属性排序的粗糙集和统计方法研究
2018-10-17张先韬
张先韬
(1.中煤科工集团重庆研究院有限公司, 重庆 400039;2.瓦斯灾害监控与应急技术国家重点实验室, 重庆 400039)
粗糙集是数据处理方法中的一种有效的软计算工具,由波兰数学家Pawlak于1982年提出[1]。它是一种刻画不完整性和不确定性问题的新型数学工具[1],能有效分析和处理不精确、不一致、不完整等各种不完备的信息,并从中发现隐含的知识,揭示潜在的规律[1]。 经过多年发展,随着大数据、互联网、移动应用、智能算法等的不断发展和现实应用需求的不断提出,粗糙集理论和方法被越来越多的行业领域和专家学者所使用[2-11]。在医疗、机器学习、模式识别、数据处理、互联网等多个行业和领域均发挥着其作用,而且越来越多的地方正在探索和尝试使用粗糙集方法与其他方法交叉结合以期对所研究问题获取更好的解决方案[2-11]。
在粗糙集理论中,属性约简是将数据库或数据系统中的信息进行合理的筛选,将冗余信息屏蔽或删除,大大简化数据信息表达而不影响研究需求或简化信息至可控范围[8]。在经典粗糙集理论中,计算信息表中各属性的重要度,可以计算出各个属性的重要性数值度量,直接进行属性重要性量化比较并进行排序。在多学科交叉研究中很多学者采用粗糙集方法进行排序、评价、预测研究[9-11],对部分数据表的信息研究是一个很好的方法,但是这种计算方法也有缺陷。在信息系统中计算属性重要度可能存在数值相同的情形,这种情形很普遍[12],对于很多研究产生了局限性,单纯使用粗糙集方法不能满足属性重要性唯一链式排序的研究需求。本文在研究中将粗糙集方法和统计学方法相结合,使用层级计算的方式,在同一标准下解决小规模数据系统中属性重要度相同无法进行属性重要性唯一链式排序的实际需求。
1 粗糙集基础知识
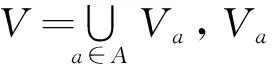
在决策中,对于每个子集B⊆C,定义[12-13]IND(B)={(x,y)∈U2|f(x,b)=f(y,b), ∀b∈B}[12-13]。IND(B)是等价关系,可以不加区分地用B表示。对任意的B⊆C和x∈U,记[x]B={y∈U|f(x,a)=f(y,a), ∀a∈B},称[x]B是对象x在属性集B下的等价类。记U/B={[x1]B, [x2]B,…,[xn]B},称U/B是属性集B对论域构成的划分[12-13]。
在信息系统I=(U,A,V,f)中,对子集X⊆U和属性集B⊆A,定义[12-13]:
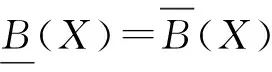
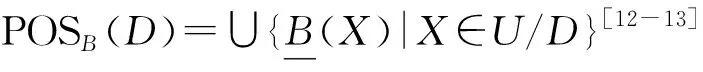
建立数据表并使用粗糙集方法进行研究,目的就是从数据表中去掉对于分类没有影响的条件属性或子集,去掉后不影响系统的分类能力,即保持其知识表达能力不变,这个过程就是属性约简。在粗糙集理论中,通过计算属性重要度或其他方法可以获取信息系统的约简,在小规模信息系统中,约简可以穷举。在某些实际问题研究中可以通过计算属性重要度对属性重要性程度进行排序,重要度为0的属性去掉以后不影响信息系统的知识表达。该方法计算的属性重要度可能存在数值相同的情形,在不允许出现并列的排序问题中,需要进一步处理区分数值相等的属性的重要程度以期获得唯一性排序。下面介绍研究中使用粗糙集属性重要度、约简结合统计学方法进行属性排序的处理方法。
2 基于粗糙集属性重要度的一级排序
以研究中使用的决策表为例[13-16],数据表为重庆市冬夏季节碳排放影响因素研究数据采样统计结果,数据表有136个不重复对象,决策属性D1、D2分别为冬季、夏季碳排放量,条件属性a1~a11为影响住宅建筑碳排放的11个影响因素,分别为住房归属、建筑使用时间、建筑层数、所住楼层、住房面积、家庭平均年龄、家庭常住人口数、最高文化水平、家庭人均年收入、节能意识、能耗设备平均使用年限,各属性值的意义不影响本文所述研究方法的使用,故不再给出。因篇幅原因,决策表数据不宜在本文中全部给出,表1给出简表。
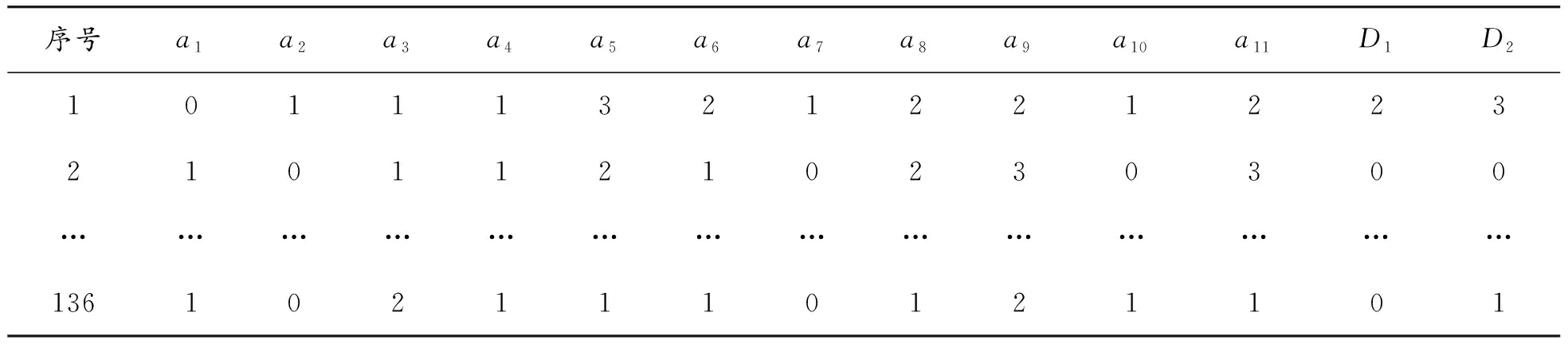
表1 决策数据表(简表)
首先使用本文提到的粗糙集属性重要度的计算方法计算各个属性的重要性度量,这种计算方法科学合理,使用粗糙集方法进行不确定信息处理和数据挖掘过程中已经被广泛使用,通过这种方法进行量化计算和排序准确可靠,计算得到在不同决策下各个属性的重要度如表2所示。
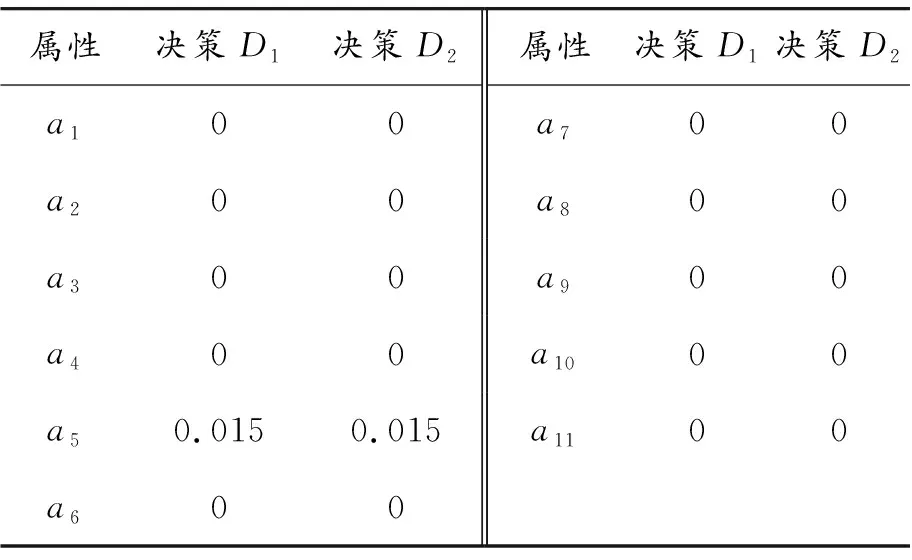
表2 属性重要性的数值度量
据表2可知:决策D1数据表中属性a5的重要度为0.015,a5比其他单个属性重要。决策D2数据表中属性a5的重要度为0.015,a5同样比其他单个属性重要。计算属性重要度进行重要性排序是综合数据表信息的全局宏观信息排序,属性重要度大的在重要性排序中占全局靠前,但是对于其他属性而言,单个属性的属性重要度均为0,无法通过计算属性重要度的方法决定这些相对重要属性重要程度的全局排序,无法对属性进行唯一链式排序,结果不能直接适用于所研究问题。为了通过数值度量计算和区分各属性的重要性,体现出各个属性的不同影响程度并实现排序,下面给出结合粗糙集约简理论和统计方法的属性排序方法。
3 基于约简的属性频次统计二级排序
本文第2节使用粗糙集属性重要性度量计算了各属性的重要度数值,但不能满足所研究问题的需求,本节介绍使用粗糙集约简理论和统计方法的二级排序方法。为了实施本节处理方法,需要使用粗糙集约简理论计算该决策表在决策D1和D2下各自的全部约简。由于所研究问题获取到的决策表数据规模较小,可以对该决策表约简穷举。
根据统计学理论和约简的意义,在穷举得到的所有约简中,单个属性出现的频数差别可以体现属性的重要程度,出现次数越多属性越重要。频数又可以除以所有约简的数量转换为比例数值,通过数值化的统计结果可以对属性的重要程度进行排序。这是一种按照等级的排序,频数(比例)越大重要等级越高,频数(比例)越小重要等级越低,频数(比例)相同重要等级相同。此方法使用统计学原理,可以保证数据表信息的客观性和正确性,从全局信息出发保持数据表信息不变的情况下得到统计数据结果,方法有理论依据支持,计算得到的数值度量结果科学可靠。由此,将得到的约简进行转换,使用数据表表示,用表格的形式表示对象的有无(0表示约简中无该属性,1表示约简中有该属性),简表见表3。
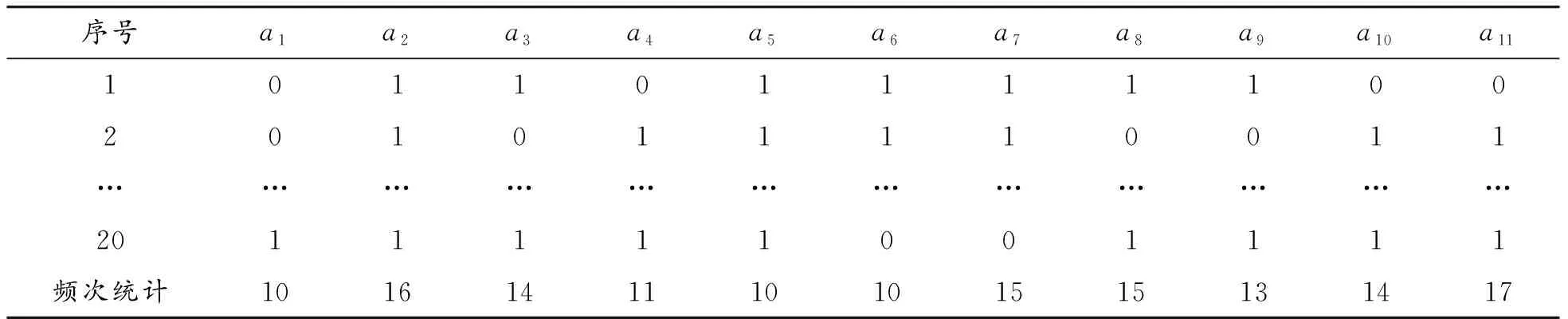
表3 决策D1数据表约简的数据表(简表)
根据表1、3可以按照本节所述频次统计法计算得到不同决策下属性重要性的有效数值度量,见表4。
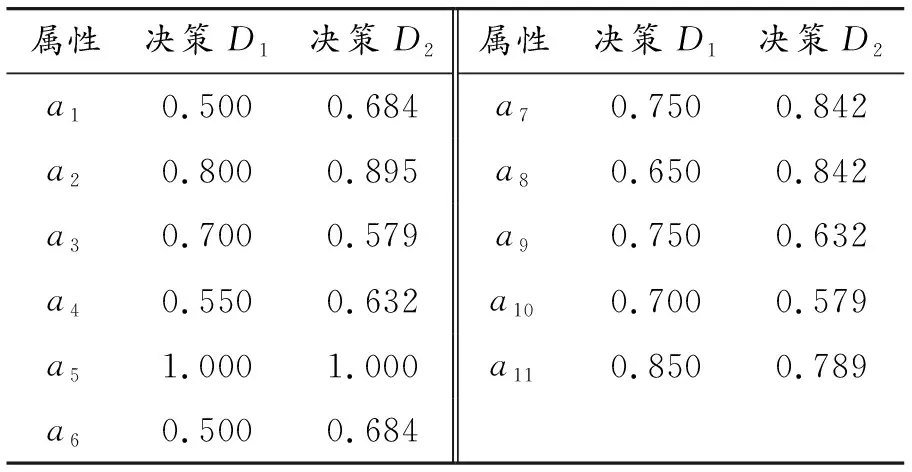
表4 属性重要性的数值度量
由此可以在不同决策下进行属性重要性由高到低的初次排序,结果见表5。
从表5可知:使用粗糙集属性重要度的计算方法得到的属性排序中,对冬季决策而言属性a9和a7重要性相当、a10和a3重要性相当、a6和a1重要性相当,对夏季决策而言属性a7和a8重要性相当、a6和a1重要性相当、a9和a4重要性相当、a10和a3重要性相当。在排序过程中使用粗糙集的属性重要度无法区分这些数值量相同的属性的重要性程度,在所研究的问题中无法完成排序问题的最终结果。为了区分这些属性以实现研究问题所需的属性排序,下节介绍一种基于约简的属性影响程度均值三级排序方法。
4 基于约简的属性影响程度均值三级排序
在获取全部约简后,在约简中去掉某属性后属性子集的重要度会减小,可以使用这一点量化计算重要度变化值的平均值(称为平均影响程度),以实现属性的重要性(影响)区分。某属性的重要度变化越大则其在约简中的影响/作用就越大,这符合客观规律和理论实践,根据平均值理论全部约简中这种影响的平均值越大则该属性的影响越大,可以视为该属性越重要,由此可以由定量计算转换成定性排序。
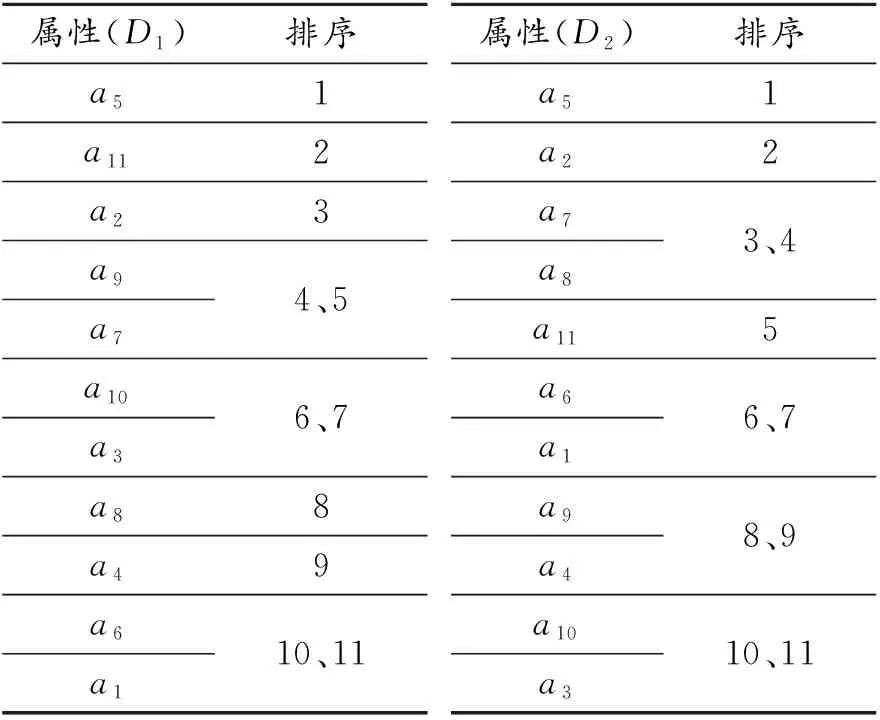
表5 决策表重要性由高到低二级排序
粗糙集属性重要度数值计算是基于数据表全局信息的量化计算方法,本节是基于数据表局部细化信息的量化计算方法。这种考量方法执行细节计算,实现从定量到定性的局部转换,比粗糙集属性重要度计算的方法等级或层次、级别低,可作为辅助计算方式,但是这种考量方法仍保持在同一标准下执行数值计算比较,任何一个约简均包含不影响系统研究的全部信息(不改变系统分类能力),执行数值差计算时考量的是全局约简和同一属性,计算结果使用平均值度量,这样计算未改变度量标准和全局信息,具有可行性和说服力,可以获得理论和实践上的有效支撑,在本文所引用的实际问题中可以发挥作用,用来区别两个属性的重要程度。称这种方法为基于约简的影响程度均值三级排序方法,下面介绍该方法的具体实施过程。
在决策D1数据表中为了区分a7、a9,分别计算其所在约简的重要度和去掉这个属性后的属性子集的重要度,对这两个数值作差,然后对得到的这些数值求平均,平均值越大属性重要性越大,由此实现这两个同等级属性的重要性排序,对于冬季碳排放决策表中的a3、a10和a1、a6和夏季碳排放决策表中的同等级属性均采用此方法进行重要性区分排序。对冬季碳排放影响因素中重要程度概率结果相同的属性进行区分计算,计算结果如表6、7所示。

表6 决策D1数据表中属性a7的平均影响程度计算

表7 决策D1数据表中属性a9的平均影响程度计算
由表6、7可知:在决策D1数据表中属性a9的平均影响程度比属性a7大,在重要性排序中a9比a7重要。对决策D1数据表中的属性a3、a10和a1、a6,可以使用相同方法进行计算。a3的平均影响程度为0.202,a10的平均影响程度为0.222,在重要性排序中a10比a9重要;a1的平均影响程度为0.122,a6的平均影响程度为0.297,在重要性排序中a6比a1重要。使用同样的方法可以对决策D2数据表中的4组同等级属性a7与a8、a6与a1、a4与a9、a3与a10进行计算,通过计算结果可知a7比a8重要,a6比a1重要,a9比a4重要,a10比a3重要。根据上面计算可以对决策D1、D2数据表的属性再次进行排序,如表8所示。
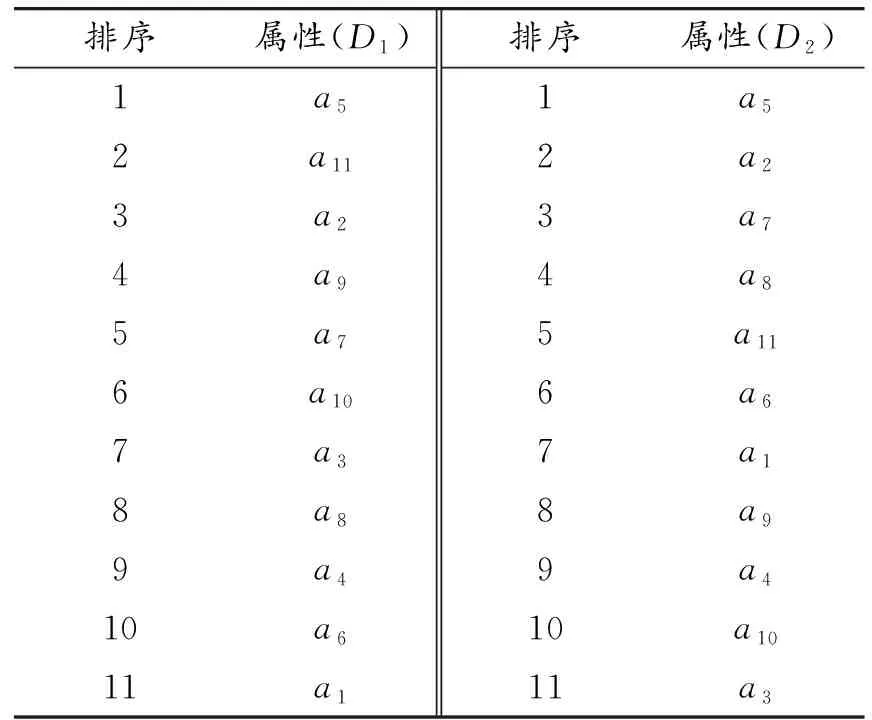
表8 决策表属性重要性由高到低三级排序
至此,经过粗糙集重要性度量、频次统计法、影响程度均值法三级排序即实现了所研究问题的数值度量计算,实现了属性重要性的唯一链式排序。11个影响因素对碳排放影响程度的综合排序结果为:
夏季a5住房面积>a11能耗设备平均使用年限>a2建筑使用时间>a9家庭人均年收入>a7家庭常住人口数>a10节能意识>a3建筑层数>a8最高文化水平>a4所住楼层>a6家庭平均年龄>a1住房归属;
冬季a5住房面积>a2建筑使用时间>a7家庭常住人口数>a8最高文化水平>a11能耗设备平均使用年限>a6家庭平均年龄>a1住房归属>a9家庭人均年收入>a4所住楼层>a10节能意识>a3建筑层数。
根据实际经验和相关研究结果可以判断上述结果的正确和可信,文中所使用的方法科学有效。
5 层级式计算金字塔模型
对本文引用的研究问题,以往研究中普遍使用的方法为调查统计法,需要大量的样本数据,这些样本数据需要进行特定的设计和数据处理,还需要假设很多情景和满足某些要求,其获取的数据结果基于问卷调查统计结果和统计数据,工作强度大、工作难点多,在属性排序研究中往往因为各种原因不能很好地进行排序或排序结果不客观,甚至只是使用分析的方法进行属性排序,不能很好地做到属性排序的数量化考量。本文所使用的方法可以免去很多繁琐的工作,针对所研究问题,获取采样数据的规律,这种采样数据获取渠道比较简单和客观,从获取的数据表中挖掘潜在的客观事实,是粗糙集理论应用于创新实践的一次有益尝试。本文所用方法获取的排序结果可以量化处理,排序结果与以往研究方法中获取的结果一致且优于以往结果,属性排序结果符合统计规律、经验和直观理解。
本文针对研究中遇到的属性排序问题使用粗糙集方法和统计学方法,分三级量化计算完成属性重要性程度各级定量计算和全局定性排序。
粗糙集属性重要度计算方法为初次排序使用方法,使用决策表全局信息计算属性重要性数值度量,由粗糙集属性重要度定义直接得到,未进行任何辅助处理,在分层级计算过程中其等级最高,为基于决策表全局宏观信息的计算,在层级计算过程中排居第1级。
在粗糙集属性重要度计算不能区分属性排序的情况下,引进统计学中的频次统计法,通过可穷举的约简中属性出现的频次计算数值度量,使用该度量体现属性的重要性程度,该过程引进统计学方法间接计算,其理论依据扎实可靠,既包含全局约简的宏观信息,也包含在约简中使用统计方法的微观信息,在层级计算过程中其等级排居第2级。
对于频次统计结果相同的情况,进一步使用影响程度均值计算法,通过在穷举的约简中考虑去掉某属性后的影响,计算该影响的均值,辅助性区分属性的重要性程度,该方法使用粗糙集理论中属性重要度和约简的意义在所对比属性所在约简不完全相同的情况下从微观角度细分综合考量属性的影响程度的均值。均值法和穷举约简保证数值度量的客观性和科学性,计算结果在此步计算中可靠可信,可以区分属性的重要性程度,因该方法在计算数据过程中不同属性所在的约简可能存在差异,故将此方法应用于层级计算的第3级。
针对本文研究的属性重要性排序层级计算方法,各层级计算的过程包含宏观到微观的变化和过渡,每级计算均执行统一度量标准,这种计算过程和每个方法均有理论支撑,包括粗糙集理论、统计学方法、平均值方法等,其层级和执行过程可表示为金字塔形状,如图1所示。
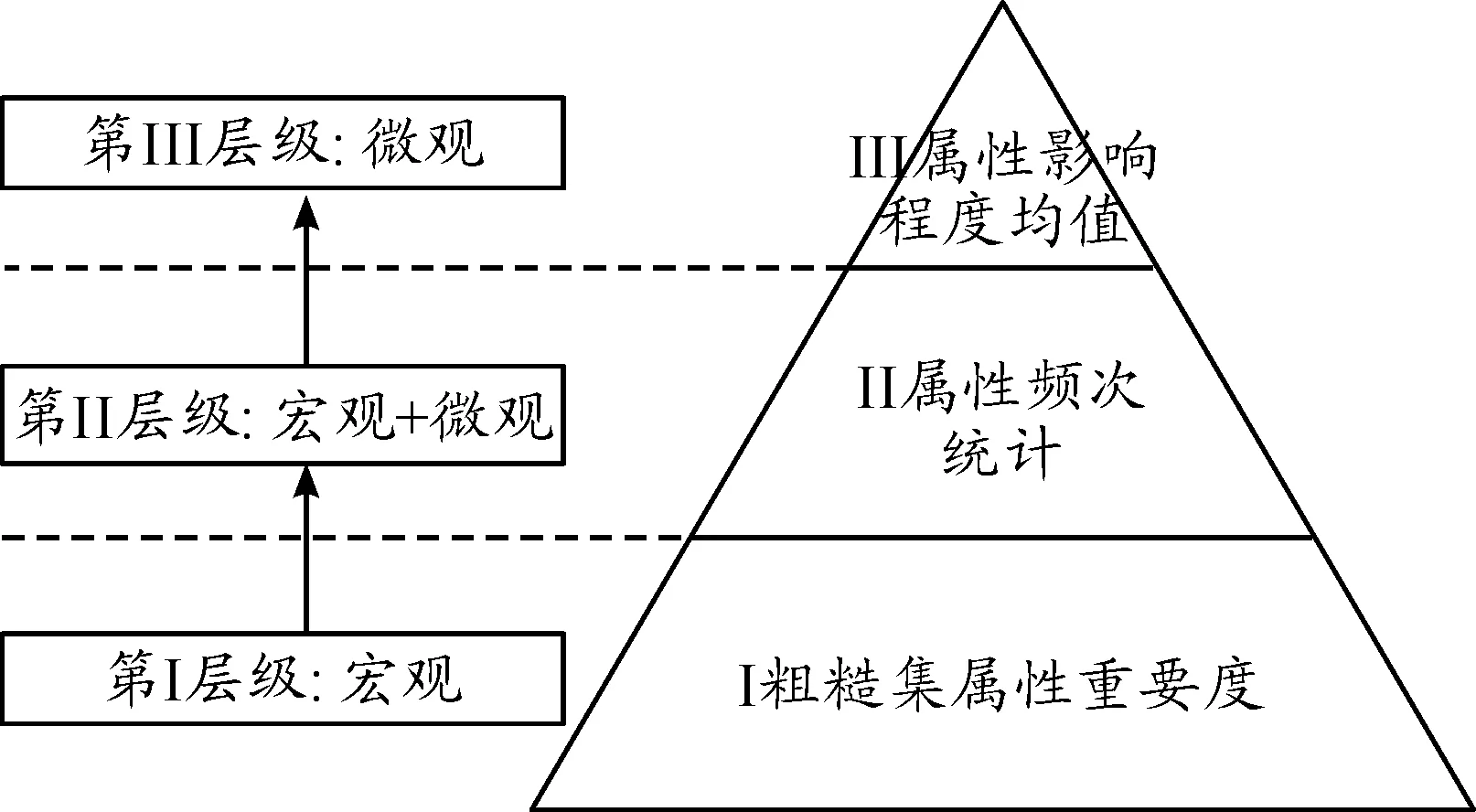
图1 层级计算金字塔模型
本文所研究层级式解决方法的金字塔表示可以直观反映各层级计算的等级和权重,执行层级算法的过程实际上是问题由宏观到微观细化处理的过程,称为层级式计算的金字塔模型。在应用问题处理过程中,可以根据需要进行处理,按需选择是否执行下级计算。
对第1层级的计算方法,除粗糙集理论中最原始的属性重要度,有可能需要使用其他扩展的重要度计算方法[17],或者使用信息熵等其他度量,在实际问题中可能需要进行方法的选择。针对不同问题可能选择使用不同的粗糙集模型,比如变精度粗糙集、序信息系统、多粒度系统、多论域系统等,其对属性重要度的计算和层级式计算的细化处理可能有所差别,本文所使用的研究方法和思路均可为各种类似问题提供参考。
6 结束语
针对本文引用的研究问题,通过三级计算的方式,实现了研究问题所需的链式唯一排序,对于实际问题的研究具有很重要的突破,使用粗糙集不确定性推理和数据挖掘的理论优势对所研究问题进行科学处理,获得了科学、良好的数据结果。本文所研究的方法适用于约简可以穷举的决策表;对于约简不能穷举的决策表,本文方法具有一定的参考意义。从多数赞成的客观规律和粗糙集包含度理论的研究角度,对约简不能穷举的决策表,本文方法在约简的使用过程中可以考虑使用可得到的大多数约简进行计算,其结果也具有一定的参考价值,尤其是在大数据研究中,在进行数据处理时,可能不会使用全部的数据结果(约简),使用多数赞成和包含度的处理方法可以实现在不同精度下不精确推理的数据处理。本文研究方法对于应用问题的研究和处理具有很好的参考价值。
