基于社会情感优化算法的船舶转向避碰决策
2018-10-16于家根刘正江卜仁祥李伟峰高孝日
于家根, 刘正江, 卜仁祥, 李伟峰, 高孝日
(大连海事大学 航海学院, 辽宁 大连 116026)
多船会遇在海上实践中属于复杂的会遇局势,船舶避碰决策是智能避碰技术研究的关键。为此,研究者尝试将群智能优化算法应用于船舶避碰决策中,并取得了一定的研究成果[1-5]。
文献[1]应用人工鱼群算法,主要研究单船会遇的3种局势(互见中的追越、对遇、交叉相遇)下的最优避碰路径问题,属于非多船会遇的避碰决策。文献[2]应用蚁群算法,针对多船会遇,重点考虑最危险船舶的单船会遇情况,研究3种局势下避碰路径问题。文献[3]基于蚁群算法在避碰决策上全局考虑所有的会遇船舶,但未划分船舶会遇局势。文献[4]应用粒子群算法,重点研究多船会遇的转向避碰决策,将问题的可行解空间取为[10,180],却未考虑大幅度避碰要求和某些局势下可能左转避碰的情况。文献[5]基于粒子群算法,侧重研究无人艇的避障问题,仅考虑规则中的3种局势。
然而,传统的群智能优化算法大多模拟动物群体的社会行为,由于这些算法模拟的动物群体只具有较低的智能,个体难以进行有效的决策,所以这些算法易陷入局部极值点[6]。人类是一个具有高智能行为的群体,社会情感优化算法[7-8](Social Emotional Optimization Algorithm,SEOA)能够模拟具有较高智能的人类群体的社会行为。在SEOA中引入个体情感因素,利用个人的情绪值控制进化策略,以提高算法的性能来改善其多样性和灵活性[9]。
在国际海上避碰规则(简称规则)和良好船艺的框架下, 本文针对船舶会遇的多种局势,分别建立互见和不在互见两种情况下的船舶转向避碰行动矩阵,限定问题的求解空间,基于SEOA全局快速寻优能力,选择考虑船舶碰撞危险度和航程损失的目标函数,最终获取多船会遇时船舶转向避碰决策的最优转向角。
1 问题描述
规则部分条款在船舶转向避碰行动上做了限制性规定(规则14,规则15, 规则17,规则19)。结合规则8对避免碰撞的行动要求,充分运用良好的船艺,限定船舶转向避碰的方向和范围,即问题的求解空间。
评价船舶转向避碰决策的好坏,要考虑转向后各目标船的安全驶过距离和本船的航程损失要素,即船舶转向避碰的目标。
由此,借鉴群智能优化算法寻找最优解问题,可以将多船会遇船舶转向避碰决策问题抽象为:在限定的问题求解空间中,针对避碰目标函数,全局范围内寻找最优避碰转向角。
2 问题的求解空间
以普通机动船(Power-Driven Vessel, PDV)作为研究对象,帆船会遇条款(规则12)暂不考虑。考虑互见中的追越、对遇、交叉相遇和不同种类的船舶会遇(本船与失控船(Vessel not under Command, NUC)、操限船(Vessel Restricted in Her Ability to Maneuver, RAM)、从事捕鱼船(Vessel Engaged in Fishing, VEF)和帆船(Sailing Vessel, SV)的会遇)的情况和不在互见中的船舶会遇的情况。
与文献[10]确定重点避让目标船的做法不同,所进行的研究全局考虑所有会遇船舶,建立船舶转向避碰行动矩阵为
(1)
式(1)中:矩阵的行为目标船的相对方位(Relative Bearing,RB),矩阵的列为目标船(Target Ship,TS)的类型;amn为本船对处在第m行的RB范围内,第n种类型的目标船应采取的转向避碰行动值;矩阵中的值用-1,0,1表示,-1为本船向左转向避碰;0为本船左、右转向避碰均可;1为本船向右转向避碰。
根据各目标船的RB和船舶类型,构建本船转向避碰的行动向量A7=[A1,A2,…,AN],AN为对第N个目标船的行动值。
行动值为1,是根据规则或良好船艺的要求;行动值为-1,是根据良好船艺确定的,旨在获取更好的避碰效果;行动值为0,说明按规则和良好船艺没有约束。多船避碰时,本船行动值的优先级按1>-1>0顺序,即:AT中如果出现1值,限定为右转避碰;否则,检测是否出现-1值,如果是,则限定为左转避碰;如果只出现0值,虽然表示左、右转向避碰均可,但考虑良好船艺和协调避碰,限定为右转避碰(海上常见)。
求解空间的限定:考虑规则中大幅度的转向避碰要求[11],如果根据AT限定为右转避碰,求解空间限定在[30,180];如果限定为左转避碰,则限定在[-180,-30]。
2.1 互见中的转向避碰行动矩阵
互见中,基于规则和良好船艺,参照互见中的局势(见图1),转向避碰行动需要考虑下列约束:
1) 追越:若目标船为被追越船A,左转、右转避碰均可;若目标船为追越船B,紧迫局面形成时,左转、右转避碰均可,考虑避碰的协调性,目标船很有可能右转,所以本船应左转避碰。
2) 对遇:本船和目标船C应各自右转避碰。
3) 交叉相遇:若目标船为直航船D,避让时应避免横越他船前方,应该向右转向避碰;若目标船为让路船E,紧迫局面形成时,本船可以行动,应避免横越他船前方,应该向右转向避碰。
4) 不同种类船舶会遇:由于不构成对遇或交叉相遇(非两艘机动船会遇),本船左转、右转避碰均可。如构成追越,则参照1)执行。
5) 良好船艺:对正横附近来船F,避免朝其转向更有助于避碰。
为研究问题方便,将PDV类型的目标船按照在转向行动上的要求不同划分为:PDV1(被追越机动船)和PDV2(非被追越机动船),PDV1的判定用目标船的航向CTS判定,即:CTS在[TB-67.5,TB+67.5]范围内(视觉可见目标艉灯光弧;(TB,True Bearing)),且两船距离越来越近。目标船RB在[67.5,292.5]时,CTS在[TB-67.5, TB+67.5]内,两船距离会越来越远,构不成追越,因此,在行动上不予考虑,其行动值取0。
基于上述约束,针对多船会遇,建立互见中的转向避碰行动矩阵(见表1)。
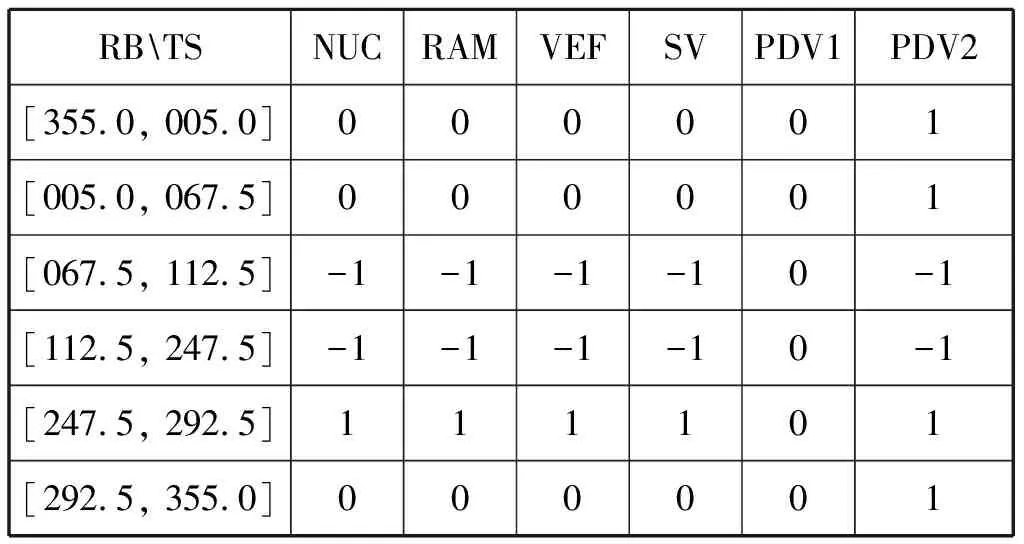
表1 互见中的转向避碰行动矩阵
2.2 不在互见中的转向避碰行动矩阵
能见度不良、不在互见中(规则19)存在碰撞危险时,任何船舶都负有同等避让责任,会遇局势见图2。规则19对转向避碰行动约束如下:
1) 除对被追越(指追越态势,下同)船舶A外,对正横前的船舶B和船舶C,避免向左转向。
2) 对正横船舶D或正横后船舶E,避免朝着它转向。
据此,研究将目标船的类型只划分为被追越船(Overtaken Vessel)和其他船(Other Vessel)两种。同理,目标船RB在[67.5,292.5]内,构不成追越,在行动上不予考虑,其行动值取0。
基于上述约束,针对多船会遇,建立不在互见中的转向避碰行动矩阵(见表2)。

表2 不在互见中的转向避碰行动矩阵
3 基于SEOA的转向避碰决策
3.1 算法的基本原理
SEOA模拟人类群体的社会行为,每个个体代表一个虚拟的人,每个个体X都希望得到较高的社会评价,并根据其情绪值选择下一步(进化)行为。对进化后的个体进行社会评价:若能得到较好的社会评价值,个体情绪值变高;若得到较差的社会评价值,则个体情绪值降低。情绪值决定下一代的进化行为,直到指定代数,获得社会评价最优的个体。
3.2 决策的目标函数
决策的目标函数即SEOA的社会评价。多船会遇,且存在碰撞危险,好的转向避碰决策应能使最小DCPA的目标船的DCPA值较大,且航程损失相对较小。为此,目标函数为
f(xj)=0.7f1(xj)+0.3f2(xj)
(2)
式(2)中:
(3)
f1(xj)为碰撞危险度函数;DCPAjr为第j个个体与第r个目标船的DCPA值;N为目标船的数目;目标函数值越小,碰撞危险度越小。
f2(xj)=
(4)
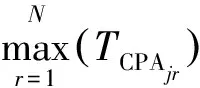
3.3 种群初始化
初始化种群数量:Npop为最大迭代代数:Maxiter,限定问题的求解空间[xmin,xmax],情绪值Ej(0)∈[0,1],初始代内情绪值均设为1,情绪值最大即个体情绪饱满,个体认为他们在初始代的行为是正确的,并选择下一步行为:
(5)
式(5)中:xj(0)为初始化阶段的个体j,其值即转向避碰的航向变化值;xj(1)为进化后第1代的个体j;k1为控制系数;rand1为服从均匀分布的随机数;xs(0)初始代中社会评价最差的L个个体。
3.4 个体进化
3.4.1计算个体的适应值
根据目标函数,计算个体的适应值,找出社会评价最差的L个个体xs(t);找出第j个个体进化至当前代的最优个体值xjbest(t)为
xjbest(t)=argmin{f(xj(h))|1≤h≤t}
(6)
找出进化至当前代的群最优个体xgbest(t)为
xgbest(t)=
argmin{f(xj(h))|1≤h≤t,1≤j≤Npop}
(7)
3.4.2计算个体的情绪值
第j个个体如果不能得到比之前各代更好的社会的评价值,情绪值下降为
Ej(t+1)=Ej(t)-Δ
(8)
式(8)中:Δ值取0.05[7],如果Ej(t+1)<0,则Ej(t+1)=0。
第j个个体如果能够得到比之前各代更好的社会评价值,情绪值大增,设Ej(t+1)=1。
3.4.3进化公式
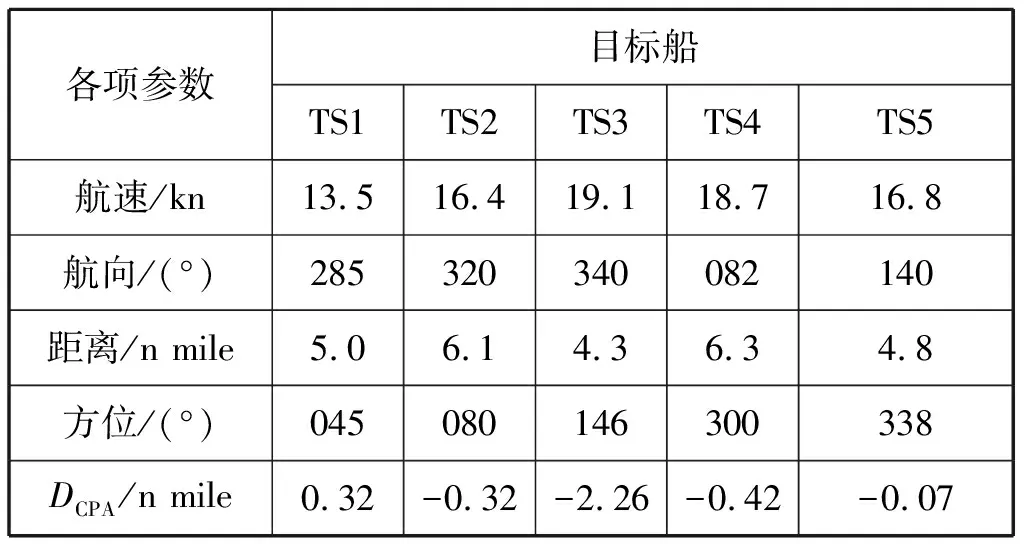
设定情绪值阈值m1、m2。如果Ej(t+1) xj(t+1)=xj(t)+k2·rand2·(xgbest(t)-xj(t)) (9) 如果m1≤Ej(t+1)≤m2,个体的情绪平和,个体学习时会对各种经验进行选择,既学习其他个体的成功经验,还考虑自身的经验进行学习,同时规避一些不好的经验。进化的方式为 xj(t+1)=xj(t)+k3·rand3·(xjbest(t)-xj(t))+ k2·rand2·(xgbest(t)-xj(t))- (10) 如果Ej(t+1)>m2,个体的情绪高昂,个体学习时更倾向于考虑自身的经验,同时规避不好的经验,进化的方式为 xj(t+1)=xj(t)+k3·rand3·(xjbest(t)-xj(t))- (11) 式(9)~式(11)中:k为控制系数;rand为服从均匀分布的随机数。 1) 初始化各参数:Npop、Maxiter、xmin、xmax、m1、m2、L、Ej。 2) 随机初始化种群。 3) 计算个体的适应值f(xj)(式(2)),选出最差L个个体值xs(t)。 4) 更新个体最优值xjbest(t)(式(6))。 5) 更新群体最优值xgbest(t)(式(7))。 6) 判定是否满足结束条件。若满足,输出最优个体值和最优个体适应值;否则,进入步骤7)。 7) 个体情绪值调节(式(8))。 8) 根据情绪值选择进化行为(式(5)。式(9)式(10)。式(11)),返回至步骤3)。 算法的流程见图3。 仿真实例中的种群数量Npop为30,最大迭代代数Maxiter设置为2 000,最差个体数L为10,为控制进化的步幅,控制系数K1为0.01,K2、K3为0.1。情绪值阈值m1为0.3,m2为0.7。 能见度不良,不在互见中。本船初始航向000,航速15 kn,同时会遇多艘船舶(TS1, TS2, …,TS5),存在碰撞危险,会遇局势见表3[12]。目标船过本艏部,DCPA为正值,过艉则为负值。 表3 能见度不良,不在互见中同各目标船的会遇局势 从图4可以判定:各目标船均不是被船追越(态势)的情况,依据行动矩阵如表2所示,可得行动向量AT=(1,1,-1,1,1),其中含1值,故向右转向避碰,问题的求解空间限定在[30,180]。 仿真结果见图5和图6。图5为各代最优个体值,即船舶转向避碰决策应转向的幅度。图6为各代最优个体的适应值。 仿真图示表明,最优个体值收敛于某一值,即转向避碰决策的解。为验证算法的可行性及有效性,执行算法30次,可得个体最优值的范围是[39.96,40.12],最优个体适应值范围是[0.434 6,0.434 7],最优个体值的均值是40.0,对应的适应值是0.434 7,即最佳转向避碰行动为右转40.0°。 能见度良好、互见中时,本船初始航向000°,航速14.3 kn,同时会遇5艘船舶(TS1(PDV),TS2(SF),TS3(VEF),TS4(PDV),TS5(RAM)),存在碰撞危险。会遇局势见表4。 表4 能见度良好,互见中同各目标船的会遇局势 TS1和TS4都是PDV,需要进一步划分类别。从见图7可看出,目标船TS1相对方位不在[67.5,292.5]内,且航向CTS1在[TB1-67.5,TB1+67.5]内,故TS1是PDV1。目标船TS4在相对方位[67.5,292.5],且航向CTS4不在[TB4-67.5,TB4+67.5]内,故TS4是PDV2。 依据行动矩阵如表1所示,可得行动向量AT=(0,0,-1,-1,0),不含1值,含-1值,故向左转向避碰,问题的求解空间限定在[-180,-30]。 仿真结果见图8和图9。图8为各代最优个体值,即船舶转向避碰决策应转向的幅度。图9为各代最优个体的适应值。执行算法30次,得个体最优值的范围是[-51.64,-51.29],最优个体适应值范围是[0.318 6,0.318 7],最优个体值的均值是-51.3,对应的适应值是0.318 6,即最佳转向避碰行动为左转51.3°。 仿真实例可看出,应用SEOA,500代内即能够收敛于某一固定值,收敛速度快,能够快速给出船舶转向避碰决策,且算法适用于“能见度不良不在互见中”和“互见中”两种情况。算法执行30次,最优个体值限定在某一范围,说明应用SEOA能够得到满意的一致最优解。 对上述两个获取的结果进行验证,实例1中,向右转向40.0°后,本船同各目标船的DCPA向量值为[2.16,1.38,-2.42,-1.63,-1.58]。实例2中,向左转向51.3°后,本船同各目标船的DCPA值向量为[4.48,-2.43,-4.05,-3.02,2.62],既满足规则中的大幅度避碰要求,又可确保安全驶过,且航程损失不大,结果满意。 1) 基于规则和良好船艺,按互见和不在互见中两种情况,对多船会遇局势进行划分,建立了转向避碰行动矩阵,通过目标船的相对方位和目标船的类型构建转向避碰行动量,限定问题的求解空间。 2) 提出一种基于SEOA的多船会遇转向避碰决策方法,应用SEOA全局快速寻优的能力,在限定的求解空间内,针对船舶碰撞危险度和航程损失的目标函数,获得最佳转向避碰决策,仿真结果满意。 3) 决策中的避碰行动矩阵和目标函数是关键,其中航程损失函数的系数可调,后续研究中可通过自学习方式调整。优化船舶复航决策,实现船舶点到点的避碰路径规划将是下一步的研究工作。3.5 算法的步骤
4 实例仿真分析
4.1 仿真实例1
4.2 仿真实例2

4.3 结果分析
5 结束语
