基于指标相关性的网络运维质量评估模型
2018-10-16吴沐阳
吴沐阳,刘 峥,王 洋,李 云,李 涛
(1.南京邮电大学 计算机学院,南京 210046; 2.中国移动通信集团山西有限公司 网络部,太原 030009)
0 引言
近年来,随着移动设备的不断普及、通信网络的日益完善,移动用户数量激增,各大运营商的竞争也越来越激烈。为了持续提供高质量的网络服务以及改善用户体验,网络的运行和维护质量管理成为运营商关注的重点,如何评估网络运维质量一直是通信服务领域的一个难题。
网络运维质量包含网络服务质量、维护质量等多个维度的评估目标,涉及到基站性能数据、维护工单数据、告警数据等多种异构数据。现代通信网络范围越来越广泛,使用的设备越来越多样化,各种监控数据持续增长,而传统专家经验的评估方式过于依赖人工分析,需要消耗大量人力资源和时间资源,并且难以应对海量的异构数据和设备线路优化等网络环境变化,最重要的是专家经验法包含太多主观意见,很难合理运用这些数据,建立客观可靠的网络运维质量评估模型,达到全面准确评估各维度质量的目的。国际电信联盟(International Telecommunication Union, ITU)[1]或是电信管理论坛(Telecom Management Forum, TMF)[2]等国际互联网标准化组织只对于网络质量相关参数进行了定义和分类,给出了概念性的模型,但没有对评估方法进行描述,也没有给出具体的评估指标体系,因此网络运维质量评估标准化在实践中的应用比较困难。
本文关注构建网络运维质量评估模型过程中的指标体系建立问题,旨在通过数据驱动的无监督方式来选择评估指标,减少其中人工干预的部分,最终确定全面客观的网络运维质量指标体系。本文提出一种指标分类方法,通过分析指标间的互相关性,将指标划分为多个簇,每个簇中的指标具有相似的信息量,从每个簇中选出一些指标来代表这个类包含的信息,以此来达到全面而不重复地涵盖原数据信息量的效果。这种方法尤其适用于含有过多指标的监控数据,可以减少人力消耗,简化质量评估中权重指定等步骤,防止评估结果受到重复信息的影响。
1 相关工作
网络运维质量评估始终是运营商关注的重点,有很多研究者提出了自己的质量评估模型或是改进了其中的关键技术。对于选定评价指标步骤,运营商使用的传统方法是依靠领域专家经验选取评价指标,客观方法主要有条件广义方差极小法和主成分分析法。文献[3]使用了条件广义方差极小法,该方法在确定一个指标集的值后,另一个指标集的值如果变化幅度很小则表示两个指标集相似,可以删除其中一个指标集。文献[4]介绍了主成分分析法,将原指标数据线性变换为另一组不相关的变量,并且保持总方差不变,然后对新变量的方差按从大到小排序得到指标的重要程度排序。主成分分析法可以同时完成指标选取和权重确定步骤,但是因为经过变换后的变量不再具有物理意义,所以很难解释评估结果。上述两种方法都可以精简指标集合,但是计算复杂不适用于海量异构数据情况。文献[5]提出一种关键绩效指标(Key Performance Indicator, KPI)指标分类方法,计算指标在不同数据集中的相关关系,统计出现多次相关关系的指标确定为相似指标来减少指标维度。
对于指标数据的量化与处理,文献[6]采用了模糊数学理论进行定性指标的量化处理。文献[7]总结了数据的标准化处理方法,包括Z-score标准化法和0-1标准化法等。还有一些文献[8-11]研究了客观的指标权重确定方法:文献[8]提出了一种基于标准方差系数的权重确定方法;文献[9]提出基于指标信息熵的熵权法,通过衡量指标值的变异程度来决定权重;文献[10]比较了离差最大法、熵权法、标准差法和CRITIC(CRiteria Importance Through Inter-criteria Correlation)法等多种客观权重确定方法;文献[11]引入冲突性的概念,对上述方法进行了改进和比较,其中引入冲突性的标准差法效果最好。网络参数指标权重的分析对于网络设备的管理、事件挖掘和故障溯源都能起到辅助作用[12]。
也有一些文献[13-16]构建了完整的质量评估模型:文献[13]使用模糊层次分析法建立了面向网络业务性能的综合评价模型;文献[14]使用灰色关联分析得到选定指标的权重集,并构建了指标集到评价的模糊关系矩阵来完成网络性能质量的评估;文献[15]利用相关向量机对灰色模糊综合评估方法得到的网络质量评估模型进行训练,解决了基于支持向量机的评估模型所存在的过拟合等问题;文献[16]基于TMF的服务水平协议(Service Level Agreement, SLA)建立了网络服务质量评估体系模型,但是这些质量评估模型都采用人工分析方法选择评估指标,缺乏客观性。
各标准组织也提出了一些通用模型和给出了相关术语的定义,对构建网络运维质量评估模型具有启发作用。TMF在GB923标准[17]中提出了与KPI指标相应的关键质量指标(Key Quality Indicator, KQI)的概念以及两者的映射模型,关键指标层级结构。KQI是用于衡量网络服务业务质量的一系列指标,是面向业务的评估指标,是对KPI指标的集成和补充。相比而言,KPI是以网络性能为中心的衡量指标,而KQI则直接反映了网络所承载的端到端的业务服务性能水平。关键指标层级结构只是一种通用思想,并没有给出具体的评估指标。
ITU定义将服务质量[18](Quality of Service, QoS)定义为一种电信业务的特性总和,表明其满足明示和暗示业务用户需求的能力;而网络性能(Network Performance, NP)指的是网络或部分网络提供用户之间通信功能的能力。这两个概念容易混淆,在评价服务质量的过程中只考虑网络性能指标是不全面的,服务质量的评估应该包含网络性能和非网络性能两个方面。网络性能包括误码率、延迟等,而非网络性能包括提供时间、修复时间、资费范围及投诉解决时间等。
根据ITU给出的官方定义,与服务质量相关的术语分为服务、网络和管理三大类[18]。服务类术语包括了呼叫建立时间、业务可接入性性能、平均服务接入延迟、服务恢复手段及时间、语音质量以及意见评分等;网络类术语主要包括了可接入性、错误及故障概率和误码率等类别的指标,这类指标侧重于所提供的网络服务的可用性和可靠性;管理类的术语涉及服务提供的速度和准确率,因此包含很多时延类的指标,也涉及探究故障原因的指标,如中断时长、平均恢复时间等。除了以上对服务质量相关术语的分类,ITU在E.803建议书[19]中还提出了支持业务方面的服务质量参数[20],一种88个,分为12类,涉及服务供应、服务变更、技术升级、服务文档、技术支持、商业支持、计费和收费等多个方面。ITU在G.1020建议书[21]也给出了与用户相关的服务质量与性能的定义。另外,ITU还在E.802建议书[22]中提出了一些概念性的通用模型、性能模型和市场模型。
2 质量评估模型构建的一般化流程
质量评估有助于寻找评估对象存在的问题,帮助改善产品和服务质量,因此近年来受到各业界的广泛关注。质量评估模型及其相关思想技术已成功运用于教育、管理、工程、计算机与通信网络等多个领域[23-25]。虽然各领域的评估对象和评估目的都不相同,但是构建模型的流程是相似的。本章总结并提出了构建运维质量评估模型的一般化流程,一共分为4步。
1)选定评价指标:选取参与评估的指标;
2)指标量化与数据标准化处理:对定性数据进行量化,对所有数据进行标准化处理;
3)确定指标权重:质量评估的关键步骤,根据指标的重要性程度确定权重;
4)建立评价模型:综合标准化后的数据和对应权重,建立评价模型,得到评估结果。
本章还以网络运维质量评估模型为例,介绍各个步骤中的常用技术和关键方法
2.1 选定评价指标
评价指标是评价内容的载体,评价结果由对评价指标进行统计分析获得,因此,选定的合适的评价指标对构建评估模型至关重要。在评估网络运维质量的过程中通常涉及到大量的参数,全部分析会给计算带来一定的困难,需要进一步地筛选指标得到一个更小的而又不丢失原来指标信息的指标集。选择指标主要遵循3个原则[5,13]。
1)精简性:指标过多会使计算变得复杂,而且会使分析结果没有侧重点,缺乏参考性;
2)代表性:指标需要尽量全面覆盖待评估对象的属性,避免信息丢失;
3)不重叠性:指标间应该尽量不重叠,相关性越小越好,防止重复评估给结果带来偏差。
网络运维质量评估指标的选取通常由运营商的专家凭主观经验完成。随着业务类型和网络设备的增加,网络性能数据的参数数量剧增,例如本文实验所使用的某运营商公司的无线网络优化数据的参数就多达590多个,其中包括“切换成功率”“无线掉线率”和“切换成2G平均时长”等,涉及网络的呼叫建立、移动性管理、资源利用和时延等多个维度的内容。凭借人为定义的方式可以达到简化评估指标的效果,但是难以避免信息丢失和信息重复的问题。通信网络也存在设备和线路更新、数据参数变化的情况,耗费大量资源建立的指标体系很可能无法重复使用。
本文提出一种基于相关性分类的指标选取策略,挖掘指标间相互关联关系,将具有相似信息量的指标划分为一簇,选取簇中关键指标来代表整个簇的指标,达到覆盖尽可能多的信息量和减少重叠指标的效果;并且在构建质量评估模型的第一步骤缩小待评估的指标集合,减少后续步骤的计算量。具体方法将在后续的章节中详细叙述。
2.2 指标量化与数据标准化处理
按照指标的数据类型指标,通常被分为定性指标和定量指标。按照ITU给出的定义,定量指标是指可以(利用工具或观察)衡量的参数以及量化确定的性能值[18],如“时延”“接通率”等。这些指标的数据通常表示为数值形式,不需要进过量化处理就可以使用。而定性指标是主观参数,是可利用人工评判和理解来表示的参数[18],例如“是否预处理”“是否延期”等。定性指标的数据表现为如是否、优良中差等文字形式。只有对定性指标进行量化以后才能和其他定量指标一起用于综合评价的计算。
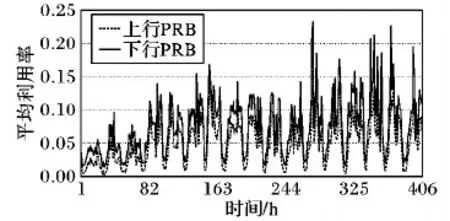
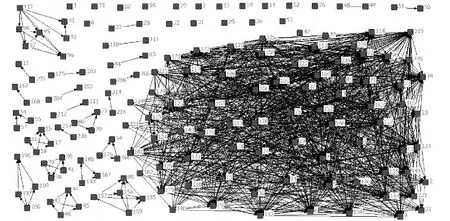
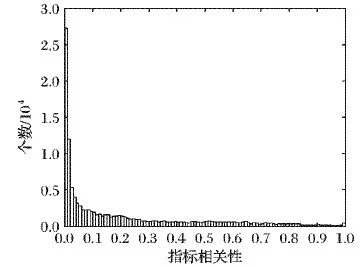
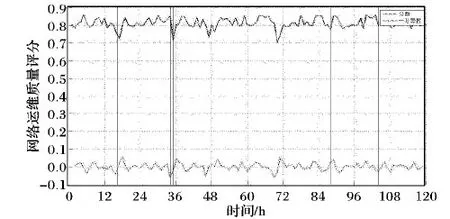
定性指标又可以分为非顺序指标和顺序指标[26]。顺序指标指的是指标之间存在明确的程度大小关系,可以将指标进行排序的指标[27]。例如:简单的“是”“否”可以量化为“1”“0”;而复杂一点的如通话质量参数数据优良中差等,影响程度由差到好排序为G1 gi=i/n;i=1,2,…,n (1) 也可以采取文献[27]提出的取中位数的方法。非顺序指标的数据不存在明显大小关系,很难用客观方法进行量化,只能依靠领域专家经验进行粗略估算。 完成定性指标的量化工作后,指标之间还存在单位和度量不一样的问题,必须将数据进行标准化处理后才能用于评估网络运维质量。数据标准化处理又称无量纲化处理[8,11,13-14,27],是指消除指标间不同单位和度量的影响,使其数据分布在同一个区间内,用来解决指标的可综合性问题。在数据标准化时,需要将指标分为成本型指标和效益型指标。简单地说,成本型指标指的是数值越大越会对评估对象产生负面影响的指标,效益型指标是数值越大越会给评估对象带来积极影响的指标。假设某指标I有数据序列d1,d2,…,dn,其中最大值为dmax,最小值为dmin,使用基于历史数据的0-1标准化方法,可以把数据处理为位于[0,1]区间内的标准数据d1,d2,…,dn。如果指标数据全部相同时,将成本型指标数据标准化为0,将效益型指标数据标准化为1;dmax和dmin不相等时,0-1标准化法计算方法如式(2)所示。 (2) 指标权重的确定是构建网络运维质量评估模型的关键问题之一,权重会对评价结果产生巨大的影响。给指标赋予不同的权重后,就能进一步聚合成综合指标,运营商就可以不用关注繁多的原始指标数据,而是通过分析综合指标得到一段时间内网络运维质量某个方面的波动情况,并以此来判定某个时刻网络运维质量的状态。现代通信网络覆盖范围广、涉及设备多样带来了两个问题:一是网络性能数据指标过多;二是指标间存在复杂的关联关系。这两个问题贯穿网络运维质量评估模型构建的整个流程,尤其给指标确定带来难度。 传统方法凭借领域专家经验来确定权重,这种方法虽然可以突出运营商关注的重点,体现经济效益规律,但是缺点也有很多:一是无法客观地呈现指标的重要性差异;二是无法顾及到指标间的关联关系,无法剔除信息重复的指标带来的影响;另外分析过程还需要耗费大量时间和人力资源。目前很多研究工作[8,11,27-28]提出了一些客观确定指标权重的方法来减少人工的参与。这些方法希望只通过确定权重这一步骤来解决上述两个问题,势必会增加权重确定步骤的计算量。本文将考虑指标间关联关系的问题放到指标选取步骤,而在确定指标权重时只需要考虑体现指标数据间的重要程度差异。 通过标准差法来客观确定指标的权重。标准差又称均方差,反映了数据集中的数据偏离均值的程度。对于某个指标I,如果不同评估对象的该指标的标准差越大,就说明指标I对于不同评估对象的数据差异性越大,也就能提供更多的信息量,在评估质量时将会起到更大的作用,所以权重也应该越大;反之,权重应该越小[11]。具体的计算方法如下:假设选定n个指标构成指标集K={I1,I2,…,In},其中某个指标Ii的全部评估对象在某段时间内的数据序列为Di={d1,d2,…,dm},其均值为Avgi,则指标Ii的标准差可以根据式(3)计算: (3) 则指标Ii的权重wi为: (4) 完成上述工作后需要确定评价公式将权重和指标数据结合起来,得到定量的评估结果,结合适当的可视化展示,可以辅助相关人员分析评估对象的质量变化情况。常用的评价公式有线性加权和、对数线性加权和以及混合加权和等方法。本文采用线性加权和的方法来计算网络运维质量评估结果。假设选定指标集合K={I1,I2,…,In},运用标准差法算得权重集合为W={w1,w2,…,wn},该指标集在某一时刻经过量化和标准化处理的数据为D={d1,d2,…,dn},则这个时刻的评估结果为: score=d1·w1+d2·w2+…+dn·wn (5) 该结果为[0,1]区间的一个数值,按同样方法计算出各个时刻的评估结果后可以得到网络运维质量结果序列,可以将其可视化展示为网络运维质量变化曲线,再进一步进行分析。 指标选取是构建网络运维质量评估模型的第一步,指标选取是否合理将会影响后续步骤的计算复杂程度和最终的评估效果。如上文提到的,指标选取需要遵循三个原则:精简性、代表性和不重叠性。这三个原则指的是在选择指标时,需要用尽量少的指标,尽量全面而又不重叠地覆盖原数据的信息量。 而在现有的指标选取方法中,人工选取依赖专家经验,只能体现运营商关注的重点却无法保障这三个原则,同时需要耗费大量人力资源;常用的主成分分析法运用降维的思想,将多指标转化为少数几个主成分指标,但存在信息丢失的问题。本文提出的基于相关性分类的指标选取策略旨在通过分析指标数据序列之间的相关性,挖掘指标之间的关联关系以此来减少评估指标信息间的重叠,最终形成全面客观的指标体系。 相关性又称相关系数,是用来反映变量之间相关程度的统计指标。相关系数不只有一种,常见的有皮尔逊相关系数等。自然科学界存在着广泛的相关关系,如植物的生长与光照时长、电压相同的情况下电流与电阻等。利用相关性来判断变量间关系的相关分析法已经在社会学、生物学、经济学等多个领域得到应用并取得了一定成效。通信网络的性能指标之间也存在着相关性,比如无线数据中“上行物理资源模块(Physical Resource Block, PRB)平均利用率”和“下行PRB平均利用率”。物理资源模块(PRB)是指是频域上12个连续的载波的资源,“上行PRB平均利用率”和“下行PRB平均利用率”指的是分别在上载和下载时物理资源模块的平均利用率,这两个指标是评价无线性能的常用指标。图1统计了一个月内这两个指标的数据序列波动情况,横坐标为时间,纵坐标为数据值。其中虚线为上行PRB平均利用率,实线为下行PRB平均利用率。两者的波动趋势基本相同,而且在后期计算过程中发现两者之间的确具有相关性,而这两个指标却都在人工选取的指标体系中,这势必会对评价结果产生影响。通过指标间相关性比较,把具有高度相关性的指标归为一簇,将原始指标集合划分为多个簇,在每个簇中选取具有代表性的指标,以此来达到降维的效果。 图1 上/下行PRB平均利用率统计 为了计算指标间的相关性,需要引入互相关函数的概念。互相关在统计学中表示为两个随机矢量间的协方差,而互相关函数用于信号分析领域时,描述的是两个随机信号或是两个时间序列之间的相关程度。网络性能、维护等数据都带有时间标签,因此指标数据也是一种离散的时间序列数据。 (6) 在实际操作时也可以使用Matlab自带的corrcoef函数来完成计算,使用这个函数计算得到的结果是一个2×2的矩阵,其主对角线是序列的自相关系数,恒为1。需要的互相关系数位于副对角线。 rij是处于[-1,1]区间的一个数值,它只能代表指标的线性相关性,正负号只表示相关的方向,只需要使用它的绝对值来代表相关性的程度。对于相关系数的大小所表示的相关程度,在业界还没有统一的说法。文献[5]提出当|rij|处于[0.4,0.7)区间时表示显著相关,|rij|处于[0.7,1]区间时表示高度相关。也有说法表示相关系数|rij|处于[0.3,0.5)区间表示实相关,处于[0.5,0.8)区间表示显著相关,处于[0.8,1]区间表示高度相关等。 接下来,将指标间存在相关性的描述抽象成指标相关性图来说明指标选取策略。每个指标Ii对应一个图中的一个节点Ni,如果两个指标Ii和Ij之间存在相关性,则存在连接它们对应节点Ni和Nj的边E(i,j)=1,否则E(i,j)=0。另设Vij=1/|rij|,用于表示节点Ni和Nj之间的距离,Vij越大,节点间的距离就越大。整个指标相关性图成为一个无向图,设置阈值T来对无向图进行剪边,公式为: (7) 剪边是将低于阈值T的|rij|所对应的E(i,j)设为0,表示认为指标Ii和Ij间相关性微弱,默认为不相关。剪边将原本的无向图划分为数个不连通的子图。利用某运营商公司2017年5月某小区的无线网络优化数据,分析两两指标间的相关性,如果定义阈值T为0.5进行剪边,可以得到如图2的剪边结果示意图,其中每个标有数字的节点都代表一个指标,连线代表两个指标之间具有相关关系。在图2中,有的子图只有单个节点,它们不与其他任何节点相连,也就是和其他指标都没有相似性,称这些单个节点的指标为孤立指标;而另外一些子图,它们由数个节点和边相连构成了连通图,表示这些相连节点的指标存在信息量上的相似性。 图2 剪边后的指标相关性图 需要注意的是,阈值T的选择需要根据具体的情况选择:T过小会导致丢失信息,过大会导致出现大量的孤立指标。虽然孤立指标反映了和其他指标都不重叠的信息,但是将所有孤立指标都纳入指标集会带来评估指标集不精简、评估结果没有针对性等问题。如何在孤立指标中选择合适的评估指标仍然是业界的一个难题。可以使用上文提到的指标权重确定方法来对孤立指标进行排序,选择重要性高的指标加入评估指标体系,或者参考领域专家经验选取运营商普遍关注的指标。 除去孤立指标外,需要在那些被划分为一簇的指标中选取一个或多个指标来代表这一类指标的信息量。选取的原则是尽量选取位于中心的指标。使用图论和网络分析中代表节点重要性的中心性属性来衡量一个点在类中的重要程度。根据对节点重要性的解释不同,中心性的度量方法也有所不同。最常用的几种方法有度中心性、接近中心性和中介中心性等。度中心性比较节点间的度,即与节点相关联的边数,节点的度越大,其度中心性越高,表示它在图中连接的其他节点越多,也就越重要。节点Ni的度中心性DCi的计算公式为: (8) 接近中心性度量节点到其他节点的加权路径,到其他节点的平均最短加权路径越小的节点,它的接近中心度越大,表示它距离其他节点越近。计算接近中心性时需要先计算出节点间的最短路径,可以使用迪杰斯特拉算法来计算最短路径。假设节点Ni和Nj间的最短路径为集合Pathij={p1,p2,…,pl},最短路径对应的权重集合PaWij={v1,v2,…,vl}。在同一个类中的节点Ni和Nj间必存在路径,因为类中的指标相关性图是一个连通图,任何一个节点经过有限条边必定能到达另外一个节点,即Pathij中必定含有一条起始于Ni的边和一条以Nj为终点的边,最短路径集合的长度l大于等于1;而不在同一个集合内的节点间不存在路径,最短路径集合为空集,长度为0,那么,接近中心度CCi的计算公式为: (9) 中介中心性指一个节点作为其他节点间最短路径的中间节点的次数,作为中间节点的次数越多,中介中心性就越高。文献[29]详细介绍了计算某点Nv的中介中心性的方法,可以概括为2步:首先需要找出所有节点对间的最短路径,然后找出经过Nv的最短路径的数量。如果一个节点Nv在节点Ns和Nt的最短路径上,那么Ns到Nv和Nv到Nt都需要是最短路径。节点Nv对于一对节点Ns和Nt的中介中心性BCst为: (10) 假设所有节点的集合为N,那么节点Nv的总中介中心性为: (11) 文献[29]对计算中介中心性的算法作出了改进,这里不展开叙述。 得到所有节点的中心性后,选择簇中代表指标的问题可以抽象为顶点覆盖(Vertex Cover)问题。顶点覆盖问题是指在组成无向图的点集中选择一个最小的子集,并且使得无向图的所有边都至少有一个端点在这个子集中。本文的目的是,希望在簇中选出的指标能够覆盖到尽可能多的相关关系,以保证指标的代表性而且能精简掉更多的指标。也就是说,如果假设每个指标Ii对应连通图中的一个节点Ni,两个指标Ii和Ij相似则对应节点Ni和Nj间存在的边E(i,j)=1的话,本文的目标和解决Vertex Cover问题相似,对于任意的边E(i,j)=1,选择出的点集N*尽可能小,且其中必存在节点Ni或Nj。 另设构成剪边后的子图G的是含有n个点的点集N={N1,N2,…,Nn}(n≥1),以及边的集合E={E(i,j)|i≤n,j≤n,i 算法1 簇中代表指标选取。 输入:子图G; 输出:点集N*。 1) 计算子图G中所有点Ni的中心度Ci; 2) 选择具有最大中心度的点Nmax加入点集N*; 3) 从子图G中删除点Nmax以及和点Nmax相连的边和点; 4) 重复第2)步直到子图G的点被全部删除; 5) 返回点集N*。 实验使用的数据为某地区2016年11月份和2017年5月份的无线网络优化数据,共记录4 034个基站的无线网络性能信息。每条数据的最前面4个字段分别是“时间戳”“小区标识码ECI”“基站标识码DN”和“小区名称”,通过这4个字段可以定位到覆盖某小区的基站在某一时刻的无线网络信息。另外,数据还记录了“RRC连接重建成功次数”“小区最大发射功率”“无线接通率”“无线掉线率”等共596个指标字段。 在选取指标的步骤中,为了选择更加适合实际数据的阈值T,使用某运营商2017年5月数据中的264 584条作为测试数据。首先,统计了两两指标间的相关性分布,如图3所示。其中横坐标是指标间的相关性,分布在[0,1]区间,纵坐标是位于对应区间的相关性的个数。文献[5]中提到业界常用的相关性系数对应相关程度的区间分布,主要有两种说法:一种是认为相关性处于[0.4,0.7)区间时表示显著相关,处于[0.7,1]区间时表示高度相关;另一种说法表示相关性处于[0.3,0.5)区间表示实相关,处于[0.5,0.8)区间表示显著相关,处于[0.8,1]区间表示高度相关。这两种方法都是统计学中常用的相关性阈值的经验法则。为了使参数更加适合网络运维质量的评估,选择两种经验法则中阈值的端点0.3、0.4、0.5、0.7和0.8这5个值,比较不同阈值得到的指标集合对人工选取的指标的覆盖度。 图3 指标间相关性统计 以阈值T等于0.4为例,利用基于相关性的指标选取算法得到38个指标簇和196个孤立指标。剔除领域专家表示不会使用的服务质量类别识别符(Quality of service Class Identifier, QCI)指标,即一组为了减少接口上的控制信令数据传输量并且使设备或系统间的互连更加容易的度量值指标后,得到包含77个指标的关键指标集合。领域专家选取的指标共有36个,该集合与专家选取的指标共有18个相同指标,覆盖度为50%。利用同样的方法,得到使用其他阈值对专家选取指标的覆盖率,如表1所示。 表1 使用不同阈值对人工指标的覆盖率对比 根据统计结果,当选择0.7作为阈值时,关键指标集合对于人工指标的覆盖度最高,也符合经验法则中相关性处于[0.7,1]时表示高度相关的说法。因此,使用0.7作为剪边的阈值T,去掉QCI指标后可以得到19个指标簇和76个孤立指标。 从覆盖率上可以看出,利用本文方法选择的指标和领域专家选择的指标很大部分是重叠的,这也印证了本文方法的正确性和实用性。为了能在同等条件下进一步比较本文构建的指标集与专家构建的指标集的质量,除了簇中代表指标外,规定选择的孤立指标的个数,使得到的关键指标个数与人工选取的相同,都为36个。根据指标选取的原则,指标集应该尽可能覆盖携带不同信息量的信息,也就是评估指标集中的指标相关性应该越小越好。因此,为了评估基于相关性的指标选取策略的效果,使用指标集合内部的相关性平均数AC来衡量待评估指标集的信息的不重叠程度。计算公式如下: (12) 进行比较的两个指标集都使用某运营商2017年5月份数据中的24 702条,根据式(12)计算得到人工指标集的相关性平均数ACh为0.085 8,而基于相关性的指标选取算法所得的关键指标集的相关性平均数ACm为0.059 1,低于前者31%。可以看出在两个指标集的指标个数相同、相似性较高的情况下,基于相关性的指标选取算法得到的指标集合的指标相关性更低、结构更加稀疏,信息更加全面。 然后,将基于相关性选择的36个关键指标代入到网络运维质量评估模型中,可以得到如图4的某小区基站在2016年11月份的网络质量分数变化曲线,其中横坐标是时间节点,纵坐标是某个时间节点的性能评分,分数在[0,1]区间内。定位到某个时刻可以看到该基站此时的网络质量评分,一段时间的评分结果可以反映该基站的网络质量波动,可以协助运维人员排除故障原因,挖掘故障规律。 通过咨询领域专家,了解到基站的性能质量低下可以关联到告警数据中“EnodeB”类型告警;因此推测,评分曲线中凹点对应的时间前后或者评分的下降幅度超过一定比例时将会会出现“EnodeB”类型的告警。为了验证评估模型的准确性,将基站的评分、评分导数和该基站产生的告警结合起来,得到了如图5的某基站的告警-评分对应图。在图5中,横坐标是时间,单位为h,纵坐标是评分结果。其中,纵坐标值在0.8上下波动的线条是分数变化曲线,纵坐标值在0上下波动线条是评分的一阶导数,竖直线条对应的横坐标值代表在该时刻发生了告警。可以看出发生告警的时刻都是分数的凹点或一阶导数的凹点,证明了质量评估模型的正确性,但是,在图中还存在一些凹点并没有发生告警,说明模型存在误报的问题。探究其原因,可能的是指标中包含一些不足以产生“EnodeB”型告警的指标,比如“切换成功率”“无线利用率”等。这类指标数值的低下无疑反映了一段时间内网络性能质量存在问题,但这类问题会自然恢复,不会产生需要相关人员处理的告警。 图4 性能分数变化曲线 图5 基站告警-评分对应图 本文总结了构建网络运维质量评估模型的一般化流程,并提出了一种基于指标间互相关性的指标选取方法。该方法基于指标间的互相关性对原始指标集进行分类,并利用中心度的概念来选择最具有代表性的指标,完成关键指标集合的构建。实验证明该指标集对人工选取的评估指标集有较高的覆盖度,能够对目前运营商使用的评估指标作出补充和修正。本文还整合了0-1数据标准化法和标准差权重确定方法建立了网络运维评估模型,该模型可以辅助运维人员监控网络质量,挖掘网络故障规律。本文利用实际数据验证评分结果对告警具有较高的预测准确度,但是存在很多误报。为了进一步完善模型,接下来将通过广泛的实验,利用历史告警发生前后的评分情况、评分波动程度等作为特征,制定告警判定标准,减少误报,提高预测准确率。2.3 确定指标权重
2.4 建立评价模型
3 基于相关性分类的指标选取策略
3.1 算法思想
3.2 方法描述
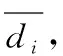
4 实验


5 结语
