主动容错云存储系统的可靠性评价模型
2018-10-16刘冬实
李 静,刘冬实
(1.中国民航大学 计算机科学与技术学院,天津 300300; 2.南开大学 计算机与控制工程学院,天津 300500)
0 引言
近年来,大规模云存储系统已成为主流IT企业的主要存储架构,因为价格等方面的优势,硬盘仍然是它们的主要存储介质。由于制作工艺及技术的进步,单体硬盘的可靠性不断提高,但是,在包含成千上万块硬盘的大规模云存储系统中,硬盘故障甚至是并发故障时有发生[1]。硬盘故障不仅会引起服务中断、降低用户服务体验,甚至会导致数据的永久丢失,给企业和用户带来无法挽回的损失。因此,当前大规模云存储系统面临着高可靠性的挑战。
传统存储系统普遍采用副本或纠删码等冗余机制提高系统的可靠性,如果有硬盘发生故障,系统可以利用其他存活盘上的数据重构故障数据,这是一种典型的“故障-重构”模式的被动容错方式。然而,面对硬盘故障频发的大规模云存储系统,被动容错技术只能通过不断增加冗余来保证系统的可靠性,导致系统承受高昂的构建、维护成本以及沉重的读写开销。硬盘故障预测[2-3]可以在硬盘真正故障之前发出预警,提醒用户对危险数据采取措施(迁移或备份),从而减少或避免硬盘故障带来的损失,这是一种“预警-处理”模式的主动容错机制。如果具有良好的预测性能和有效的预警处理机制,主动容错机制可以大幅度提高云存储系统的可靠性。
正如Eckart等[4]所说,主动容错方式并不能完全避免硬盘故障的发生(没有达到100%的预测准确率),还需要结合一定的冗余机制共同保证系统的可靠性,因此主动容错云存储系统的可靠性分析非常复杂。目前针对该领域的研究非常匮乏,仅有少量研究[2,4-5]基于硬盘故障及重构过程符合指数分布的假设,采用马尔可夫(Markov)模型评价主动容错存储系统的可靠性。
而且,现有研究存在以下缺陷:1)故障分布假设不合理。基于指数分布的假设,硬盘故障率和修复率恒定不变,文献[6]通过领域数据的分析推翻了该假设。2)故障类型考虑不全面。只关注硬盘完全崩溃故障,而忽略了潜在扇区错误等块故障对系统可靠性的影响,随着系统规模和单体硬盘容量的增大,块故障已不容忽视[7]。3)度量指标不准确。采用平均数据丢失时间(Mean Time To Data Loss, MTTDL)作为可靠性评价指标,而MTTDL相对于系统的实际运行时间过长,并不能准确评价云存储系统的可靠性水平[8]。
本文针对主动容错磁盘冗余阵列(Redundant Arrays of Independent Disks, RAID)RAID-5和RAID-6云存储系统提出两个可靠性状态转移模型,描述系统在各种可靠性状态之间的转换,并根据模型设计了蒙特卡洛仿真算法,模拟主动容错RAID系统的运行,统计系统在一定运行周期内发生数据丢失事件的期望个数。本文方法克服了现有研究的缺陷,采用更接近实际的韦布分布(而不是指数分布)函数描述随时间变化(下降、恒定不变、或上升)的硬盘故障和修复率,除硬盘整体故障外,增加考虑块故障和磁盘清洗过程对云存储系统可靠性的影响,并采用更合理的指标(某一运行周期内发生数据丢失的个数)评价系统可靠性。利用本文方法可以准确、定量地评价主动容错技术和系统参数对存储系统可靠性的影响,帮助系统设计师(或管理员)设计出满足可靠性要求的容错方案,更好地理解系统性能和可靠性之间的权衡。
1 背景知识
1.1 相关工作
硬盘期望寿命的研究是可靠性评价的基础。Gibson[9]认为硬盘故障时间(Mean Time To Failure, MTTF)服从指数分布是一个合理假设,这为后来很多研究[2,4-5,10-11]利用马尔可夫模型分析存储系统可靠性提供了理论指导;但Schroeder等[6]以高置信度推翻了硬盘故障时间服从指数分布的假设,他们建议研究者使用真实的故障替换数据(或是双参分布,如韦布分布),模拟硬盘的故障时间,已有一些研究[12-15]基于硬盘故障非指数分布的前提,使用仿真或组合分析等方法分析存储系统的可靠性。
基于硬盘故障分布数据,研究者提出了一些存储系统可靠性评价方法,有三类被广泛采用:1)连续时间马尔可夫链模型[2,4-5,10-11]能直观表示系统的故障、修复等事件,基于硬盘故障指数分布假设前提,可方便地计算系统平均数据丢失时间(MTTDL);2)蒙特卡洛仿真方法[13,16]适用于不同的硬盘故障分布,且容易表达一些复杂策略,如延迟校验计算、延迟修复等;3)组合分析方法[13-15]直接计算各种数据丢失情况的概率,计算速度远优于前两种方法,且能与它们结合,适用于不同硬盘故障分布。
伴随着硬盘故障预测问题的研究,学术界也相应地出现了一些评价主动容错存储系统可靠性的研究[2,4-5],但是这些方法存在一些缺陷,并不能真实有效地评价主动容错存储系统的可靠性水平。因此,本文拟弥补现有方法的缺陷、研究能准确评价主动容错存储系统可靠性的方法。
1.2 硬盘故障
潜在块故障(Latent block defects)一般由潜在扇区错误或数据损坏引发:1)潜在扇区错误是部分二进制位永久损坏,无论尝试多少次都不能正确读取一个扇区,一般由磁头划伤或介质损坏等物理原因造成;2)数据损坏是数据块上存放着错误的数据,只能通过校验信息验证才能发现,通常由软件或固件缺陷造成。随着系统和硬盘个体容量的增大,这些块级别的硬盘故障已不能再被忽视。为检测和修复块故障,存储系统通常在后台运行着一个“磁盘清洗”进程,主动读取并检测系统中所有的数据块,如果发现损坏数据块,系统会利用冗余信息重构损坏数据。
运行故障(operational failure)是硬盘最为严重的故障形式,表现为整个硬盘永久不可访问,只能通过替换硬盘进行修复。如果系统中发生了运行故障,系统会立即启动故障重构过程,利用其他存活盘上的数据和冗余信息恢复出故障数据。
1.3 主动容错技术
当前大部分硬盘内部都具有SMART(Self-Monitoring, Analysis and Reporting Technology)[17]配置,SMART 是硬盘的“自我监测、分析和报告”技术,可以实时监测硬盘重要属性值并与预先设定的阈值进行比较,如果有属性值超过阈值,则认为硬盘即将发生运行故障,于是发出预警信息,提醒用户对危险数据进行备份或迁移。为了提高预测性能,有研究者尝试基于硬盘 SMART 信息、采用统计学或机器学习方法构建硬盘故障预测模型[2-3],其中有一些模型(比如,基于决策树[2]的预测模型)取得了比较理想的预测效果。
在主动容错系统中,硬盘故障预测模型运行在系统后台,实时监测工作硬盘的属性状态并周期性地(比如,每隔一小时)输出它们的“健康度”情况,如果发现预警(危险)硬盘,系统会立刻启动预警修复进程,把预警硬盘上的数据迁移备份到其他健康硬盘上。
1.4 冗余机制
在云存储系统中,多个运行故障和(或者)多个块故障同时发生会导致数据丢失事件的发生,如果(消除运行故障的)重构过程或者(消除块故障的)磁盘清洗过程能够及时完成,可以避免数据丢失事件的发生。
RAID-5和 RAID-6是两种广泛应用在云存储系统的冗余机制,存储硬盘在系统中被划分为不同的校验组,数据在校验组中按条纹存储,从而实现数据的并行访问以提高系统访问性能[18]。每个RAID-5校验条纹能够容忍任意一个故障——一个运行故障或一个块故障;每个RAID-6校验条纹能够容忍任意两个并发故障——两个并发的运行故障、一个运行故障和一个块故障、或两个块故障。
1.5 韦布分布
在实际系统中,硬盘故障的发生率不是恒定不变的,而是遵循典型的“浴盆曲线”规律[ 19]:经历过初期比较高的“婴儿死亡率”之后,硬盘故障率进入平稳期,直到硬盘生命周期的末尾,由于磨损老化,故障率再次升高。另外,Schroeder和Gibson[6]发现,相对指数分布,韦布分布可以更好地拟合硬盘故障数据的累积分布函数。而且,Elerath和Schindler[13]通过领域数据的分析,发现韦布分布可以很好地匹配硬盘故障、修复以及磁盘清洗事件的时间分布。
因此,使用两个参数的韦布分布函数模拟硬盘故障(运行故障和块故障)、故障重构以及磁盘清洗过程在云存储系统中的发生。韦布分布的概率密度函数f,累积密度函数F,风险率函数h,以及累积风险率函数H的公式[20]如下:
(1)
F(t)=1-e(-(t/α)β)
(2)
(3)
H(t)=tβ/αβ
(4)
其中:α是表示特征生命的尺度参数(scale parameter),β是控制分布形状的形状参数(shape parameter)。
根据上述公式可以看到:1)β>1时,风险率h随着时间t的增长而变大,即硬盘发生运行故障的风险随时间逐渐升高,能够模拟运行时间较长出现老化现象的云存储系统;2)β=1时,韦布分布退化为指数分布,即硬盘发生运行故障的概率是恒定不变的(不随时间变化而变化),能够模拟处于稳定运行时期的云存储系统;3)0<β<1时,风险率h随时间的推移而降低,能够模拟处于“早期失效”时期的云存储系统。
2 可靠性状态转移模型
2.1 主动容错RAID-5系统
对于一个RAID-5校验组,理论上有三种导致数据丢失的情况:
1)同时发生两个运行故障;
2)同时发生一个运行故障和一个块故障;
3)同时发生两个块故障。
通常每个硬盘存储着上万个数据块,相同校验条纹上的数据块同时发生故障的概率非常小(从而可以忽略),即,校验组内两个或更多并发的块故障一般不会导致数据丢失,因此,只考虑上述前两种导致数据丢失的故障情况。
针对主动容错RAID-5校验组,创建了如图1所示的可靠性状态转移模型,大致存在8种不同的可靠性状态,随着故障、修复、预警等事件的发生,校验组在不同可靠性状态之间转移。

图1 主动容错RAID-5可靠性状态转移
图1中,RAID-5校验组总共有N+1块硬盘,包含N块数据硬盘和一块冗余硬盘,符号“W”表示预警事件,“OP”表示运行故障事件,“LD”表示块故障事件。使用单、双箭头两种状态转移线,其中,单箭头表示某一状态到另一状态的转换,双箭头表示两种状态之间的相互转换。状态转移线上的符号“g[·]”表示状态之间转移的通用函数,转移线上面的“g[·]”是左边状态转移到右边状态的函数,下面的表示右边转移到左边的函数。“fdr”表示硬盘故障预测模型的故障检测率(Failure Detection Rate),“d”表示某事件的时间分布,其中:“dLD”表示块故障事件的时间分布, “dOP”表示运行故障的时间分布,“dW-OP”表示预警硬盘(没有被及时处理)发生运行故障的时间分布,“dScrub”表示磁盘清洗事件的时间分布,“dRestore”表示运行故障修复的时间分布,“dHandle”表示预警处理事件的时间分布。“dW-OP”由提前预测模型的提前预测时间TIA(Time In Advance)和预警处理分布“dHandle”确定。
状态1 校验组中所有硬盘都在正常运行且没有块故障。从状态1出发校验组有三种转移可能:1)有硬盘发生了块故障(LD),转移到状态2;2)有硬盘被预警即将发生运行故障(出现预警硬盘),转移到状态3;3)有硬盘(被预测模型漏报)发生了运行故障,转移到状态5。状态转移依赖于可用硬盘的数量,预测模型的故障检测率,(运行或块损坏)故障以及修复(或预警备份)事件的时间分布。比如,从状态1到2的转移是N+1块硬盘根据故障分布dLD发生块故障的函数,状态1到5的转移是N+1块硬盘根据分布dOP存在故障风险,并以(1-fdr)的概率(被漏报)发生运行故障的函数。
状态2 校验组内发生了块故障。校验组从状态2出发有三种转移可能:1)磁盘清洗过程及时修复了块故障,返回状态1;2)其他(无损坏块的)硬盘被预警即将发生运行故障,转移到状态4;3)其他硬盘(被预测模型漏报)发生了运行故障,转移到状态7。
状态3 有硬盘被预警将要发生运行故障。从状态3出发有4种转移可能:1)预警硬盘得到及时有效的处理(危险数据被安全迁移到新的健康硬盘,并替换预警盘),返回状态1;2)其他(非预警)硬盘发生块故障,转移到状态4;3)预警硬盘没有得到及时处理,发生了运行故障,转移到状态5;4)其他硬盘发生运行故障,转移到状态6。
状态4 校验组内发生了块故障,同时又有其他硬盘被预警。从状态4出发有三种转移可能:1)预警硬盘得到及时处理,返回状态2;2)磁盘清洗过程消除了块故障,返回状态3;3)预警硬盘没有被及时修复而发生了运行故障,或者其他硬盘发生了运行故障,转移到状态7。
状态5 校验组内发生了运行故障。从状态5出发有四种转移可能:1)故障修复完成(增加新硬盘替换故障硬盘,并重构损坏数据),返回状态1;2)其他硬盘被预警,转移到状态6;3)其他硬盘又发生了运行故障,转移到状态8;4)其他硬盘发生块故障,转移到状态7。
状态6 校验组内发生了运行故障,同时又有其他硬盘被预警。从状态6出发有三种转移可能:1)运行故障被成功修复,返回状态3;2)预警硬盘得到及时处理,返回状态5;3)预警硬盘发生了运行故障,或者,其他(非预警)硬盘发生运行故障,转移到状态8。
状态7 校验组内同时发生一个运行故障和其他硬盘的块故障。
状态8 校验组内存在两个并发的运行故障。处于这两种状态时,校验组发生数据丢失事件,不能再提供正常服务。
2.2 主动容错RAID-6系统
对于一个RAID-6校验组,理论上有4种导致数据丢失的情况:
1)3个运行故障同时发生;
2)2个运行故障和1个块故障同时发生;
3)1个运行故障和2个位于同一条纹的块故障同时发生;
4)3个位于同一条纹的块故障同时发生。
与RAID-5类似,多个并发的块故障处于同一校验条纹的概率很小,可以忽略。通常来说,当RAID-6校验组内3个硬盘同时发生损坏时(3个运行故障,或者,2个运行故障和1个块故障),会导致数据丢失事件的发生。
针对主动容错RAID-6校验组,创建了如图2所示的可靠性状态转移模型。

图2 主动容错RAID-6可靠性状态转移
RAID-6校验组内有N+2块硬盘,包括N块数据盘和2块校验盘,大致存在12种可靠性状态,其中,状态1~8与图1的情况类似,此处仅介绍与图1不同的内容。因为RAID-6可以容忍任意的两个并发故障,所以转移到状态7和8时,不会发生数据丢失,系统还可以自我修复。
处于状态4时,如果其他(非预警或块损坏)硬盘发生运行故障,转移到状态9。
处于状态6时,如果:1)其他(非预警)硬盘发生块故障,转移到状态9;2)其他硬盘发生运行故障,转移到状态10。
处于状态7时,如果:1)其他硬盘被预警,转移到状态9;2)其他硬盘发生运行故障,转移到状态11。
处于状态8时,如果:1)其他硬盘被预警,转移到状态10;2)其他硬盘发生运行故障,转移到状态12;3)其他硬盘发生块故障,转移到状态11。
状态9,校验组内发生了运行故障和块故障,同时又出现预警硬盘。此时,校验组有四种转移可能:1)运行故障得到及时修复,返回状态4;2)预警硬盘得到及时有效的处理,返回状态7;3)块故障被磁盘清洗消除,返回状态6;4)预警硬盘没有得到及时修复,发生了运行故障,或者其他硬盘发生运行故障,转移到状态11。
状态10,校验组内有两个并发的运行故障,同时又有硬盘被预警。此时,校验组有3种转移可能:1)某个运行故障被成功修复,返回状态6;2)预警硬盘得到及时处理,转移到状态8;3)预警硬盘发生了运行故障,或者其他硬盘发生运行故障,转移到状态12。
状态11,校验组内发生了2个运行故障和一个(些)块故障,数据丢失事件发生。
状态12,校验组内同时发生了3个运行故障,数据丢失事件发生。
3 仿真
根据第2章提出的可靠性状态转移模型,设计了事件驱动的蒙特卡洛仿真算法,模拟主动容错RAID云存储系统的运行,并统计系统在一定运行周期内(比如10年)发生数据丢失事件的期望个数。算法通过6种仿真事件向前推进模拟时间:
a)运行故障事件,潜在存在于每一个硬盘上;
b)块故障事件,潜在存在于每一个硬盘上;
c)故障重构完成事件,在运行故障修复完成时触发;
d)磁盘清洗完成事件,在磁盘清洗过程完成时触发;
e)故障预警事件,在预测模型检测到潜在运行故障时触发(故障发生前TIA小时发生),受到预测模型性能的限制;
f)预警处理完成事件,在预警数据备份完成时触发。
事件e)和f)模拟了主动容错技术在存储系统中的应用,事件c)和f)触发系统增加新硬盘。如果发生的故障满足一定条件,系统发生数据丢失事件,为了保持系统规模,增加新数据到系统中。
程序开始时为系统中的每块硬盘生成一个潜在的运行故障和块故障,并基于硬盘故障预测模型的性能生成一些预警事件,然后根据事件发生的先后顺序插入一个最小堆。在程序运行期间(达到指定仿真时间之前),不断地从最小堆的顶部弹出最先出现的事件以模拟它的发生,并根据事件类型采取相应操作。事件的发生时间是累积的,直到达到或超过指定的仿真时间。重复执行仿真程序,直到系统发生10次以上的数据丢失事件,最后统计数据丢失事件的期望数量作为仿真程序的结果。
4 评价
本章首先评价了可靠性状态转移模型的准确性,然后利用模型对主动容错RAID云存储系统作了参数敏感性分析。
4.1 实验准备
对仿真算法中的事件a)~d),使用Elerath等[13]通过领域数据分析得出的分布参数,详细信息见表1,其中,硬盘A和B是1 TB容量的近线SATA类型硬盘,硬盘C是288 GB容量的企业级FC型号硬盘。
Li等[2]提出的分类决策树模型可以提前大约360 h预测出95%的潜在运行故障,所以设置提前预警时间TIA=300 h,即运行故障发生前300 h触发预警事件。预警发出后,系统会启动预警处理进程,把危险硬盘上的数据迁移备份到其他健康硬盘上。为了简化程序,假设预警处理需要的时间与故障重构时间相同,使用故障重构的参数设置预警完成事件。

表1 韦布分布参数[13]
设置每个RAID-5校验组内包含的硬盘总量为15,每个RIAD-6校验组内为16,这样,每个 RAID 校验组内都包含14块数据硬盘。为每个主动云存储系统部署1 000个校验组,即,RAID-5系统总共包含15 000块硬盘,RAID-6系统总共包含16 000块硬盘,这样,两个存储系统都存储相同容量的用户数据。
4.2 模型验证
4.2.1 被动容错系统
如果设置预测模型的故障检测率(fdr)为0,本文模型退化为被动容错云存储系统的可靠性状态转移模型。为了验证模型在被动容错系统上的有效性,使用论文[14]和[13]中的可靠性公式(被动容错RAID-5公式[14]、被动容错RAID-6公式[13])与本文提出的模型作了实验对比。实验分别使用公式和仿真统计了不同运行周期内被动容错RAID-5和RAID-6云存储系统发生数据丢失事件的期望个数,结果显示在图3中。

图3 系统在不同运行周期内发生数据丢失事件的期望数
对于所有型号的硬盘,每个云存储系统的仿真结果和公式计算结果都非常接近,只有不到10%的偏差,这些结果证实了本文模型在被动容错云存储系统上的有效性。
4.2.2 主动容错系统
为了验证模型在主动容错云存储系统上的有效性,使用马尔可夫可靠性评价模型(主动容错RAID-5模型[4]、主动容错RAID-6模型[2])与本文的模型进行实验对比。因为马尔可夫模型的限制,此实验设置βf=1,βr=1,并且忽略块故障和磁盘清洗事件。分别使用仿真算法和马尔可夫模型评价了硬盘A系统在10年内的可靠性水平,结果显示在图4中。
结果显示,在不同的预测性能下两种模型得出的结果都非常接近,平均只有10%的误差,证实了本文模型在主动容错云存储系统上的有效性。

图4 不同预测性能下发生数据丢失事件的期望数
4.3 敏感性分析
使用本文提出的模型,系统设计者在系统部署前或者潜在数据丢失事件发生前就能了解系统参数对系统整体可靠性的影响,有助于系统构建和维护。本节将演示如何使用状态转移模型分析系统参数对系统可靠性的影响。除非特殊说明,下述实验使用硬盘A的分布参数,运行周期设置为10年。
4.3.1 重构时间
故障修复时间越长,系统(降级模式期间)发生并发故障的概率越大,所以故障重构时间对系统可靠性的影响很大。本实验分析了故障重构时间对主动/被动容错云存储系统可靠性的影响。对于主动容错云存储,设置预测模型的预测准确率fdr为0.8;当fdr=0时,系统退化为被动容错系统。
通过调节参数αr改变重构时间,结果显示在图5中。

图5 不同重构时间下发生数据丢失的期望数
正如上述分析所示,随着重构时间的增加,系统可靠性逐渐降低。而且,1)相比RAID-5系统,RAID-6系统的可靠性受重构时间的影响更明显,这主要是因为RAID-6系统发生数据丢失需要更多的运行故障;2)与被动容错系统相比,主动容错系统的可靠性对重构时间的敏感性低,由于主动容错技术的引入,系统由“正常-故障恢复”两状态变化为“正常-预警处理-故障恢复”三状态,系统处于故障恢复状态的时间变短,使得重构时间对系统可靠性的影响减弱。
4.3.2 块故障率
块故障的发生频率受到硬盘型号和硬盘使用情况的影响。本实验想研究系统可靠性对块故障率的敏感性。通过改变参数α1调整块故障的发生频率,结果显示在图6中。结果显示,块故障率越高,系统可靠性越低。而且,相比被动容错系统,主动容错系统受块故障率的影响较大,这主要是因为引入主动容错技术之后,系统中发生运行故障的概率降低,从而导致块故障对数据丢失事件的贡献增大。
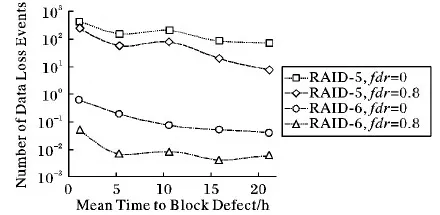
图6 不同块故障率下发生数据丢失的期望数
4.3.3 磁盘清洗周期
本实验研究磁盘清洗周期对系统可靠性的影响,通过改变参数αs调整磁盘清洗时间,结果显示在图7中。结果显示,随着清洗周期的变长,系统可靠性不断降低;而且,与块故障率实验结论类似,相比被动容错系统,主动容错系统对磁盘清洗周期的敏感性更强。

图7 不同清洗周期下发生数据丢失的期望数
5 结语
本文分别针对主动容错RAID-5和RAID-6云存储系统提出可靠性状态转移模型,分析了运行故障和块故障下系统的全局可靠性。基于状态转移模型,设计了蒙特卡洛仿真算法,模拟主动容错云存储系统的运行,评价主动容错技术、硬盘运行故障、重构过程、块故障以及磁盘清洗过程对系统全局可靠性的影响。利用本文提出的模型,系统设计者可以方便准确地评价主动容错技术以及其他系统参数对云存储系统可靠性的影响,有助于存储系统的构建和维护。
[15] EPSTEIN A, KOLODNER E K, SOTNIKOV D. Network aware reliability analysis for distributed storage systems [C]// Proceedings of the 2016 IEEE 35th Symposium on Reliable Distributed Systems. Washington, DC: IEEE Computer Society, 2016: 249-258.
[16] HALL R J. Tools for predicting the reliability of large-scale storage systems [J]. ACM Transactions on Storage, 2016, 12(4): Article No. 24.
[17] ALLEN B. Monitoring hard disks with smart [J]. Linux Journal, 2004, 2004(117):9.
[18] 罗象宏,舒继武.存储系统中的纠删码研究综述[J].计算机研究与发展,2012,49(1):1-11.(LUO X H, SHU J W. Summary of research for erasure code in storage system [J]. Journal of Computer Research and Development, 2012, 49(1): 1-11.)
[19] ELERATH J G. Specifying reliability in the disk drive industry: No more MTBF’s [C]// Proceedings of the 2000 International Symposium on Product Quality and Integrity, Reliability and Maintainability Symposium. Piscataway, IEEE, 2000: 194-199.
[20] McCOOL J I. Using the weibull distribution: reliability, modeling and inference [J]. Journal of Applied Statistics, 2012, 41(4): 913-914.
