两段式虚拟网络功能硬件加速资源部署机制
2018-10-16范宏伟胡宇翔兰巨龙
范宏伟,胡宇翔,兰巨龙
(国家数字交换系统工程技术研究中心,郑州 450002)
0 引言
软件定义网络(Software Defined Networking, SDN)将控制和数据平面分离,通过开放网络控制接口,实现上层应用对网络的管控。网络功能虚拟化(Network Function Virtualization, NFV)通过虚拟化技术,将虚拟网络功能(Virtual Network Function, VNF)运行在虚拟机(Virtual Machine, VM)或者容器中,按需实现网络功能的动态灵活部署[1]。相比传统网络,SDN/NFV架构符合未来信息产业的发展需求,得到了学术界和运营商的重点发展和推动。然而,基于软件实现的VNF,在数据转发、处理上的性能远落后于传统网络硬件设备,无法满足线速要求到达40~100 Gb/s网络功能的业务需求。VNF的性能瓶颈限制了SDN/NFV架构的进一步发展[2-3]。
为此,针对VNF数据处理的加速机制成为学术界的研究热点。当前VNF的主要加速机制是将部分网络功能卸载到硬件中,利用硬件的高性能提升VNF的吞吐量和减少时延。根据承载VNF的加速硬件种类,可以将现有的研究归纳为两个方向。一是利用SDN交换机的硬件处理能力,以表项形式实现对VNF数据处理的加速。文献[4]利用OpenFlow交换机承载无状态网络功能,实现了对大量数据包的快速处理,提高了网络功能的性能。文献[5]通过在交换机中引入状态表,实现了SDN交换机对有状态网络功能的加速,极大提升了转发效率。方向二则是利用服务器端的智能网卡、网络处理器(Network Processer, NP)、图形处理器(Graphics Processing Unit, GPU)[6-7]和现场可编程门阵列(Field-Programmable Gate Array, FPGA)[8-9]等可编程硬件,将相对固化的数据处理功能卸载到硬件加速单元中,而软件完成复杂多变的逻辑任务,将两者结合从而提升VNF处理性能。文献[6]利用GPU的大规模并行处理能力,结合定制的流处理程序,实现对网络功能加速的有效支持。文献[9]根据VNF的加速需求,灵活改变FPGA的逻辑功能,实现与CPU细粒度分工合作,提升VNF的吞吐量,降低了处理时延。
在SDN/NFV架构中,网络中的业务流量要按顺序经过多个、不同类型VNF的处理,构成“服务链”,服务链中的网络功能分布式地运行在网络的各个节点之中,并受限于各节点内的物理资源[10-11]。从目前对VNF加速机制的研究来看,仅限于单节点内加速架构的设计,缺乏对全网硬件加速资源的统一管理和部署研究,难以满足服务链中位于不同节点内VNF的加速需求。因此,当SDN/NFV架构引入VNF硬件加速资源后,如何最优地部署这些加速资源到各网络节点中,以实现对服务链的加速处理,是亟待解决的问题。
为了实现VNF硬件加速资源到全网节点的最优部署,本文将服务器端的加速卡和转发节点内的加速表项进行统一管理,提出了两段式加速资源部署模型,在不引入额外开销的情况下,部署在各节点中的加速资源最大限度满足VNF的加速需求。首先,提出了VNF加速资源的统一管理架构,以实现对全网硬件加速资源的统一管控;然后,对VNF加速资源的部署问题进行数学建模,并分析加速资源对服务链映射的影响,提出了加速资源部署算法的性能指标;其次,设计了基于拓扑势和节点协作的两段式加速资源部署算法,对问题进行求解;最后,对算法进行了仿真验证,证明了算法的有效性。
1 VNF硬件加速资源统一管理架构
针对当前SDN/NFV架构中存在的加速资源部署问题,本文提出了VNF硬件加速资源在现有SDN/NFV架构中的统一管理架构(Uniform Hardware Acceleration Management architecture, UHAM),总体结构如图1所示。结合华为提出的硬件资源统一抽象概念[12],不论是服务器端的加速卡,还是转发设备内的加速表项,并没有引入新的物理资源种类,都属于NFV标准架构基础设施(NFV Infrastructure, NFVI)中的计算资源和网络资源。因此,对于VNF硬件加速资源,仍由虚拟化的基础设施管理模块(Virtual Infrastructure Manager, VIM)负责管理和分配,在降低管理开销的同时,隐藏了引入加速资源的复杂性。在VIM仓库清单要包含硬件加速资源的能力和特性信息,并与虚拟资源之间进行关联。VNF管理器(VNF Manager, VNFM)负责VNF实例的生命周期管理,通过读取VNF的描述(VNF Description, VNFD)模板,与VIM模块进行信息交互,将NFVI资源按需求分配给相应的VNF。在引入硬件加速资源后,VNFD内对于虚拟资源的需求可以根据通用物理资源、硬件加速资源之间的特性进行细化,上传多个相应的VNF模板,以支持多种类型的硬件加速资源。
编排器(NFV Orchestrator, NFVO)负责NFVI资源的编排和网络服务生命周期的管理。SDN控制器通过标准的南向接口与整个NFV服务管理和编排模块进行连接,根据网络拓扑和策略要求进行路由规划,控制转发节点内的转发表项(Forwarding Table, FT)和加速表项(Acceleration Table, AT)。当SDN交换机承载网络功能时,为避免引起控制器的负载和表项之间的冲突,在UHAM架构中,引入了主从控制器模式来解决该问题。其中,主控制器负责管理和下发流量转发规则,而从控制器负责管理和下发VNF加速功能表项,实现二者的分离。此外,从控制器与VIM模块进行交互,实现对转发节点内硬件加速资源的管理,结合服务器端加速卡资源信息,从而实现对全网内加速资源的统一管理。

图1 VNF硬件加速资源统一管理架构
2 问题建模
基于UHAM架构,本文重点研究在SDN/NFV架构中统一管理VNF硬件加速资源后,如何优化部署硬件加速资源到网络节点中,在不引入额外开销的情况下,提升硬件加速资源对VNF的承载效率。首先,定义本文所要解决的硬件加速资源部署问题。
定义1 VNF硬件加速资源的部署问题(VNF hardware acceleration resource deployment problem)。网络中节点资源和链路连接都已确定,在用户服务链请求未知的情况下,运营商如何将VNF硬件加速资源,包括转发设备端和服务器端两类资源,合理地部署到各网络节点中,实现按一定策略完成服务链的映射后,部署在网络节点内的硬件加速资源能最优承载有加速需求的网络功能,最大化所部署加速资源的使用效率。
2.1 符号描述
1)网络拓扑。如图2所示,网络拓扑表示为一个无向带权图G=(S,L),其中,S和L分别代表转发节点集和链路集合。链路L的资源属性是带宽容量B(lu,v)(其中,u,v∈S,lu,v∈L)。用N表示服务器节点集合,其物理资源属性(CPU、内存、硬盘等)表示为R;服务器节点n与转发节点s的连接关系用η(n,s)∈{0,1}(n∈N,s∈S)表示,若η(n,s)为1,则假定服务节点n和转发节点s之间相连,且链路带宽为转发节点s与相邻转发节点的链路带宽之和,而且假定服务器节点最多与一个转发节点相连。

图2 网络拓扑示意图

3)网络功能。服务链根据资源(计算、存储和网络)需求和VNF间的顺序约束将网络功能映射到网络的各个节点中。F=(f1,f2, …,fp)表示网络中存在的网络功能实例集合,网络功能fj∈F(j=1,2,…,p)处理的数据流量为dj。网络功能fj对不同类型加速资源的开销用CHk(fj)(k=0,1,…,q)表示。γ(fj,Hk)∈{0,1}(j=1,2,…,p,k=0,1,…,q)表示网络功能fj与节点内硬件资源Hk之间的承载关系。
2.2 评价指标
服务器端存在多种类型的加速资源卡,而且彼此之间承载的网络功能类型有一定的重合,存在相似性,为服务端加速资源的部署问题求解带来一定的困扰。为简化模型,本文假设服务器端的加速资源卡均为FPGA加速卡,即:
假设1H=(H0,H1),其中H1为FPGA加速卡。因为,相比FPGA,GPU加速需要对数据进行格式化处理,耗时过长,难以满足对时延敏感的网络功能需求,而且能耗相对较高;而NP的适用领域相对受限,无法同FPGA可以为任何网络功能重构硬件逻辑。由于FPGA对VNF承载的可扩展性最强,能够加速报文转发、加解密和视频转码等几乎所有领域内的VNF,可以替代其他类型的加速卡,而且该假设并未改变该问题的性质和求解方法,而仅仅是简化了问题的复杂度。
VNF硬件加速资源优化部署主要是为了实现:当运营商考虑加速资源影响服务链映射策略时,部署到各节点的加速资源的类型和数量,与网络中原有的物理资源(计算、网络、存储)相适应,硬件加速资源能够尽可能承载网络功能,同时不引入额外开销(传输时延等)和避免加速资源闲置造成的浪费。因此,为较好地刻画加速资源在全网节点内的部署情况,现提出加速资源承载的流量和加速资源的利用率两个评价指标来描述加速资源的使用效率,其定义如下。
定义2 加速资源承载的流量。网络中被硬件加速资源处理的总的数据流量,如下所示:
(1)
定义3 加速资源的利用率:网络中处于加载状态下的单位加速资源处理的数据流量,如下所示:
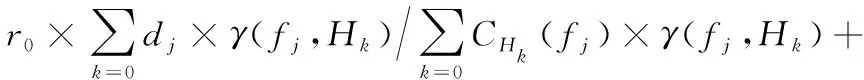
(2)
其中,r0+r1=1,r是两类加速资源的权重调节系数,对两类加速资源进行统一。加速资源承载的DH表示由加速资源处理的流量,当网络内各节点部署的加速资源足够多时,网络中映射固定数目的服务链时,DH将为定值,此时所有VNF的加速需求都能被满足,但在部署有限加速资源的情况下,DH越大,则证明加速资源部署结果越合理,能够满足服务链的加速需求;而加速资源的利用率QH越大,表示单位加速资源处理的业务流量越接近加速后网络功能的吞吐量上限,处于高负载状态,实现了对加速资源的高效利用。
为避免引入额外开销和加速资源部署位置对服务链映射的影响,在评价加速资源部署策略时,服务链的映射策略中应不考虑加速资源这一因素,将有加速需求的网络功能以“未知状态”下映射到网络节点中。完成服务链映射后,根据流量的传输路径,位于该路径节点内的加速资源尽可能承载有加速需求的网络功能,计算加速资源承载的流量DH和利用率QH,作为加速资源部署算法的评价指标,判断部署策略的合理性。
3 两段式加速资源部署算法
为实现加速资源的优化部署,要根据两类加速资源各自的特性,来确定部署的策略和算法。服务器端FPGA加速卡能承载服务链中复杂的VNF,具有更高的灵活性,但成本和功耗开销相对较大;转发节点内的加速资源,能够承载无状态网络功能或者轻量级有状态功能,对承载的功能类型限制较大,但网络中转发节点的数量较多,而且配置的加速表项容量更大。因此,有加速需求的网络功能可以优先由转发节点内的加速资源进行承载,当超出转发节点加速资源的承载能力时,再由服务节点的加速卡进行承载,来发挥加速资源的最大效用。
基于以上分析,本文针对全网加速资源部署问题,提出一种两段式加速资源部署(Two-stage Acceleration Resource Deployment, TARD)算法。TARD算法在分析两类加速资源不同特点的基础上,考虑交换设备的物理属性和拓扑位置,以适应转发节点承载的流量为目标,利用拓扑势[13]思想量化部署的加速资源;增强转发节点和服务节点间加速资源的协作性,提高加速资源利用率,尽可能多地承载网络功能。TARD算法分为两个阶段,算法流程如图3所示:第一阶段利用基于拓扑势的加速资源部署算法将转发节点的加速表项资源部署到相应转发节点;第二阶段结合转发节点加速资源的部署情况,利用节点协作思想将服务端加速卡配置到服务节点内,完成VNF硬件加速资源的部署。

图3 TARD算法流程
3.1 基于拓扑势的加速资源部署算法
在引入硬件加速资源前,转发节点负责服务链内网络功能的连接,引导流量转发到正确的服务节点中。因此,传统的服务链部署策略中对转发节点的选择,主要考虑转发节点自身的固有属性(位置、带宽、度数等)。为不引入额外的开销,提高硬件加速资源的利用率,转发节点是否所部署加速资源以及具体的数量,要与转发节点在服务链映射中所承载的流量相适应。本节通过分析转发节点影响服务链映射时的属性内容,并引入拓扑势方法,分析转发节点间的相互作用,通过转发节点的改进拓扑势来量化加速资源的部署数量。
在数据场理论中,物理系统被视为包含s个节点并相互作用的网络。该系统中每个节点的周围都存在一个空间上的虚拟场,该场会作用于场内的任何节点。网络中任何一个节点都将与其他节点相互作用,形成整个拓扑上的一个场,定义为拓扑势场。根据数据场中势函数定义,场中任意节点si的拓扑势可以由高斯函数表示为:
(3)
其中:mj为节点的质量,di, j为节点间距离,σ为影响因子,表示节点的影响力,用于控制节点拓扑势场作用范围。
根据以上数据场理论,将拓扑势方法应用于由转发节点组成的网络拓扑中,用来描绘转发节点在服务链部署时的影响力,从而确定加速资源部署数量。由于在服务链部署中对于转发节点属性的选择具有多样性和特殊性,对拓扑势方法进行了改进,将转发节点的拓扑势定义如下:
(4)
其中:mj1和mj2分别表示转发节点的度数和该节点到相邻转发节点的带宽和,M1和M2表示各自属性的权重,其值由熵权法确定,统一两个属性的数量级;di, j表示节点si和sj之间最短距离的跳数;be(j)表示转发节点的介数中心度,衡量节点的作用范围。度数和带宽和是转发节点承载服务链能力的约束表示;介数中心度表示网络中经过该节点的所有点与点之间的最短路径数目。在服务链映射过程中,不同网络功能之间的流量大都选择节点间的最短路径进行转发,因此介数中心度反映了服务链映射中对转发节点的偏好。
转发节点的加速资源部署数量与拓扑势之间的关系可以表示为:
(5)
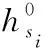
算法1 基于拓扑势的转发节点加速资源部署算法。
输入:转发节点所组网络的邻接矩阵,其中,两个节点相连为1,不相连为∞;
步骤1 确定网络中各转发节点的两个固有属性:转发节点的度数m1和带宽总和m2;
步骤2 用Floyd算法求节点的路径矩阵和距离矩阵,算出各节点间的距离和节点的介数;
步骤3 根据熵权法计算权重M1和M2,得到各节点的质量m=M1×m1+M2×m2;
步骤4 根据式(4)、(5)计算各节点的拓扑势和加速资源部署数量;
3.2 基于节点协作的加速资源部署算法
对于服务器端加速资源的部署,当服务节点内加速资源恰好满足节点内工作时的VNF加速需求,表明加速资源部署数量的合理性。在NFV环境下,服务节点间相互同构,在用户请求到达和服务链映射完成的情况下,每个服务节点内运行的VNF类型和数量可以认为是均匀分布,即服务节点内VNF对加速资源的需求开销与节点内运行的VNF总量成比例的,而服务节点本身的物理资源R(CPU、内存、硬盘)限制了节点内部署网络功能的最大数量,也就反映了节点内VNF对加速资源的需求数量。因此,服务节点内加速资源的部署数量与节点内物理资源R直接相关。
在SDN/NFV架构中,服务器端加速资源与转发节点加速资源共同协作完成对服务链的加速。因此除了节点内物理资源R对服务器端加速资源部署的影响,还要考虑两类加速资源间协作关系,保证加速资源整体部署的合理性。根据上述对两种加速资源对网络功能承载的设定,服务节点内有加速需求的VNF,优先由服务链流量传输路径中,与服务节点相邻近的转发节点内的加速资源承载。换句话说,服务节点与部署有加速资源的交换节点越近,节点内有加速需求的网络功能被转发节点承载的可能性越大,相应地,可以据此减少服务节点内部署的加速资源数量。所以,服务节点内加速资源的部署数量还与部署有加速资源的转发节点距离有关。
综合以上两点分析,服务节点内加速资源与流量转发路径中转发节点内加速资源共同协作,完成对服务链的加速处理,对服务节点内加速资源部署数量可以定义如下:
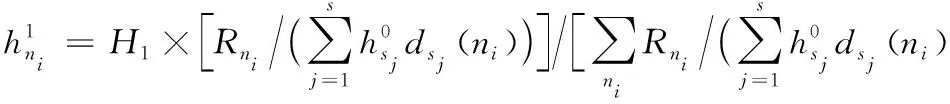
(6)
dsj(ni)=|ni-sj|B
(7)
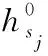
算法2 基于节点协作的服务节点加速资源部署算法。
输入:各服务节点内配置的物理资源R,以及转发节点和服务节点所组网络的邻接矩阵。其中,两个节点相连为链路带宽值,不相连为0;
步骤1 根据算法1,确定网络中各转发节点内加速资源部署数量;
步骤2 用Floyd算法求各服务节点与转发节点间的最短距离;
步骤3 根据式(6)、(7)计算各服务节点的加速资源部署数量;
在TARD算法的阶段1和2,都需要Floyd算法求解节点间的最短路径,需要O(n3)的时间,若网络为疏松图,则时间复杂度可降为O(n2logn+nm)[14],其中n和m分别代表网络拓扑中节点与链路数目。
4 实验结果及分析
为了评估TARD部署算法的有效性,首先TARD算法完成加速资源到各节点内的部署,然后利用基于贪婪算法(Greedy)和禁忌搜素(Tabu Search)的服务链映射算法[15]完成网络功能的映射,部署到各节点内的加速资源尽可能承载网络功能,计算加速资源承载的流量和利用率,作为评价指标。因为目前没有其他的加速资源部署算法,本章只能与考虑节点单一属性的加速资源部署算法(Single-attribute Acceleration Resource Deployment algorithm, SARD)和均匀分配的加速资源部署算法(Uniform Acceleration Resource Deployment algorithm, UARD)进行比较。其中:考虑节点单一属性的部署算法(SARD)是指,对转发节点加速资源只考虑度数、带宽或者介数中心度,而服务节点加速资源只考虑物理资源R;均匀部署算法(UARD)是指将全部的转发节点加速资源和服务节点加速资源平均分配到两类节点内。
4.1 实验环境
采用如图4所示的网络拓扑[16],网络中有13个转发节点、6个服务节点,转发节点之间的链路带宽和服务节点内的物理资源,根据表1的参数设置随机生成。仿真平台采用Matlab R2015a搭建,计算机处理器为Intel Core i5-3450、3.10 GHz,8 GB RAM。

图4 仿真网络拓扑

参数最小值最大值服务节点资源R6001000链路带宽B/(Mb·s-1)300500
设网络有10种功能,其中4种功能需要加速,即γ=1,而有3种功能可以被两类加速资源承载,1种功能只能被服务器端加速卡承载。各类功能传统的物理开销和加速开销以及加速后的吞吐量,根据表2的参数设置随机生成。每条服务链由10类功能中多个VNF组成,数量服从3~5的均匀分布,而服务链的源节点和目的节点,随机从13个转发节点中选取。每条服务链的数据流量服从[3,5] Mb/s的随机分布。根据网络功能对两类加速资源的开销,设定转发节点加速资源可部署的总量为800,部署加速资源节点拓扑势的最低门限Qmin设定为0,服务节点加速资源可部署的总量为135。设定算法性能指标的参数,r0为0.75,r1为0.25。仿真平台用Matlab R2015a搭建,在PC机上(Intel Core CPU i5-3450 3.10 GHz,8 GB RAM)运行。
当底层网络的资源确定后,分别利用Greedy和TS算法将不同服务链数目成功映射到网络中,要求每条服务链中的网络功能映射到不同的服务节点内。其中,Greedy算法根据策略的不同可以分为GFP(Greedy Fast Processing)算法和GLL(Greedy Least Loaded)算法。基于贪婪算法的GFP算法是指,在链路带宽约束下,对每条服务链,依次搜索确定有足够的剩余资源能够承载网络功能的服务器节点,当有多个服务节点均满足要求时,选取相距较近的服务节点进行承载,此时,从源节点到最后一个所选服务器的路径也随之确定;然后,计算出一条从最后一个所选服务节点到目的节点的(最短)路径,依次完成每条服务链的部署;基于贪婪算法的GLL算法与GFP思想类似,从选取距离最近的服务节点,换为选取剩余资源最大的服务节点;TS算法设定服务节点负载均衡为全局优化目标,通过多次搜索完成不同数目服务链到网络中的映射。每种服务链数目重复仿真50次,得到不同服务链映射算法下,TARD算法和要比较的加速资源部署算法的平均性能指标。

表2 VNF参数
4.2 性能分析
图5分别表示利用GFP、GLL和TS算法映射不同数目服务链情况下,不同部署算法下的加速资源承载流量。从图中可以看出,随着服务链数目的增大,加速资源承载的流量不断增大,但不同算法的流量的数值和增长幅度不同。在三种的服务链映射算法和不同服务链数目下,TARD算法的加速资源承载的流量最大,相比其他部署算法承载流量的平均值,能够提升38.4%、41.4%和30.4%。随着服务链数目的进一步增大,尤其是在TS映射算法下,加速资源承载的总流量增长速度开始放缓,已经接近所部署加速资源承载的流量上限。均匀部署算法没有考虑节点间彼此的差异性,部署的加速资源与节点本身的属性不相适应,性能指标最差。只考虑节点单一属性主要考虑节点本身的属性,没有考虑服务链部署时的路径选取,以及两类加速资源间相互影响。随着服务链数目的增加,加速资源承载的总流量较低,是因为部分加速资源部署不合理造成的。TARD算法的部署方法综合考虑节点资源对服务链部署时的影响和两类加速资源间的相互作用,增加了加速资源部署的合理性。因此,TARD算法的加速资源配置策略更加合理,能够负载更多的业务流量。
图6分别表示GFP、GLL和TS算法部署不同数目服务链情况下,不同部署算法的加速资源利用率。从图中可以看出,随着服务链数目的增大,加速资源的使用效率不断增大,但不同算法的加速资源使用效率的上升速度和幅度不同。在相同条件下,相比其他算法利用率的平均值,TARD算法的加速资源使用率最高,提升了10.9%、8.3%和14.5%。由于TARD算法部署的加速资源与节点的传统物理资源相适应,在较少的服务链数目时,就已经实现对使用状态下加速资源的复用,使得加速资源利用率达到较高的标准;随着服务链数目的增加,加速资源的利用率进一步提高,接近满载状态,因此上升速度和幅度相对有限。

图5 加速资源承载的流量对比

图6 加速资源的利用率对比
图7表示不同服务链映射算法下的TARD性能指标。从图中可以看出,相较于GFP算法和GLL算法,不论是加速资源承载的流量,还是加速资源的利用率,使用TS算法映射服务链时,TARD算法的性能指标达到最高。TS算法通过反复迭代计算得到的服务链映射方案更优,节点的物理资源与部署的网络功能更加契合,同样,节点内部署的加速资源与网络功能的加速需求更加匹配。因此,在相同的条件下,当服务链映射算法更优时,TARD算法的性能指标能进一步提高。
5 结语
VNF加速资源能够提升网络功能的数据处理速率,从而满足高速率转发的业务需求,推动了SDN和NFV的进一步发展。本文在所提VNF加速资源统一管理平台的基础上,研究了全网范围内如何将VNF加速资源合理部署到各转发节点和服务节点问题。首先,通过分析VNF加速资源对服务链部署的影响,构建了VNF加速资源部署模型,提出了加速资源部署算法的性能评价指标;然后,针对该问题提出了两段式加速资源部署算法,对转发节点和服务节点内的加速资源部署问题进行了求解,并对算法进行了性能仿真。仿真实验证明,所提算法能够保证加速资源承载更多的业务流量,同时提高加速资源的利用率。在SDN/NFV架构中完成硬件加速资源的部署后,如何高效编排加速资源从而实现服务链的最优承载,目前缺乏相关研究,设计加速资源编排机制将是下一步的研究方向和目标。
[7] YI X, DUAN J, WU C. GPUNFV: a GPU-accelerated NFV system [C]// APNet ’17: Proceedings of the 1st Asia-Pacific Workshop on Networking. New York: ACM, 2017: 85-91.
[8] GE X, LIU Y, DU D H C, et al. OpenANFV: accelerating network function virtualization with a consolidated framework in openstack [C]// SIGCOMM ’14: Proceedings of the 2014 ACM Conference on SIGCOMM. New York: ACM, 2014: 353-354.
[9] LI B, TAN K, LUO L, et al. ClickNP: highly flexible and high performance network processing with reconfigurable hardware [C]// SIGCOMM ’16: Proceedings of the 2016 ACM SIGCOMM Conference. New York: ACM, 2016: 1-14.
[10] DWARAKI A, WOLF T. Adaptive service-chain routing for virtual network functions in software-defined networks [C]// HotMiddlebox ’16: Proceedings of the 2016 Workshop on Hot Topics in Middleboxes and Network Function Virtualization. New York: ACM, 2016: 32-37.
[11] 刘彩霞,卢干强,汤红波,等.一种基于Viterbi算法的虚拟网络功能自适应部署方法[J].电子与信息学报,2016,38(11):2922-2930.(LIU C X, LU G Q, TANG H B, et al. Adaptive deployment method for virtualized network function based on viterbi algorithm [J]. Journal of Electronics and Information Technology, 2016, 38(11): 2922-2930.)
[12] BRONSTEIN Z, ROCH E, XIA J, et al. Uniform handling and abstraction of NFV hardware accelerators [J]. IEEE Network, 2015, 29(3): 22-29.
[13] 李德毅,刘常昱,杜鹢,等.不确定性人工智能[J].软件学报,2004,15(11):1583-1594.(LI D Y, LIU C Y, DU Y, et al. Artificial intelligence with uncertainty [J]. Journal of Software, 2004, 15(11): 1583-1594.)
[14] CORMEN T T, LEISERSON C E, RIVEST R L. Introduction to algorithms [J]. Resonance, 2009, 1(9): 14-24.
[15] MIJUMBI R, SERRAT J, GORRICHO J L, et al. Design and evaluation of algorithms for mapping and scheduling of virtual network functions [C]// NetSoft ’15: Proceedings of the 2015 1st IEEE Conference on Network Softwarization. Piscataway, NJ: IEEE, 2015: 1-9.
[16] FENG H, LLORCA J, TULINO A M, et al. Approximation algorithms for the NFV service distribution problem [C]// IEEE INFOCOM ’17: Proceedings of the 2017 IEEE Conference on Computer Communications. Piscataway, NJ: IEEE, 2017:1-9.
