基于多层非负局部Laplacian稀疏编码的图像分类
2018-10-16张景会吴克风孟晓静
万 源,张景会,吴克风,孟晓静
(1.武汉理工大学 理学院,武汉 430070; 2.北京机电工程研究所,北京 100074)
0 引言
近年来,图像分类成为机器学习领域的研究热点,而图像表示是图像分类的核心问题,其中应用最广泛的是稀疏编码。Yang等[1]提出一种基于尺度不变特征变换(Scale-Invariant Feature Transform, SIFT )描述子并结合空间金字塔匹配(Spatial Pyramid Matching, SPM)的稀疏编码(Sparse Coding)算法(ScSPM);为了防止编码过程中图像块之间的相似性信息丢失,Gao等[2]在ScSPM的基础上引入图形Laplacian算子,提出基于Laplacian的ScSPM(Lsc-SPM)图像分类算法,提高了稀疏编码的稳定性,增强了稀疏编码的鲁棒性。虽然两者能在一定程度上提高分类精度,但没有考虑到局部性,在某些假设下,局部性比稀疏性更重要,因此Wang等[3]提出一种基于局部约束的线性编码(Locality-constrained Linear Coding, LLC);近邻数K的大小影响着LLC编码的分类性能,编码中的某些正值元素与负值元素的差值绝对值随K值的变化而变化,导致LLC编码的不稳定,因此刘培娜等[4]在LLC优化模型的目标函数中加入非负性约束,提出了一种称为非负局部约束的线性编码算法(Non-Negative Locality-constrained Linear Coding, NNLLC);Han等[5]利用非负矩阵分解(Non-negative Matrix Factorization, NMF)和Laplacian算子,提出基于非负性和依赖性约束的稀疏编码方法(Lap-NMF-SPM)。
以上稀疏编码方法都是在单层结构的基础上进行的,而近年来,在视觉识别领域通过深度学习方法直接从数据中学习有效特征变得越来越流行,已有很多学者验证了多层架构模型比单层结构具有更强的特征学习能力,例如自动编码器[6]、限制玻尔兹曼机[7]、卷积神经网络(Convolutional Neural Network, CNN)[8]等深层架构。Guo等[9]提出一种基于两层局部约束稀疏编码体系结构的新特征学习方法,利用双层结构来学习中间层特征,并采用局部约束项来保证编码的局部平滑性,取得了较好的效果;He等[10]将稀疏编码扩展到多层体系结构,提出一种新的称为深度稀疏编码(Deep Sparse Coding, DeepSC)的无监督特征学习框架,该方法通过从稀疏到密集模块连接不同层次的稀疏编码器,得到了良好的分类性能;Gwon等[11]提出一个基于多层稀疏编码的深度稀疏编码网络(Deep Sparse-coded Network, DSN),采用最大值融合后的稀疏编码作为下层的密集输入,将融合当作神经网络里的非线性激活函数,克服了简单堆叠稀疏编码器的缺点。Zhang等[12]引入深度稀疏编码网络(Deep Sparse Coding Net, DeepSCNet)的深层模型,结合CNN和稀疏编码技术的优势进行图像特征表示。Papyan等[13]提出一个新的多层卷积稀疏模型(Multi-Layer Convolutional Sparse Coding, ML-CSC),并使用分层阈值算法来解决该问题。Zhou等[14]提出一个深度稀疏编码网络的图像分类算法,可以直接从图像像素自动发现高判别性特征。虽然上述多层稀疏编码方法能在一定程度上减少重构误差,提高分类性能,但是都忽视了图像的局部信息,导致编码不稳定。为了达到全局稀疏,避免局部特征之间可能相互抵消,更多地提取特征之间的空间几何信息,万源等[15]提出融合局部性和非负性的Laplacian稀疏编码的图像分类算法,有效解决了局部性信息缺失和特征相互抵消的问题,改善编码的不稳定并保持特征之间的相互依赖性。
很多研究表明,与单层稀疏编码相比,深层架构模型通过一层层的非线性网络结构来表征数据的内在分布,提取图像更深层次的抽象特征,有效刻画图像的内在信息,具有高效的特征表达能力,克服了单层模型的局限性。因此本文将稀疏编码模型扩展到多层架构模型中,提出一个多层融合局部性和非负性的Laplacian稀疏编码算法。另外,在稀疏编码阶段,本文利用非负局部Laplacian稀疏编码,不仅考虑了特征之间的局部关系与空间关系,而且解决了特征之间可能会相互抵消的问题,达到了全局稀疏的目的。本文的方法可以学习不同的特征层次结构,同层的稀疏编码可以保持图像块之间的空间平滑度,下层在上层的基础上可以捕获图像的更多空间信息,使得图像表示具有更强的鲁棒性。
1 相关工作
对于图像分类来说,局部特征编码不仅可以精确地模拟图像,还可以提高图像分类性能。简要介绍两种编码方法:稀疏编码和Laplacian稀疏编码。稀疏编码使用少量的基向量来学习图像的有效表示,目的是学习M空间中的超完备(基向量的个数远大于维数)字典U,并选取尽可能少的基向量,将输入特征向量简洁、有效地表示为这些基向量的线性组合。
1.1 稀疏编码
词袋模型(Bag of Words,BoW)和空间金字塔匹配模型(Spatial Pyramid Matching,SPM)是图像分类中两种经典的编码方法,能够很好地进行图像表示,但在生成视觉字典的过程中,BoW和SPM使用的K-means方法极易造成重构误差,从而导致语义信息的丢失。因此,Yang等[1]引入稀疏编码(Sparse Coding, SC)概念对传统的向量量化方法进行改进,提出ScSPM方法,具体优化问题如下:
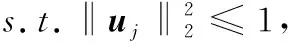
(1)
其中,X∈RD×N为特征矩阵,U∈RD×M为非负字典,S∈RM×N为相应的稀疏编码,第一项为重构误差项,第二项为稀疏性惩罚项,λ为正则化参数,l1范数用来保持编码的稀疏性,其中‖·‖F表示矩阵的Frobenius范数。
1.2 Laplacian稀疏编码
考虑到传统稀疏编码方法对特征的敏感性,导致相似的特征编码成不同的码字,Gao等[2]在稀疏编码的基础上引入Laplacian矩阵以保留相似局部特征编码的一致性,提出Laplacian稀疏编码方法,有效改善了编码的不稳定性,保留了图像块之间的相似性信息。具体优化问题如下:
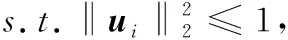
(2)

由于同时优化目标函数中的U和S,该问题是非凸的,这样很难找到一个全局最小值,但是优化函数分别关于U或者S是凸的,那么交替优化U和S就会存在全局最优解,因此交替固定U(或者S)来优化S(或者U)。
2 本文方法
单层稀疏编码虽然能够有效地表示图像,但多层稀疏编码可以学习不同的特征层次结构,同层的稀疏编码可以保持图像块之间的空间平滑度,下层可以在上层的基础上捕获图像的更多空间信息。基于此,本文提出一个两层的具有非负性和局部性约束的Laplacian稀疏编码(Laplacian Sparse Coding by incorporating Locality and Non-negativity, LN-LSC)方法,用于学习可辨别性的层次特征。图1为本文提出的MLLSC图像分类模型的结构示意图。
在图1中,本文提出了一个2层的稀疏编码架构,主要包括输入层、两个稀疏编码隐藏层、输出层,每个稀疏编码层都可以学习相应级别的特征表示,并训练相应的字典和稀疏编码。在稀疏编码阶段,迭代地使用近似解析解来更新字典以最小化优化误差;在池化阶段,利用平均区域划分对稀疏编码进行最大值融合;此外,将局部非负性约束项引入到优化函数中,以强调特征量化期间的平滑限制。本文方法旨在通过连续编码过程尽可能多地提取具有可判别性的特征,最终实验结果证明,两层结构比单层稀疏编码结构更有效。MLLSC算法模型主要包括以下几个步骤:

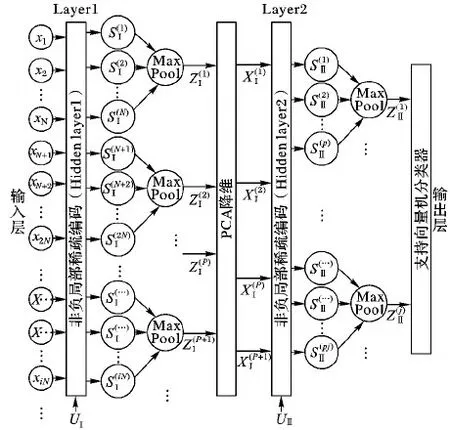
图1 MLLSC算法的整体框架
2.1 单层Laplacian稀疏编码的改进
尽管Laplacian稀疏编码(Laplacian Sparse Coding, LSC)能在一定程度上减小重构误差,但是LSC具有不稳定性,忽略了特征之间的局部信息;并且在LSC的优化问题中减法的使用导致特征之间相互抵消,造成图像特征信息的丢失。因此本文采用融合局部性和非负性的Laplacian稀疏编码方法,即将局部性加入到Laplacian稀疏编码的优化函数中,保证了相似的特征具有相似的编码,且在优化问题的约束条件中引入非负性,克服了图像局部性特征信息丢失的缺陷,达到了全局稀疏的目的。首先从局部特征中随机选取部分特征作为模板特征来训练非负字典U和稀疏编码V,具体的优化问题如下所示:
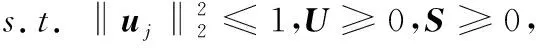
(3)
其中:X=[x1,x2,…,xN]为图像的SIFT特征矩阵;U=[u1,u2,…,uM]为非负字典,S=[s1,s2,…,sN]为相应的稀疏编码,ui为字典U的第i个基向量;di表示局部适应器[3],它为每个基向量赋予不同的自由度,其与输入描述子xi的相似性成比例;⊙代表两个列向量逐元素相乘;tr(·)表示矩阵的迹。具体表达式为:
di=exp(dist(xi,U)/θ)
dist(xi,U)=[dist(xi,u1),dist(xi,u2),…,dist(xi,uM)]T
其中:θ为调整权重衰减的参数;dist(xi,bj)表示xi和bj之间的欧氏距离。
2.2 学习局部约束的非负字典和稀疏编码
本节将对引入局部性和非负性的Laplacian稀疏编码的优化问题进行求解,主要训练局部性约束的非负字典,学习相应的稀疏编码。
对于式(3),同时优化U和S虽然是非凸的,但交替优化U和S却是凸的,从而求得全局最优解。首先固定X和U,目标函数转化为如下优化问题:
s.t.S≥0
(4)
将目标函数转化为矩阵迹的形式,并引入Lagrange乘子φij≥0,且φ=[φij]。构造拉格朗日函数[15]如下:
L(S,φ)=tr(XTX-2STUTX+STUTUS)+
tr(α(d⊙S)T(d⊙S)+βSHST)-tr(βSWST+φST)
(5)
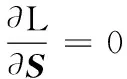
(6)
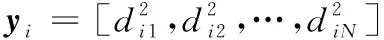
现固定特征矩阵X和系数矩阵S来学习字典U,式(3)变成了具有二次约束的最小二乘问题:
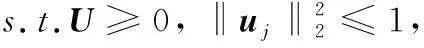
(7)
本文采用拉格朗日对偶的方法来求解该问题。设λ=[λ1,λ2,…,λM],其中λi表示第i个不等式约束‖uj‖2-1≤0的拉格朗日乘子,最终得到拉格朗日对偶问题如下:
s.t.λi≥0,i=1,2,…,M
(8)
其中,Λii=λi,该问题可通过共轭梯度方法来解决,Λ*为最优解,则可得最优字典:
U*=(XST)(SST+Λ*)-1
(9)
2.3 多层LN-LSC算法的描述
多层稀疏编码采用空间连续的图像块作为输入,使得学习到的图像表示更有效。其中,一幅图像的两层非负局部Laplacian稀疏编码过程如图2所示。
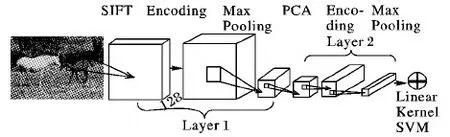
图2 一幅图像的编码流程
其中输入层是图像的SIFT特征描述子:{x1,x2,…,xN},{xN+1,xN+2,…,x2N},…,{xiN-N+1,xiN-N+2,…,xiN}。
然后对提取的SIFT特征描述子进行融合局部性和非负性的LSC(LN-LSC),在编码过程中进行字典学习,利用梯度下降法更新字典U,根据式(4)求出字典;然后根据稀疏编码S的更新规则对稀疏编码进行迭代更新,最后得到第一层的稀疏编码:
⋮
利用LN-LSC算法得到每个特征描述子的稀疏向量S∈RM×N之后,将每一个图像块得到的稀疏编码进行最大值融合,可得图像块的稀疏表示:
zl=max{|sl1|,|sl2|,…,|slN|};l=1,2,…,M
其中:sli表示稀疏向量sl的第i个元素;而zl是融合之后每个图像块稀疏表示的第l个元素。每一个图像块的稀疏向量用z=[z1,z2,…,zM]来表示,即:
⋮
为了防止过拟合现象的出现,在进行第二层LN-LSC之前,对第一层最大值融合后的稀疏编码进行主成分分析(Principal Components Analysis, PCA)降维,去掉冗余特征,降低特征的维数,保留图像主要信息,利用特征向量张成的子空间Γ=(μ1,μ2,…,μr)及特征变换Y=ΓX,得到降维后的特征矩阵,其中μ1,μ2,…,μr(r≤n)为特征值对应的特征向量:
⋮
一方面,将第一层融合后的稀疏编码与第二层融合后的稀疏编码结合作为输出;另一方面,将PCA降维后的密集编码作为第二层的输入。第一层的最大值融合是针对每个图像块的SIFT特征描述子的稀疏编码进行的,得到的是每个图像块的稀疏表示;而第二层的最大值融合是针对每个图像块的稀疏向量进行的,得到的是每个图像的稀疏表示。第二层进行与第一层同样的操作,进行最大值融合:
zl=max{|s1l|,|s2l|,…,|spl|};l=1,2,…,M
其中,spl表示第p个图像块稀疏表示的第l个元素,则整个图像的稀疏表示为:ZⅡ=[z1,z2,…,zM],zi表示整个图像稀疏表示ZⅡ的第i个元素。图3为了第一层和第二层稀疏编码和最大值融合的过程:
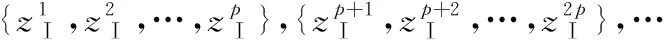
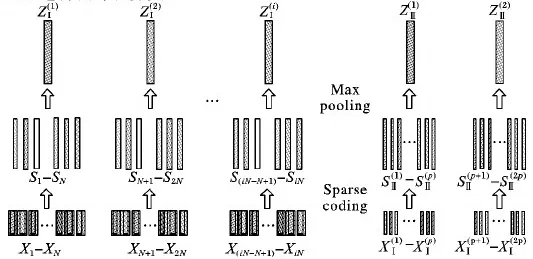
图3 第一、二隐层的稀疏编码及最大值融合过程
3 实验及结果分析
本文使用Corel-10、Scene-15、Caltech-101和Caltech-256四个数据集验证MLLSC图像分类算法的有效性。首先采用实验验证的方法,从准确率方面验证本文模型的合理性,将本文方法与3种单层稀疏编码方法和1种多层稀疏编码模型进行对比,再次证明本文方法在整体分类性能上的优势。为了准确评估分类模型的性能,本文采用10-折交叉验证方法。
3.1 数据集
本节主要介绍4个标准的数据集,4个数据集如下:
Corel-10:该数据集包含10种类别图像,每个类别有100张图像,该数据集共有1 000张图像。
Scene-15:该数据集包含15种场景图像,每个类别有200~400张图像,该数据集共有4 485张图像。
Caltech-101:该数据集包含101种对象类别的图像,每个类别约有31~800张图像,该数据集共有9 144张图像。
Caltech-256: 该数据集包含256类对象,每一类图片的数量都大于等于80张。本文从每一类中分别随机选择15、30和60作为训练样本,其余的作为测试样本。
其中,Corel-10数据集的部分样本图像如图4所示。

图4 Corel-10数据集部分图像
为了验证本文方法的有效性,将本文方法和以下几种方法进行对比分析。
1) ScSPM:利用稀疏编码的空间金字塔匹配的图像分类算法,在图像的不同尺度上进行稀疏编码,并结合空间金字塔匹配方法表示图像。
2) LScSPM:Laplacian稀疏编码方法,利用局部特征之间的依赖关系构建Laplacian矩阵,并将Laplacian矩阵引入到稀疏编码的目标函数中来保持局部特征的一致性。
3) LN-LSC:融合局部性和非负性的Laplacian稀疏编码方法,将局部性和非负性加入到拉普拉斯稀疏编码的目标函数中,使得编码过程更稳定,保留更多的特征。
4) DeepSC:深度稀疏编码算法(Deep Sparse Coding)将稀疏编码扩展到多层体系结构,通过稀疏到密集模块连接不同层次的稀疏编码器,从稀疏到密集模块是局部空间融合和低维嵌入的步骤,能够学习图像的多层稀疏表示。
3.2 实验设置
本文采用10-折交叉验证来测试MLLSC算法的有效性。将Corel-10、Scene-15和Caltech-101三个标准数据集随机分成10份,依次将其中9份作为训练样本,剩余1份作为测试样本进行测试。每次实验都会得出相应的准确率,每次准确率的平均值作为对算法精度的估计;最后,将MLLSC算法与其他方法进行比较并分析结果的有效性。
本文选取4×4的粒度对图像进行平均区域划分,将每个图像平均分成p=16(4×4)个图像块。在特征提取阶段,利用16×16的滑动窗口、步长为8进行SIFT特征提取,每个局部特征描述子均为128维,即D=128;在训练字典阶段,固定两个隐稀疏编码层字典的大小为M=1 024;利用K近邻构建相似矩阵时,取K=5。
在本文优化问题中,目标函数和约束条件所涉及的参数主要包括α,β和θ,针对不同的数据集,设置参数的值也不同。比如:对于数据集Corel-10和Scene-15设置α=0.4,β=0.2,而对于Caltech-101数据集,设置α=0.3,β=0.1。构造总的优化函数时,在3个数据集上,α和β的不同取值对分类效果的影响如图5所示。
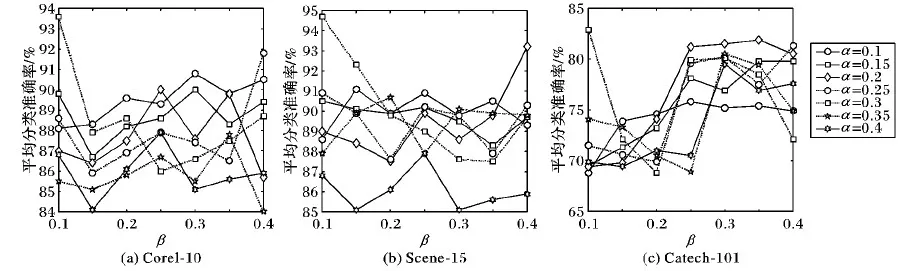
图5 α和β对分类准确率的影响
3.3 算法性能比较
这一节对本文所做实验进行性能分析,基于四个标准数据集的分类效果,将本文所提出的方法与三种单层稀疏编方法包括ScSPM、LScSPM、LN-LSC,一种多层稀疏编码方法DeepSC进行比较。其中,表1为MLLSC算法与三种单层稀疏编码方法在Corel-10、Scene-15两个数据集上的分类准确率,表2为Caltech-101数据集上不同训练样本下的分类准确率,分别与三种单层稀疏编码模型和一种多层稀疏编码模型对比验证的结果,表3为Caltech-256数据集不同训练图像数目下的分类准确率,同样对比三种单层稀疏编码模型和一种多层稀疏编码模型。
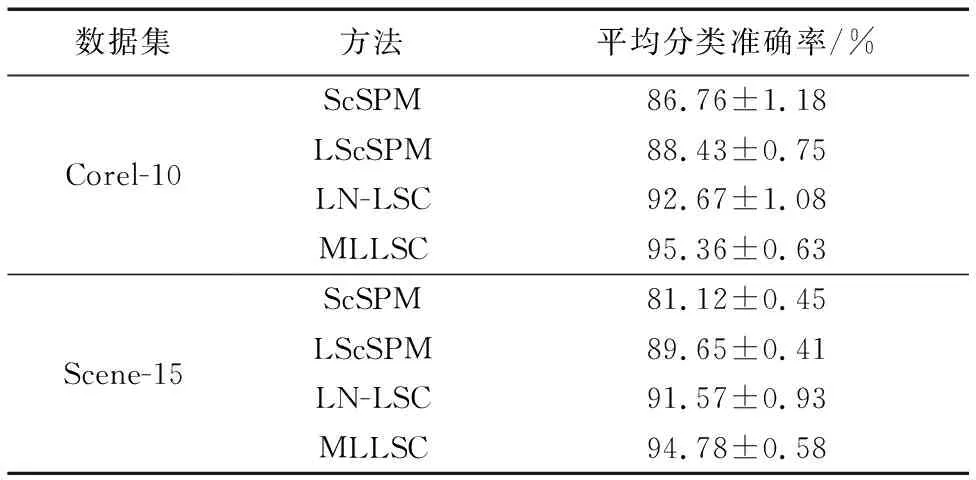
表1 4种方法在Corel-10和Scene-15上的分类结果
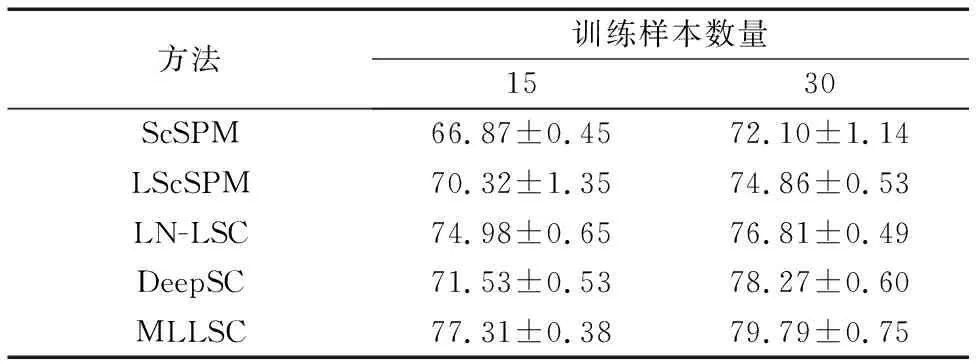
表2 5种方法在Caltech-101数据集上的分类结果 %
从表1的实验结果可以看出,本文算法在2个数据集上的测试结果整体优于其他算法。除了MLLSC算法之外,LN-LSC算法的准确率最高,与LN-LSC相比,MLLSC的准确率提高了约3%。对于前三种算法,均是在单层结构上进行的,而本文方法结合深度学习模型强大的学习能力,提出一个多层架构,将图像的层次稀疏特征集合到一起,捕捉了图像信息的多个方面,学习到图像的更多特征信息,因而有效提高了图像的分类性能。另一方面,LScSPM算法仅在优化函数中加入了Laplacian正则项,忽略了特征的局部性和非负性,而本文算法结合了局部性和非负性,使相似的特征尽可能地编码成相似的码字,在一定程度上改善了编码的不稳定性,并克服了局部信息丢失和特征相互抵消的缺陷,有效提高了分类准确率。

表3 5种方法在Caltech-256数据集上的分类结果 %
由表2的实验结果可以看出:本文方法的分类性能均优于其他方法,在融合局部性和非负性的Laplacian稀疏编码的基础上构建多层稀疏编码架构,有效提高分了类性能;与ScSPM算法相比较,DeepSC算法的平均分类准确率提高约6%,说明多层稀疏编码能在不同的层次和不同的空间范围上学习图像的稀疏表示,能够有效学习图像的特征信息,提高了图像的分类性能。与DeepSC算法相比,MLLSC算法在优化函数中不仅引入了Laplacian正则项,而且在优化函数中添加了局部性,在约束条件中添加了非负性约束,减小了量化误差,使得编码更加稳定,准确率提高1%~6%。与LN-LSC算法相比,MLLSC将稀疏编码方法扩展到了多层架构,可以学到图像的层级特征,获得图像的更多特征信息,而且本文利用平均区域划分(Average Region Division,ARD)来代替了空间金字塔划分,使得融合后的特征向量更稀疏。
为了充分证明MLLSC算法的有效性,将MLLSC算法与已有的四种算法在Caltech-256数据集上进行实验验证,结果如表3所示,当训练图像数目为15,30,60时,与三种单层稀疏编码算法相比,MLLSC算法在分类准确率上取得了较好的结果;特别地,与深层稀疏编码算法DeepSC相比,训练图像数目分别为15、30和60时, MLLSC算法的准确率分别提高了约2.1%、1%和1.3%。由此可见,本文方法将单层稀疏编码扩展到多层架构,并且每层稀疏编码均在Laplacian稀疏编码的基础上引入了局部性和非负性,有效提高了图像的分类性能。
3.4 不同参数值对算法的影响
影响分类准确率的因素很多,图6给出了在数据集Caltech-101上,ScSPM、LScSPM、LN-LSC和MLLSC方法选择不同训练样本数和不同尺寸大小的字典的分类准确率。在该数据集上训练样本数分别设置为:15,20,25,30,35,40,45,50,55和60。由图6(a)可知,随着训练样本数的增加,MLLSC的分类准确率呈现平稳上升趋势;分别设置字典大小分别为:256,512,1 024,2 048和4 096。由图6(b)可知,随着字典尺寸的增加,所有方法的分类效果逐渐变优直至呈现平稳趋势。当训练样本数或字典大小一定时,本文方法都优于其他单层结构的稀疏编码方法,说明了本文方法在多层的基础上提取了图像的更多重要信息,进而提高了分类准确率。因此,本文MLLSC框架能够学习到图像的层次特征,捕获图像的重要信息,从而使得图像的特征表达更有效。

图6 不同参数下的分类准确率比较
3.5 复杂度分析
假定模板特征数量为N,字典大小为M,一幅图像的区域划分数量为p,构造Laplacian算子的计算复杂度为o(N*N),局部性约束的计算复杂度为o(N*M),假设第一层循环迭代t1次,第一层总的计算复杂度为o(t1*N*(N+M)),同理第二层总的计算复杂度为o(t2*M*M),针对编码融合阶段,空间金字塔划分过程中涉及到金字塔的层数pLevels和直方图的个数nBins,因此复杂度为o(N*+pLevels*nBins),而本文方法在融合阶段利用的是平均区域划分,计算复杂度为o(p*M),远小于利用空间金字塔划分的复杂度。综上所述:MLLSC算法总的计算复杂度为o(t1*N*(N+M)+t2*M*M)。
4 结语
特征学习一直是机器学习的核心问题,受单层稀疏编码优异特征学习能力的推动,本文提出了多层-融合局部性和非负性的Laplacian稀疏编码算法(MLLSC),将稀疏编码扩展到深层特征学习框架。多层框架通过池化步骤连接来自不同层次的稀疏编码器,其由局部空间融合步骤和降维步骤组成。这种新方法能够在不同的抽象层次和不同的空间范围上学习图像的稀疏表示。本文在多个视觉对象识别数据集上测试MLLSC,均取得较高的分类准确率,且优于所对比的稀疏编码方法。下一步目标是将本文提出的MLLSC方法扩展到其他的分类,如音频识别问题等。
[13] PAPYAN V, ROMANO Y, ELAD M. Convolutional neural networks analyzed via convolutional sparse coding [J]. Journal of Machine Learning Research, 2017,18:1-52.
[14] ZHOU S, ZHANG S, WANG J. Deep sparse coding network for image classification [C]// ICIMCS ’15: Proceedings of the 7th International Conference on Internet Multimedia Computing and Service. New York: ACM, 2015: Article No. 24.
[15] 万源,史莹,吴克风,等.融合局部性和非负性的Laplacian稀疏编码的图像分类[J].模式识别与人工智能,2017,30(6):481-488.(WAN Y, SHI Y, WU K F, et al. Laplacian sparse coding by incorporating locality and non-negativity for image classification [J]. Pattern Recognition and Artificial Intellgence, 2017, 30(6): 481-488.
