邻域粗糙集约简算法在图像特征选择中的应用
2018-11-13续欣莹
成 婷,张 扩,续欣莹
(太原理工大学 信息工程学院,山西 晋中 030060)
0 引 言
当前社会的数据迅速地增长,且数据处于动态更新的状态,需要高效准确地处理这些新增样本是研究的重点。文献[1]提出邻域关系模型,文献[2-3]改进了该模型,提出代数观下基于邻域模型的数值型数据属性约简算法,但该算法为静态约简算法。现在已经有学者在其基础上提出动态约简算法,这些算法都从代数观分析其动态更新过程。而通过文献[4]可知信息观在不一致决策方面要优于代数观。因此,从信息观研究基于邻域粗糙集的动态约简算法具有重要的理论意义。
行人检测在计算机视觉等领域有着重要的应用[4-6]。目前基于计算机视觉的行人检测大多是基于特征提取和机器学习的方法[7-9]。运用特征描述行人与背景的区别。经过这些年的科学发展,学者已经提出很多有效的行人检测算法,如 HOG[10],LBP[11],CSS[12],EOH[13],Edgelet[14],Shapelet[15]等。
在以上这些特征中,最具代表性的为Dalal等提出的HOG特征,利用图像得到相关区域的梯度直方图对行人进行描述。但该特征在某些方面也存在着不足之处:向量维数高、计算所需时间较长。
针对上述问题,本文提出一种基于增量式场景图像特征选择的邻域粗糙集约简算法,该算法在增加图像样本后利用HOG特征,求出原图像集的条件熵,给出新增样本后条件熵的计算公式,当原图像样本约简集失效时,可以知道是新增的图像样本集中的某个或者某些样本使得条件熵发生了改变,再进行约简时,只需得到这些样本以及它们的不一致邻域,然后进行约简,最后再反向剔除原约简集中的冗余特征,得出最终的特征集。
1 相关知识
定义 1[16]:给定有限集合U={u1,u2,…,un},δ> 0,对于U上任意对象ui,定义其δ邻域为:δ(ui)={ |uΔ(u,ui)≤δ},其中距离函数Δ满足:
1)Δ(u1,u2)≥0,Δ(u1,u2)=0当且仅当u1=u2,∀u1,u2∈RN;
2)Δ(u1,u2)=Δ(u2,u1),∀u1,u2∈RN;
3)Δ(u1,u2)≤Δ(u1,u2)+Δ(u2,u3),∀u1,u2,u3∈RN。
定理1:样本的相似性可以通过距离函数衡量,两个样本的距离越近越相似,两个样本的距离越远越不相似。
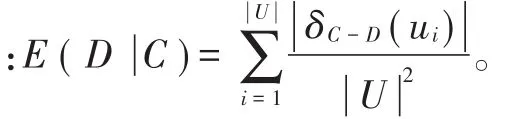
定理2[17]:同定义2设定NDT,M⊆C,则M为C中的约简的条件为
定义3[3]:同定义2设定NDT,B⊆C,对∀a∈C-B,a相对于B的重要度定义为:
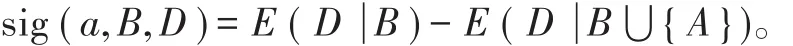
2 增量式特征选择
2.1 基于条件熵的属性约简
文献[18]提出基于信息熵的属性约简算法(简称为ARACE算法),该算法是基于信息熵下的启发式约简算法,算法流程图如图1所示。

图1 ARACE算法流程图Fig.1 Flowchart of ARACE algorithm
文献[19]在文献[18]的基础上对算法进行改进,给出新的信息熵模型,提出ADEAR算法,该算法能够得到更好的约简结果以及约简精度。
2.2 基于邻域系统下条件熵的增量式属性约简
2.2.1 批量增加样本后条件熵的计算公式
定义4:同定义2设定NDT,B⊆C是条件属性集,为属性B的条件熵,δB(x)为样本x在属性集B上的邻域,δD(x)为样本x在属性集B上的决策类,增加一个样本x后,新的条件熵为:

推论1:同定义4的设定条件,当批增加m个样本Um后,得到的条件熵为:
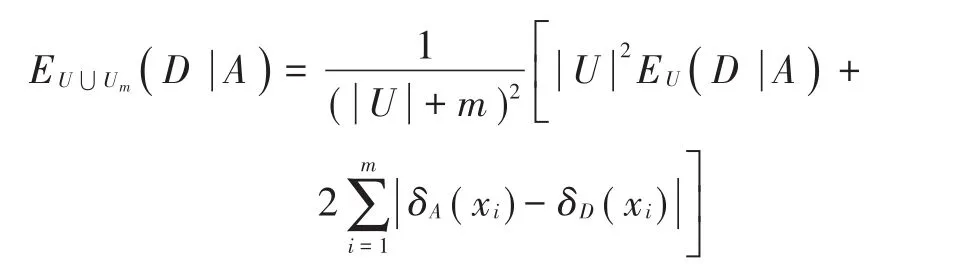
证明:用迭代法进行求证。

当加入其中一个样本后,条件熵变为:

令U1=U∪{x1},再加入一个样本后,条件熵变为:

最后当增加第m个对象xm后,条件熵变为:

2.2.2 批量增加样本后约简算法分析
批量增加样本之后,可以利用上述的条件熵公式,再通过基于信息熵下的属性约简算法对新增样本后的样本集进行属性约简,接下来对算法进行相关分析。
定理3:同定义2设定NDT,原约简集red0,增加的样本集x,当新增样本在red0下不存在不一致邻域,新样本集下的约简集为red0。
证明:由 red0⊆ C,得到δred0-D(x)⊆δC-D(x),如果δC-D(x)为∅,则δred0-D(x)为∅,即:
EU⋃{x}(D| RED0)=EU⋃{x}(D|C),red0为新样本集下的约简集。
定理4:同定义2设定NDT,原约简集red0,当red0不再有效,运用算法得到新约简集red1,并将red0冗余去除得到red2,则red2⋃red1为新约简集。
证明:red0可以区分U-δred0-D(x),而 red2可区分δred0-D(x),所以red2⋃ red1可区分U⋃{x}。
2.3 HOG特征提取
在计算HOG特征时,首先提出HOG描述子概念,它由图像划分出互相不相交的像素块(cell)表示,进而通过相关公式计算梯度方向来描述图像中的局部特征[8]。
将图像分成m×t个cell块,将n×n的cell组成一个block块,相邻的block块可以重叠,这样block块之间能够衔接起来,而不是彻底划分开。然后将各block块中cell的梯度方向进行归一化处理,经过归一化处理的梯度方向形成了图像的所有的HOG特征。HOG特征提取的具体过程如下:
1)输入图像;
2)将图像划分成cell块;
3)求每个cell的梯度方向;
4)将cell组成bolck块;
5)将block块中的所有梯度方向进行归一化;
6)获得HOG特征。
本次实验选取的图像集是麻省理工学院提供的128×64的Pedestrian Data图像集和128×64 INRIA图像集,其中将Pedestrian Data有目标的图像集作为正样本,将无目标的INRIA图像集作为负样本。HOG特征示意图如图2所示。图像原始维数为128×64,将图像分成16×8个cell,每个 cell是8×8像素,每2×2个 cell组成一个 block块,那么总的block块数为15×7=105块。梯度方向选择为每20°一个分区,一共180°,所以一个cell可以得到9维HOG特征,一个block块得到36维HOG特征,一幅图像包含105块block,那么总HOG特征为105×36=3 780维。
虽然图像集能够提取3 780维特征,但是特征集存在大量的冗余,极大地影响了运行的速度,浪费了大量不必要的时间。为此需要运用2.2节提出的基于邻域系统下条件熵的批增量式属性约简算法,对特征集进行选择。
2.4 基于邻域系统下条件熵的增量式属性约简在场景图像下的应用
由于图像集采用的HOG特征具有高维的特点,如果直接采用ARACE,ADEAR算法,约简过程会需要很长的时间,使得特征选择的思想失去了意义,此时需要将该算法进行改进,使算法能够迅速地处理高维特征的数据集。采用2.2节提出的算法能够解决上述问题,将该算法应用到图像集的特征提取中,能够显著提升约简时间、约简精度等。算法的特征选择大体流程如下所示:
1)从2.3节得到图像集的HOG特征;
2)以block块为单位进行约简,得到可以完全表征图像的 block块;
3)对步骤2)得到的block块进行约简;
4)得到最终选择的特征集。
从2.3节可以知道,整个HOG特征由block组成,将每一个block块(36维特征)作为一个单元特征,利用2.2节算法进行约简之后,对约简后得到的block块下的所有特征进行组合,再运用2.2节算法进行约简,最终求得特征集。

图2 HOG特征示意图Fig.2 Diagram of HOG characteristic
2.5 基于增量式场景图像特征选择的邻域粗糙集约简算法描述
通过以上分析,BIIAR算法描述如下:
选取图像集,把图像集打上标签,并将正负样本随机打乱,通过2.3节得到这些图像集的HOG特征,选取部分样本,并将其组成邻域决策系统NDT=<U,C,D>,将C中每36维设为一个block,并对这105维block块进行约简,得到约简集RED,再对RED进行二次约简得到该系统的原特征集red0,条件熵EU(D|C)。同时将剩余样本分成n份,每份设为Xi(i=1,2,…,n)。
输入:邻域决策系统NDT=<U,C,D>,原约简集red0,条件熵EU(D|C),样本集Xi
输出:约简后图像集剩余block块的位置S,特征集red
Step1:初始化距离函数Δ和邻域半径δ
Step2:判断Xi是否为空集

Step3:计算新增样本集Xi在原约简集上的red0不一致邻域δred0-D(Xi)

Step4:计算新增样本集Xi在条件属性集C上的不一致邻域δC-D(Xi)
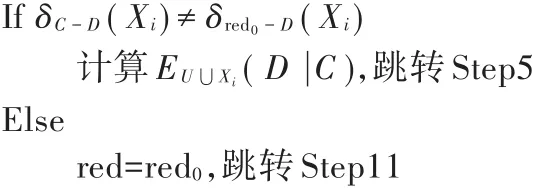
Step5:计算新增样本集Xi在属性集RED上的不一致邻域δRED-D(Xi)

Step6:设δRED-D(Xi)与新增样本集Xi组成样本集Y,计算样本Y在条件属性集C上的不一致邻域δC-D(Y)

Step7:对样本Y建立条件属性为C-RED的临时邻域决策系统,并将C-RED以block块为单元,求该临时邻域决策系统的约简RED1,令REDnew=RED1⋃ RED
Step8:将RED分成block块为Zt(t=1,2,…,n),计算条件熵EY(D|Zt),并按该条件熵大小对Zt降序排列

按照上述排列顺序计算EY(D|REDnew-Zi)

Step9:得出REDnew对应的图像集中block块的位置S
Step10:将U与新增样本集Xi组成样本集W,并建立条件属性REDnew的临时邻域决策系统,并对临时邻域决策系统约简,得到特征集red
Step11:输出red
REDnew对应的block块即为加入样本集Xi后可以完全表征新图像的block块,red为新图像集可以表征图像的特征。
Step8中二次约简的算法流程如下:
输入:将δred0-D(Xi)与新增样本集Xi组成样本集R,样本集W,令E=EW(D|C),REDnew
输出:特征集red
Step1:初始化距离函数Δ和邻域半径δ
Step2:在REDnew中寻找与red0相等的特征,记为F
Step3:计算样本R在条件属性集F上的不一致邻域δF-D(R),

Step4:对样本集R,建立条件属性为C-F的临时邻域决策系统,并求该临时邻域决策系统的约简red2,令red=F⋃red2
Step5:对∀ai∈F计算条件熵EW(D|C),并按该条件熵大小对ai降序排列

按照上述排列顺序计算EW(D|red-{aj})
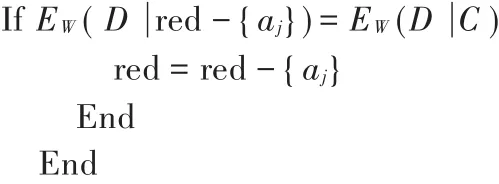
Step6:输出red
算法时间复杂度分析:设U中的样本数为m,Xi中的样本数为m1,原数据集条件属性个数为N,原数据集中含有的block数为N1,原数据集的约简个数为N2,Xi在U下的不一致邻域的样本个数为m2,Xi在RED上的不一致邻域的样本个数为m3,样本m3与Xi不一致邻域的样本个数为m4,REDnew中样本组成的block个数为N3,REDnew中与red0相等的特征个数为N4,RED中样本组成的 block个数为N5,red2中样本的N4个数为N6。

3 实验分析
通过与ARACE算法、ADEAR算法进行实验对比验证BIIAR的准确性和高效性。
3.1 约简情况
图3a)和图4a)表示当邻域阈值δ=0.17时三种算法每次新增样本之后约简后的特征维数和block数,其中图3a)中三条线分别表示三种算法约简后的特征维数,图4a)中三条线分别表示三种算法约简后的 block数。从中可以看出三种算法约简后的block数几乎一致,而且特征维数也很接近,验证了BIINR算法的有效性。
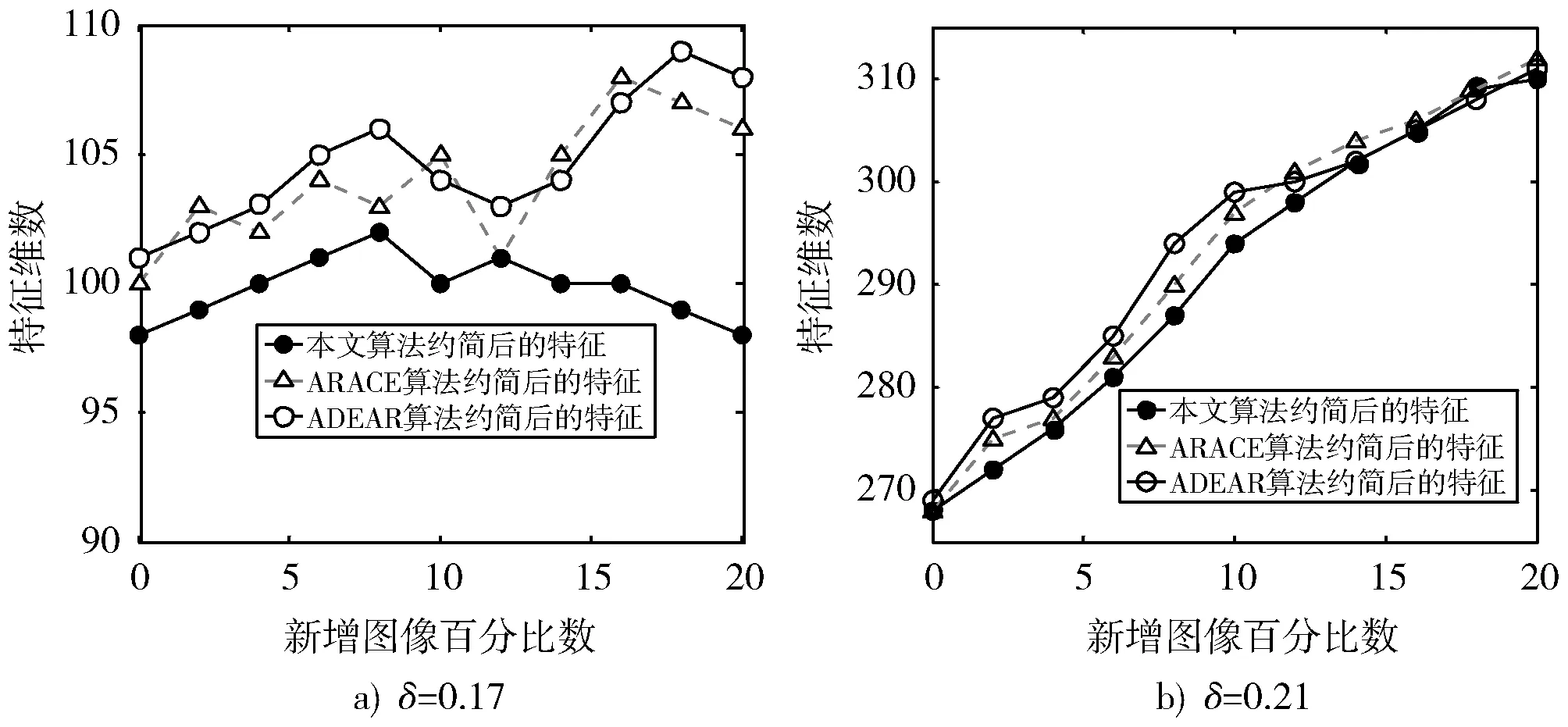
图3 当邻域阈值δ分别为0.17和0.21时三种算法约简后的特征维数对比图Fig.3 Comparison of characteristic dimensions after reduction with three algorithms asδ=0.17 andδ=0.21 respectively
图3b)和图4b)表示当邻域阈值δ=0.21时三种算法每次新增样本之后约简的block维数和特征维数,其中图3b)中三条线分别表示三种算法约简后的特征维数,图4b)中三条线分别表示三种算法约简后的 block数。从中可以看出三种算法约简后的block数基本一致,而且特征维数基本保持一致。

图4 当邻域阈值δ分别为0.17和0.21时三种算法block数对比图Fig.4 Comparison of block number of three algorithms as δ=0.17 and δ=0.21 respectively
总结:从图3,图4可以看出,当邻域阈值δ=0.17时三种算法约简后的block数远少于当邻域阈值δ=0.21时三种算法约简后的block数。从图4b)中可以看出,BIINR算法在δ=0.21时所选择的43维block块存在冗余属性,而且从图5b)中可以看出,BIINR算法在δ=0.17时所选择的9维block块特征主要集中在行人的头部和四肢部分,基本能够表现特征选择,说明邻域阈值δ=0.17时得到的结果更好。最后从得到的结果来看,BIINR算法的改进思想是可行的,可以实现动态约简。
3.2 运行时间情况
增量式算法的核心思想不仅要求动态约简,而且还要求算法的高效性,通过实验得到的三种算法约简的高效性实验结果如图6所示。

图5 约简得到的block块示意图Fig.5 Schematic diagram of the block gotten by reduction
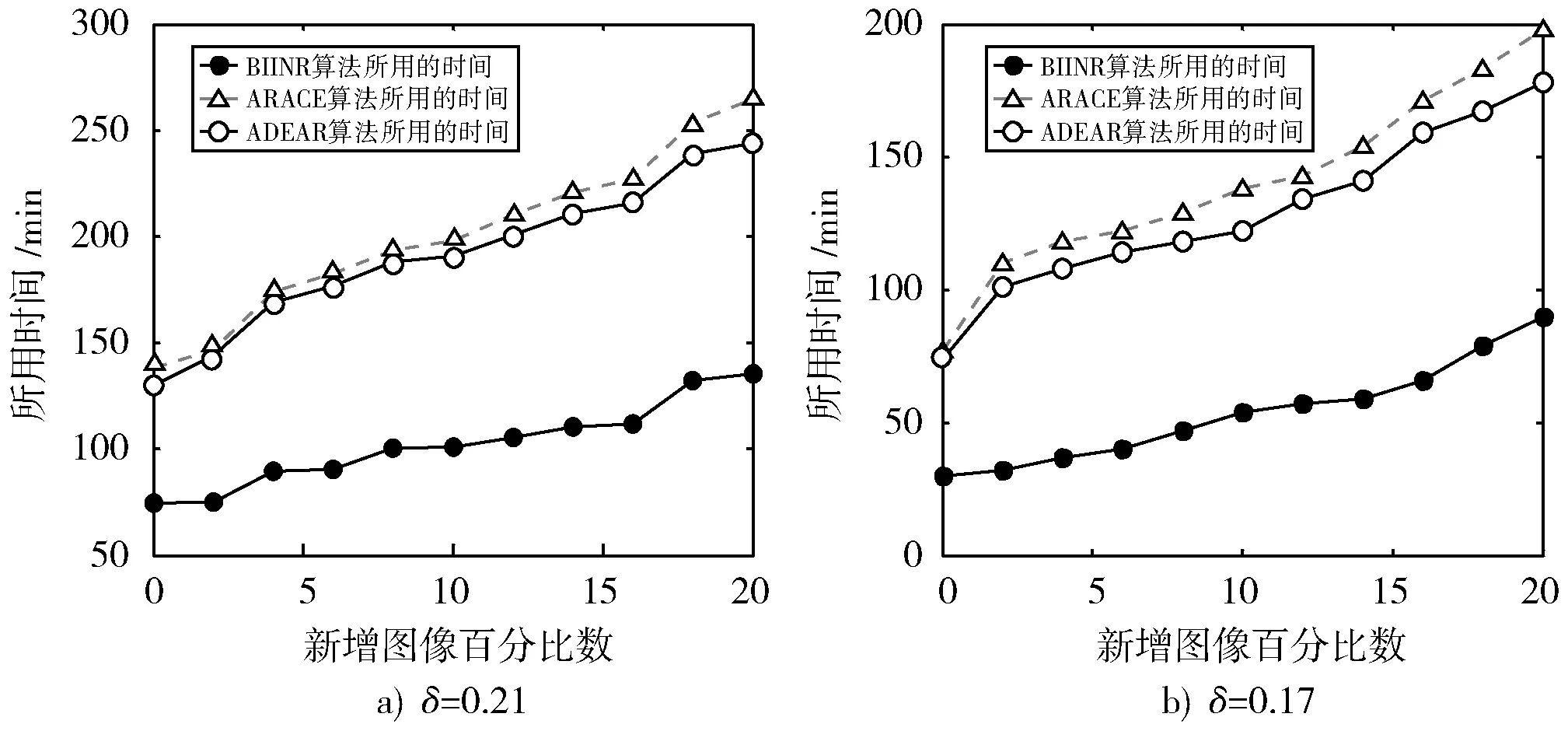
图6 三种算法约简运行时间对比图Fig.6 Comparison of running time of three reduced algorithms
图6a)为当邻域阈值δ=0.21时三种算法的运行时间,从图中可以看出BIINR算法在新增样本后运行时间明显低于ARACE算法和ADEAR算法,其中BIINR算法在第二个阶段和倒数第二个阶段新增样本中斜率明显偏高,说明这两个阶段中引起约简集变化的新增图像较多,因此算法运行时间相对长一些,而ARACE算法、ADEAR算法整体斜率偏高,运行时间较长。图6b)为当邻域阈值δ=0.17时三种算法的运行时间,从图中可以看出BIINR算法在新增样本后运行时间明显低于ARACE算法和ADEAR算法,其中BIINR算法在第四个阶段和后两个阶段斜率偏高,说明这三个阶段中引起约简集变化的新增图像较多,所以算法运行时间相对长一些,而ARACE算法和ADEAR算法同图6a)中的情况基本相同,算法整体斜率偏高,整体运行时间也是比较长。综上所述,BIINR算法高效性能方面要明显优于ARACE算法。
3.3 所得特征在分类器下的精度情况
为了验证三种算法约简后的block块和特征,本文通过SVM和KNN两种分类器对三种算法进行精度测试,对约简后block和特征的数据集以十折交叉算法求得两种分类器下的检测精度。实验结果如图7,图8所示。图7和图8为邻域阈值δ分别为0.17,0.21时三种算法在增加样本经过约简后在各分类器下的精度值。
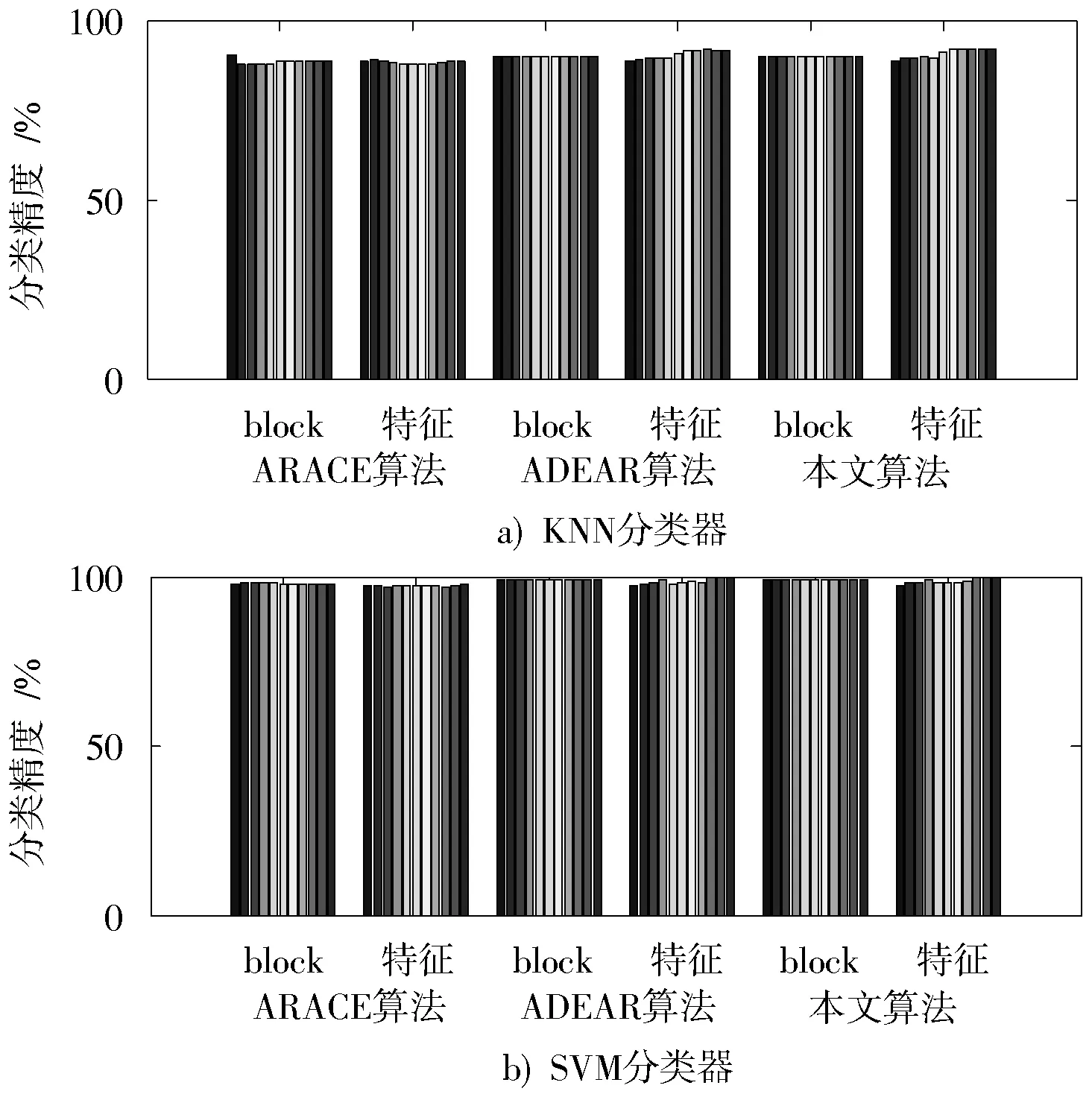
图7 邻域阈值δ为0.17时三种算法约简后在KNN,SVM分类器下的精度对比Fig.7 Comparison of thethree algorithms′accurate values detected by KNN and SVM classifiers after reduction of added sample asδ=0.17
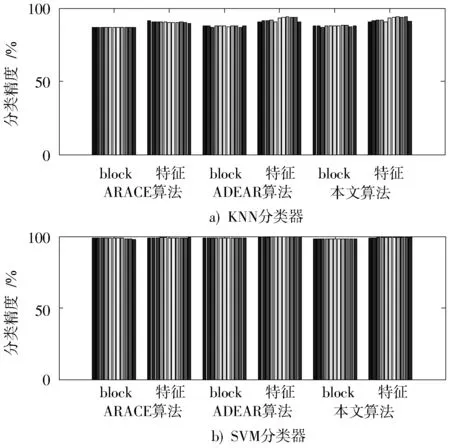
图8 邻域阈值δ为0.21时三种算法约简后在KNN,SVM分类器下的精度对比Fig.8 Comparison of the three algorithms′accurate values detected by KNN and SVM classifiers after reduction of added sample asδ=0.21
从图7,图8可以看出,无论邻域阈值δ为何值,三种算法约简后的检测精度都十分接近。下面进行简要分析:
1)当邻域阈值δ=0.17时
从图7a)可以看出,KNN分类器下BIINR算法约简后的特征以及block块的平均精度要稍高于ARACE算法、ADEAR算法;从图7b)可知,SVM分类器下BIINR约简后的特征以及block块的平均精度要基本上都稍高于ARACE算法,ADEAR算法。ARACE算法、ADEAR算法约简后的特征平均精度达到97.44%,98.03%,block块的平均精度达到98.02%,98.59%。而BIINR算法约简后的特征平均精度达到98.53%,block块的平均精度达到99.15%。
综上,BIINR算法约简后的特征平均精度、约简后block的平均精度都要高于ARACE算法、ADEAR算法。
2)当邻域阈值δ=0.21时
从图8a)可以看出,KNN分类器下BIINR算法约简后的特征平均精度要高于ARACE算法、ADEAR算法,两种算法约简后的block块的精度相同;从图8b)可知,在SVM分类器下BIINR约简后的特征平均精度要稍微高于ARACE算法、ADEAR算法。ARACE算法、ADEAR算法约简后的特征平均精度达到99.62%,99.51%,BIINR约简后的特征平均精度达到99.69%,三种算法约简后的block块的精度基本相同,ADEAR算法约简后的block块的精度略小于其他两种算法。
综上,BIINR算法约简后的特征平均精度要高于ARACE算法、ADEAR算法,三种算法约简后的block块的精度基本相同。而且可以知道的是约简后的特征平均精度要高于基于block块约简后的平均精度,主要原因是基于三种算法约简后的特征去除了block块中的干扰特征,所以导致三种算法约简后的特征平均精度比较高。
4 结 论
传统的行人检测方法为静态特征提取方法,本文提出一种基于增量式场景图像特征选择的邻域粗糙集约简算法。首先将图像集归一化为样本集,并打上相应的标签;其次在信息观的角度下结合图像数据集,给出新增样本后计算条件熵的统一公式,并验证了公式的准确性。当有新样本加入时,首先判断是否需要重新约简,随后运用提出的算法对数据集进行增量计算,提高了算法的效率,得到更新后的约简集以及block块。通过实验与ARACE算法、ADEAR算法进行比较,BIINR算法在特征选择、运行时间、精度这几个方面都有着不错的结果,验证了BIINR算法是可行有效的。
