类别中小于边界阈值的噪声孤立点;
Step6. 返回结果矩阵Y.
注意到,密度峰值聚类算法最大的优势在于根据聚类中心的两大特点绘制决策图,选择聚类中心[19].但是聚类中心的选择依靠局部密度ρi和距离δi,而这2个值都取决于数据点间的距离di j,当数据集规模较大时,计算量非常大,以样本数的二次幂规模增长,内存需求极大.一种可行的解决方法是通过网格筛选,先去除密度稀疏不可能成为聚类中心的点,然后利用剩余的点进行决策图绘制.虽然会损失一部分数据信息,但由于筛选的点均为密度稀疏的点,不影响聚类中心的选取,在保证聚类准确率的基础上极大地降低了计算复杂度.
2 基于网格筛选的密度峰值聚类算法
2.1 算法描述
一种改进的基于网格筛选的密度峰值聚类算法(SDPC)的提出目的是降低原DPC算法的计算复杂度,使该算法不受数据集大小的限制.本文算法基本思想:引入稀疏网格筛选的方法,去除一部分密度稀疏即不可能成为聚类中心的点,只保留稠密网格单元中的点作为候选集进行聚类中心的选取.虽然引入网格筛选的方法会损失部分数据信息,但由于密度稀疏网格中的数据点局部密度均较小,与聚类中心局部密度较大的特点矛盾,因此筛选的点不会成为聚类中心,去除并不影响聚类中心的选择.例如,假设对数据规模为n的数据集X={x1,x2,…,xn}进行网格划分,并筛选去除“稀疏”网格,只对“稠密”网格包含的m(m≪n)个元素进行聚类,则新数据集A={a1,a2,…,am},ai∈X的聚类中心和数据集X的聚类中心基本相近,从而保证了聚类的准确性.
SDPC算法首先以网格来划分数据空间,将数据集映射到网格单元;然后利用数据在网格中分布的不均匀性,选出“稀疏”网格和“稠密”网格,通过设定筛选比例,把“稀疏”的网格单元去除;集中精力考虑剩余网格中的数据点,使用DPC算法中绘制决策图的方法确定聚类中心;最后将剩余的点归到密度大于它的最近类中.该算法有效降低了时间复杂度和内存需求,具体步骤见算法2.
定义1. 网络边长.假设存在一个d维数据集,第i维上的值在区间[li,hi)中,i=1,2,…,d,则S=[l1,h1)×[l2,h2)×…×[ld,hd)就是d维数据空间.对数据空间的每一个维度进行划分,将其划分成边长相等且互不相交的网格单元,为了提高计算效率和聚类效果,本文进行几何平均数的求解,定义网格的边长ξ:
(6)
其中,a为比例系数,用来调整控制网格边长大小.本文实验数据表明:当a∈[0.5,1.5]时,网格能得到合适的划分进行筛选,并且能够获得较好的聚类效果.
定义2. 单元格密度.假设将数据集X={x1,x2,…,xn}映射到对应的网格单元中,按照定义1中ξ将数据空间划分为{u1,u2,…,un}网格单元,则单元格ui的密度为
ρui=count(Gui),
(7)
其中,count(Gui)表示统计网格编号为Gui的单元格中点数.
算法2. SDPC聚类算法.
输入:数据集X={x1,x2,…,xn}、筛选比例a;
输出:聚类结果Y.
Step1. 按照定义1划分数据空间,将数据点X={x1,x2,…,xn}映射到对应的网格单元;
Step2. 根据式(7)计算每个网格密度,并按照网格密度进行从大到小排序;
Step3. 按比例a筛选去除“稀疏”网格,只保留可能成为聚类中心的样本点,形成新的数据集A={a1,a2,…,am};
Step4. 计算数据集A中两两样本间距离;
Step5. 根据式(3)和式(4)计算A中每个样本的ρi和δi值;
Step6. 从由ρi,δi构成的决策图中选择k个聚类中心;
Step7. 使用算法1中分配策略将数据集A中的其余数据点归于密度等于或者高于“当前点”的最近点一类;
Step8. 将Step3筛选出的n-m个数据点,按照“最近邻”原则归到最近中心点一类;
Step9. 返回结果矩阵Y.
2.2 算法复杂度分析
密度峰值聚类算法的核心思想是根据聚类中心的两大特点绘制决策图寻找聚类中心,本文算法保留了此选择聚类中心的方法,但本文算法却只需要在筛选过的m个点中寻找聚类中心,计算复杂度远远小于原密度聚类算法,尤其当n特别大的时候.
对样本规模为n的数据集,原密度峰值聚类算法存储两两之间距离矩阵的空间复杂度为O(n2),也是该算法空间复杂度的主要来源.本文算法只需对筛选剩下的m个点存储相似度矩阵,空间复杂度O(m2)≪O(n2).同时,本文算法比原密度峰值聚类算法增加了筛选去除的每个样本到每个聚类中心的距离,但增加的空间复杂度不超过O(|CL|(n-m)),而且表示类簇数的|CL|通常较小,因此,本文算法的空间复杂度一定比原密度峰值的空间复杂度小.
与原密度峰值聚类算法相比,本文引入网格筛选的概念,需事先利用网格划分去除部分密度稀疏一定不是聚类中心的点,但此事件的时间复杂度几乎可以忽略.另外,获得聚类中心后,本文算法需对开始筛选去除的n-m个点进行分配,这些点在原密度峰值聚类算法中需要O((n-m)2)的时间复杂度计算其ρi和δi属性,本文算法只需要计算其与聚类中心的距离,时间复杂度一定小于O((n-m)2),为节省时间做出贡献.假设n表示数据集中样本点的个数,本文算法的时间复杂度由以下4部分决定:1)用O(n)的时间划分数据空间,将数据映射到网格单元中;2)使用快速排序的方法,O(ulgu)的时间按比例筛选稀疏的网格单元,u(u≪n)表示非空网格单元个数;3)对筛选过后剩下的m(m≪n)个点进行密度峰值聚类,时间复杂度为O(m2);4)分配筛选去除的点到k个聚类中心的距离,时间复杂度不超过O((n-m)2).所以本文算法时间复杂度不超过O(n)+O(ulgu)+O(m2)+O((n-m)2),由于m≪n且u≪n,其总的时间复杂度一定小于DPC算法.
3 实验与分析
3.1 实验设计
为了证明SDPC算法的聚类性能,实验采用经典人工数据集和UCI数据集对本文算法进行测试和评价.我们将通过合成数据集的可视化来比较SDPC算法与DPC算法的精度以及运行效率.除了DPC之外,SDPC在UCI数据集的性能还与在高维数据集上效果较好的标准谱聚类(NJW-SC)[20]、基于Nystrom的低秩近似谱聚类(Nystrom-SC)[21]以及2种改进的DPC-KNN算法[7]和FKNN-DPC算法[8]进行比较.本文使用聚类精度(Acc)来测量聚类结果的质量.对于N个不同样本集xi,yi,zi是xi,yi和zi的固有类别标签和预测类别标签,Acc计算为
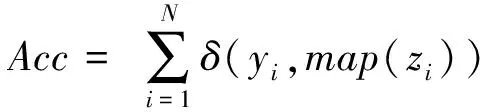
(8)
其中,map()通过Hungarian算法将每个簇标签映射到类别标签,并且该映射是最优的.Acc的值越高,聚类性能就越好.在实验中,DPC和SDPC算法参数dc的选择参考文献[5]取1%~2%,DPC代码由文献[5]的作者提供.该文中算法均通过10次试验尝试获取最优参数,并且实验展示的结果都是其平均结果.
仿真实验在Inter core i5、双核CPU、内存4 GB、Windows7的操作系统和MATLAB 2010的环境下进行.
3.2 实验结果分析
3.2.1 人工数据集实验结果分析
本节对6组人工数据集进行算法测试,实验数据特征如表1所示.数据集A2和A3分别包含7 500个和5 250个数据点,具有变化数量簇(M=50,35)的2维集合.S2数据集包含15类、5 000个数据点,呈复杂性空间分布.Five Cluster数据集共有4 000个数据点,5个类分别具有不同的大小和形状.Twenty和Forty分别是有20和40类的数据集,均匀分布在数据空间.

Table 1 Characteristic of Artificial Datasets表1 人工实验数据特征
实验首先将数据集按照不同的数据分布,映射到不相交的网格单元中;然后计算网格单元的密度,筛选去除密度稀疏网格中数据点.这里由于数据集规模较大和数据分布较紧密,所以筛选比例直接取70%,留下30%的“稠密”网格;然后用DPC算法在留下的数据集上选取正确的聚类中心;最后分配剩余点以及筛选去除的点.SDPC算法的聚类结果如图2~7所示.
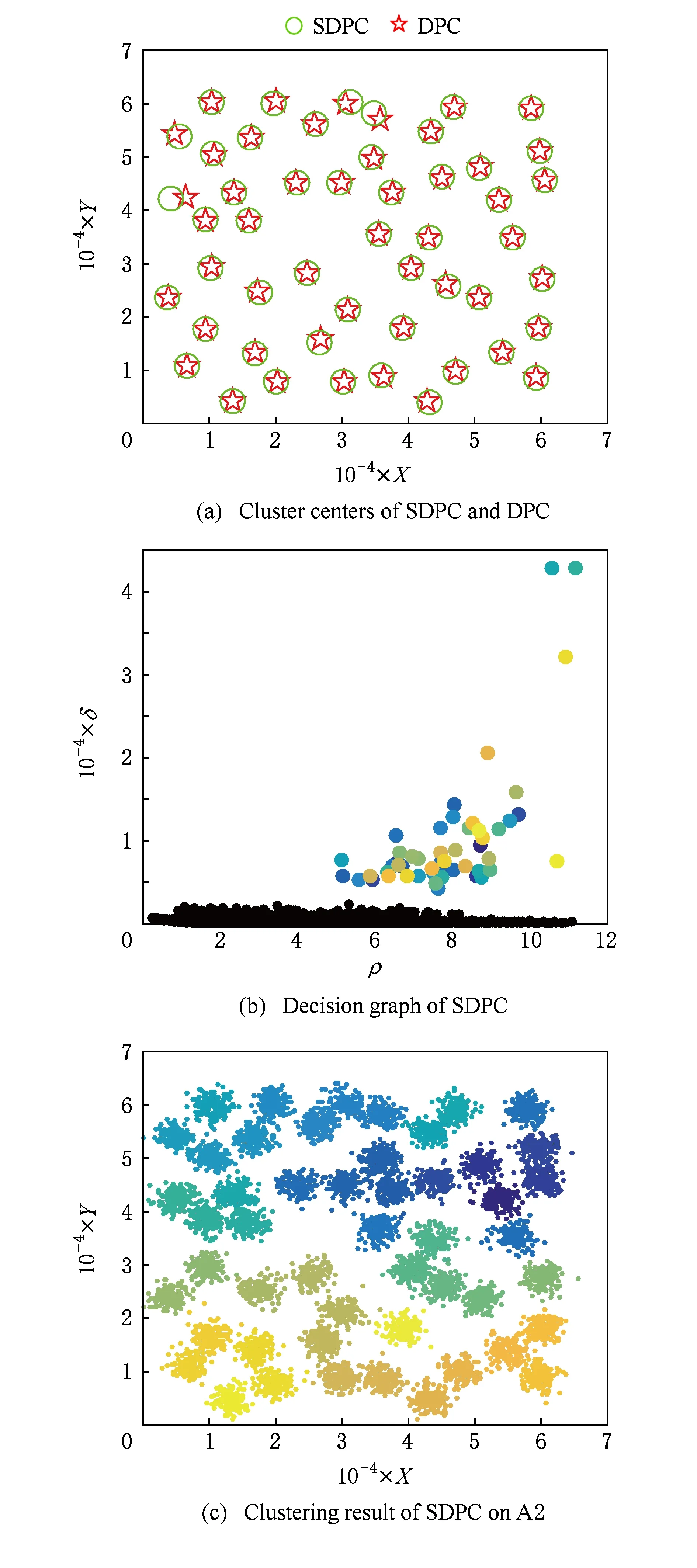
Fig. 2 Clustering results of A2 by SDPC图2 SDPC对A2数据集的聚类结果

Fig. 3 Clustering results of A3 by SDPC图3 SDPC对A3数据集的聚类结果

Fig. 4 Clustering results of S2 by SDPC图4 SDPC对S2数据集的聚类结果
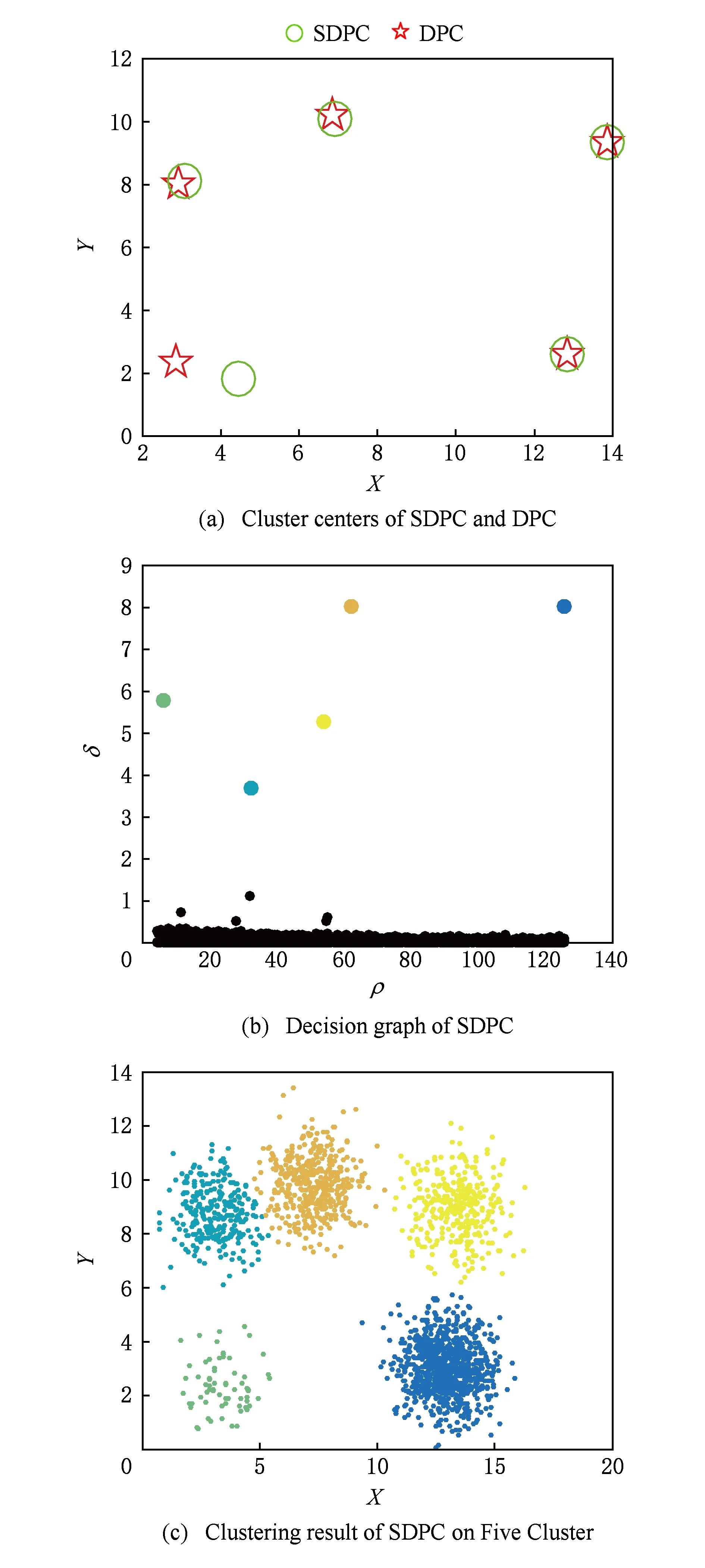
Fig. 5 Clustering results of Five Cluster by SDPC图5 SDPC对Five Cluster数据集的聚类结果

Fig. 6 Clustering results of Forty by SDPC图6 SDPC对Forty数据集的聚类结果
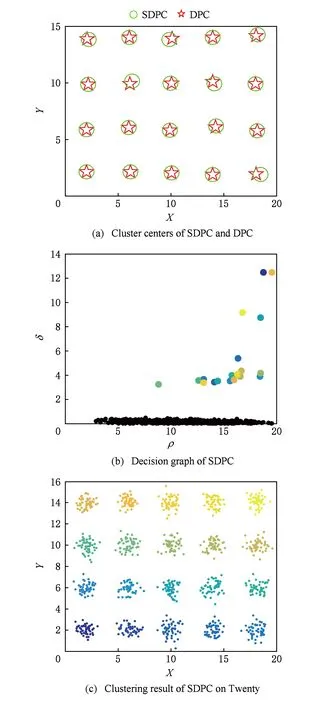
Fig. 7 Clustering results of Twenty by SDPC图7 SDPC对Twenty数据集的聚类结果
图2(a)~图7(a)表示DPC和SDPC在各个数据集上的聚类中心图,“☆”表示DPC的聚类中心,“○”表示SDPC的聚类中心.从图2(a)~图7(a)中看出,2个算法的聚类中心很接近,因此可以说明筛选去除密度稀疏网格单元中的数据并不影响聚类中心的选取.图2(b)~图7(b)分别是SDPC在这6组数据集上的决策图.进一步可以证明SDPC保留了DPC选取密度峰值的方法,可以准确找出聚类中心.图2(c)~图7(c)是SDPC的聚类结果图,可以看出SDPC均有令人满意的聚类结果.虽然DPC在这6组数据集上也表现出良好的聚类性能,但随着数据规模的增大,其时间消耗呈指数上升,如表2所示.
从表2中可以看出,SDPC在这6个数据集上运行时间明显低于DPC.DPC依靠计算所有点的局部密度和距离属性寻找聚类中心,计算复杂度较高.而本文SDPC算法采用网格筛选的方法,只考虑从高密度数据集中选取聚类中心,计算复杂度将大幅度下降.随着数据规模的增大,SDPC的优越性越明显,如图8所示.从图8可以看出,数据集越大,SDPC比DPC快得越明显.这在一定程度上说明SDPC算法能够较好地处理大规模数据集,在保证聚类准确率的同时有效降低了时间复杂度,提高了DPC的运行效率.

Table 2 Clustering Time of SDPC and DPC on Different Datasets
3.2.2 UCI数据集实验结果分析
本节分别采用表3中6组UCI数据集验证本文SDPC算法的聚类性能.Iris是最常见的数据集,包含150个样本点、3类.Seeds包含3类小麦种子,每个样本有种子的7个属性描述.Waveform包含3类波形,每类各占33%.Ring Norm数据集中2类样本分别呈现有部分重叠的不同正态分布.Pen Digits和Gamma是2个包含10 000个以上样本的大规模数据集.
由于高维数据在数据空间中分布稀疏,这里进行SDPC算法测试时,根据数据集大小的不同,随机选取不同的比例进行筛选,然后进行聚类中心的查找.分别计算在各情况下SDPC算法的准确率以及运行时间,与DPC以及Nystrom-SC,NJW-SC,DPC-KNN,FKNN-DPC进行对比.Nystrom-SC算法在大规模数据集上均取50%的样本点,并取最好的实验结果.SDPC以及各对比算法的聚类准确率和运行时间分别如表4和表5所示(“-”表示内存不足,无法进行实验).

Table 3 Characteristic of UCI Datasets表3 UCI实验数据特征
从表4中可以看出,本文SDPC算法由于保留了DPC算法选取聚类中心的方法,所以聚类的准确率同其他5种算法相比还算令人满意.DPC以及其他对比算法在较小规模的数据集上可以正常运行,但当处理Pen Digits等大规模数据集时,会提示内存不足而无法聚类.因为DPC需要所有数据点之间的相似度,空间复杂度为O(n2),当数据量很大时,存储数据点的局部密度和距离属性需要很大的内存空间.而本文算法采用网格筛选的方法,只需要计算部分数据之间的相似度,空间复杂度大幅度降低,所以可以在有限的内存里进行大规模数据集的聚类.从表4中可以看出,大部分情况下,随着筛选比例的减少,即保留数据集的增大,SDPC的准确率会逐渐增加,这是由于保留的数据集越多,聚类中心的选择越准确.
表5中,在小规模数据集上,SDPC算法和DPC算法的运行效率相当;但随着数据规模的增大,SDPC算法明显优于DPC算法,当数据规模达到上万时,本文算法仍然保持着良好的性能.因为SDCP只计算了部分数据之间的相似度寻找聚类中心;而DPC计算了所有数据之间的相似度,时间复杂度很高.随着筛选比例的增加,SDPC的速度越来越快.而Nystrom-SC和NJW-SC以及改进的DPC算法虽然在小数据集上有着不错的聚类效果,但在大规模数据集上,消耗时间太长,影响聚类效率.综合考虑聚类准确率以及运行时间,本文SDPC算法在大规模数据集上更有优势,适合大数据环境下的数据挖掘.

Fig. 8 Clustering time of DPC and SDPC on different datasets图8 DPC和SDPC算法在不同数据集上的聚类时间

DatasetsSDPCScreening RatioAccuracySDPCDPCDPC-KNNFKNN-DPCNystrom-SCNJW-SC0.30.9400Iris0.20.94000.94000.96000.97300.88000.88670.10.94000.30.8762Seeds0.20.87620.85240.91430.92400.89520.93810.10.87620.70.6072Waveform0.50.62180.58080.58400.70300.61800.61860.30.61000.70.5104Ring Norm0.50.52310.50850.50820.51000.50570.94690.30.62090.70.4200Pen Digits0.50.42000.30.42050.70.5110Gamma0.60.51100.50.5248

Table 5 Clustering Time of Different Algorithms on Different Datasets表5 各算法在不同数据集上的聚类时间
4 结束语
求解密度峰值聚类算法将所有样本点作为聚类中心的候选数据集,依赖于计算所有数据点的局部密度和距离属性,时间复杂度和空间复杂度均为O(n2),无法处理大规模数据集.本文算法引入网格筛选的方法,通过将数据点映射到对应的网格中,根据数据分布去除局部密度较小的点,只保留有效数据集绘制决策图寻找聚类中心,很大程度上降低了时间开销以及空间开销.本文从理论上证明了网格筛选可以有效降低计算复杂度.经典人工数据集和UCI真实数据集的实验结果表明:本文算法优于传统的密度峰值聚类算法,既保持了原有算法寻找聚类中心的准确性,又降低了计算复杂度,能较好地处理大规模数据集.
无论是原密度峰值聚类算法还是结合了网格筛选方法的密度峰值聚类算法,在选择聚类中心时,依然需要依靠用户的经验,进一步探索是否可以使选择更加可靠简单.
