基于计数型布隆过滤器的可排序密文检索方法
2018-10-16相中启
李 勇,相中启
(1.曲靖师范学院 信息工程学院,云南 曲靖 655011; 2.上饶师范学院 数学与计算机科学学院,江西 上饶 334001)
0 引言
随着云计算技术的日益推广,越来越多的用户选择将本地数据外包给云服务器存储,以获取高质量低成本的应用服务。然而,近年来不断暴发的信息安全事件,尤其是2016全球“勒索”病毒事件的出现,引起了互联网用户对云计算环境下数据隐私安全性的广泛担忧。因此,必须对数据进行加密处理,以密文的形式在云中存储数据,防止隐私信息的泄漏。数据以密文的形式在云中存储,改变了数据之间原有的特性和关联,使得传统基于明文的数据检索方法不再有效。可搜索加密技术以密文的方式建立安全检索索引和保存数据,直接在密文状态下完成对数据的检索,不会泄漏任何明文信息,被广泛地应用于云计算环境下对数据的隐私保护和密文检索;但是,已有的可搜索加密方法存在数据查询更新和删除操作不方便、时间效率低、不支持对查询结果按精确度进行排序等问题,因此,设计一种安全高效、操作方便、支持排序的密文检索方法具有重要的理论意义和实用价值。
1 相关工作
可搜索加密技术起源于Song等于2000年在文献[1]中提出的首个对称可搜索加密(Symmetric Searchable Encryption, SSE)方案——基于密文扫描思想的对称可搜索加密方案(Symmetric Searchable Encryption Scheme based on Ciphertext Scanning, SWP),但该方案不支持文件检索索引,而是采用对称加密技术将文件划分为“单词”进行加密,算法的存储开销大、时间效率极低。此后,国内外学者围绕着如何提高可搜索加密算法的安全性、时间开销、查询精确度、可操作性等问题开展了大量的研究工作。2003年,Goh在文献[2]中提出了基于索引的可搜索加密方案Z-DIX(Index-based Searchable Encryption Scheme),相比SWP方案有较大提升,但是,当检索系统中的文件数目较多时,仍然需要耗费较长的检索时间,效率较低。2006年,文献[3]中,Curtmola等在Song等的基础上,提出了SSE-1、SSE-2方案,进行文件检索时,服务器只需要O(1)时间复杂度即可完成检索操作,然而,在文件进行添加、删除时,服务器需重新构建索引以适应更新状态,索引维护开销较大。针对文献[3]中存在的索引维护开销大、不支持文件动态更新的问题,文献[4-6]对服务器中存放的密文文件的动态添加、更新或删除操作进行了改进,提出了适合密文状态下动态更新的算法。此外,对于如何提高密文检索结果的精确度和排序问题,文献[7]基于树状检索结构提出了改进算法,但该算法存储开销较大。文献[8]为减小存储空间开销,基于二叉树构建了可排序文件检索结构。针对文献[7-8]中存在的索引维护开销大和时间性能低的问题,文献[9]中,提出了一种基于计数型布隆过滤器的分布式文本检索模型(Text Retrieval Model based on Counting Bloom Filter, CBFTRM),但CBFTRM模型无法实现对查询结果排序。文献[10]提出了一种安全多关键词密文排序检索方案,但是该方案中对不同关键词计算的相关性分数并不能有效地说明文件与关键词之间的相关性高低,排序结果不够精确。文献[11]中首次提出了基于隐私保护的多关键词模糊检索方案,大幅提高了文件检索效率和精确度。文献[12]在文献[11]的基础上基于计数型布隆过滤器构建索引向量,使用MinHash算法对关键词降维,减少了索引构建和查询陷门生成时间,同时以计数型布隆过滤器索引向量的计数表示关键词权重,对查询结果排序,但是计数型布隆过滤器索引向量的计数并不能准确地表示关键词与文件间之间的关系,对查询结果的排序并不准确。
综上所述,已有的可搜索加密技术方案在时间效率、检索精确度、排序性能、索引更新能力等方面存在不足之处。为了对已有方案进行改进,本文基于计数型布隆过滤器提出一种适合云计算环境下的可排序密文检索方法——基于计数型布隆过滤器的可排序密文检索方法(Ciphertext Retrieval Ranking Method based on Counting Bloom Filter, CRRM-CBF)。首先,基于计数型布隆过滤器构建安全检索索引,以实现对密文数据的高效检索和索引的动态更新功能;然后,使用文件集中关键词在文件中的出现频率构建关键词频率矩阵;最后,使用词频逆文本频率(Term Frequency-Inverse Document Frequency, TF-IDF)模型计算检索关键词与目标文件的相关度分值,根据检索关键词与目标文件的相关度分值来实现对文件检索结果按精确度排序。
2 预备知识
2.1 计数型布隆过滤器
布隆过滤器(Bloom Filter, BF)起源1970年,由Burton Bloom在文献[13]中首次提出,是一种高时空效率的数据结构,由一个很长的二进制向量和一组相互独立的哈希函数组成,主要用于判断某一个元素是否在某一个集合中:若某一元素经过一组相互独立的哈希函数映射,输出结果对应于布隆过滤器中向量位置序列的值全为1,则可判断该元素属于集合;反之,只要任意相应位置的取值不为1则可判断该元素不属于集合。BF只支持插入和查找操作,不支持删除操作,是一种仅适合应用于静态集合中元素判断的简单数据结构,对于动态集合中的元素判断显得无能为力。
计数型布隆过滤器(Counting Bloom Filter, CBF)[14]是一种在BF的基础上进行改进的数据结构,它的基本原理是,将BF向量中的每一位扩展成一个计数器(Counter),插入元素时,如果有不同元素被r个哈希函数多次映射到同一位置,那么将对应位置Counter的值加1,删除元素时,将对应位置Counter的值减1,CBF在BF的基础上增加了删除操作,支持集合中元素的动态更新,适用于动态集合中的元素判断,如文件检索、网页去重等,BF与CBF的映射结构如图1所示。
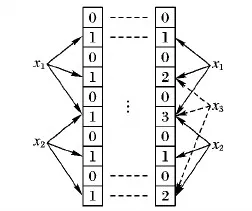
图1 BF与CBF映射结构
2.2 TF-IDF模型
TF-IDF模型[15]是常用于信息检索的一种加权统计方法,用于评价某一关键词对于文件集合中的某一份文件的重要程度,由关键词词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)两部分组成。其中,词频TF表示某关键词在文件中出现的次数,定义为式(1):
(1)
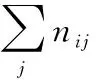
逆文档频率IDF表示某一关键词在文件集合中的普遍性重要程度,通常用作关键词的权重因子,定义为式(2):
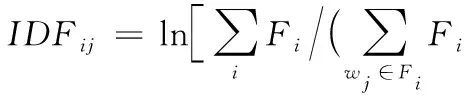
(2)
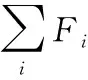
最后,TF-IDF模型以式(3)的值作为查询关键词与目标文件的相关度分值,并从大到小排序,返回用户最感兴趣的top-p个目标文件。
TF-IDF=TFij*IDFij
(3)
3 系统安全模型
云计算环境下可搜索加密系统的安全模型如图2所示,由数据拥有者(Owner User, OU)、授权用户(Authentication User, AU)、不可信云服务器(Cloud Server, CS)3部分组成。
1)数据拥有者:提取文件关键词,构建文件检索索引,并将索引和文件加密外包给云服务器。
2)授权用户:输入查询关键词,生成查询陷门发送给云服务器,获取感兴趣的top-p个目标文件。
3)云服务器:根据密文索引和查询陷门完成计算,给用户返回感兴趣的top-p个目标文件,同时负责密文索引的更新。
由于云计算系统都是在遵守用户数据托管和通信协议的基础下进行工作的,本文认为,云计算系统中的服务器是一个“诚实而好奇”的半可信实体,即,云服务器不会刻意地恶意攻击系统、泄漏用户隐私、或与其他非授权用户合谋攻击系统,但却会出于“好奇”而挖掘用户数据和推送应用服务、泄漏用户隐私。因此,本文考虑选择已知密文攻击模型作为安全目标,在云计算系统通信环境下,云服务器或其他未授权用户不能获取任何明文信息,数据拥有者上传的文件集、安全检索索引,授权用户的查询请求及查询结果等都以密文的形式存在,攻击者只能选择唯密文攻击。

图2 云环境下可搜索加密系统安全模型
4 CRRM-CBF方法
云计算环境中数据检索具有数据量大、用户数量多、检索更新操作频繁等特点,已有的需要线性搜索时间来逐次匹配密文信息且需要大量对数运算的可搜索公钥加密方法显然是不合适的,已有的排序密文搜索算法虽然计算量小、速度高,但是也存在查询精确度不高的问题[16],因此,本文基于CBF提出一种可以实现精确密文排序的可排序密文检索方法CRRM-CBF,下面详细介绍CRRM-CBF方法的具体实现过程。
4.1 主要符号定义及说明
CRRM-CBF方法中所涉及到的一些主要符号定义及说明如下。
F:明文文件集合F=(F1,F2,…Fm)。
C:密文文件集合C=(C1,C2,…Cm)。
FID:集合F中对应文件的标识符集合FID=(FID1,FID2,…,FIDm),这里的FID是数据拥有者自己为了区分发布的文件而随机分配的一个标识,不具有任何挖掘语义。
MID:集合F中对应文件在云服务器中的存储标识符集MID=(MID1,MID2,…,MIDm)。
QID:与检索关键词相关联的文件标识符集合QID=(QID1,QID2,…,QIDm1),QID⊆FID。
W:所有文件关键词构成的集合W=(w1,w2,…,wn),关键词允许在文件中多次重复出现。
ψ:关键词在文件中的出现频率次数构成的关键词频率矩阵。
I:将所有关键词映射到CBF中,构成的文件检索索引向量。
M:拥有k位存储空间的映射向量,其长度允许动态增加,存储关键词映射的取值。
Cψ:关键词频率矩阵密文。
CI:文件检索索引的密文形式,即安全索引。
Qw:检索关键词。
Q:检索关键词向量。
TQ:检索陷门。
4.2 具体实现过程
CRRM-CBF方法的具体实现过程主要包括:
步骤1 Initial()初始化操作。数据拥有者OU从集合F中提取每个文件的关键词,得到关键词集合W,并对关键词进行向量化处理。
步骤2 Preproc()预处理操作。数据拥有者OU统计各关键词在文件中的出现次数记为ψij,表示关键词wj在文件Fi中的出现次数,并以ψij值构造如(4)所示的关键词频率矩阵ψ。

(4)
在ψ的基础上,计算集合F中各文件Fi中包含的关键词数并记为NFi,wj,以及集合F中包含有关键词wj的文件数并记为Nwj,F,其中,NFi,wj的计算公式如(5)所示,Nwj,F的计算公式如(6)所示:
(5)
Nwj,F={Nwj,Fi-1+1,i=i-1|ψij≠0,i=m,j=1,2,…,n|}
(6)
步骤3 BuildIndex_I()、CreatLink()构建文件检索索引、关键词与文件的关联链表。数据拥有者OU先将W中的每个关键词使用r个相互独立的值域为[0,k-1)整数的哈希函数映射到CBF中的M向量,以此作为文件检索索引。然后将索引向量中M[k]位置的计数器Counter扩展成如图3所示的链表头Link.head={M[k],Next},并在表头的后面插入元素Link.element={FID,Next},插入的元素即为与M[k]位置上关键词相符的文件标识符,Next为指向下一个元素的指针,尾部元素的Next指针指向Null。最后,得到文件检索索引I和关键词与文件的关联链表,其结构如图3所示。

图3 关键词检索索引结构
步骤4 KenGen(k,n)产生安全密钥。数据拥有者OU输入安全参数k、n,使用概率密钥生成算法生成安全密钥sk=(M1,M2,M3,S,Pplu),并使用秘密通道将安全密钥sk发给授权用户,这里的秘密通道指采用Kerberos协议来完成对授权用户的身份认证和密钥分发,其中M1、M2为k阶随机可逆矩阵,M3为n阶随机可逆矩阵,S=(0,1)k为k位二元向量,Pplu为一个秘密的大素数。
步骤5 Enc(F,ψ,I,sk)加密。数据拥有者OU使用安全密钥sk对文件集F、词频矩阵ψ、文件检索索引I加密,同时使用MD5函数计算每个文件在云服务器CS中的存储标识符MIDi=MD5(FIDi),最后,将得到的文件集密文C、词频矩阵密文Cψ、安全索引CI、存储标识符MID一起上传云服务器CS。
(7)
(8)
其中:ψ的加密过程如式(7),I的加密过程如式(8),I′、I″为I分解出来的两个子向量,详细的分解过程参考文献[12]中的运算规则进行。考虑到高级加密标准(Advanced Encryption Standard, AES)对称加密运算速率快、安全级别高,适合于加密大规模文件集,本文使用AES加密算法和密钥Pplu对F加密得到密文文件C。
步骤6 Trap(Q,sk)产生检索陷门,授权用户AU输入文件检索关键词Qw=(w1,w2,…,wj),并使用步骤3中的同一组哈希函数将查询关键词映射到CBF中的M向量,得到检索向量Q。然后再采用步骤5相似的方法,使用安全密钥加密检索向量,输出得到检索陷门TQ,文件检索陷门的生成公式如式(9),最后,将检索陷门TQ发往云服务器CS。
(9)
步骤7 Ranking_Search(CI,Cψ,TQ)。密文检索与排序的详细过程如下:
1)云服务器CS收到授权用户AU的检索陷门后,首先进行安全索引CI与TQ之间的内积运算,以检索与查询关键词相符的目标文件,详细计算过程[11-12]如下。

I′T·Q′+I″T·Q″=IT·Q
根据上式文件检索的计算结果,从关键词与文件的关联链表中找到与检索向量中关键词相符的文件标识符集QID,并将QID发送给授权用户AU。
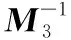
(10)
3)授权用户AU根据关键词频率矩阵ψ,使用式(1)~(6)读取并计算检索关键词的TF-IDF值,以此TF-IDF值作为区分QID中目标文件的相关度分值,并根据这个相关度分值从大到小对QID中的文件排序,返回授权用户AU感兴趣的前top-p个有序的目标文件的标识符。
4)授权用户AU使用相同的MD5函数计算top-p个目标文件的MD5[top-p(QID)]值,并将MD5[top-p(QID)]的值依次发送至云服务器CS。
5)云服务器CS收到MD5[top-p(QID)]值后,根据MID值依次按顺序将C中的top-p个密文目标文件发送给授权用户AU,最后,授权用户AU使用相同的解密算法AES和解密密钥Pplu对前top-p个密文目标文件解密,还原得到排序的明文目标文件,完成整个通信过程。
5 性能分析
5.1 安全性分析
针对有关文件检索索引、检索陷门、关键词频率矩阵的安全性保护问题,本文借鉴了文献[11-12]中的做法,随机生成了可逆矩阵M1、M2、M3,二元向量S,对文件检索索引向量、关键词检索向量及关键词频率矩阵进行加密,由于密钥矩阵的空间是无穷大的,每次随机产生的密钥矩阵只有唯一的一个可逆矩阵,未授权用户想要正确伪造密钥矩阵生成检索陷门、解密关键词频率矩阵的可能性为0,有效保证了文件检索索引、检索陷门、关键词频率矩阵的安全性;同时,为了保证不会因关联检索陷门的泄漏而泄漏隐私信息,本文还使用二元向量S对索引向量I进行分裂运算,针对同一个检索向量产生两个完全不同的陷门,保证了陷门的无关联性。最后,在文件隐私和密钥管理的安全性保护方面,本文分别使用AES对称加密算法和Kerberos协议来完成对文件集的加密和密钥的管理,有效保证了文件集和密钥的安全性,其中AES算法和Kerberos协议的安全性在许多文献已有详细的证明,本文在此不再叙述。综上所述,在保证密钥sk不被人为泄漏的前提下,CRRM-CBF方法针对已知密文攻击模型是安全的。
5.2 可更新能力分析

5.3 可排序能力分析
针对CBF构建索引不带语义功能,不能实现对文件检索结果排序的问题,本文在CBF索引的基础上引入了关键词文件关联链表和关键词频率矩阵ψ,AU首先通过CBF索引判断检索关键词是否属于关键词集W,若属于,则在关键词文件关联链表中找到与检索关键词相关联的目标文件FID,再通过FID在关键词频率矩阵ψ中读取检索关键词的出现频率,使用TF-IDF模型统计计算检索关键词对目标文件区分能力的相关度分值,最后,就可以按相关度分值对文件检索结果实现排序,并且,查找链表和词频矩阵两次比对过程还可以消除CBF索引的假阳性概率。
5.4 效率分析
为了较好地评测CRRM-CBF方法在文件检索时的时间开销、检索精确度方面的性能。本文以安然公司邮件数据集(Enron Email Dataset, EED)作为实验真实数据集[17],从中随机选取文件,基于Java程序设计语言,使用开源开发环境Apache-tomcat-7.0.23、MyEclipse2014、JDK1.7,开源分词器MMSEG4J来实现方案,并在Intel Core i5-3230 2.60 GHz双核心CPU、2.0 GB RAM内存、Windows 7 64位操作系统平台上进行实验测试。
5.4.1 检索时间开销
文件检索的时间开销主要受文件集的规模、文件检索索引的效率、检索陷门的生成时间、检索结果的排序机制影响,可以较全面地衡量一种可排序密文检索方案的整体性能,也是衡量系统服务质量的一项重要性能指标。为了较客观地评价本文CRRM-CBF方法与文献[11-12]中方法在文件检索时间方面的性能,本文分别以CRRM-CBF方法、文献[11-12]中方法构建文件检索索引和检索陷门进行测试。1)实验设定输入10个检索关键词、返回top-10个结果为目标文件,随机从数据集中选取100、200、300、400、500、600、700、800、900、1 000个文件进行文件检索测试,实验测得文件检索的时间开销如图4(a)所示。2)实验设定分别输入1、5、10、15、20、25、30个检索关键词、返回top-10个结果为目标文件,在1 000个文件中进行文件检索测试,实验测得文件检索的时间开销如图4(b)所示。

图4 3种方法文件检索时间开销比较
图4(a)显示,用10个关键词为输入在不同文件集规模下进行文件检索的时间开销结果为,文献[12]中方法最低,本文方法接近于文献[11]中方法;图4(b)显示,在文件数为1 000检索关键词数不同的情况下文件检索的时间开销结果为,在检索关键词数量小于5个的情况下,本文方法接近于文献[12]方法而略优于文献[11]中方法,随着关键词数量的增加,本文方法基本接近于文献[11]中方法而渐差于文献[12]中方法,主要原因是,3种方法的索引建立和陷门生成机制都基本相同,不同的是,文献[12]使用了MinHash算法对关键词进行了降维处理,生成文件索引时需要的哈希函数运算次数较少,减少了构建文件检索索引的时间开销,但对比图4(a)与图4(b)中的结果发现,这种降维处理的效果在少量关键词检索时的时间开销优势并不明显。文献[11]中方法相比本文方法虽然少了对检索结果排序的时间开销,但在构建索引时却多了相似度计算的时间开销,而本文方法的排序只是对常数项关联文件和精确词频的读取与计算,其算法时间复杂度为O(1),当关键词数量较少时,检索结果中与关键词相关联的文件并不多,也就是说,词频读取与计算的时间开销并不大。因此,总体上来讲,本文方法的文件检索时间开销是较小的。
5.4.2 检索精确度
查询精确度是衡量密文检索系统服务质量的另一项重要性能指标,为了客观地测评本文方法与文献[11-12]中方法在文件检索精确度方面的性能,实验设定从数据集中随机选取1 000个文件、输入10个检索关键词、返回top-10个结果作为目标文件,测试在返回的top-10个结果中关键词的相关度分值,以此衡量文件检索结果的精确度,测试结果如图5所示,相关度分值越高,表明检索结果越精确。图5中结果显示,本文方法检索精确度最高,而文献[11]中方法最低,其主要原因是,文献[12]仅以索引向量的计数为关键词权重建立排序机制,其排序精确度受假阳性概率影响,所以排序精确度偏低,本文方法则建立精确的词频矩阵,依据词频矩阵来计算文件检索关键词区分目标文件的相关度分值相对文献[12]来讲更加精确可靠。最后,文献[11]中由于没有建立有效的排序机制,所以精确度最低。

图5 3种方法文件检索精确度比较
6 结语
本文基于计数型布隆过滤器提出了一种适用于云计算环境下密文检索和排序的方法CRRM-CBF。通过构建CBF索引向量,实现了文件的密文检索和索引的动态更新,同时,考虑到CBF构建的索引向量本身不带语义功能,不能实现对目标文件的精确排序功能,文中引入了词频矩阵和TF-IDF模型计算关键词区分文件能力的相关度分值,有效地实现了对目标文件的排序功能。最后,从理论上对方法的安全性能力、可更新能力和可排序能力进行了分析,通过实验测试分析了方法的文件检索时间开销和检索精确度,证明了方法的可行性和有效性,但不足之处是,本文方法在实现排序的过程中,由于引入了词频矩阵和文件关联链表,增加了存储空间和索引更新开销,因此,下一步的研究方向是进一步减少存储空间和索引更新开销。
