超平面距离的非平衡交互文本情感实例迁移方法
2018-10-15田锋王媛媛吴凡郑庆华
田锋,王媛媛,吴凡,郑庆华
(1.西安交通大学陕西省天地网技术重点实验室,710049,西安; 2.西安交通大学电子与信息工程学院,710049,西安)
交互文本是网络用户的重要交流方式之一,如QQ和微博。面向交互文本的情感分析技术在E-learning、舆情分析、人机对话等领域具有重意义。现实中,非平衡特性在交互文本中普遍存在,即一类情感类别的样本数远远大于其他情感类别的样本数,导致在其上训练的分类模型忽视少数类信息,产生过拟合问题。同时,网络上的交互文本更新速度快,用原始数据集构建的模型对新生数据的分类效果比较差,即形成分类模型泛化性能差的问题。如何提高非平衡情感分类模型的泛化分类性能是当前研究的难点之一。
在处理非平衡问题时,已有的很多方法都是在单一训练数据集上变化,近年来,迁移学习的概念被引入到非平衡分类中[1-2],此类方法基于目标数据集与源数据集实例间的相似度进行源数据集中迁移实例筛选,进而合成新的数据集并在其上训练出情感分类模型。从源数据集向目标数据集迁移高质量的实例极其重要,但是基于实例迁移的方法在解决非平衡问题时很少考虑泛化问题。
受SVM[3]方法中超平面构造的思路启发,本文提出一种基于实例同超平面距离的源数据集可迁移实例筛选算法,以解决如何有效地向目标数据集引入新信息的问题。在构造的合成数据集上训练出泛化性能优的分类模型,克服泛化性能弱的难点。
1 相关工作
在现实中非平衡问题广泛存在,目前解决非平衡分类问题主要采用从数据集层面上和算法层面上处理两类方法。数据集层面的方法通过改变训练集的规模与特征分布,降低不平衡度来提高分类性能,典型方法有Oversampling、Subsampling、SMOTE等;算法层面的方法有集成方法、代价敏感学习方法、特征选择方法和单类学习方法等[4]。然而,上述方法都是在单一训练数据集上进行构造,信息的更新度不够,在新数据集上分类性能差。
最近,因迁移学习[5]从一个或多个源数据集中提取知识,给训练数据集带来了新的信息,所以迁移学习应用于文本情感分类逐渐成为研究热点。按照被识别对象的粒度可分为句子级上、段落级上和文档级上的文本情感分类研究。
在句子级上,文本情感分类在社交网络中应用最为广泛[6]。Yong等提出基于word2vec情感词语义相似性的迁移方式[7];Wu等提出在迁移之前使用两阶段采样方式,根据共现特征和目标数据集特征筛选合适的数据[8];田锋等针对多领域类分布不均衡问题提出分领域实例选取与迁移方法,采用目标数据集单一实例最相似N个实例无差别迁移的策略[9]。
在段落级上,文本情感分类在商品、电影评论中应用广泛。Zhang等提出一种新的基于非负矩阵三因子分解的迁移学习,通过链接相似特征簇进行情感分类[10]。
在文档级上,Li等通过源领域的学习将文档类别信息迁移到词特征上,然后把情感分类信息通过词特征迁移到目标领域的文档[11];庄福振在此基础上将词特征改进为词特征聚类进行迁移学习[12]。
虽然上述迁移学习文本情感分类涉及了非平衡分类,改善了目标数据集的特征分布,但是没有考虑交互文本内容与情感随着时间而不断变化、不同时段内数据特征分布差异较大的现象,所训练模型并不能满足对未来数据的分类需求、仍易过拟合,并未缓解泛化问题。
针对此问题,本文拟结合SVM分类超平面特点引入新信息的效用理论来指导筛选高质量迁移实例,提升交互文本情感分类的泛化性能。
2 超平面距离实例迁移方法
2.1 超平面距离实例迁移方法的思想
心理学家威廉·麦克斯·华德特提出的信息效用理论反映了人们对于事物中所含信息的心理反应强度,这种新颖程度(新奇度)只有在一定的范围内才会对人和动物产生激励作用[13]。这种事物的新奇度与人们心理反应之间的关系可用一条倒U型的曲线来表示,即被认为心理学第一定律的Wundt曲线,如图1所示。本文将信息效用理论引入文本情感分类,利用文本的新奇度与最优信息效用筛选高质量迁移实例。本文假设文本的新奇度和最优信息效用是由源数据集蕴含的知识、目标数据集知识和分类超平面距离3个因素决定的。
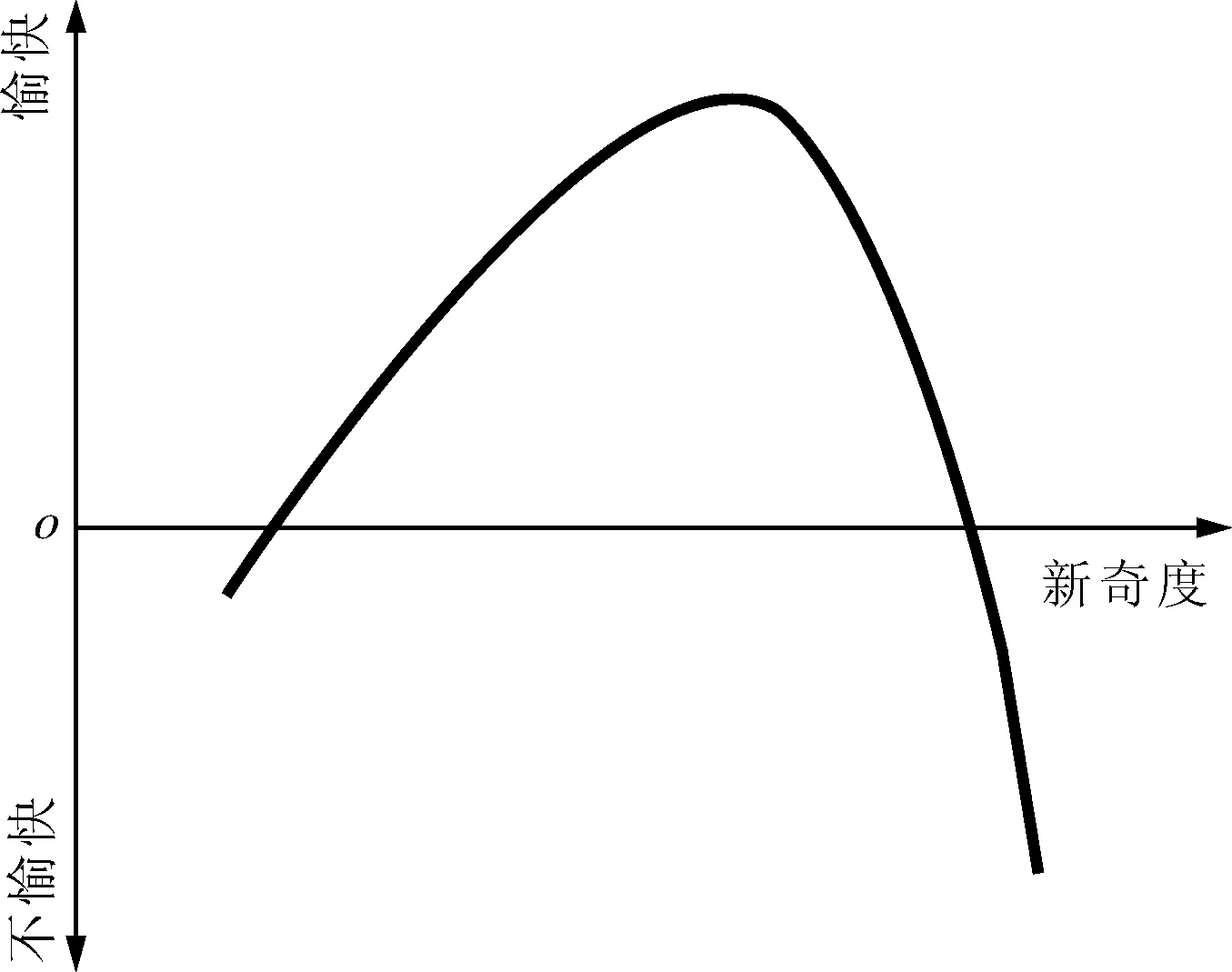
图1 Wundt曲线
由于交互文本特征维度高,使用分布之间的差异相加(如KL距离)来衡量源数据集中待迁移实例的新奇度不准。本文采用源数据集实例与分类超平面距离的远近作为新奇度的一个维度,即距离分类超平面越远的实例蕴含的旧信息越多,新奇度越低,无益于提升分类性能,向分类超平面附近添加适量的少数类,更有益于提升分类性能。
最优信息效用表示迁入多少源数据集实例时能够达到最佳分类性能。当迁移实例过多,引入过多新奇度低或噪声实例,将使数据集偏离原始分布太远,产生误导作用,使分类器分类性能下降。相反,加入适量新奇度高的实例,能明显提升分类性能。迁移实例比例是决定文本新奇度的另一个维度。
本文受SVM分类器超平面构造方法的启发,提出将位于少数类和多数类支持向量之间的源数据集实例作为待迁实例,并基于目标数据集上的分类超平面构造一个偏移超平面。基于待迁实例到偏移超平面的距离最短来筛选迁入的实例,同时采用迁入比例控制迁入实例规模生成合成数据集。该方法旨在通过向非平衡目标数据集加入与偏移超平面一定距离的源数据集实例,促使超平面向多数类实例方向偏移,减少错分的少数类实例个数。同时,源数据集实例的加入增加了目标数据集少数类信息,可缓解非平衡交互文本特征空间稀疏的问题,改变目标数据集的特征空间分布,提高目标数据集泛化分类性能。图2是基于实例与超平面距离的迁移实例筛选示意图。
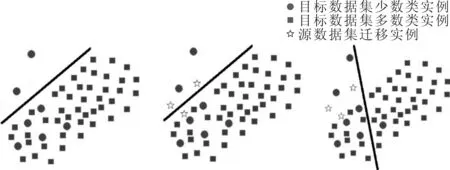
(a)原始数据集 (b)加入迁移实例 (c)新的合成数据集图2 基于超平面距离的迁移实例筛选示意图
2.2 超平面距离实例迁移方法描述
本文提出的迁移方法首先将目标数据集和源数据集实例合并提取特征,包括语法特征、统计特征、uni-gram和bi-gram词频特征(基于中文情感词汇本体构建词典),使源数据集实例可以直接迁移到目标数据集中,完成预处理;然后,使用基于超平面距离的迁移实例筛选算法在源数据集上筛选满足条件的实例加入目标数据集构成合成数据集。
基于实例与超平面距离的迁移实例筛选方法的核心是如何利用新奇度来迁移实例。本文中新奇度考虑实例与超平面的距离和迁入实例比例两个变量。由于加入位于超平面附近的实例对超平面的影响比较明显,故本文设置位于支持向量之间的实例为待迁实例。首先,将由目标数据训练得到的线性核SVM分类器命名为C,通过间隔最大化学习得到的分类超平面为
w*x+b*=0
(1)
相应的分类决策函数为
f(x)=sign(w*x+b*)
(2)
假设将支持向量与SVM分类超平面的距离视为1,多数类支持向量所在的超平面距离分类超平面的距离表示为1,少数类表示为-1。使用训练好的分类器C对源数据集中的实例进行类别预测,计算源数据集中每个实例(xi,yi)与从分类器C构造的偏移超平面的距离公式如下
di=w*xi+b*-β
(3)
式中:β是控制偏移超平面位置的距离阈值,取值集合为{-1,-0.5,0,0.5,1}。阈值取-1时选取的偏移超平面是少数类支持向量所在的超平面,阈值取1时选取的偏移超平面是多数类支持向量所在的超平面。
由于迁移实例个数在不同规模数据集上不同,本文以迁移实例占目标数据集少数类的比例为度量,记为迁入比例γ,根据迁入比例计算迁移实例数M。将计算出的源数据集中每个实例与偏移超平面的距离进行从小到大的排序,选择前M个实例加入目标数据集构成合成数据集。
3 基于超平面距离的实例迁移实验
3.1 实验数据集
本实验以二分类问题(正负面情感)为研究对象,采用的数据集为微博数据集、BBS论坛数据和QQ数据集。微博数据集来自新浪微博网友互动,BBS论坛数据来自某校内论坛用户互动,均是涵盖多种类型话题的交互短文本。QQ数据集来自腾讯QQ上某学习小组的交互短文本。
实验共两组数据集,第一组的目标数据集来自微博短文本,命名为weibo,共5 065条,非平衡比(少数类实例个数∶多数类实例个数)为1∶4,稀疏度约为1.697 4×10-4,记为Dweibo。源数据集来自BBS论坛数据中的3 137条负面情感实例,命名为BBS。第二组的目标数据集来自QQ数据集,命名为QQ,共4 778条,非平衡比为1∶4,稀疏度约为9.425 8×10-5,记为DQQ。源数据集来自微博数据集中学习主题的4 268条负面情感实例,命名为w_study。两组的测试数据集分别为和两个目标数据集不同时段的数据集,各为1 045条和959条实例。Syn_W数据集表示第一组实验中的weibo数据集和BBS数据集构成的合成数据集,非平衡比为1∶3.3,记为Dsyn_w。Syn_Q数据集表示QQ数据集和w_study数据集构成的合成数据集,非平衡比为1∶3.3,记为Dsyn_q。
3.2 实验步骤
合成数据集生成时,在迁移实例中为了确定最优信息效用,设置不同的参数执行实验实现对目标数据集引入新信息的比例控制策略。该策略首先采用目标数据集训练分类器,每次筛选一定比例的实例加入目标数据集形成合成数据集。在每个合成数据集上训练分类模型,比较不同迁入比例下的泛化分类性能,确定最优信息效用。设置方法中的一些参数为:迁入比例参数以10%为步长,从10%递增至300%,使数据集达到平衡。实例与超平面的距离d分别取-1.0,-0.5,0.0,0.5,1.0。
对比数据集及实验方法:使用SMOTE[14]、Subsampling[4]、Oversampling[4]方法分别生成的3类数据集,其非平衡比例均为1∶1,分别记为DSMOTE、DSub、DOver。在目标数据集以及各个合成数据集上使用SMO、LibSVM、RandomForest(RF)、代价敏感的SMO(Cost+SMO)、代价敏感的LibSVM(Cost+LibSVM)和代价敏感的RandomForest(Cost+RF)、CNN[15]共7种分类方法进行分类泛化性能测试实验。
3.3 性能评价指标与实验结果
本文选择加权受试者工作曲线下方的面积(加权ROC)、少数类(负面情感类)F值和多数类(正面情感类)F值为非平衡交互文本情感分类的评价指标。加权ROC准确反映了真正率和假正率之间的关系,设为R,是非平衡问题分类准确性的综合代表。F值是情感分类准确率和召回率的综合评价指标。
按如上步骤的实验结果如图3~4、表1~6所示。
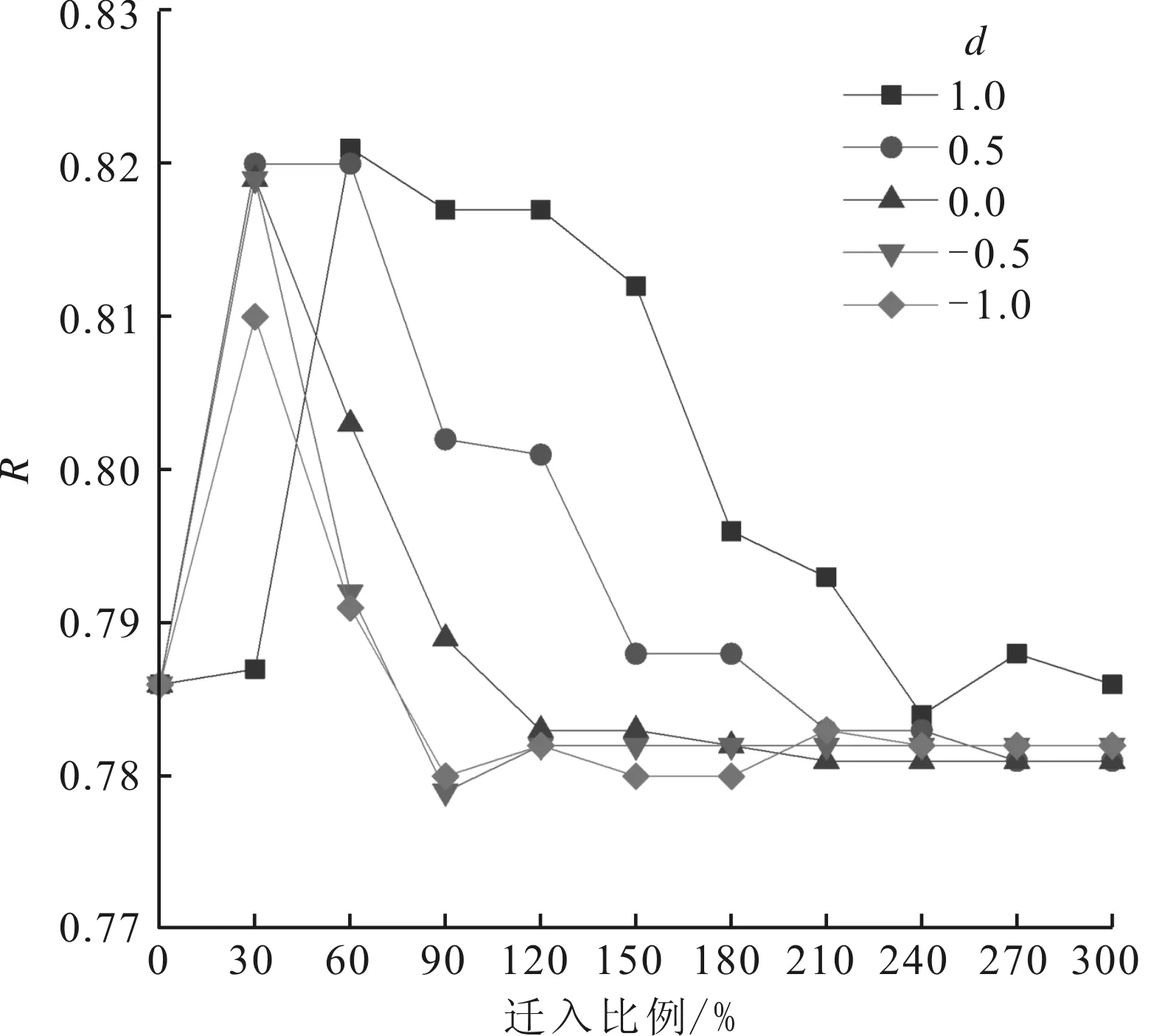
图3 不同距离参数下泛化分类性能R 随迁入比例的变化
图3是不同距离参数下随着迁入比例增加,Syn_W数据集在SMO分类方法下泛化分类性能加权ROC值的变化图。随着迁入比例越来越大,所训练分类模型的R呈现出先快速增长、后缓慢下降的现象。图3证实迁移文本带来的新信息在一定程度上才能对非平衡情感分类产生正面作用,比较符合信息效用理论。
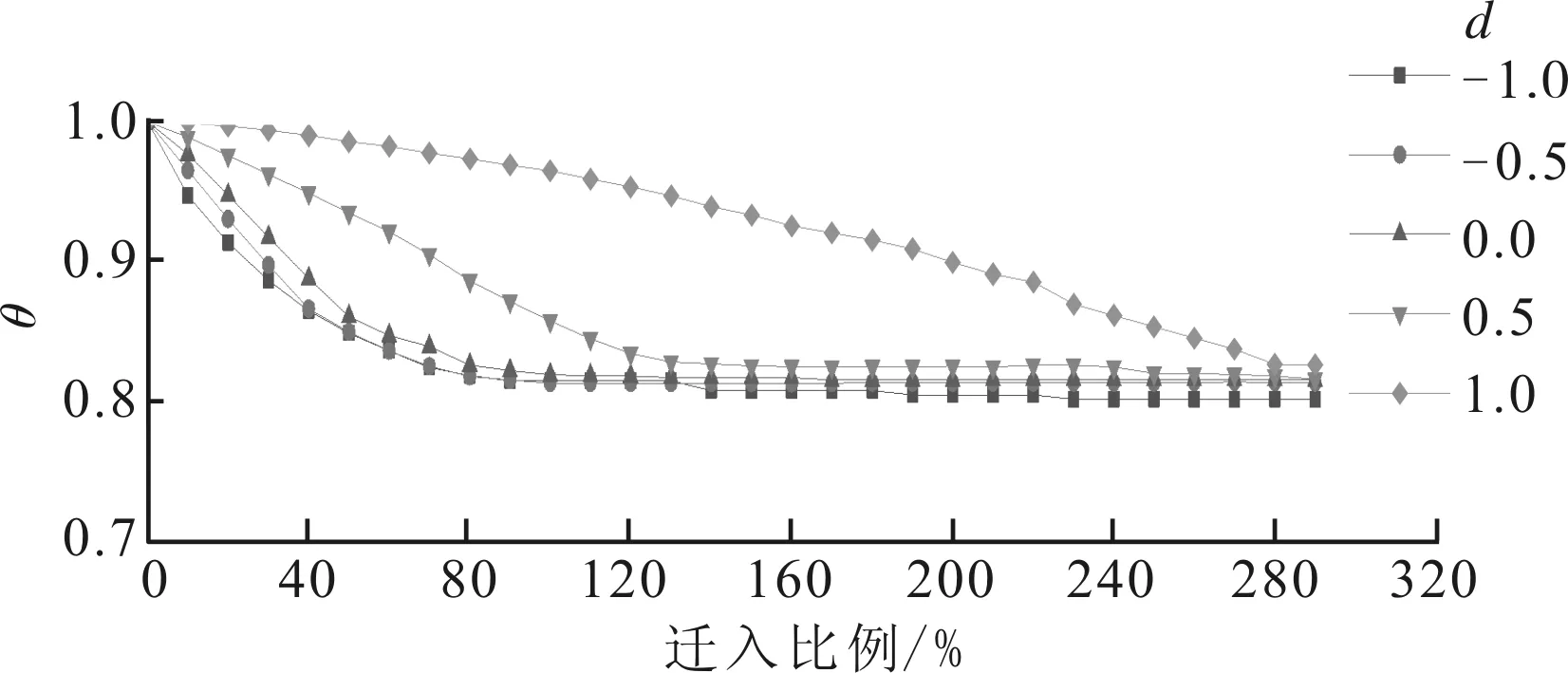
图4 不同距离参数下的分类超平面图
图4是在不同距离参数下随着迁入比例变化时的分类超平面图。采用余弦计算超平面法向量w与初始超平面法向量w0的夹角θ,用夹角的变化衡量超平面变化。由图4可以看出,当迁入比例达到一定值时,超平面均不再改变,形成稳定状态。该现象是由于源数据集中满足距离约束的迁移实例个数有限,即新奇度高的实例有限。迁入比例较小时,其恰好能全部迁移进入目标数据集,迁入比例过大时,新奇度低的实例对超平面的影响越来越小。
在weibo和QQ数据集上分别使用本文方法获得最佳合成数据集与使用SMOTE、Subsampling、Oversampling方法处理获得平衡数据集,5种分类模型进行泛化分类性能测试的R、少数类F值和多数类F值结果见表1~表6。由表1和表4的黑体数值可以看出,本文方法在代价敏感的RandomForest上的分类结果与对比方法中最好的SMOTE
+RandomForest方法相比,R有2%的微弱下降,但是由表2和表5的黑体数值可以看出,本文方法在少数类F值上均有显著上升,平均增幅为11%。在QQ数据集上,本文方法在代价敏感的RandomForest上与SMOTE方法对比,将少数类F值提升21%。由表3和表6的黑体数值可以看出,与目标数据集相比,在所有对照方法上多数类F值均有明显下降,但是本文方法中迁移实例使多数类F值略微下降,很少会出现微弱上升的现象,可能与新信息的引入使分离间隔更准确有关。由于训练数据集的规模不够大,同时存在非平衡问题,使用深度学习CNN方法进行分类并未表现出很好的泛化分类性能。从整体上来看,由于两个目标数据集特征稀疏度不同,在weibo数据集上使用SMOTE、Subsampling和Oversampling方法使数据集达到平衡后少数类F值出现下降的现象,这是将更多多数类错分为少数类导致的过拟合问题,而本文方法并未出现过拟合,分类结果较好。
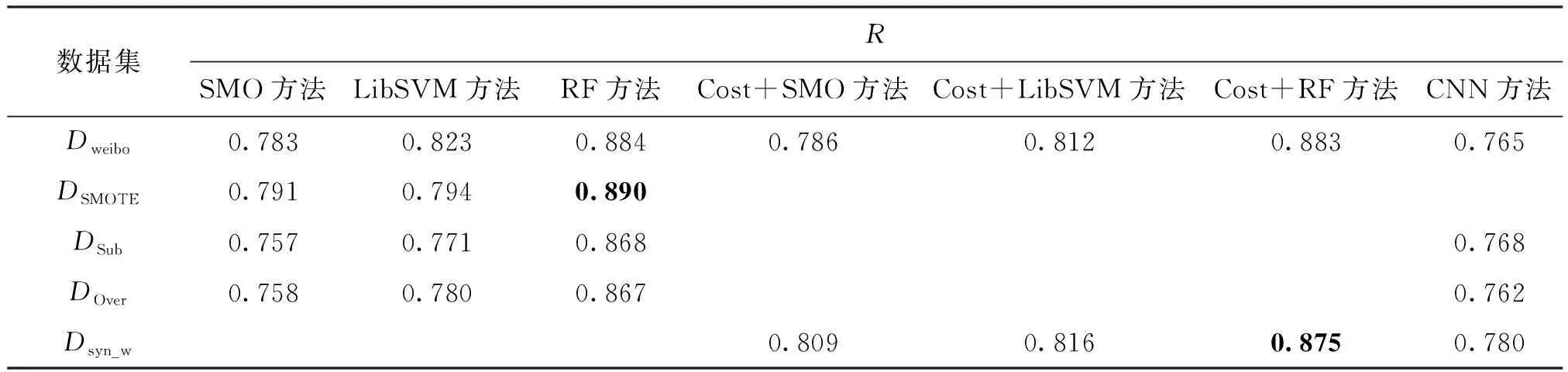
表1 weibo数据集上不同方法R的比较
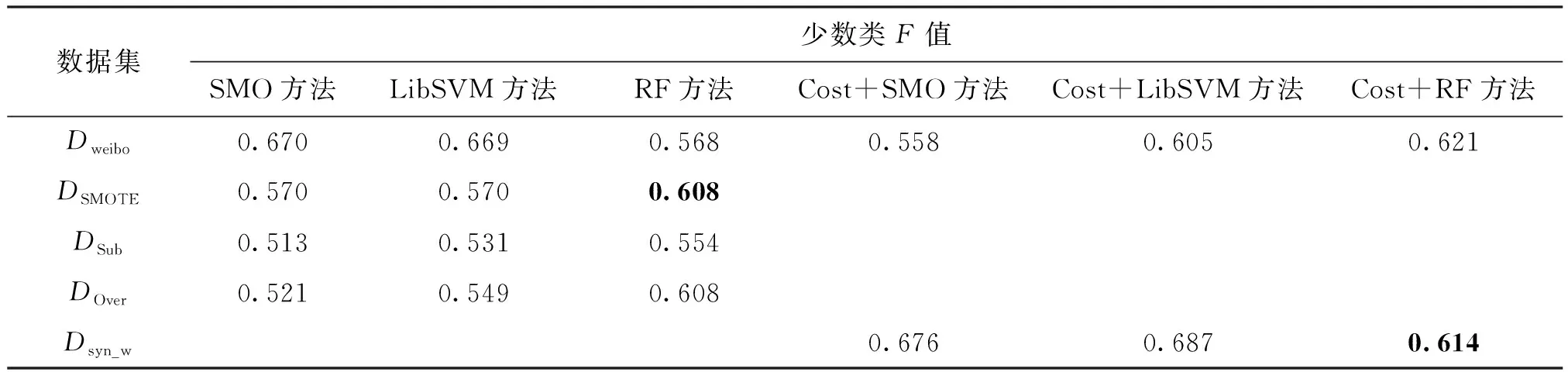
表2 weibo数据集上不同方法的少数类F值的比较
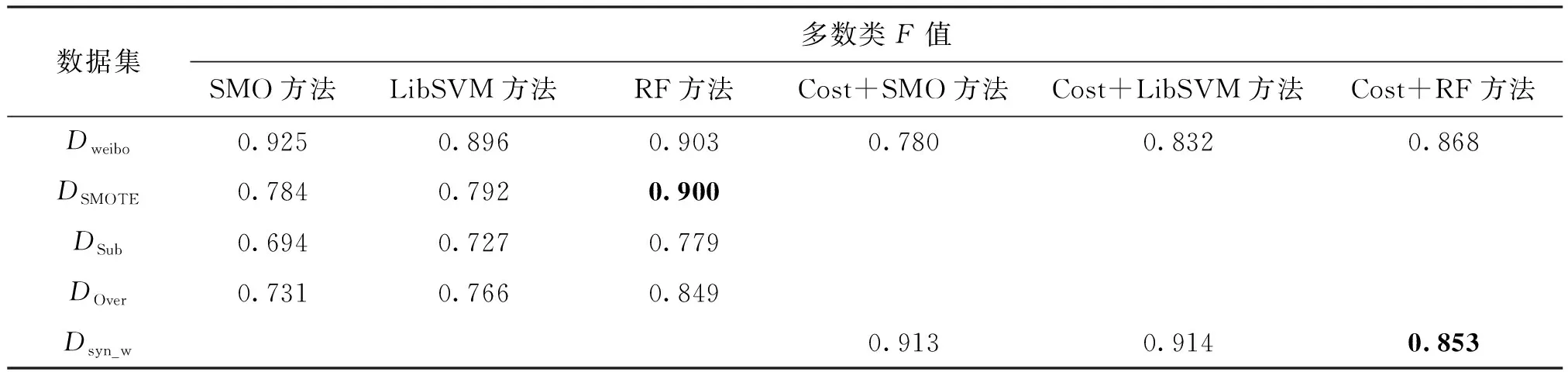
表3 weibo数据集上不同方法的多数类F值的比较
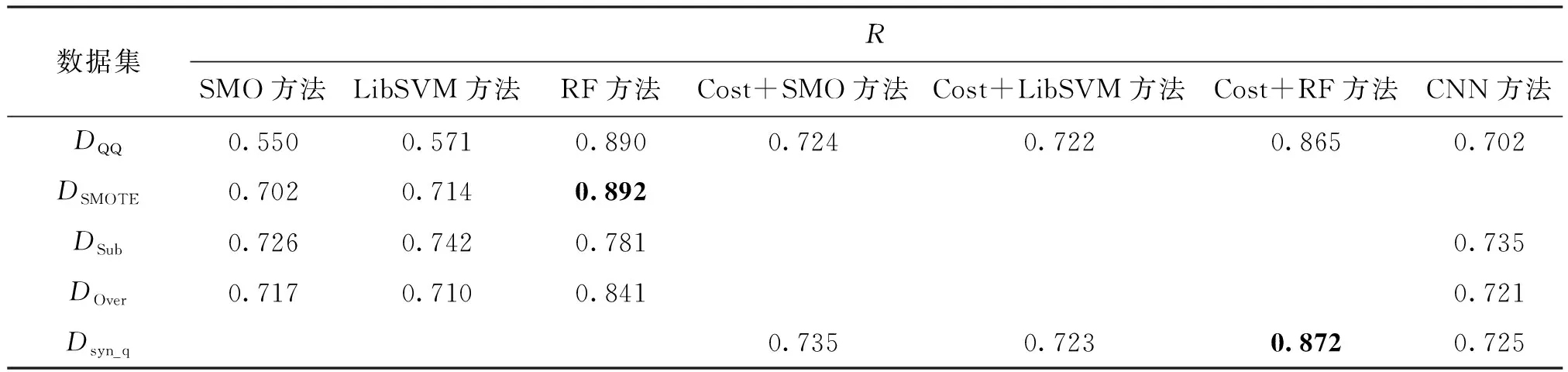
表4 QQ数据集不同方法R的比较
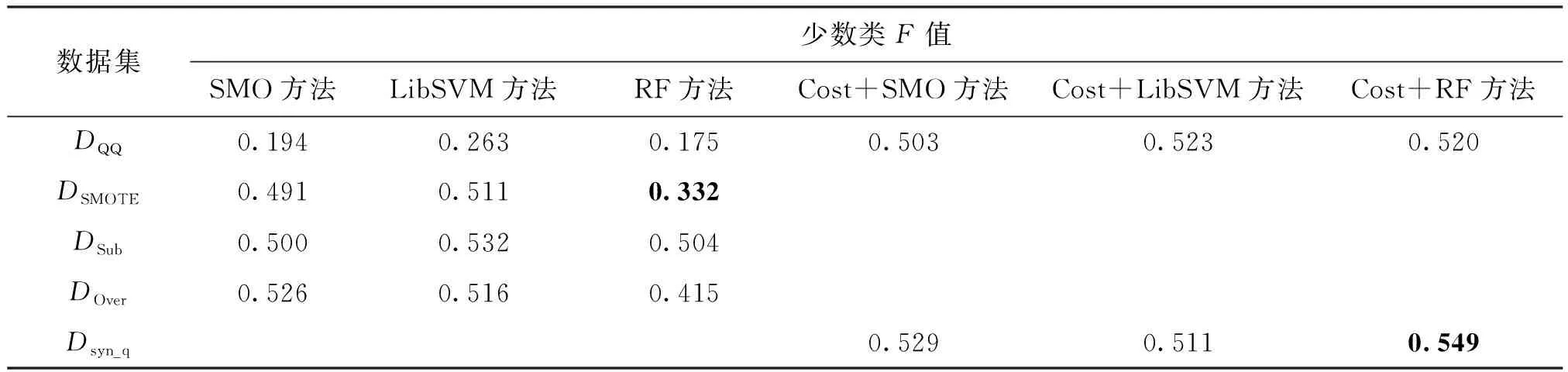
表5 QQ数据集不同方法的少数类F值的比较
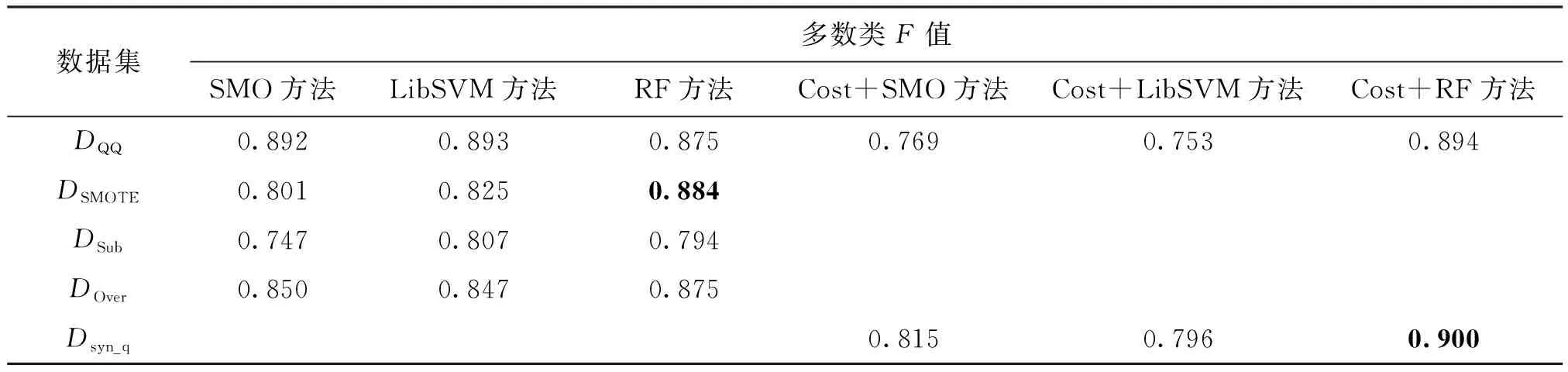
表6 QQ数据集不同方法的多数类F值的比较
根据上文信息效用理论中的新奇度和最优信息效用进行迁移,在非平衡比较小的数据集上,迁移位于非平衡超平面与少数类支持向量所在平面之间的实例,当迁入比例为20%~30%左右时,可获得泛化分类性能优的模型。
4 结 论
针对交互文本存在非平衡、特征维度高、特征值稀疏问题,导致高性能分类模型难构建,本文提出基于超平面距离的非平衡交互文本情感实例迁移方法。在信息的效用理论启发下,迁移富含新信息的少数类实例缓解非平衡特性,利用迁入比例控制策略改变特征分布、缓解特征值稀疏问题,获得了泛化分类性能优的模型。与Subsampling、Oversampling等基于目标数据集的采样方法不同,本文方法在一定程度上缓解了这些方法中存在的训练模型过拟合问题。通过两组大量的对比实验证明:与SMOTE、Subsampling、Oversampling 3种数据层处理方法和SMO、LibSVM、随机森林、代价敏感、CNN等分类方法相比,本文方法所训练的分类模型在加权ROC指标微弱降低的代价下,可获得少数类识别F值上的较大增幅。
本文的研究思路不仅适用于SVM分类,同样可用于其他分类方法,具有可拓展性。但是,本文仅用实验结果验证了理论方法的有效性和可信性,后续将结合随机矩阵理论,进一步探索该方法的机理,以及最优合成数据集的参数估计方法,并推广应用。
