Oracle通信TNS协议中请求报文的解析①
2018-10-24侯方杰
侯方杰, 王 雷, 王 嵩, 盛 捷
(中国科学技术大学 信息技术学院 自动化系, 合肥 230001)
1 概述
数据库作为各类信息系统的核心部分, 其安全性在整个安全体系结构中举足轻重. 根据Verizon 2016数据泄露调查报告[1], 分析已确认的 2260 起数据泄露事件中, 泄露源 7 成以上和数据库相关. 且由内部违规, 即公司内部人员的操作失误和权限误用造成的数据泄露事件占总事件的20%. 在外部攻击方面,2016年数据库漏洞中, 80%以上都属于SQL 层入侵范畴, 主要是利用数据库系统SQL语言漏洞[2]. 诸多的安全隐患也催生了大批数据库安全审计软件, 在事中发现并阻断违规和入侵语句, 在事后审计和分析, 对泄密行为追根溯源, 保证数据库的安全. 而Oracle数据库作为最流行的数据库产品之一[3], 在各种数据库安全软件中均被广泛支持.
将网络数据报文转化为数据库会话是数据库安全审计中必不可少的一部分. 由于Oracle公司并未公布数据库通信细节, 当前的安全审计重点针对Oracle数据库的通信协议TNS(Transparent Network SubStrate Protocol)进行分析. 文献[4,5]都基于TNS协议设计与实现了Oracle审计系统, 并进行了性能评价. 文献中给出了TNS数据包头的格式、数据包分类及会话流程,但对于数据包的内部格式细节却没有太多说明, 并且仅覆盖一两个协议版本. 文献[6]则通过WireShark抓包工具研究数据包的结构来对TNS协议进行解析, 对客户端与服务器建立连接的过程进行了细致的分析,并给出了网络选项协商、类型编组、认证过程, 分析了TNS协议中的5种数据包结构. 但该文献并未给出抓包测试的操作系统、服务器、客户端以及TNS协议版本, 并且对于关键的Data类型数据包中的请求与响应报文的结构并没有更深入的分析, 难以从中提取出SQL以及响应的内容.
当前公开的TNS协议解析总的来说有3个问题.一是重点放在安全软件的系统设计与实现上, 对于TNS协议的分析较为简略;二是对TNS协议分析的层次不够深入, 难以还原出用户的操作和数据库的响应;三是覆盖的数据库服务器、客户端、操作系统和协议版本不够全面, 只适用于特定的协议版本、服务器, 甚至是特定的连接.
本文针对市场上多种常用的TNS协议版本、数据库服务器与客户端, 分析其TNS数据包尤其是请求数据包的格式细节. 使用Wireshark抓包工具, 获取数据包样本;通过人工分析, 初步获取报文规则;通过数据挖掘的方法, 确定报文中的关键字节, 及其与SQL的偏移量的关系, 生成匹配规则;设计实验, 使用匹配规则提取数据包中的SQL语句做验证;分析匹配失败的用例, 配合后期校正规则, 提高测试通过率.
2 TNS协议概述
TNS协议是Oracle数据库远程通信协议. 根据数据库服务器和客户端的选择, TNS可以使用Plain TCP、SSL TCP、命名管道、IPC传输. 其中命名管道是进程间通信, IPC是本地通信, Plain TCP明文传输,SSL TCP是加密传输. 考虑到绝大多数远程客户端连接用的是Plain TCP和SSL TCP, 本文仅分析Plain TCP下的TNS协议. 理论上获得SSL秘钥后对SSL TCP解密得到的报文, 也适用于本文的分析.
Oracle通信的流程在文献[4–6]中都有详细的说明, 并且和本文请求报文解析的关系不大, 在此略过.本节重点介绍对分析过程至关重要的TNS报文头部结构.
TNS报文通用首部格式如图1所示, 共8个字节,包括数据包长度、数据包校验和、数据包类型、保留位、数据包头部校验和. 需要注意的是, 最新的315版本TNS协议中, 数据包长度和校验和位置进行了对调.目前数据包校验和、保留位、数据包头部校验和均以0填充. 数据包类型的取值与含义见表1. 其中, 类型为0x06的是Data类型数据包. 在连接建立完成之后, 客户端的请求、服务器的响应都是Data类型, 因此本文分析的对象主要也是该类型数据包.
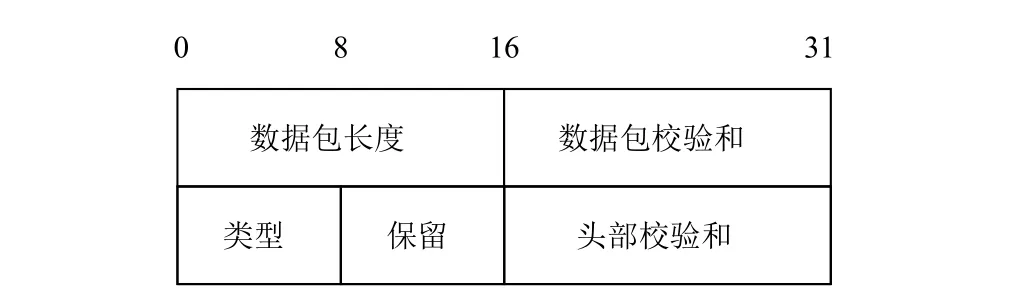
图1 TNS通用首部格式
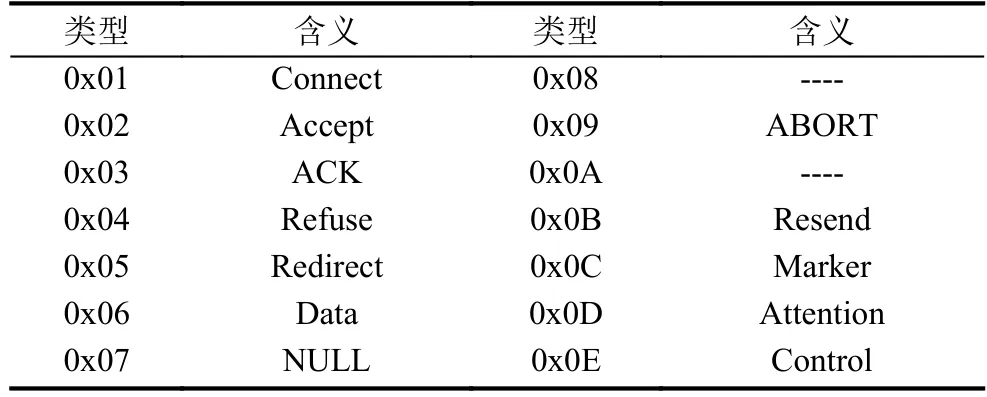
表1 TNS通用头部中类型的取值与含义
Data类型第一个问题是协议中数据包格式包括8个字节的TNS通用首部位置和格式不固定. 对于提取协议请求内容来说, 后面依次重要的是DATA
FLAG、ID、SUB知道内容在报文中的偏移量. ID和但这个偏移量会根据数据部分. 其中DATA FLAG一般填充0库服务器、客户端版本不同而变化, ID还会受到协议版本号、SUB ID和数据部分可能会重复出现,类型、长度等影响. 如图2因此需要根据报文中所示. ID和SUB ID可以唯一关键词来确定后续数据部分的具体类型偏移量.
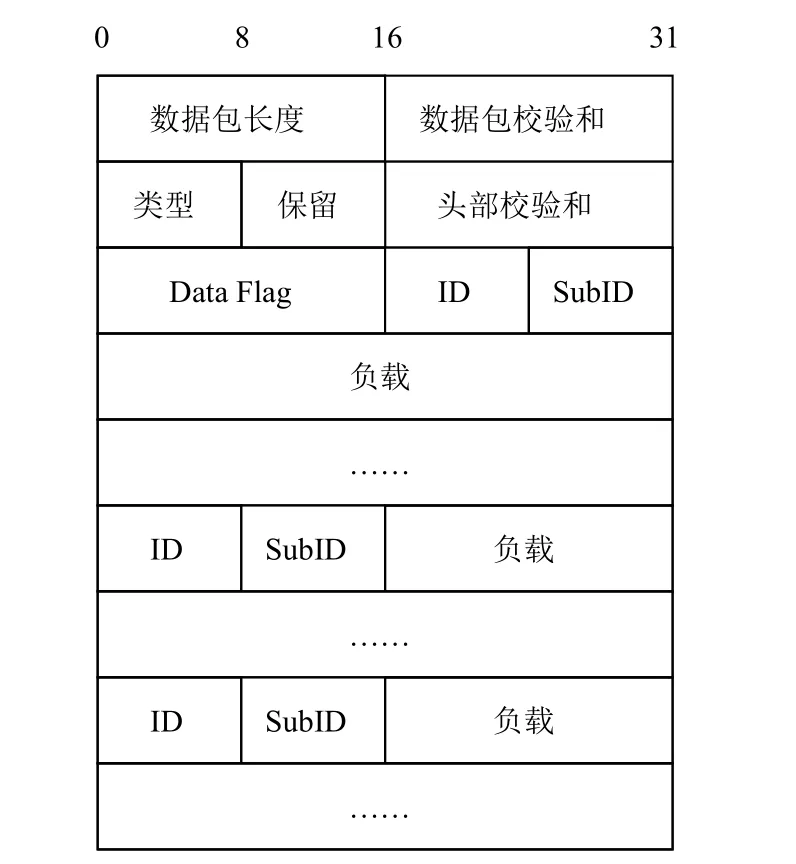
图2 TNS协议Data类型数据包格式
3 TNS请求解析方案
本节将从样本获取、人工初步分析两方面介绍TNS请求解析方案的设计依据.
3.1 样本获取
根据对市场上常用的TNS协议版本、数据库服务器、客户端的调研, 以及在某电信集团数据中心机房采集到的数据流量显示, 常用的TNS协议版本包括308、310、312、313、314、315. 为了保证通用性, 本文解析支持TNS308到31的5全版本. 在数据库服务器方面配置了Windows和Linux下的Oracle8i、9i、10g、11g、12c, 而客户端采用了java连接(包括classes12、ojdbc14、ojdbc5、ojdbc6、ojdbc7的JAR包)、Navicat(主版本号包括 10、11、12)、PL/SQL Developer(主版本号包括6、7、8、9、10、11)、Oracle SQL Developer(主版本号包括2、3、4)和PowerDesigner, 使用到的动态连接库包括instant client 10.2、11.2和12.2的oci.dll.
3.2 人工初步分析
对于采集到的数据包, 根据请求者的IP和数据包中ASCII码是否包含连续的英文字母, 将请求报文单独提取了出来. 统计了请求报文数据类型的ID和subID, 并结合前面一章的分析得到了请求报文的一个简单结构, 如图3所示. 初步分析揭示了TNS协议解析的两个主要问题.
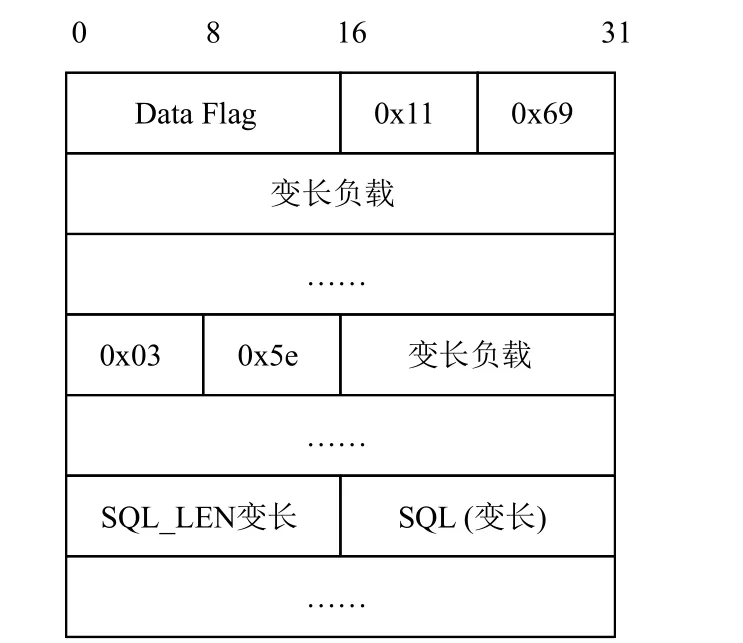
图3 请求报文格式
第一个问题是协议中数据的位置和格式不固定.对于提取协议请求内容来说, 重要的是知道内容在报文中的偏移量. 但这个偏移量会根据数据库服务器、客户端版本不同而变化, 还会受到协议版本号、数据类型、长度等影响. 因此需要根据报文中关键词来确定偏移量.
第二个问题是协议解析涉及的范围广, 数据量大,人工分析的方式耗时耗力, 并且无法精确定位偏移量.需要一个系统的分析方法. 而诸多协议逆向的方法[7–9]在不依赖先验知识的情况下对协议格式进行分析, 对包含负载的报文格式解析效果并不好.
本文通过数据挖掘的方法, 提取基于位置的关键词, 建立关键词与偏移量的关系. 依次对不同TNS协议的版本获取偏移量规则, 以提高工作效率. 之所以用协议版本作为样本划分, 是因为相对于操作系统、服务器、客户端版本, 相同协议版本的报文显示出更强的规律性.
4 关联挖掘获取偏移量
本节采用关联挖掘的思想, 确定字段值与偏移量的关系. 关联挖掘最早应用于顾客交易数据库中项集的关联规则[10], 随后关联规则的挖掘被广泛研究. 在关联挖掘中, 首先获得频繁集, 再从频繁集中通过预设的置信度获取关联规则. 在确定关键词与偏移量关系时,可以先找到特定偏移量的频繁关键词, 再从中获取规则.
4.1 关联挖掘的数据格式
假设第k个报文偏移量为s, 则它的SQL前面存在s个字节. 将第i个字节的偏移量与值组为2元组, 记为


并且有
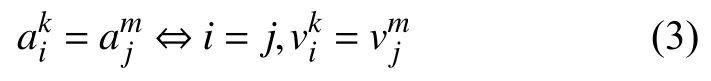
也就是说仅当偏移量和值都相同时, 才认为两个报文上的某个字节是相同的. 记F为字节与偏移量的映射关系, 则有
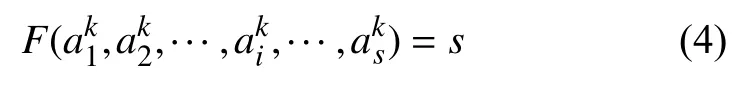
由于这个映射关系和某个具体的报文无关, 因此可以略去k, 即
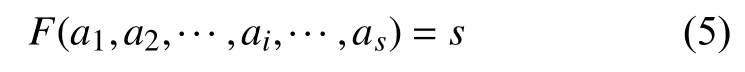
报文中对结构有关键影响的字节只占少数. 也就是说, 只需部分关键字节的值, 就可以确定报文偏移量.转化为数学语言, 即
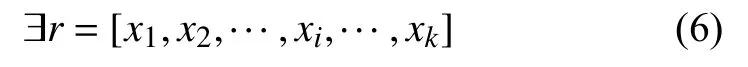
满足
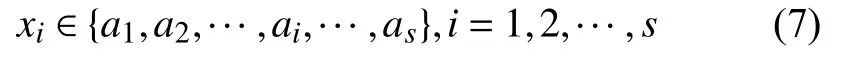
使得
式(8)是一个关联规则的形式. 在关联挖掘中, 以ai和s的取值范围作为项集, 将数据格式定为
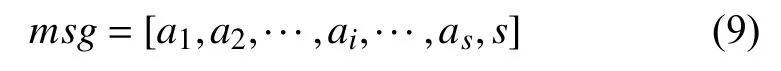
并从样本中获取数据集, 使用Apriori算法, 可以挖掘出形如式(8)的关联规则. 由于式(8)是针对偏移量的关联规则, 可以将样本数据先按照偏移量的不同划分为若干个组, 对每个组分别求频繁集. 每个组内偏移量是定值, 因此偏移量s一定在频繁集中. 在求关联规则时, 再将各组频繁集汇总. 依据偏移量的不同进行划分, 可以有效的降低计算量.
4.2 样本数据提取
样本数据提取指的是从初始网络数据包中提取出a1,a2,···,ai,···,as和偏移s. 本文将SQL语句限制为select、insert、create、drop、delete等单词开头的常用语句. 然后采用字符串匹配的方式,即可确定SQL语句的起始位置, 以及从开头到SQL的每一个字节, 从而自动而快速地生成样本数据集.
4.3 算法描述
关联挖掘采用的是Apriori算法[11], 具体描述如下:
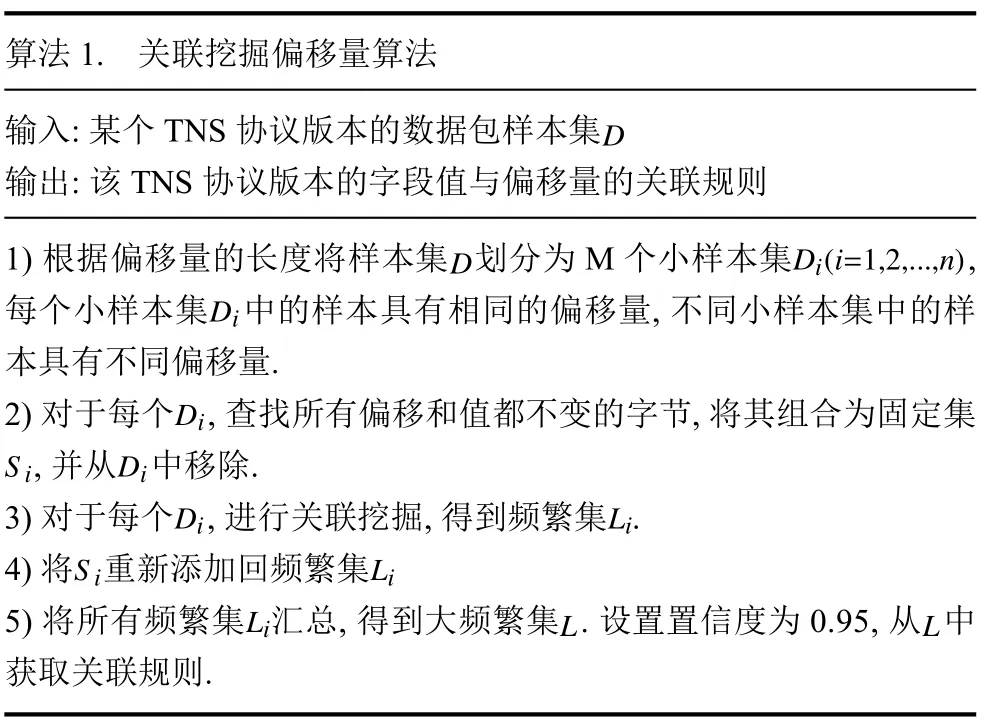
上述算法将置信度设置得接近于1是因为, 对于一个特定的字段组合, 其对应的偏移量也是通常固定的. 第5)步中, 仅搜索和偏移量相关的规则.
在挖掘的过程中发现, 小样本集Di中数据报文存在着不少字节, 它们的偏移和值是完全固定的, 所以一定会出现在频繁集中. 但是这部分字节并不会在计算时被忽略, 反而是出现在每一次频繁集的迭代中. 为了减少计算量, 第2)步将这些偏移和值固定的字节在挖掘之前从样本集中移除, 在第4)步挖掘结束后重新添入频繁集.
5 实验分析
本节首先用前述的挖掘算法, 获取挖掘结果, 并对其含义做解释. 然后在实际系统工作环境下, 使用挖掘得到的规则对请求报文做解析. 同时对规则的准确度做评价.
实验环境采用3.1节描述的所有客户端和服务器,分别在Windows和Linux环境下, 两两连接, 运行SQL脚本采集数据. 将采集数据按照TNS协议版本进行划分, 再分别使用关联挖掘的方法获取偏移量的规则.
5.1 最大最小规则
挖掘结果显示, 对于同一个偏移量, 得到规则不止一个. 记偏移量为s的集合为

定义最小规则rmin→s为:
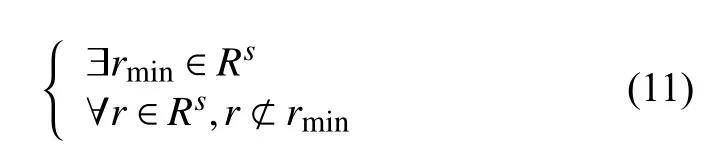
定义最小规则rmax→s为
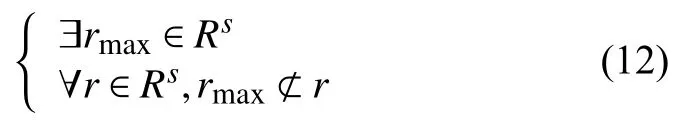
若rmin⊆rmax, 则rmin和rmax构成一对最大最小规则. 很明显, 除非R为空集,rmin和rmax总是存在. 并且,对于一个偏移量s, 可能存在不止一对最大最小规则.
在规则集中, 最大最小规则有很多用处. 最小规则因为包含的字节数量最小, 没有冗余, 适合直接用于请求报文SQL的提取. 而最大规则由于包含了更多的信息量, 适合对报文结构作进一步的分析. 对TNS315协议, 035e报文头部到SQL的一对最大最小规则如图4(a)和4(b)所示. 图中最大规则因为篇幅原因, 省去了字节值前面的0x.

图4 偏移量为40的最小规则及最大规则
5.2 细化协议格式
通过对各种最大规则的分析对比, 得到了请求报文的一个更详细的格式. 图5中是TNS315版本请求报文的部分格式. 图中的Magic1、Magic2、Magic3为定长字段. 图中的变长字段, 如SQL_LEN、VarD1、VarD2等, 均满足len+data的结构. Len为1个字节,data长度为len个字节. 图中的VarS1为变长字段, 一般为2个、4个或8个字节的填充字段. 实验结果说明, 数据挖掘方法对获取变长结构的关联字段和报文中的定值字段非常有效.
5.3 规则解析效果测试
本文使用最小规则来解析并提取报文中SQL语句. 图6显示了各个TNS协议版本挖掘出的最小规则的数量. TNS 310版本支持的服务器和客户端版本最多, 其格式最复杂, 挖掘出的规则数量也最多. 而TNS 314版本的格式则相对比较简单.
本文根据挖掘出的最小规则, 进行Oracle报文解析的实际测试. 通过上海某电信集团机房的专业数据库操作人员为期2个月的采集和测试, 初期的测试通过率仅为71%, 如图7所示. 发现问题包括:部分报文结构的缺失、部分变长字段发现了新结构. 主要原因在于样本集不够全面, 无法覆盖所有报文格式. 本文通过使用异常样例扩充样本集, 重新挖掘来完善规则, 提高测试通过率.
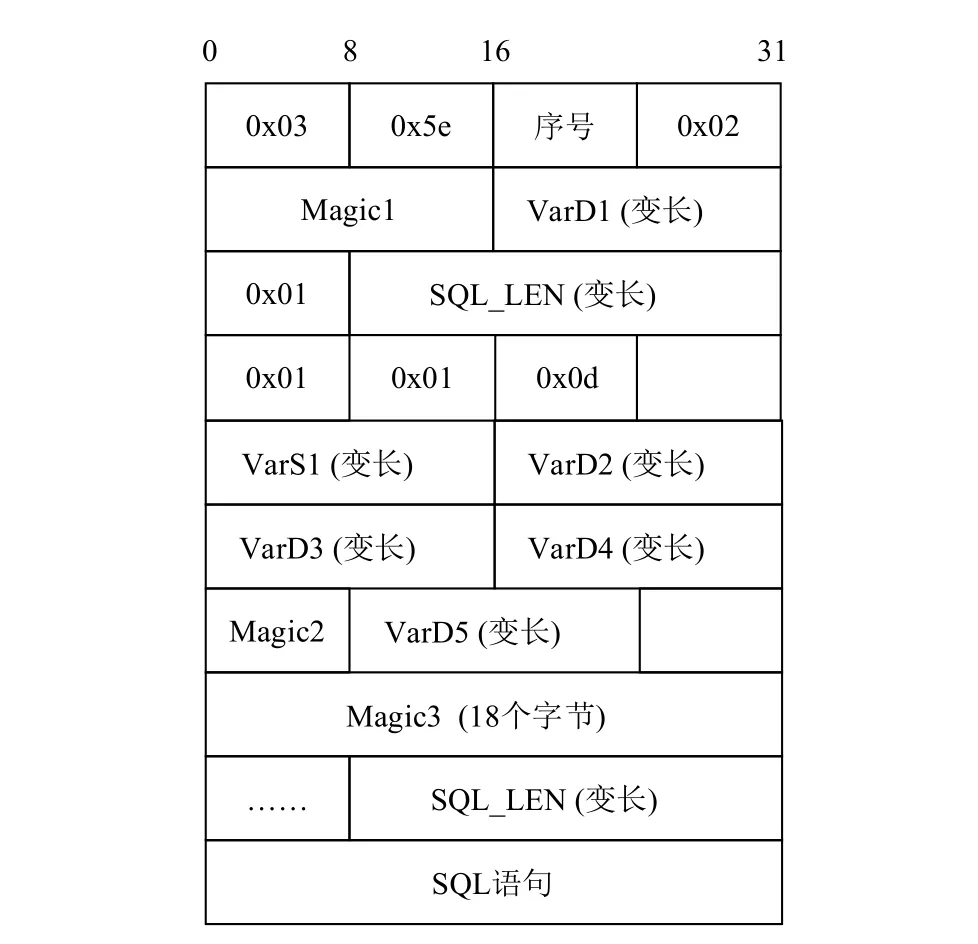
图5 更详细的报文格式
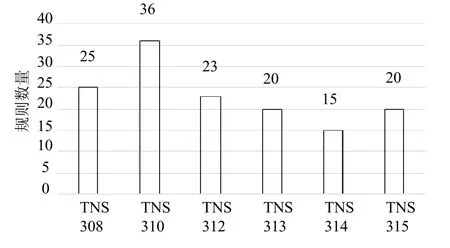
图6 不同TNS协议版本的规则数量
在这之后, 本文一边实地运行解析系统, 一边更新解析系统的规则集. 采集到的数据包如果解析异常, 就会被添加进样本集中, 重新进行挖掘. 挖掘出的新规则会被添加进正在运行的解析系统规则集中. 到目前为止, 解析系统已运作9个月. 除了开头2个月有个别异常, 之后均能正常解析.
6 结论与展望
本文针对Oracle数据库TNS协议的请求报文, 提出了一个解决方案, 适用于多种常用操作系统、服务器、客户端和协议版本. 采用数据挖掘的方法来处理字节数多、意义不明的报文, 获取对报文结构有重要影响的字段. 由于初期样本采集覆盖范围不够广, 挖掘的结果对于样本中出现频率少的报文类型并不友好.后期校正使用解析过程中的异常样例扩充样本集, 反复挖掘, 提高对所有类型报文的适用性. 实地采集数据进行解析, 可以有效提取出请求报文中的SQL语句,数据挖掘的方法可以有效地从大量数据中提取出规则,省时省力. 下一步计划采用现有方法继续研究响应报文中的内容.
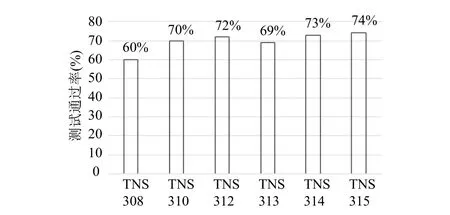
图7 不同TNS协议版本的测试通过率
