铁路网多路径搜索技术的实践
2018-10-22李向农
李向农
(中铁工程设计咨询集团有限公司,北京 100055)
铁路网多路径搜索技术即铁路网中点对之间一条以上较短路径的计算技术,是铁路线网分析、径路比较和OD(Original Destination,即客货流起点至终点)分配等应用的基础。
铁路网多路径搜索技术简称铁路KSP算法[1],为通用KSP算法在铁路网络计算问题中的应用。国外学者Hoffman和Pavley在1950年首先提出了该问题[2],并将其分为一般KSP算法和简单路径KSP算法。铁路网多路径计算求出的路径不能有环形子路径,必须用简单路径KSP算法求解,同时考虑经济性和多种运输方式的竞争。普通简单路径KSP算法求出的路径难以满足铁路网实用性要求,需对路径增加更为严格的限制条件。KSP算法在各行各业中都有广泛应用[3-4],国内外学者对其有大量研究成果,有Yen的经典算法[5],也有Martins、Hershberger、Maxel、Suri等对Yen算法的不断改进[6-7];通过扩展Dijkstra算法[8],国内学者柴登峰与张登荣[9]、袁红涛[10]、高松[11]等也提出了对该问题的多种优化算法;现代优化技术也应用到KSP问题,如马烨[12]的遗传算法,黄则汉[13]的蚁群算法,林洁[14]的人工免疫算法等。上述学者算法的共同特征:一是所针对的网络为一般有向图,并没有考虑铁路网特点而进行优化或简化;二是主要计算一对节点间的多条路径。而在铁路网络应用如OD分配中,经常需要知道所有节点间的多条路径(当然通过对每对节点进行多路径计算,可以得到所有节点间的多条路径,但其计算时间将会大大延长),而且记录所有路径所需的内存空间也将非常巨大;三是所求路径为普通无环路径,没有考虑铁路运输的合理路径。以下提出一种具有铁路网络特征、实用可行和满足众多铁路网络应用的多路径计算方法。
1 铁路网的抽象及有关概念
1.1 铁路网络及其特性
铁路网可表示为有向图N=(S,L),其中N为铁路网,S为铁路站点集合,可表示铁路车站、枢纽编组站、OD小区重心点等。对于X个站点的铁路网,设i为站点,则S={1,2,i,,X};L为铁路区段集合,表示两站点之间直接连接的铁路线路,设(i,j)为站点i至站点j的区段,(i,j)∈L,铁路网分上下行,所以(i,j)和(j,i)成对出现;两站点之间可能有多条铁路线直接相连,但为了计算和路径表示方便,可规定两站点之间只允许一条铁路线直接相连,对于有两条及以上铁路线相连的相邻站点对,可在其中一条线上强制增加站点来区分,并标记为不可简化;设w(i,j)为区段(i,j)的权重,可表示相邻两站点间铁路长度、运行时间或广义权重等,对铁路网来说,w(i,j)和w(j,i)相差不大,为简化计算,可令w(i,j)=w(j,i)。
1.2 铁路网路径及合理路径
对于上述铁路网,从站点o到站点d之间的路径可表示为r(o,d)=(o,s1,s2,,sk,d),其中s1,s2,,sk为从站点o到站点d依次经过的相邻站点,且o,si,d互不相同(无环)。
将站点o到站点d的路径中相邻站点间区段的费用相加可得路径长度,记为dist(o,d)。站点o到站点d的所有路径中,长度最短的路径为最短路径,记为minr(o,d),其长度记为mind(o,d),称dist(o,d)-mind(o,d)为路径r(o,d)的绕行长度,记为a(o,d)。
在铁路运输实践中,a(o,d)经常有一定的范围,可用最短路长度mind(o,d)的相对倍数来表示;同时当mind(o,d)很大时,mind(o,d)倍数也将很大,造成绕行长度过大,在现实中不可能发生,所以a(o,d)应有一个绝对的最大控制值M;再则,为保持长路径和短路径绕行控制的一致性,一条铁路合理路径中,其子路径应全部满足同样的绕行控制,称满足以上绕行要求的路径为合理路径,即站点o至站点d的合理路径满足以下条件:
a(o,d)≤c×mind(o,d)且a(o,d)≤M
(1)
(其中c为大于1的数值,一般可取1~1.5);
a(i,j)≤c×mind(i,j)且a(i,j)≤M
(2)
(其中i∈r(o,d),j∈r(o,d),且i≠j)。
2 铁路网的简化
2.1 铁路网简化的概念
铁路网的复杂性一般以其所含站点和区段数量来衡量,实际铁路网的站点数量往往很大,如我国铁路网目前车站数达到6 000个以上,如果按照原始铁路网络进行多路径搜索计算,其时间复杂性和内存空间占用都将达到不可忍受或不可能的程度。所以,在实际应用中,都要将原始网络进行简化。如我国铁路OD统计将全国铁路划分为483个OD小区,将OD小区重心点作为路网站点,可大大降低网络复杂度,又对研究结论不会造成太大影响;李旭华[15]采用分层思想对网络进行分级,降低了路网复杂性。本节主要探讨在不改变路网多路径计算最终结果的情况下简化铁路网的方法。
2.2 铁路网站点分类及简化方法
为简化网络,将网络站点分为枝站点、中间站点和支点。采用递归定义法定义枝站点为在铁路网N(S,L)中相邻站点非枝站点数不大于1的站点。中间站点定义为在铁路网N(S,L)中相邻非枝站点数为2的站点。定义支点为既非枝站点又非中间站点的站点。
图1为15个站点的铁路网络。图中虚线框内站点为枝站点。有如下特征:一是和站点8组成一个树形结构;二是两两之间只有一条合理路径;三是删除这些站点后不会对其他站点间合理路径个数和长度有影响。
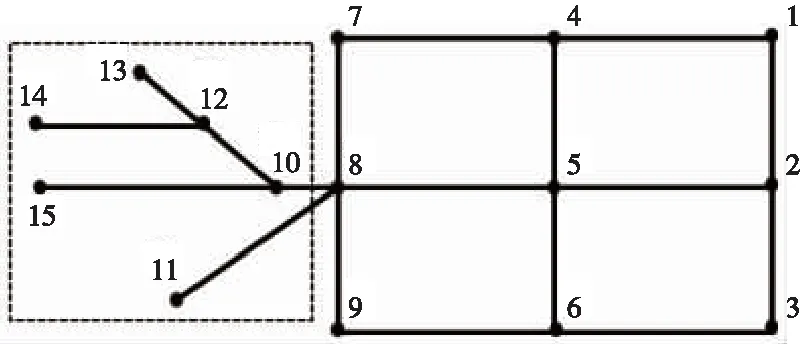
图1 铁路网简化情况示意
站点1、3、7、9为中间站点。有如下特征:一是相邻非枝站点数为2个;二是删除这些站点,并将其与2个相邻的非枝站点拼接后形成的网络,不影响其他站点间合理路径个数和长度计算结果。
站点2、4、5、6、8为支点。消除枝站点和中间站点后的路网称为简化路网N*(标记为不可简化的站点且不可删除)。铁路网多路径计算只需在简化路网上计算支点间的多条路径。
图1中,经简化后的路网只含5个支点,复杂度大大降低。
2.3 铁路网多路径检索
支点与支点间的多路径检索只需根据简化路网上的经由站点递归求出。
两站点都为中间站点的多路径检索,其路径须经由其相邻支点间路径。由于一个中间站点有两个相邻支点,所以共有4种路径组合方式,可通过穷举简化路网上4个相关支点间的路径并消除重复路径求出。两站点其中之一为中间站点的多路径检索为上述情况的特殊情形,可采用类似方法求出。
两站点中有枝站点的情况下,多路径检索分两种情况,一种为两枝站点在一个树形结构下,定义该树形结构的根为根站点,这时只有一条路径,可在原路网上向根站点回朔求出;另一种为其他情况,这时可由树形结构根站点代表相关枝站点进行多路径搜索求出。
3 铁路网多路径计算
一次计算所有站点间最短路径,比较有效的方法为Floyd法[16],但Floyd法仅能计算一条最短路径,为了计算K条较短路径,需扩展Floyd法。以下多路径计算采用扩展Floyd法的思路。
设有简化路网N*(S*,L*),|S*|=Q,Q为网络中支点数,需计算所有支点之间的前K条较短路径。
第一步:初始化。支点i到支点j间的第k短路径记为rout(i,j,k)={t,w,v,x,y}。其中t为标识数字,唯一标识支点i到支点j间的某条路径;w为该路径长度(权重);v为该路径所经由的支点;x表示经由支点i到支点v由x标识的路径;y表示经由支点v到支点j由y标识的路径。以上表示法可唯一确定N*中一条路径,通过递归函数可提取出路径所含站点序列。记K维向量R(i,j)={rout(i,j,k)|k=1,2,,K}。构造矩阵Dk={R(i,j)|i=1,2,,Q;j=1,2,,Q}。
对D0中rout(i,j,k)作初始化:对所有支点i=1,2,,Q和j=1,2,,Q,如果支点i和支点j相邻,则rout(i,j,1).w=w(i,j),rout(i,j,1).t=ID(某唯一标识数);否则rout(i,j,1).w=∞(无穷大,表示无此路径);对所有k=2,3,,K,rout(i,j,k).w=∞。
第二步:计算Dk,k=1,2,,K。依次由Dk-1计算Dk。
由rout(i,k,kx)和rout(k,j,ky)计算rout(i,j,kr),更新Dk-1,其中i=1,2,,Q;j=1,2,,Q,kx=1,2,,K,ky=1,2,,K。
对所有i,j,kx,ky作如下计算:rout(i,j,kr).w=rout(i,k,kx).w+rout(k,j,ky).w;rout(i,j,kr).v=k;rout(i,j,kr).x=rout(i,k,kx).t;rout(i,j,kr).y=rout(k,j,ky).t。如果rout(i,j,kr).w=∞,或者rout(i,j,kr).w≥rout(i,j,K).w,或者该路径不符合合理路径要求,则直接舍弃并计算下一条路径;否则rout(i,j,kr).t=ID(分配唯一标识数),将该路径按长度升序插入R(i,j)中,R(i,j)中最后一个元素自动舍弃。循环更新Dk-1,得到Dk。
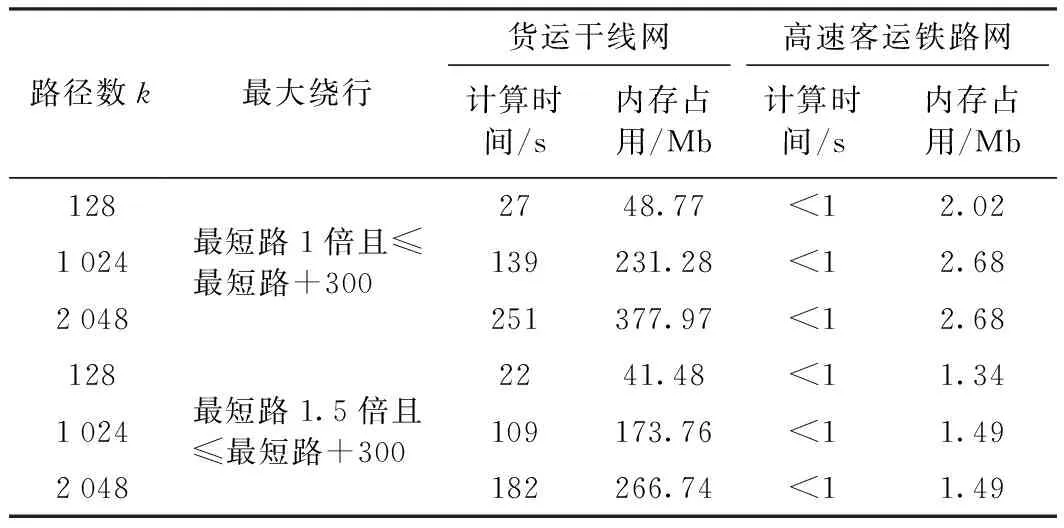
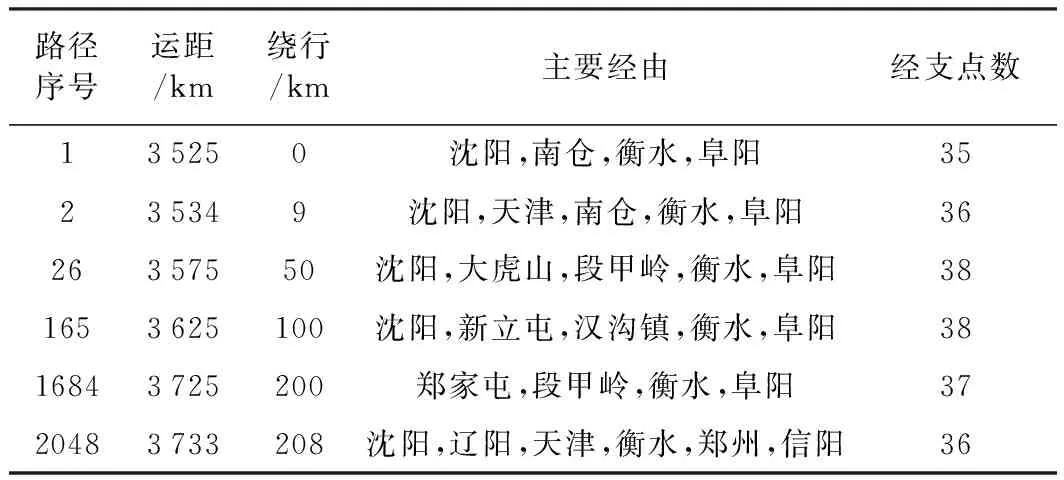
在铁路网中,利用w(i,j)=w(j,i),在第二步计算中,可只处理i Floyd算法时间复杂度为O(n3),其中n为网络节点数,由于本算法先对路网进行了简化,仅对铁路网中的支点应用Floyd算法,可有效降低计算时间。以全路货运干线网和高速客运铁路网为例,全路货运干线网站点为623个,简化后支点为287个,参加计算的站点数减少53.9%,则计算时间可降低90.2%;高速客运铁路网站点127个,支点100个,参加计算的站点数减少21.3%,则计算时间可降低51.2%。另外,本算法一条径路由五元数值组{t,w,v,x,y}表示,若每个数值占内存2字节,则仅用10个字节就可以唯一表示一条径路,内存占用较小。 采用C++11编程实现本算法,在4核CPU-3.30 GHz、4 G内存64位计算机上进行运算,测试结果如表1所示。 表1 计算时间和内存占用情况 可以看出,货运干线网上最大路径数达到2 048条时,计算时间在240 s左右,内存占用在400 Mb以下。对高速客运铁路网进行同样条件下的测试,计算时间普遍小于1 s,内存占用在3 Mb以下,一次计算完成后,下次查询任意两站点间的多路径将瞬间完成。 表2 哈尔滨至广州间主要路径情况 表2为货运干线网哈尔滨至广州间的主要路径,可以看出,路径中经由支点数普遍在35个以上,有海量合理路径,从第1 684条至第2 048条,绕行距离只增加8 km,要列举全部合理路径是不可能的。所以,在实际应用中,有必要对路网支点数和合理路径限制条件进行控制。 铁路网多路径搜索技术特别是全部站点间多路径的一次性计算,在铁路OD运量分配和车流优化等铁路规划、设计和运营工作中有着广泛的应用。全国铁路网站点多、区段数量大、计算复杂,在目前常规计算机配置下,寻求在可接受的计算时间和内存占用情形下,一次计算全部站点间多条较短路径的方法具有重要的现实意义。 铁路网多路径搜索的实质为KSP问题,解决全部站点间KSP问题,扩展Floyd法较优。实际测试表明,即使在全路复杂的货运干线网中计算2048条较优路径,Floyd方法计算时间和内存占用效果仍然较好,对解决全部站点间KSP问题具有较高的实用价值。现代计算机一般配备多核,利用多核计算机并行计算技术的优化算法,本方法计算时间还有较大的提升空间。4 效果分析
5 结束语
