基于深度残差生成对抗网络的医学影像超分辨率算法
2018-10-16秦品乐王丽芳
高 媛,刘 志,秦品乐,王丽芳
(中北大学 大数据学院,太原 030051)
0 引言
图像超分辨率技术是指从一幅或多幅低分辨率图像运用技术手段获得对应的高分辨率图像,在医学影像[1-2]、面部识别[3]、卫星图像[4]等场景拥有广泛应用。
目前超分辨率技术主要有3类[5],即基于插值[6]、重建[7-8]和学习[9]的方法。基于插值的方法如双线性内插(Bilinear interpolation, Bilinear),最近邻插值(Nearest-Neighbor interpolation, NN)[5]和双三次插值法(Bicubic)[10],该类方法计算时以假设图像像素的灰度值连续变化为前提,使用邻近区域像素点的灰度值来计算要插入的像素灰度值,却没有考虑到图像的复杂性。该类算法比较简单、复杂度低、适应性不强,使得生成的图像边缘轮廓比较模糊,视觉上过于平滑,容易产生方块现象。基于重建的超分辨率技术如迭代反向投影法[11-12]、最大后验概率方法[13]、凸集投影法[14]。此类方法利用低分辨率图像作为约束前提,并结合图像的先验知识来重建出高分辨率图像, 在一定程度上缓解了基于插值方法产生的方块现象,效果上有较好的改善,但当放大倍数较大或输入图像尺寸较小时,能有效利用的先验知识较少,不足以满足高分辨率的需求,重建出的效果也较差。基于学习的方法,该类方法通过学习高、低分辨率图像间的关联,利用样本图像的先验知识来重建高分辨率图像,相比其他方法有较大优势。近年来,由于深度学习在诸多领域取得的成功,使得基于深度学习的超分辨率重建方法成为研究的热点。2014年,Dong等[15]率先将卷积神经网络应用于图像超分辨率领域中,提出使用卷积神经网络的超分辨率(Super-Resolution using Convolutional Neural Network, SRCNN)算法,该算法通过3层的卷积神经网络结构学习低分辨率到高分辨率的关联关系,重建出的高分辨率图像效果相比传统方法有很大改善,但3层的网络层次结构太浅,难以获得图像深层次的特征。之后,Dong等[16]又提出了快速的超分辨率卷积神经网络算法,该算法对SRCNN算法进行了改进,将3层的卷积神经网络结构加深到了8层,同时对低分辨率图像的上采样用反卷积取代了双三次插值,取得了比SRCNN更好的效果,但8层网络结构依然较浅,重建出的效果有限。Kim等[17]提出基于深度递归神经网络 (Deeply-Recursive Convolutional Network for image super-resolution, DRCN)的超分辨率算法,相比SRCNN较小的局部感受野,DRCN算法通过增加局部感受野大小来进一步利用更多的邻域像素,同时该算法使用递归神经网络减少过多的网络参数,取得了较好的效果。Ledig等[18]将深度学习中热门的生成对抗网络(Generative Adversarial Network, GAN)应用于图像的超分辨率重建中,提出了基于生成对抗网络的超分辨率 (Super-Resolution using a Generative Adversarial Network, SRGAN)算法,该算法将低分辨率图片样本输入到生成器网络训练学习,来生成高分辨率图片,再用判别器网络辨别其输入的高分辨率图片是来自原始真实的图片还是生成的高分辨率图片,当判别器无法辨别出图片的真伪时,说明生成器网络生成出了高质量的高分辨率图片。实验结果表明相比其他深度学习方法,SRGAN算法生成的图片效果在视觉上更逼真。
将低分辨率的医学影像进行超分辨率重建,可有效提升影像清晰度,重建后的高清医学图像能使医生更清楚看到组织结构和病变早期发现病情,为医生对疾病作正确的判断作辅助诊断,为医学影像的研究、教学、手术等提供支持。目前超分辨率重建在自然图像上研究众多,在医学影像上的研究还不够丰富,不同于自然图像,大多数医学图像纹理更复杂,细节更丰富,黑白的颜色没有彩色那般更好的视觉辨识度,所以保留纹理细节不丢失成为医学超分辨率重建的关键。
鉴于基于深度学习的超分辨率重建方法生成的图像质量高、视觉效果好,本文在最新的SRGAN基础上,通过使用缩放卷积、去掉批量规范化层(Batch-Normalization, BN)、增加特征图数量、加深网络等对SRGAN作出改进,提出了基于深度残差生成对抗网络(Deep Residual Generative Adversarial Network, DR-GAN)的医学影像超分辨率算法,来达到对医学影像放大2倍后仍然保留较多的纹理和细节特征的目标。
1 相关理论
1.1 生成对抗网络
生成对抗网络(GAN)由Goodfellow等[19]提出,它启发自博弈论中的二人零和博弈。GAN强大的图片生成能力,使其在图片合成[20]、图像修补[21]、超分辨率[18]、草稿图复原[22]等方面有直接的应用。
GAN的基本框架包含一个生成器模型(Generative model, G)和一个判别器模型(Discriminative model, D),GAN的过程如图1所示。
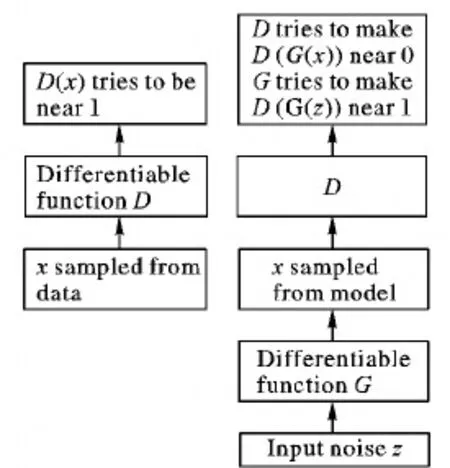
图1 GAN的基本框架
如图1所示的GAN的基本框架中, 生成器模型用可微函数G(x)表示,判别器模型用可微函数D(x)表示,每个函数都有可调参数。GAN过程中有两个场景:第一个场景中,从真实训练数据中采样x,作为判别器模型D(x) 的输入,D(x)通过自身的训练学习,尽可能地输出接近1的概率值;第二个场景中,从先验分布中采样z,经生成器模型生成伪造样本G(z),将其作为判别器模型的输入,判别器模型的目的尽量使D(G(z))接近0,而生成器模型的目的尽量使它接近1,最终在二者的互相博弈中达到平衡。
原始的生成对抗网络理论中,并不要求生成器和判别器都是神经网络,只需能够拟合出相应的生成和判别的函数就可以,但是,由于神经网络在图像处理方面的较好效果,所以,本文设计生成器和判别器均为神经网络结构。
1.2 残差和快捷连接
残差网络(Residual Network, ResNet)和快捷连接(Skip Connection)由He等[23]提出,该网络结构使得更深的网络更容易训练,因而可以通过增加网络层数提高识别准确率。
残差块的基本结构如图2所示。

图2 残差学习:基本残差块
如图2所示,残差网络在原始的卷积层上增加跳层快捷连接支路Skip Connection构成基本残差块,使原始要学习的H(x)被表示成H(x)=F(x)+x。残差网络的残差结构使得对H(x)的学习转为对F(x)的学习,而对F(x)的学习较H(x)容易。残差网络通过层层累加的残差块结构,有效缓解了深层网络的退化问题,提高了网络性能。
由于残差网络的残差块(Residual Block)和快捷连接的结构,改善了网络深度增加带来的梯度消失和网络退化问题,提升了深度网络的性能。鉴于残差网络结构近年来在图像生成任务上的优异成绩,本文将改进算法的生成器部分设计成基于残差网络的神经网络结构。
2 基于DR-GAN的医学影像超分辨率算法
2.1 改进思想
神经网络的结构、宽度和深度等是影响网络性能的重要因素。在网络结构方面,本文借鉴文献[24]提出的缩放卷积思想采用缩放图片再卷积的上采样层来尽量削弱棋盘效应的出现,借鉴文献[25-26]作超分辨率对原始的ResNet去掉BN层节约显存获得性能提升的做法,本文将SRGAN的标准残差块去掉BN层,来建立一种新的残差块结构,以此简化残差块结构达到优化网络的目的。在网络宽度方面,本文借鉴文献[25]在有限内存时增加特征图通道数比加深网络更有效的做法,将原始SRGAN的判别器进一步增加特征图数量,由于过多的特征图数量易使网络不稳定,所以本文算法通过增加快捷连接使网络更稳定、更易训练来提升网络性能。在网络深度方面,受到文献[27-29]显示更深网络能够建立高复杂度映射,极大提高网络精确性的启发,本文算法通过增加网络的深度来提高网络的性能。由于过深的网络难以训练,所以改进方法将生成器部分的残差块数量由原有的16个增加到32个,网络深度增加了16层。
综上所述,本文提出的DR-GAN改进原有SRGAN主要是通过用缩放卷积的上采样层(ResizeLayer)替换原始SRGAN的亚像素层,将SRGAN的标准残差块去掉BN层,增加原始SRGAN判别器的特征通道数并添加快捷连接改进原始判别器参数,增加生成器部分的残差块数量来加深网络层次。
2.2 DR-GAN算法的网络结构
由2.1节所述的改进思想,将改进的措施应用到本文的研究,设计的整个网络结构如图3所示,其中生成器网络结构如图3(a)所示,判别器网络结构如图3(b)所示。

图3 DR-GAN网络结构
2.2.1 生成器
如图3(a)所示的生成器网络参数,改进生成器网络的参数设置与原始SRGAN略有不同。具体来说,输入的低分辨率图片,先进入卷积层进行卷积操作,卷积层参数设置为3×3×3×64,即64个3×3 过滤器,3个通道,步长为1,再填补适宜的0用以保持图片尺寸;借鉴文献[25]使用整流线性单元(Rectified Linear Unit, ReLU)提升性能的思想,本文使用ReLU替换原始SRGAN的参数化整流线性单元激活,达到评价指标的提升,然后依次进入到32个相同残差块网络中训练学习;特别地改进的每个残差块都去掉了BN层并使用Skip Connection的方式易于网络的训练,从32个残差块输出后接着进入卷积层然后使用Skip Connection,接着上采样将图片放大2倍,上采样操作采用缩放卷积的做法,先用最近邻插值将图片放大2倍后再进入卷积层,最后通过卷积操作后输出高分辨率图片。
2.2.2 判别器
如图3(b)所示,改进的判别器的网络结构和参数设置与原始SRGAN的不同。具体来说,输入待判别的高分辨率图片,先经过5层的卷积层抽取图片特征,不同于原始的SRGAN,为了增大局部感受野,采用4×4尺寸的卷积核,并进一步增加特征图数量,即像VGGNet[27]那样,卷积层通道的数量从第一层的64个开始,每层的通道数以2倍递增,直到第5层的1 024个;接着经1×1卷积核的卷积层进行降维,然后经层层的卷积操作并使用Skip Connection使网络顺畅训练,再将图片数据的维度压平(Flatten)再经全连接层(Fully Connected layer, FC)后经Sigmoid输出判别的结果。
2.3 代价函数
代价函数的选择是深度学习算法设计中的一个重要部分,由于交叉熵[30]可以用来衡量两个分布之间的相似程度,均方差的高效性,交叉熵和均方差损失函数在深度学习代价函数设计中的广泛应用,所以本文算法选取均方差以及训练数据和模型预测间的交叉熵作为代价函数。如式(1)~(8):
LDR-GAN={min(LD),min(LG)}
(1)
其中,LDR-GAN表示DR-GAN算法的损失函数,LD为判别损失函数,LG为生成损失函数,网络训练的目的为最小化LD和LG。
LD=Ld1+Ld2
(2)
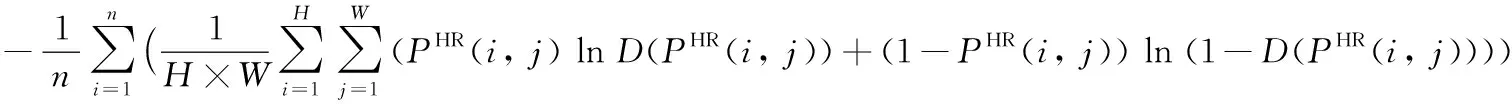
(3)

(4)
其中:PLR为网络输入的图片,PHR为供参照的原始高清图片,n为小批量样本(mini-batch)大小,本文n=16。H、W分别为图片的高度和宽度,D(PHR(i,j))表示真实高分辨率图片训练数据输入判别器的结果,G(PLR(i,j))为图片经生成器后的生成结果,Ld1表示真实高分辨率图片训练数据输入判别器判断后的输出结果与其真实值(为1)的交叉熵。Ld2表示低分辨率图片输入生成器生成的高分辨率图片再输入到判别器的判别结果与其真实值(为0)的交叉熵。
LG=LMSE+10-3Lg+2×10-6LVGG
(5)
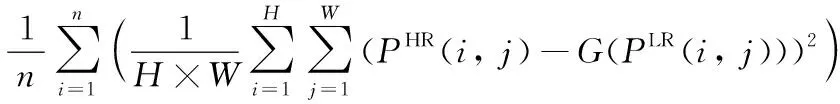
(6)
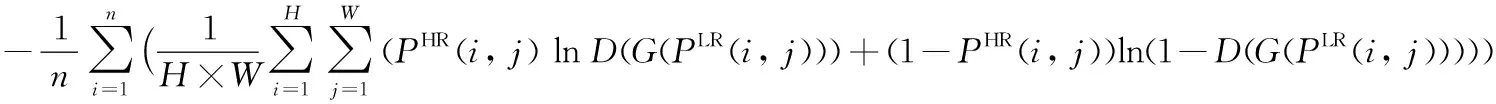
(7)
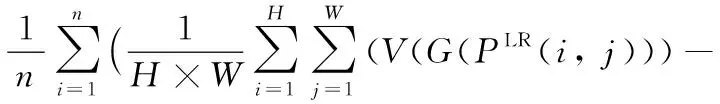
V(PHR(i,j)))2)
(8)
其中:V(PHR(i,j))为真实高分辨率图片输入到预先训练好的VGG19[27]网络模型的输出结果,V(G(PLR(i,j)))为低分辨率图片用生成器生成的结果输入到预先训练好的VGG19网络模型的输出结果,LMSE表示PHR与G(PLR(i,j))像素之间的损失,Lg表示低分辨率图片输入生成器后的生成结果再输入到判别器的判别结果与真实值(为1)的交叉熵。LVGG表示V(G(PLR(i,j)))与V(PHR(i,j))像素之间的损失。
2.4 训练过程:
采用mini-batch的训练方式,因为实验硬件GPU显存的限制,mini-batch设置为16张图片。训练时,对每个mini-batch的每个真实高分辨率图片随机裁剪96×96的子图片,接着对此高分辨率96×96的子图片用目前主流做法使用Bicubic下采样2倍得到降质的低分辨率48×48图像,然后把这个mini-batch的真实高分辨率子图和对应的低分辨率降质图片输入到判别器和生成器网络中进行训练,同时使用Adam优化算法在训练过程中促使判别损失和生成损失函数达到最小来不断更新网络的参数。初始学习率设置为1×10-4,实验迭代12 000次,每隔6 000次将学习率减小,变为原来的0.1倍,以达到训练最优的目的。
算法伪码实现如下:
for number of training iterations do
Sample minibatch of HR train set to randomly cropPHR:512×512 toPHR_sub:96×96
use Bicubic downsamplePHR_subtoPLR_sub:48×48
PLR_subinput the Generative Model to generatePfake
PHR_sub,Pfakeinput the Discriminative Model to discriminate thePfake,Adam Optimizer minimize theLDto update the Discriminative network
Adam Optimizer minimize theLMSE,Lg,LVGGto update the Generative network
end for
3 实验仿真与结果分析
本文实验使用的是美国国家肺癌中心的数据集[31],并从中挑选了清晰度高、纹理丰富、细节复杂的304张512×512高质量的图片来训练。
本实验环境包括硬件环境和软件环境。实验测试所用的硬件设备是一台Intel Xeon服务器,搭载2块NVIDIA Tesla M40的GPU,每块显存12 GB,共24 GB。实验软件,平台是64位Ubuntu 14.04.5 LTS操作系统,Tensorflow V1.2,CUDA Toolkit 8.0,Python3.5。
3.1 实验与结果
为了验证说明本文算法超分辨率重建图片的效果,特别选取了常见的具有典型性的3种传统超分辨率方法和2种具有代表性效果较好的基于深度学习的超分辨率方法。3种传统超分辨率方法是Bilinear、NN和Bicubic,2种基于深度学习的超分辨率方法是DRCN和SRGAN。为了公正地对比各算法,各个算法均统一在搭载GPU 为NVIDIA Tesla M40,Tensorflow V1.2的Intel Xeon服务器实验环境下使用Python3.5实现仿真。Bilinear、NN和Bicubic的结果与迭代的次数无关,DRCN、SRGAN和DR-GAN均迭代12 000次,初始学习率设置为1×10-4,每隔6 000次将学习率减小,变为原来的0.1倍。
为了验证各超分辨率算法的处理效果,显示实验结果的客观合理,选取4幅有代表性,肺部气管、肺泡、胸廓等细节复杂,纹理丰富的肺部影像进行对比测试。实验结果如图4所示。
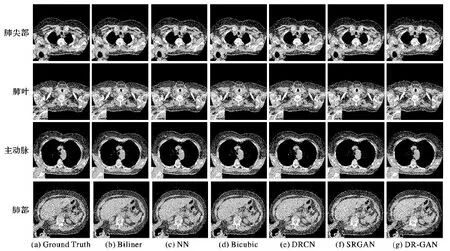
图4 各方法超分辨率效果对比
3.2 评价指标
由于峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[32]和结构相似性(Structural SIMilarity, SSIM)[33]被广泛地作为图像压缩、修复后评价图像质量优劣的检测手段,本文也选用PSNR和SSIM作为超分辨率重建算法重建图像质量的参考评价指标,并将整个数据集的PSNR和SSIM数据平均化,将整个数据集上的平均峰值信噪比(Mean Peak Signal-to-Noise Ratio, MPSNR)和平均结构相似性(Mean Structural Similarity, MSSIM)也纳入重建图像质量的参考评价指标。
同时,算法超分辨率重建出高分辨率图片所耗费的时间也是衡量算法优劣的重要因素。为了评价本文算法与其他算法的优劣,本文将算法的耗时也作为评价算法的参考指标。
3.2.1 客观效果
为了客观显示本文算法与其对比的各个算法的效果,对图4各算法超分辨率重建后的图片分别与最左侧的原始高清标准图像(Ground Truth)计算PSNR、SSIM,用同样的方法计算得到整个数据集上的PSNR、SSIM数据,然后得出整个数据集的MPSNR、MSSIM数据,并记录各算法的耗时,以实际数据值作为评价各算法优劣的参考。图4的PSNR、SSIM和各算法的耗时如表1所示。
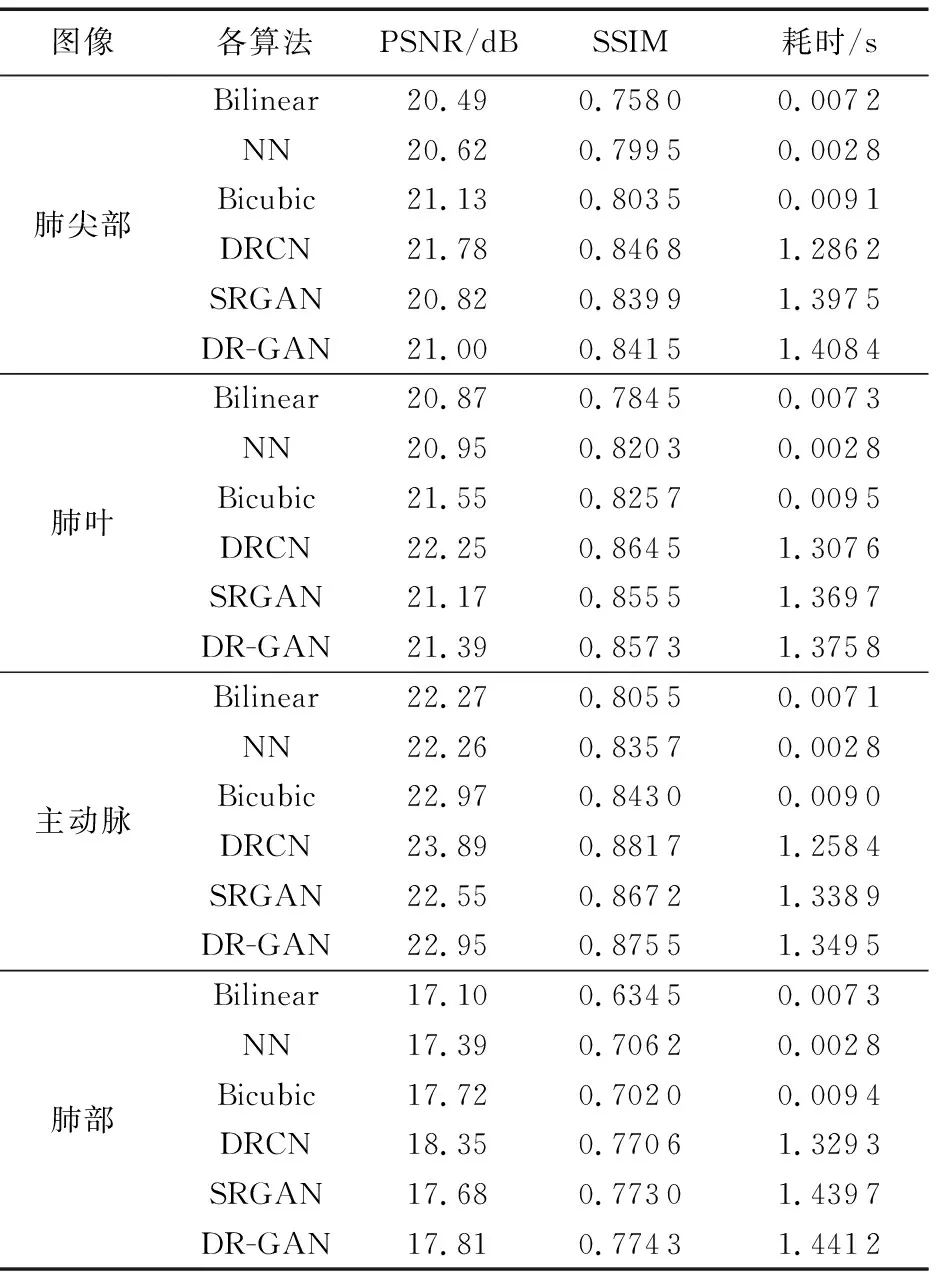
表1 各超分辨率算法评价指标值对比
同时,将整个数据集上计算的PSNR、SSIM数据平均化,得到各算法在整个数据集上的MPSNR、MSSIM和平均耗时如表2所示。
由表1中图4第1行的各超分辨率算法实验数据可以看出,Bilinear、NN、Bicubic、DRCN算法重建出图片的PSNR、SSIM分数越来越高,DR-GAN和SRGAN的PSNR、SSIM分数低于DRCN, 但DR-GAN的PSNR、SSIM均略高于原始SRGAN算法。
同样,从表1中图4第2行~第4行的各超分辨率算法实验数据可以看到,Bilinear、DRCN重建出图片的PSNR、SSIM分数分别为最低和最高,Bilinear、NN、Bicubic、DRCN的PSNR、SSIM分数也越来越高,同时DR-GAN的PSNR、SSIM均高于SRGAN。
从表2中可以看到,Bilinear、NN、Bicubic、DRCN的MPSNR、MSSIM分数同样是越来越高的,DR-GAN的MPSNR、MSSIM均高于SRGAN。

表2 各超分辨率算法MPSNR,MSSIM,耗时结果对比
各算法的耗时方面,从表1可看出,基于深度学习的DRCN、SRGAN,DR-GAN的耗时高于传统的Bilinear、NN、Bicubic算法,但是DRCN、SRGAN、DR-GAN的耗时都在1.5 s以内。
同时,由DR-GAN算法训练过程中的生成损失和判别损失的实验数据绘制图表如图5所示。

图5 DR-GAN算法的损失
从图5可以看到,随着迭代次数的增加,生成损失整体呈现下降趋势,曲线后段趋于平缓,另一方面,随着迭代次数的增加,判别损失整体呈现缓慢上升趋势,因此,综合权衡生成损失和判别损失,确定本文算法最终迭代次数为12 000次。
3.2.2 主观效果
从图4显示的结果可以看出,在处理医学影像的超分辨率任务时,整体来看,基于深度学习的DRCN算法、SRGAN算法和DR-GAN算法处理的效果都明显优于传统的Bilinear、NN、Bicubic算法。主观来看,DRCN算法、SRGAN算法和DR-GAN算法都得到了较好的超分辨率图像,但对于上面的某些图片和某些部位,DR-GAN算法显示出了更逼真的细节纹理和图像锐度。
具体来说,图4第1行(肺尖部)中:Bilinear算法得到的图片整体看起来很模糊;NN算法得到的图片出现了比较明显的方块状;Bicubic得到的图片也比较模糊,且在视觉上显得过于平滑;DRCN在图像锐度方面有了很大的提升,但相比SRGAN和DR-GAN在复杂细节方面的处理仍显不足;SRGAN在图像锐度和视觉效果方面都较好,但图中方框区域的下半部分出现了棋盘状效应;而DR-GAN算法没有显现棋盘状效应,DR-GAN算法的效果最接近于标准图像。
同样,在图4第2行~第4行中,也可以看到:Bilinear很模糊,NN有明显的方块状,Bicubic也比较模糊且视觉过于平滑,DRCN提升了图像锐度但复杂细节处理不足,SRGAN相比DR-GAN算法对丰富纹理处理仍显不够细腻,DR-GAN算法在视觉上显示出了更逼真的纹理细节。
3.2.3 综合评价
虽然PSNR是广泛使用的评价图像质量的客观检测手段,尤其在超分辨率领域,众多的算法和大型挑战赛[34]往往以PSNR数值的高低来评判算法的优劣,但PSNR本身有很大的局限性,最近几年很多的实验结果[18,35]和研究[36]都显示了,PSNR数据无法和人类视觉感官看到的完全符合,有些情况,PSNR较低的反而比PSNR较高的视觉上更逼真[18]。
所以本文采用客观PSNR,SSIM等评价指标和主观视觉效果的综合评价方式。
从表1和表2的实验数据结果可以看出,DR-GAN算法的PSNR、SSIM、MPSNR、MSSIM均高于原始SRGAN算法。
虽然DR-GAN算法超分辨率重建图像的PSNR、SSIM等客观指标低于DRCN,但是从主观视觉效果上来看,DR-GAN算法重建的图像纹理要更细腻、更逼真,视觉体验更好,更接近真实标准图像。
在耗时方面,因为传统插值等方法计算简单,复杂度低,耗时短,DR-GAN算法在提高精度的同时牺牲了时间,时间上虽然缺乏明显优势,但也在可接受的范围内。
因此,综合评价来说,本文提出的DR-GAN算法要优于SRGAN、DRCN、Bilinear、NN、Bicubic算法。
4 结语
针对2倍医学影像超分辨率,本文提出了基于深度残差的生成对抗网络的医学影像超分辨率算法。该算法由生成器网络和判别器网络构成,其中生成器网络由基于改进的32层残差网络和快捷连接组成,判别器由层层卷积层和快捷连接组成。对于肺部医学影像的2倍超分辨率图像,提出的算法综合PSNR等客观指标和主观视觉效果因素要优于SRGAN、DRCN、Bilinear、NN、Bicubic算法,充分说明了本文算法的适用性。下一步的研究工作将探寻高效的算法,以便重建出高质量的更大放大倍数的高分辨率图像。
