基于端到端记忆神经网络的可解释入侵检测模型①
2018-10-24高筱娴魏金侠宋丹劼
高筱娴, 龙 春, 魏金侠, 赵 静, 宋丹劼
1(中国科学院 计算机网络信息中心, 北京 100190)
2(中国科学院大学, 北京 100049)
1 引言
入侵检测系统(Intrusion Detection System, IDS)是部署在网络中用于检测异常网络行为的安全设备, 对于网络系统安全具有重要作用. 由于网络技术的不断发展, 网络攻击行为也在不断变化和升级, 因而入侵检测技术需要不断更新、改进以适应网络威胁的变化.
目前, 入侵检测技术主要包括基于知识的误用检测和基于行为的异常检测. 误用检测是将当前监测的网络行为与提前定义好的入侵行为一一对比, 若符合则视为入侵行为. 误用检测对已知攻击类型有很好的检测效果, 但无法检测出变异攻击类型或未知攻击类型. 异常检测是对正常网络行为建模, 若当前网络行为不符合正常行为模式, 则判断为异常网络行为. 异常检测在变异攻击类型和未知攻击类型上有较好的表现,但存在误报率高的问题.
目前很多研究工作尝试将两种检测方法结合起来达到优势互补的目的. 一种常用的方法是将基于知识的模型和基于行为的模型分别进行训练和预测, 之后把两类算法的预测结果按照预定策略(如投票和交并集等)融合, 作为最终的判断结果[1]. 另一种方法是使用复合模型, 首先使用单模型学习数据内在知识, 然后将学习到的知识用于下一步的检测算法. 这两种方法的共同点是, 它们都包含了不止一个基本模型, 各个模型分别训练之后相结合, 这使得训练过程复杂化.
入侵检测中的另一个问题是, 在实际应用中, 入侵检测系统给出对网络行为的判断结果后, 安全人员需要根据该判断结果做出相应的安全处理, 这一过程要求安全人员具备足够的经验. 而基于异常的入侵检测技术往往不能给出检测依据, 这就提高了对安全人员经验的要求. 因此, 使入侵检测模型输出可解释性信息在实际应用中具有一定的意义.
文章中, 我们提出一种基于记忆神经网络的入侵检测模型, 它能够利用已有的攻击知识, 使用端到端的学习方法, 用来简化入侵检测算法步骤. 同时, 该方法能够对检测结果提供可解释信息, 帮助安全人员了解当前网络行为特点. 我们设计并搭建模型, 在NSL KDD数据集上完成了实验.
本文第二节介绍入侵检测领域的相关工作, 第三节介绍我们提出的模型架构和实现细节, 第四、五节设计、完成实验, 并分析实验结果, 第六节以Snort规则为例, 详细描述模型在数据应用上的扩展方案, 最后在第七节总结本文工作, 提出未来工作方向.
2 相关工作
入侵检测系统根据监控的事件类型以及部署位置,分为基于主机的IDS和基于网络的IDS[2]. 前者监控主机上的事件, 后者则部署在特定的网络设备上, 对网络流量进行分析, 以识别可疑活动. 我们的模型是基于网络的, 处理的数据为静态流量数据.
用于入侵检测的两种典型的方法是基于知识的误用检测方法和基于行为的异常检测方法.
误用检测通过预定义的静态signature来过滤流量数据[3]. 静态signature通常从安全专家构建的攻击模式库中选择. 大多数商业IDS和开源应用程序都采用基于知识的方法, 如 Snort[4]和Bro IDS[5]. 对这类方法研究主要集中在构建signature或对知识重编码上. 例如, Gu等人提出将Snort规则和基于主机的统计结合起来监测僵尸网络[6]. Kumar等人通过有色Petri网的自适应实现了匹配的遗传模型[7]. 基于signiture的方法还包括对IDS系统的改进, 如杨忠明等人采用策略分流的方式, 同时使用Snort和Bro过滤不同层次的流量数据[8]. 基于signature的方法在已知的攻击类型上有很好的性能.
基于行为的方法也称为基于异常的方法, 使用一段时间内的监控流量来描述正常网络行为[1]. 如果当前行为不符合正常网络行为模式, 则认为它是异常网络流量. 机器学习和数据挖掘方法中的无监督和有监督方法被广泛用于基于行为的检测. 例如, 在Tajbakhsh等人的文章中使用模糊关联规则发现行为中有价值的关系模式, 进而判断入侵行为[9]. Blowers等人使用DBSCAN聚类算法对正常和异常网络数据包进行分组来检测异常流量[10]. 基于行为的检测方法, 其主要研究内容是提升模型检测速度和精度. Singh R等人设计了基于profiling和OS-ELM的入侵检测方法, 能够提高大数据情况下的检测速度和准确率[11]. Chong D等将增强学习方法中的学习自动机(learning automata)与SVM相结合, 选择出有效特征子集以简化训练过程,提高SVM训练效率和精度[12]. Agarap等人引入SVM来替代GRU模型最终输出层中的Softmax以提高神经网络的分类精度并降低训练时间[13]. 异常检测在工业控制, 军事监视以及网络安全等领域具有广泛的应用[14], 因而有大量的综合性研究.
异常检测和误用检测相结合的方式通常有两种实现方式, 一种是分别使用异常检测和误用检测结果的交并集作为最终结果;另一种是将两种方法串联使用.如任晓芳等提出的方法中, 使用随机森林形成误用检测中的模式, 若网络行为数据与模式匹配则判断为攻击, 否则将其转交至异常检测算法中, 异常检测用K-means实现[15]. 王峰的研究中使用神经网络完成了类似的检测过程[16]. 组合方法和复合方法的研究内容主要为改善原始数据质量和提升检测精度两方面. 如Al-Yaseen WL提出改进的K-means算法来构建高质量的训练数据集, 再使用SVM和ELM算法对处理后的数据分类, 提高已知和未知攻击的检测效率[17]. 可见, 使用两种检测方式融合的入侵检测方法中, 通常要训练不止一个模型, 网络行为数据要经过多个模型判断.
3 模型
记忆神经网络(Memory Neural Network)由Weston J等人提出[18]. Sukhbaatar等人在此基础上提出了端到端的记忆神经网络(N2N Mem Network)[19]. 模型中, 背景知识或上下文信息被存储在外置记忆单元中, 通过神经网络循环完成输入数据和记忆项之间关联关系的计算, 过程中自动选择出K个最相关的记忆项融合到原始输入数据中, 用于对标签的训练.
本文使用端到端记忆神经网络的一种变体, 是一个基于领域知识的分类器, 其基本思想是利用领域知识辅助分类, 领域知识与当前网络行为的匹配度越高,该知识项在分类器中发挥的作用越大, 据此设计模型架构, 主要由五个部分组成, 如图1所示. 网络流量数据首先与领域知识做匹配度计算, 然后将领域知识按照匹配结果融合进原始流量数据, 对融合数据分类得到最终判断结果, 同时匹配结果作为可解释信息输出.
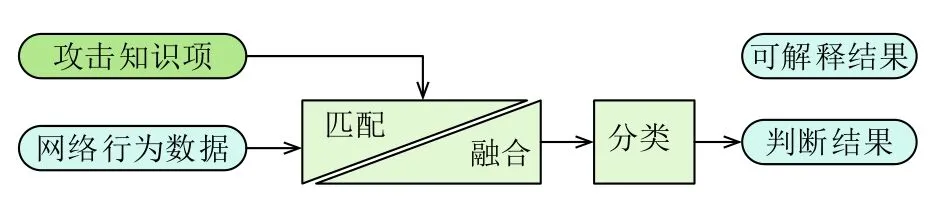
图1 模型框架
3.1 输入输出
本文模型利用领域知识辅助对网络行为进行分类,其输入包括领域知识和待分类的网络行为数据. 领域知识是关于攻击的知识, 可以是IDS规则、防火墙规则、安全人员经验数据等;网络行为数据是反映当前网络行为或状态的数据, 一般从网络流量数据包中提取, 如连接方式、操作类型等. 模型中领域知识应当与网络行为数据具有关联关系, 才能使用领域知识辅助对网络行为分类.
领域知识由若干条彼此独立且具有实际意义的领域知识项组成, 在训练和使用前静态加载进入模型, 用来表征关于攻击的特点, 在模型中用一个矩阵M来表示:
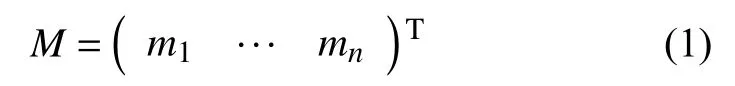
其中,mi表示第i条领域知识. 网络行为数据用来表征当前网络行为或状态, 用向量x表示.
模型的输出包括两部分, 一个是分类器对网络行为的分类结果, 为某一种的攻击类型, 用值yˆ表示;另一组可解释信息, 用于向安全人员提供参考, 用值E表示.
3.2 匹配
匹配模块计算网络行为数据与知识项的匹配程度.当网络行为与某条领域知识相匹配时, 认为网络行为倾向于是该知识项所表征的行为类别, 或者说当前网络行为具有该知识项表征行为类型的部分特点. 匹配模块中有一个匹配算法来计算网络行为与知识项的匹配度.
首先将x和M转换到统一的计算空间, 得到嵌入行为数据x′和嵌入知识矩阵M′:

其中,V是一组转换矩阵.
假设g是匹配度计算函数, 则网络行为x和领域知识的匹配度为:
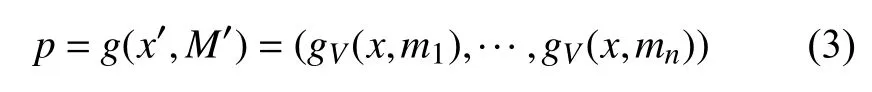
网络行为x与知识项mi所表征的攻击类型越接近,相应的pi的值越大, 表示x和mi匹配度越高.
匹配模块的另一个作用是输出关联度高的知识项的类型标签, 作为最终分类结果可解释信息.
3.3 融合
融合模块试图在分类计算之前将原始输入和领域知识相结合, 从而使知识信息能够在分类中发挥作用.融合的基本思想是知识项与网络行为之间的匹配度越高, 则该知识项在分类器中发挥的作用越大. 假设重构输入为o, 需要通过原始输入x, 知识项M和匹配度p来计算.

这样, 重构输入o就同时包含了原始输入内容和领域知识的内容.
3.4 分类
分类是模型的主要部分. 它负责将流量记录分类到预定义的类别中, 确定它们是正常流量还是其他特定的攻击类型:

3.5 模型细节
本文将采用余弦相似度作为匹配算法, 使用线性加权作为融合算法, 模型细节如图2所示.

图2 N2N Mem-IDS模型
首先使用一组转换矩阵V将知识项M和行为数据x映射到维度相同的空间, 分别得到MA,MB和u:
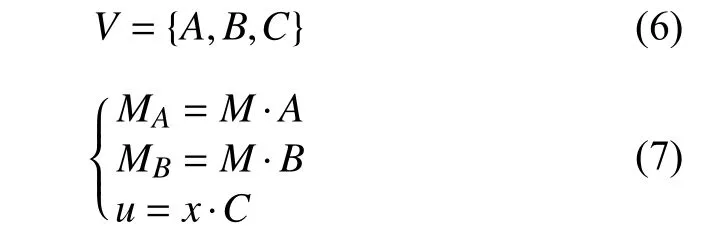
假设向量ai是MA中第i个嵌入知识项, 使用余弦相似度计算每个嵌入知识项与输入网络行为的匹配程度:
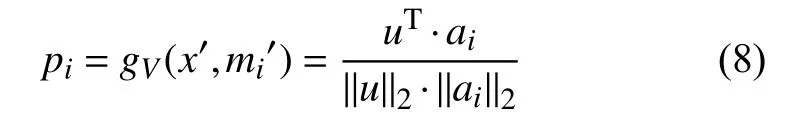
矩阵MB中的嵌入知识项bi根据匹配度pi, 用线性加权算法与u融 合, 然后使用转换矩阵W得到重构输出o:
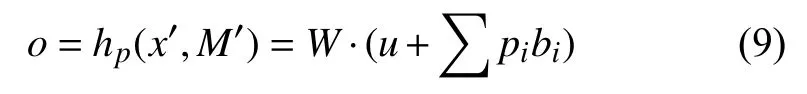
本文模型是一个堆叠网络, 本层的输出将作为下一层的输入, 即:

最后一层的输出用来得到最终的分类结果:
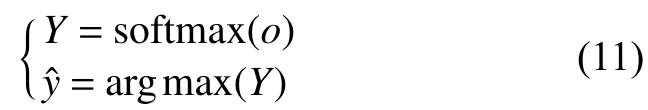
训练过程中, 参数V和W将会被模型自动学习.
4 实验设计
本章首先介绍实验使用的数据集, 接着介绍数据处理方法和攻击知识项提取方法, 然后介绍实验方案设计, 最后给出实验结果与分析.
4.1 数据介绍
本文实验使用的NSL KDD数据集源于KDD CUP99数据, 是目前最重要的公开入侵检测数据集之一. 1998年美国空军发起DARPA’98入侵检测系统评估计划, 在模拟真实空军网络的局域网内收集网络流量数据, 用于进一步研究[20,21]. 1999年从原始数据中提取出KDD CUP99数据集. 2009年, Tavallaee等人通过去重、重新设置数据比例等操作改进了KDD CUP99数据集存在一些内在问题, 形成NSL KDD数据集[22].
NSL KDD数据集中每一条数据表示一个网络连接记录, 其类别包括正常类型和4大类、40子类攻击类型. 数据集由一个训练集train+和一个测试集test+组成, 测试集中的攻击类型都是训练集中的攻击类型或者训练集中攻击的变体类型.
4.2 数据预处理
NSL KDD数据有41个特征, 包括离散特征和连续特征. 对于连续特征, 我们使用Z分数(z-score)标准化进行处理,z-score标准化计算方法为:

其中, µ =E(X),σ=Var(X). 对于离散特征, 我们使用独热编码(One-Hot Encoding)对特征值进行处理. One-Hot Encoding是使用N维特征来对原始特征中的N个取值进行编码, 即原始特征中的每一个取值都由新特征组中对应位置的0/1状态来表示. 经过处理后的数据共有122个特征.
数据集中共有41个行为类型, 我们将这41个类型归纳为五大类攻击类型, 同样适用One-Hot Encoding对其编码, 使用五维向量作为数据标签, 用于五分类实验.
4.3 攻击知识项提取
模型要求领域知识与网络行为数据具有关联关系,本实验中我们采用从行为数据集中直接提取攻击知识项的方式来获取领域知识. 根据数据集特点, 我们设计如下算法, 在数据集全集中提取攻击知识项:

步骤3)中, α表示特征重要程度累加值所占比例经过预实验 α =80%时有较好的效果, 因而采用α=80%, 即知识项保留重要程度前80%的特征. 这使得新特征能够排除非重要因素的影响, 降低数据复杂度, 同时在一定程度上保留该行为类别的特点.
4.4 实验设计
使用检测率(Detection Rate,DR)和精确度(Precision)作为入侵检测模型的评价指标, 把记忆神经网络模型和其它相关工作中的结果进行对比. 其中:

记忆神经网络模型在输出分类结果的同时, 输出可解释信息. 可解释信息为与网络行为数据相关度最高的三个攻击知识项的类别. 定义ExpV和MemV用于评价记忆神经网络中记忆模块的作用.
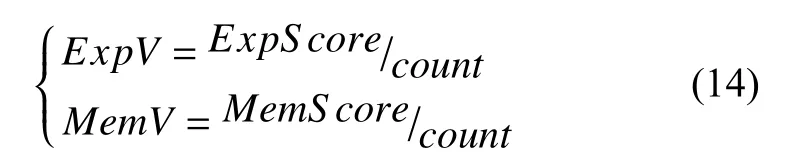
ExpV表示可解释结果对研究人员的可参考价值,ExpV越大, 可参考价值越大.MemV表示攻击知识项对判断结果所起作用,MemV越大说明模型中攻击知识项发挥的作用越大.ExpScore和MemScore取决于可解释结果和输入值的真实类别, 计算方式如表1所示.
我们设计另外两种知识项提取方式, 方法1为不使用攻击项, 方法2为随机从数据集中选取50条数据作为攻击知识项, 方法3为直接对不同类别数据进行聚类. 将本文方法与这三种方法相比较, 验证知识项有效性.

表1 ExpScore和MemScore计算方式
5 实验结果
本文中模型的输出包括分类结果和可解释信息.根据4.4的评价指标计算方式, 采用不同攻击知识项提取方式对模型输出的可解释信息质量进行比较. 比较结果如图3(a)所示. 发现使用本文知识项提取方式在ExpV和MemV上具有最佳表现. 这是因为输出的可解释信息是与网络行为数据匹配度最高的3条攻击知识项标签. 而匹配度越高的攻击知识项越能够表征网络行为特点, 因而将其输出后能够给安全人员参考, 使其了解当前网络行为所具有的部分特征. 另一方面, 在模型设计中, 匹配度越高的攻击知识项对分类器的辅助作用越大, 因而匹配度能够表征分类器的部分分类依据.
图3(b)为使用攻击知识项和不使用攻击知识项的对比结果, 可以看出攻击知识项确实在模型中发挥了辅助分类的作用.
将本文模型与几个模型比较, 验证模型有效性, 结果如图4所示. 对比显示本文模型相比传统单模型机器学习算法, 在检测率和精确度上有明显的提升.
6 在不同类型数据上的扩展
由于数据来源限制, 本文实验中从训练数据中提取近似的聚类中心, 作为领域知识的替代项. 如3.1节中提到的, 领域知识的来源可以是IDS规则、防火墙规则、安全人员经验数据等, 本节以Snort规则为例,提出不同类型数据在模型中使用方式的设想.
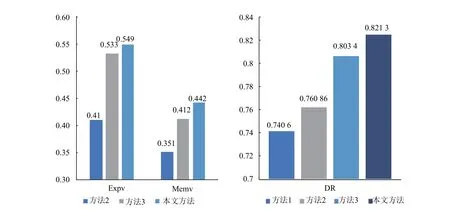
图3 不同知识项提取方式实验结果对比
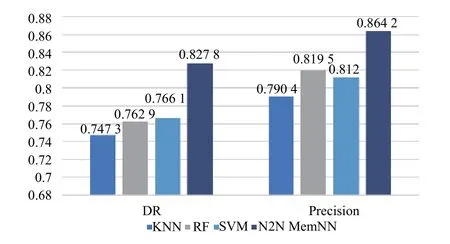
图4 与其它模型实验结果对比
一条Snort规则对应一种网络威胁和应对方式, 由规则头和规则选项组成, 规则头指定待筛选的连接和规则动作, 规则选项包含若干匹配条件, 一旦待筛选连接满足全部的匹配条件, 则触发规则动作. 当使用Snort规则作为知识领域时, 本文提出的方法中, 匹配模块和融合模块应作出相应的修改.
匹配模块判断Snort规则与网络连接数据的匹配程度. 一种可行的方案为, 将Snort规则中的匹配条件与原始网络连接数据相比对, 计算被满足的匹配条件所占比例, 作为规则与连接的匹配程度. 即

其中,Ik(x)表示连接x是否满足第i条规则mi的第k个条件,K为mi中的条件总数.
融合模块将按照匹配程度将Snort规则融合到原始数据中. 一种可行方案为, 使用匹配度作为特征,将其以连接(concatenate)方式与原始数据融合. 连接方式如下图5所示.
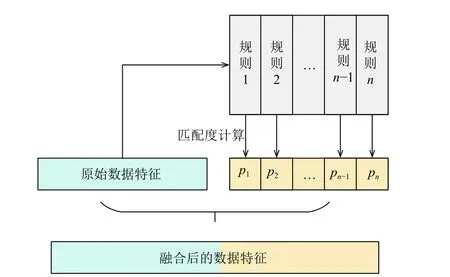
图5 连接(concatenate) 融合方法
在这种情况下, 网络连接数据与知识项的相似度直接作为新的数据特征放入分类器中, 能够为分类器提供更多信息以达到辅助分类的目的. 而每条Snort规则对应一种网络威胁, 可以用于可解释信息输出.
此外, 使用IDS规则的方式还有其它扩展方式,如, 针对规则中的匹配条件, 按照专家知识设置匹配权重;将描述形式的规则以某种方法转化为可计算的向量形式等. 同理, 防火墙规则或经验数据等都能够通过设计合适的匹配方法和融合方法, 使之在模型中发挥作用.
7 结论与展望
本文提出一种基于端到端的记忆神经网络的入侵检测方法, 这种方法利用神经网络将领域知识整合到算法中, 令神经网络分类器在领域知识的辅助下进行的端对端训练和预测, 并给出最终预测结果的可解释依据. 之后本文通过实验对模型进行评估证明领域知识在模型中发挥了作用, 并且模型在检测率和精确度上有良好表现. 最后本文以Snort规则为例, 描述了模型在其它类型数据上的可行扩展方案. 今后, 将尝试诸如IDS规则等各种更加通用的领域知识数据, 并从神经网络优化角度考虑优化模型以降低模型训练时间.
