等维新息SVR模型对隧道沉降时间序列的预测研究
2018-10-22陆慧娟叶敏超
李 伟,严 珂,陆慧娟,叶敏超
(中国计量大学 信息工程学院,浙江 杭州 310018)
城市地铁隧道在其施工和使用过程中必然会发生沉降现象.为了预防沉降带来的安全隐患,达到确保工程安全施工,隧道能正常运行维护的目的,对隧道的沉降进行精准的预测研究具有十分重要的意义[1].目前针对隧道沉降的预测有很多的方法,如经验公式Peak法、时间序列法、回归分析法、马尔可夫链法、灰色聚类法、人工神经网络法等[2].因为影响隧道沉降的因素众多,所以对沉降的预测问题是一个非线性的回归问题[3-4].SVR支持向量回归模型在基于结构风险最小化原理的基础上具有处理小样本,避免局部最优和泛化能力好的优点[5].时间序列是指某一变量的观测值按时间顺序排列,通过对此排序的研究,从中寻找和分析事物的变化特征、发展趋势和规律.对时间序列的研究起源于计量经济学,现已被广泛用于预测路基沉降、建筑物沉降以及边坡位移等.因为本文研究的隧道沉降数据为小样本时间序列,所以本文选用SVR支持向量回归并结合等维新息理论处理时间序列数据,构建了等维新息SVR模型进行预测研究.
SVR模型参数的选取对模型的表现有重要的影响,现有多种优化算法可以用于寻参,例如:遗传算法(GA)、模拟退火(SA)、蚁群算法(ACO)和粒子群算法(PSO)等[6].其中粒子群算法寻优收敛速度快,不容易陷入局部最小,且算法容易实现,所以比较适合SVR模型的参数寻优.PSO-SVR模型已应用于许多不同的领域,并且都取得了良好的效果.在生物工程方面,熊伟丽等人将PSO-SVR模型应用到发酵过程状态预估中,解决了发酵过程中微生物数无法测量的问题[7];在旅游行业,翁钢民等人提出将季节调整和PSO-SVR模型相结合对北京游客人数进行预测,大大的提高了预测的准确性[8];颜七笙等人也发现PSO-SVR方法是一种科学有效的边坡稳定性评价方法[9].
1 SVR支持向量回归简介
SVM支持向量机是Vapnik等人于上个世纪90年代针对模式识别问题在统计学习理论的基础上发展而来的机器学习算法[10].SVM严格的数学理论基础,与其能较好地解决小样本、非线性、局部极小等问题,使得其在很多领域都取得了成功应用[11].
在支持向量机发展的过程中,人们又发现SVM能够很好地应用于求解回归问题,所以在SVM基础上又发展了SVR支持向量回归.SVR支持向量回归实质上就是用非线性函数f(x)=ω·Φ(x)+b拟合样本数据,即在约束条件下寻找最优拟合超平面,尽量使超平面与数据点间的距离最小[12].最终确定回归函数如下:

(1)

2 PSO粒子群优化算法简介
粒子群优化算法是人们在研究飞鸟的觅食行为时提出的,其主要思想就是:在群体的觅食过程中,群体中的每个个体都会受益于所有成员在这个过程中的所发现和积累的经验[14].
PSO算法中,群体中的每个粒子都有两个参数:粒子自身的位置和速度.每个粒子还拥有一个由适应度函数所决定的适应度值(fitness value).所以粒子的飞行区域就代表着求解空间,每个粒子的位置都是解空间中的一个解.每个粒子所经历过的最好位置就是个体的最优解,叫做个体极值;整个群体经历过的最好位置是群体目前找到的最优解,叫做群体极值[15].每次迭代,粒子根据自身以往的移动经验以及其他粒子的移动经验来进行本次自身的移动以实现调整自身的位置,因而可以借助这两个参数进行迭代寻优.PSO算法流程图如图1.

图1 粒子群算法流程图Figure 1 Flow chart of particle swarm optimization
粒子根据式(2)(3)不断更新自身的速度和位置:

(2)

(3)
3 等维新息SVR支持向量回归模型的搭建
3.1 SVR中参数选择
对于支持向量回归SVR,参数的选择对模型的优劣有着非常大的影响.惩罚因子C、核函数参数g和不敏感损失函数系数ε都对SVR模型的学习精度和鲁棒性起着决定性的作用[17].
惩罚因子C是在确定的数据子空间中调节SVR置信范围和经验风险的比例.不同的数据子空间对应不同的C值.C值过大则模型预测误差会变大;C值过小模型精度提高但是泛化能力变弱.
核函数参数g影响着数据在高维特征空间中分布的复杂程度,反映了支持向量之间的相关程度.g过小支持向量间的联系比较松弛,模型比较复杂,泛化能力差;反之g过大,支持向量的联系影响过强,模型的精度较差.
不敏感损失函数系数ε决定着回归函数对样本数据的不敏感区域的宽度,即影响着支持向量的个数,同时还影响着拟合误差的大小.ε过大,则支持向量的个数减少,模型过于简单,预测精度下降;ε过小,支持向量个数偏多,回归精度变高但模型会过于复杂,泛化能力下降.
由分析可知SVR模型的复杂度、泛化能力取决于C、g、ε这三个参数,尤其是C和g的相互关系.对于SVR模型参数的选择,传统的方法是重复多次的“试凑法”,即不断地用实验测试来取得比较满意的参数选择[18].现将优化算法引入SVR模型实现参数的优化选择.本文便是采用PSO粒子群优化算法对惩罚系数C和核函数参数g进行优化选择.适应度函数对衡量一个PSO算法的优劣有很大的影响[19],本文选取均方误差(MSE)作为适应度函数,每个粒子的适应度函数值由如下函数得出:

(4)

3.2 等维新息SVR模型的建立
因为研究数据是时间序列数据,没有其它特征的一维数据,所以需要使用预测时间点的先前历史数据输入SVR模型进行训练测试.等维新息采用灰色理论中新陈代谢的思想,每次输入的数据都是去掉最老旧的信息而加上最新的数据[20],以此保持输入数据的维度相等.假设{xi}(i=1,2,…,m)为一组时间序列数据.则:
{{x1,x2,…,xn},{x2,x3,…,xn+1},…,{xp,xp+1,…,xn+p-1}}作为输入样本序列;
{xn,xn+1,…,xn+p}T作为输出样本序列.
用这样的等维新息样本序列输入到SVR模型中进行训练和预测.
本文研究的隧道沉降数据为时间序列,所以采用等维新息理论处理,经过多次实验验证得出取历史数据数为3,即每次用三个连续时间点的数据去预测下一个点,也就是第四个时间点的沉降值.算法整体步骤如下:
Step1 载入训练数据;
Step2 等维新息化处理数据;
Step3 利用PSO粒子群算法寻找最优的SVR模型参数惩罚系数C和核函数参数g;
Step4 利用最佳参数对C、g和libsvm工具箱构建SVR支持向量回归模型;
Step5 使用训练数据训练SVR模型;
Step6 测试数据等维输入训练完成的模型,输出回归预测结果.
关于模型整体流程图,如图2.

图2 模型整体流程图Figure 2 Overall flow chart of model
4 仿真实验实现
4.1 数据来源
数据来源于隧道工程实际采集的时间序列数据,为宁波市2015—2016年交通隧道和珠海市2016—2017年交通隧道施工时隧道上方采集的地表沉降数据.实验随机选取部分珠海(采集点序号:180~250)和宁波(采集点序号:550~580)采集点的实测数据进行预测研究.
4.2 实验结果
选取宁波与珠海的采集点数据进行仿真,选定ε=0.000 1,选取RBF函数为核函数;使用PSO优化算法优化选取C和g,本文设定C∈[0.01,1 000]和g∈[0.000 1,200].针对不同的采集点利用粒子群算法得到不同的最佳惩罚系数C和核函数参数g值如表1.

表1 不同采集点对应的C和g
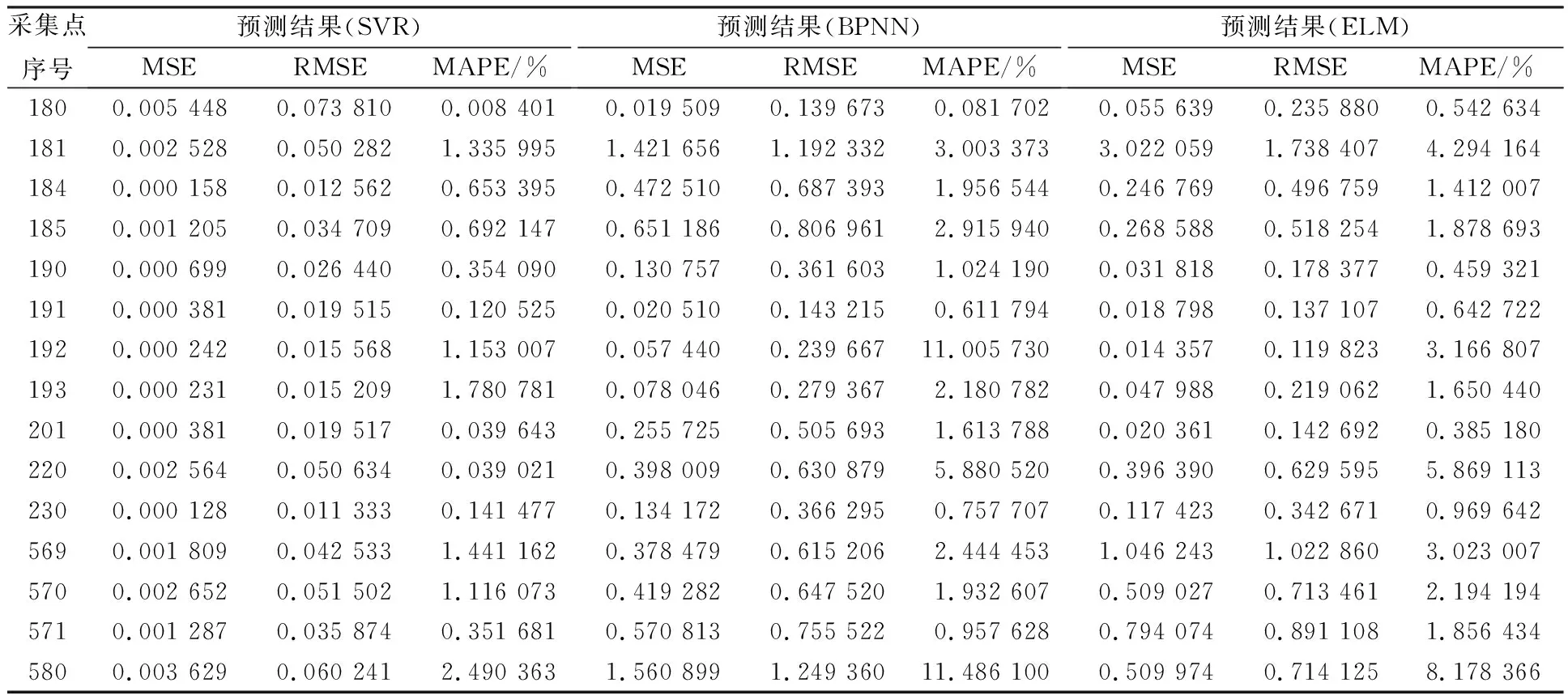
使用得到的最优参数构建SVR模型,训练完成后,选取若干具有代表性的采集点拟合曲线如图3(a)、3(b)、3(c)、3(d).不同模型预测效果的评价结果如表2.
4.3 结果对比分析
为检测基于等维新息SVR模型的预测效果,实验还做了与PSO-BP模型与ELM模型的对比.几个模型的预测效果见上述实验结果.表1对SVR模型的参数选择做出了解释,给出了详细的针对不同采集点数据SVR模型参数的选择.拟合曲线图展现出,PSO-SVR模型的拟合值与真实值最为接近,预测效果要明显优于其他两个模型.表2对模型的预测结果数据进行了具体分析,通过用均方误差(MSE)和标准误差(RMSE)以及平均绝对百分误差(MAPE)统计指标分别对三个模型进行评价对比.从表中可以看出,等维新息SVR模型的预测误差最小,模型的MAPE值最大为2.490 363%,远小于PSO-BP模型的11.486 1%和ELM模型的8.178 366%.其余两个误差评判指标,也是等维新息SVR模型表现最好,误差最小.

图3 预测拟合曲线Figure 3 Predicted fitting curve
采集点序号预测结果(SVR)MSERMSEMAPE/%预测结果(BPNN)MSERMSEMAPE/%预测结果(ELM)MSERMSEMAPE/%1800.005 4480.073 8100.008 4010.019 5090.139 6730.081 7020.055 6390.235 8800.542 6341810.002 5280.050 2821.335 9951.421 6561.192 3323.003 3733.022 0591.738 4074.294 1641840.000 1580.012 5620.653 3950.472 5100.687 3931.956 5440.246 7690.496 7591.412 0071850.001 2050.034 7090.692 1470.651 1860.806 9612.915 9400.268 5880.518 2541.878 6931900.000 6990.026 4400.354 0900.130 7570.361 6031.024 1900.031 8180.178 3770.459 3211910.000 3810.019 5150.120 5250.020 5100.143 2150.611 7940.018 7980.137 1070.642 7221920.000 2420.015 5681.153 0070.057 4400.239 66711.005 7300.014 3570.119 8233.166 8071930.000 2310.015 2091.780 7810.078 0460.279 3672.180 7820.047 9880.219 0621.650 4402010.000 3810.019 5170.039 6430.255 7250.505 6931.613 7880.020 3610.142 6920.385 1802200.002 5640.050 6340.039 0210.398 0090.630 8795.880 5200.396 3900.629 5955.869 1132300.000 1280.011 3330.141 4770.134 1720.366 2950.757 7070.117 4230.342 6710.969 6425690.001 8090.042 5331.441 1620.378 4790.615 2062.444 4531.046 2431.022 8603.023 0075700.002 6520.051 5021.116 0730.419 2820.647 5201.932 6070.509 0270.713 4612.194 1945710.001 2870.035 8740.351 6810.570 8130.755 5220.957 6280.794 0740.891 1081.856 4345800.003 6290.060 2412.490 3631.560 8991.249 36011.486 1000.509 9740.714 1258.178 366
所以等维新息SVR模型的预测精度要明显高于PSO-BP人工神经网络模型与ELM极限学习机的预测精度.我们得出结论等维新息SVR模型适用于对隧道沉降时间序列数据的预测研究.
5 结语
SVR是基于SVM发展而来的回归预测方法,实际应用显示出其具有很好的回归精度和泛化能力,然而此模型与SVM一样都必须要选取到最优的参数,才可以有良好的表现.所以本文在对SVR模型参数对模型的精度和泛化性影响的研究基础上,使用具有全局优化性能且简单方便的PSO粒子群算法来优化SVR参数,不仅避免了参数选取的盲目性而且也节省了时间;另外,本文还运用了等维新息理论处理时间序列数据,利用了数据之间的联系,有助于预测精度的提升,综合以上最终提出了等维新息SVR支持向量回归预测模型.仿真结果表明,等维新息SVR模型能较好地对隧道沉降时间序列进行预测研究.
