语料库中的隐喻标注研究∗
2018-10-12柳超健王军曹灵美
柳超健 王军 曹灵美
(苏州大学,苏州215006/浙江传媒学院,杭州310018;苏州大学,苏州215006)
提 要:近年来,随着认知隐喻研究的“实证转向”与“社会转向”,学界开始不断关注语料库隐喻研究中的两个基本问题:在方法论层面,创新语料库中隐喻的检索与识别方法;在语义学层面,挖掘隐喻使用的触发机制与隐喻选择的影响因素。然而,当前研究尚缺乏或极少探究语料库中的隐喻标注问题。基于目前国内外自然语言处理中隐喻识别的相关研究和诸多具有代表性的隐喻语料库标注实践,本研究系统提出隐喻标注的原则与内容,并深入探讨其标注的模式与方法,以供国内外学者在认知隐喻研究与隐喻语料库建设中参考。
1 引言
隐喻标注作为隐喻语料库建设与研究的重要组成部分,大体上继承通用语料库中标注的特点与功能。然而,隐喻是人类对抽象概念进行推理的基本机制与认知手段,与其他语言形式相比,蕴含更多隐性或相对不突显的信息。由于隐喻语言本身及其概念结构的特殊性与复杂性,隐喻标注也必将呈现出诸多不同特性。若将Lakoff等收集的重要隐喻目录(Master Metaphor List)视为隐喻标注研究的起点,经过30多年的发展,它主要有以下特点:研究方法基本能够相互传承与借鉴;语料收集覆盖度高;重视隐喻概念的界定问题。但也存在以下问题:尚未形成科学、统一且易操作的隐喻识别程序及方法;标注内容随意、广度模糊、深度不足;标注模式差异显著,各自为阵。因此,有效解决上述问题对隐喻标注研究意义重大,同时也将对基于语料库的相关研究产生直接影响。鉴于此,本研究主要从标注原则、标注内容、标注模式与标注方法4个层面探讨语料库中的隐喻标注问题,以期为隐喻标注研究提供相关借鉴。
2 隐喻标注的原则
隐喻标注的原则是确保隐喻标注过程科学与规范的前提,并对隐喻研究的各个层面有重要的制约作用。本研究基于Leech(1993:275)在通用语料库中提出的标注原则,并结合目前国内外自然语言处理中隐喻识别的相关研究及诸多具有代表性的隐喻标注实践,系统提出隐喻标注的5个基本原则:强制性、选择性、准确性、一致性和折衷性。早期相关研究已对语料标注的外部信息和结构特征作过较为详实的论述(Leech 1993,1997;何婷婷2003;Sinclair 2007)。此外,从现代计算机科学的发展视角看,Leech在标注原则中提到的语料处理技术已不再是难点问题。因此,本研究提出的原则主要针对隐喻标注的内容,暂不探讨标注中如何利用计算机对隐喻语料进行数据保存等技术性问题。
(1)强制性原则。该原则主要针对隐喻标注的广度而言,即,隐喻标注必须涵盖4个基本要素(隐喻性词汇、源域、目标域和概念映射)。从理论上讲,隐喻标注至少可以从词汇、语法、语义、语用及语篇等层面进行。然而,语料的标注和语料的利用始终是一对矛盾体。从用户的角度来看,语料标注越详尽越好,而标注者则还须考虑标注的可行性。因此,任何标注模式都是在二者之间求得的一种妥协的产物(丁信善1998:8)。从目前国内外语料库隐喻标注的实践来看,多数研究在方法上虽能相互传承与借鉴,但在标注内容方面各自为阵,存在较大的随意性。此外,隐喻具有不同层次的抽象性(Ritchie 2003)。如果语料标注无法明确隐喻性词汇、源域、目标域以及相应的概念映射,隐喻的识解必将因时、因地、因人而产生较大的差异。若单论此,对隐喻的基本要素进行标注就显得尤为重要。
(2)选择性原则。隐喻语料库既可隶属能够代表某种语言全貌而建成的通用语料库,也可以是出于某种特定的研究目的而开发的专用语料库。显然,研究目的不同将导致两种类型的语料库在标注方面产生差异。基于此,在遵循强制性原则的基础上,可适当根据语料库的研究目的对隐喻语言进行不同层面的选择性标注,如表1所示。
(3)准确性原则。与隐喻的其他话题相比,学界对隐喻识别的关注步伐略晚,但它确属隐喻研究中一个常被忽略的问题。通过文献梳理,我们发现目前研究中对该话题并未达成概念上的统一。其中最根本的问题在于隐喻识别到底应该识别什么,是隐喻性词汇还是源域与目标域,又或是概念映射?是否应该严格区分隐喻在词汇层面和概念层面的识别?此外,概念隐喻理论强调隐喻的概念性本质特征,但Lakoff在其诸多论著中始终未谈及如何从纷繁的语言隐喻中构建或提取概念隐喻的方法或原则。这将直接导致各家在隐喻映射问题上观点迥异,众说纷纭。因此,隐喻标注不仅需要明确隐喻识别的概念,更要制定或选取一套清晰、科学且易操作的识别方法。
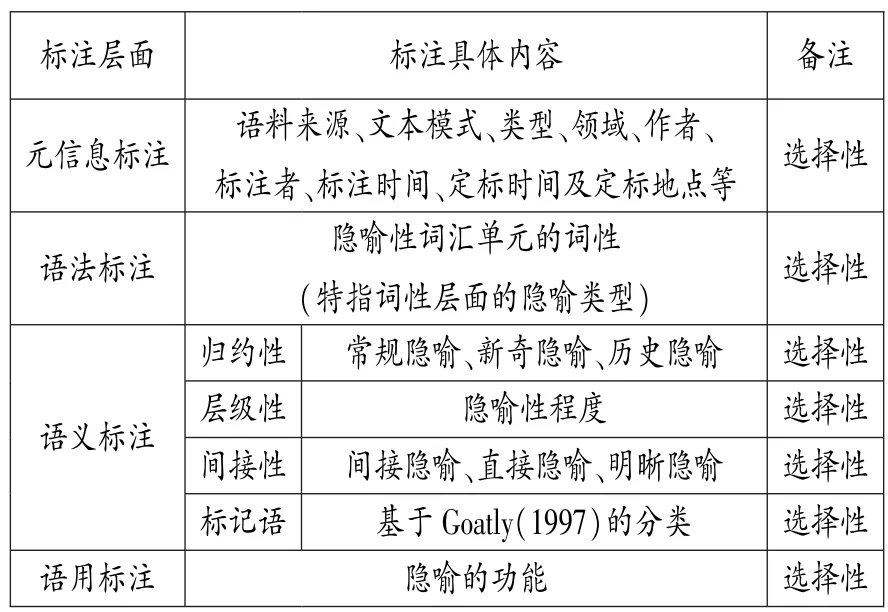
表1 隐喻的选择性标注内容
(4)一致性原则。在隐喻标注中,针对同一隐喻概念,不论是语义层面的隐喻规约性,还是语用层面的隐喻功能,标注者之间都应达到某种程度上的一致性。因此,在隐喻标注之前,不仅要严格制定标注者的选择标准,还要切实提出或选取一套科学、严密的隐喻标注模式和流程,尽可能缩减标注者之间的差异,从而确保隐喻标注的信度与效度。对于标注结果仍有疑虑的标注案例,必须通过小组讨论的方式加以解决。若存在无法解决的案例,也应明确告知用户标注的置信区间等相关信息。
(5)折衷性原则。 Leech(1993:275)认为语料库标注方案不具有真值性,不存在所谓的“标准”模式。因此,任何标注方案都不能作为第一或唯一标准。即使存在,也只能通过大量实践和比较才能得到。鉴于目前学界尚未制定标准、统一的通用语料标注赋码与规范,标注过程应注重实用性并最大限度地为语料库使用者提供便利。在增强语料使用灵活性的同时,还要尽量选用学界普遍接受的中立方案,这将有利于语料库的资源共享。当前,国内外隐喻语料库建设单位在选择语料标注赋码时也存在上述问题。因此,隐喻标注也应综合考察与研究各种标注方案,取长补短,并结合自身的研究目的,制定一种较为折衷的标注方案。
3 隐喻标注的模式
可扩展性标注语言(Extensible Markup Lan⁃guage,XML)是目前最常见的通用语言标注格式。与SGML等早期模式相比,XML不使用预设标签,也不注重文本格式的呈现,但更关注对数据结构的定义与描写。因此,用户可基于不同需求来定义不同领域内的标记语言。整体而言,XML可弥补HTML的缺陷与不足,具有更强大的文件传送与处理能力。可以说,XML的自身特点与隐喻标注的本质存在某种程度上的契合。本研究选取XML作为标注语言主要基于以下3项既定事实。
(1)XML遵循特定的语法规则,能够确保每个文档形式的完整性。比如,XML的基本结构是层级性的成对标签,即,每个元素必须包含起始标签(start tag)与结束标签(end tag),并注明属性及其数值。这种强制性的语法规则在很大程度上能够简化XML相关应用程序的开发,而不必参照DTD对文件结构进行确认。因此,XML可使隐喻语料更严谨,语料观察更直观,语料检索更方便,从而能够最大限度地确保隐喻标注的系统性和完整性。
(2)XML虽有严格的定义方法和规则集,但其文档建立在基本内嵌(nested)结构中某个核心集的基础之上。当语料库因为添加不同层级的信息而使原来的结构变得复杂时,这些基本结构就可代表复杂的信息集合,而不需要改变自身结构。从而,标注者需要为内部结构的复杂化程度付出的努力就更少。隐喻的核心内容是源域到目标域的跨域映射过程。在隐喻标注过程中,标注者完全可以标注隐喻的基本要素为基础,并依据不同程度的研究目的,选择性地进行层级标注。
(3)XML具有可扩展性。首先,除了XML模式中定义的数据类型之外,开发者可自行创建DTD,并应用于多种“可扩展”的标志集。其次,通过使用某些附加标准,可对XML的核心功能进行扩展。比如,增加样式、链接和参照能力。XML的扩展内容为其他可能产生的标准提供坚实的基础(李薇等1999:24)。不可否认,隐喻的识别、理解与生成是一个动态变化发展的过程,因此,在语料标注中能够表征其形式的语言格式也必然不是一成不变的。XML恰好为隐喻标注提供一个表征结构化信息的方式,并允许用户自定义任意标记形式,以满足或改变不同标注内容的需求。这就突破以往HTML只可描述文本格式的束缚,而且至少在数量方面极大提高隐喻标注的效率。
4 隐喻标注的方法
目前现有的语料标注方法主要包括人工标注、人工标注+机器辅助、机器标注+人工辅助以及机器全自动标注。从宏观上讲,隐喻标注可分为隐喻识别与隐喻标记两个过程。隐喻识别是隐喻标记的基础,其效度将直接影响隐喻标记的质量。因此,隐喻标注的本质是在隐喻识别的基础上,通过使用某种特定的符号代码对隐喻各个层面的信息进行加工、处理和记录的过程。本研究采用Pragglejaz Group(2007)提出的 MIP隐喻识别方法。从理论上讲,隐喻标注的两个过程可选取上述任意一种标注方法。然而,本研究倡导在隐喻识别阶段应采用“人工识别+机器辅助”,在隐喻标记阶段应以“机器标注+人工辅助”或机器全自动标注为宜。之所以采用这两种方法,主要有以下几个方面的考量:
(1)隐喻概念的特殊性及复杂性。尽管La⁃koff等学者的跨域映射论为隐喻的分析与阐释提供基本理论框架,但其心理真实性问题向来受到学界的质疑与挑战。因此,在自然语篇中,对隐喻的理解须采用多元化、跨学科的研究视角。比如,可选取语料库语言学的基本原理与方法来观察隐喻的共时与历时变化;可采用语篇分析法来挖掘隐喻语言的形式、结构与功能;可基于行为学方法来研究或验证人类心智对隐喻的认知表征。
(2)隐喻识别的方法论与技术性问题。语言隐喻与概念隐喻的关系通常极其复杂且两者易融合(conflated),但语言形式毕竟只是表层结构,终究无法完整地表征其概念系统(Steen 2007:175)。虽然语言隐喻的识别是概念隐喻构建的基础,然而研究过程中对两者的识别需要对应的方法论。从研究现状来看,现存的隐喻识别程序或集中于识别隐喻性词汇,或缺乏科学、系统且易操作的方法来指导隐喻在概念层面的识别,又或是对两者识别的关系问题含糊不清。这些问题在很大程度上将影响隐喻形式化与模型化的准确性与科学性,不利于隐喻自动识别的发展。此外,从目前隐喻自动识别研究的个案来看,在语料标注规模及标注对象方面依然受到限制,整体标注不具有代表性。
(3)隐喻标注的指向性问题。隐喻标注阶段并不涉及文本中的每个词汇单元或句子,这是由隐喻语料库的特殊性决定的。这就导致隐喻识别之后,必须借助人工手段对隐喻性词汇及相关涉及隐喻概念映射的句子(群)进行筛选、校对与补充。当然,这一阶段的任务可以通过开发相关计算机程序,并通过手工录入信息的方式来实现计算机的自动筛选。比如,张冬瑜等(2015)在归纳情感隐喻语料库理论框架的基础上,通过对词条信息进行多重人工检查及严格控制信息更新的方式,设计出情感隐喻的录入界面,极大提高隐喻标注的效率。由此可见,标注阶段采用机器录入的这种方案不仅是为了提高标注效率,减轻标注者的记忆负担,更重要的也是为了保证语料标注赋码上的一致性。
5 隐喻标注的内容
5.1 元信息标注
隐喻语料库的元信息标注主要是记录语料库中文本的非语言信息,包括外部信息(如语料来源、文本模式、类型、领域、作者、出版时间、标注阶段、首标时间、定标时间等)和文本的内部结构特征(如标题、段落、文献、伴随口语的副语言特征等)。这些信息通常置于文件头部,并通过某种特定的符号编码与文本建立关联。根据XML格式,将标注内容置于尖括号内,并注明属性及参数值。此外,每项标注内容必须包含独立的起始标签与结束标签。具体标注格式如下:
<annotator team =“...” name= “...”orgname=“...” > < /annotator> 分别表示“标注者起始标签、标注团队、标注者、标注者单位、标注者结束标签”。
<annodate initial_notated = “...” lastmod =“...” > < /annodate>分别表示“标注时间起始标签、首标时间、定标时间、标注时间结束标签”。
< corpus source = “...” discourse =“...” > < /corpus> 分别表示“语料起始标签、语料来源、类型、语料结束标签”。
以上标注内容是用户获取隐喻语料库基本信息的重要窗口。具体来讲,它可以帮助用户按照元信息标注参数检索出所需要类别的批量文本或对于整个研究最有某种显著意义的一些特定文本,也可以用来确定某些元文本参数之间准确的统计学数据,进而研究它们之间的相关性(陈虹2012:40)。当然,隐喻语料库开发者需要根据不同的研究目的或公开程度来合理选取相应的元信息进行标注。
5.2 语法标注
语法标注有时也被称为词类赋码或词性标注,是指对语料库文本中的每个词汇单元添加某种标签或记号来表明词性(Leech 1997:2)。这是一种最基本的语料标注方法,也是自然语言处理中相对比较成熟的一种自动标注技术。目前最常见的英语自动词性赋码软件有Claws,TreeTag⁃ger,Wmatrix等。隐喻语料库中的语法标注主要是针对隐喻性词汇而言的。因此,在标注之前,需要通过某种隐喻识别程序来获取语料库中的隐喻性词汇,然后通过计算机软件的自动标注技术对这些词汇进行词性标注,被标注的词汇单元将对应于不同的隐喻类型。具体标注格式如下:
<p>
<s n=“45”>Container<w NN>group Tiphook yesterday<w VBD>said it was still<w JJ>confident of<w VBG>winning its<w JJ>joint£ 643 million<w NN>bid for Sea Containers even though the<w NN>battle has<w VBN>swung<w IN>towards James Sherwood’s ferries⁃to⁃trailers combine.
<s n= “46” > ...
< /p >
以上文本的开头<p>表示段落的开始,</p>表示段落结束。 <s n=“45”>和<s n=“46”>分别表示文本中的句序。而尖括号内的字母组合代表该词的词性,即隐喻类型。比如,<w NN>表示group是一个普通名词,<w VBN>表示swung是动词的过去分词。因此,这两个词的隐喻类型分别归类为名词性隐喻与动词性隐喻。
5.3 语义标注
认知语言学通常将隐喻研究划入认知语义学研究的范畴。因此,语义标注无疑是隐喻语料库标注过程中的重要环节。通常情况下,隐喻的语义标注主要包含以下5个方面。
(1)基本元素
本研究利用英国兰卡斯特大学Paul Rayson开发的在线语义标注工具Wmatrix进行文本中的隐喻识别:程序步骤包括获取主题语义域、确定候选源域及源域词汇、识别隐喻形符、确定目标域与构建概念映射(柳超健 王军2017)。此外,在概念映射构建环节,本研究还引入目前主流的隐喻语料库 Master Metaphor List,ATT⁃Meta data bank,Metalude作为概念映射构建的主要参考依据。当然,如果在标注过程中无法在上述隐喻语料库中检索到相应的基本概念映射,标注者也可自定义额外的词汇范畴。具体标注格式如下:
<view>
<mapping>LIFE IS A JOURNEY</mapping>
<metuw>road</metuw>
<source domain>journey</source domain>
<target domain>life</target domain>
<source>MML</source>
<original literature>more than cool reason</original literature>
</view>
以上文本的开头<view>表示隐喻界定的开始,</view>表示隐喻界定的终止;<metuw><source domain><target domain><mapping>分别对应于隐喻的基本要素journey,journey,life和LIFE ISA JOURNEY;<original literature>表示该隐喻源于专著More than cool reason;<source>表示该概念映射的主要参考依据来源于隐喻语料库Metaphor Master List.
(2)归约性
正常情况下,在词汇单元产生隐喻意义时,人们无法有意识地感知其隐喻性,因为绝大多数隐喻表达式都是高度规约化的。然而,隐喻的归约性并非静止不变,它是一个程度上的问题。隐喻规约性差异将产生不同的隐喻类别,其中最常见的有常规隐喻、新奇隐喻和历史隐喻(etymological metaphor)。隐喻的规约性程度越高,识别难度也就越大。隐喻的归约性是语料库用户透视隐喻概念的一个重要视窗。具体标注格式如下:
<view>
<conventionality>conventional metaphor</conventionality>
<conventionality> novel metaphor< /conven⁃tionality>
<conventionality>etymological metaphor</conventionality>
</view>
(3)层级性
隐喻具有层级性(gradability),即,不同概念的隐喻性程度之间存在差异。通常情况下,源域和目标域所共享的语义特点越多,隐喻程度就越弱。比如,海洋绿洲的隐喻性要低于心智“绿洲”的隐喻性。语义回响值是衡量隐喻性程度的基本指数,可通过观察语料库中隐喻使用的实际情况来获取。当不相关的概念被引入、激活或响应语境中的隐性概念时,相应的语义回响值就会增大(Hanks 2006:31)。隐喻的层级性从本质上讲是隐喻性程度的体现。隐喻性程度越高,其显性程度越低。鉴于目前尚未有可定性的计算方法来界定隐喻性,本研究暂选用从-5到+5的数值区间进行量化。数值越大,隐喻性程度越高。隐喻性程度对于揭示隐喻使用者及隐喻接受者的认知行为具有重要意义。具体标注格式如下:
<view>
<metaphoricity>5</metaphoricity>
</view>
(4)间接性
隐喻概念的间接性(indirectness)及归约性与隐喻的功能存在某种程度的相关性,并且会影响隐喻接受者的心智模型(Krennmayr 2011:273)。因此,可基于概念的间接性对隐喻进行标注。隐喻概念的间接性在语言层面可分为间接隐喻、直接隐喻和明晰隐喻(explicit metaphor)。间接隐喻是概念隐喻中最具有原型意义的类别,即源域的概念结构(比如high wage)通过间接方式来表征目标域;直接隐喻无需借助间接概念进行概念转换与表征,最常见的形式为明喻(simile);明晰隐喻主要涉及隐喻的间接回指,即在概念结构中可重新获取所指概念的隐喻性(Steen et al 2010:33-40)。具体标注格式如下:
<view>
< indirectness > indirect metaphor < /indirect⁃ness>
< indirectness > direct metaphor < /indirect⁃ness>
< indirectness > explicit metaphor < /indirect⁃ness>
</view>
(5)标记语
某些隐喻的使用通常伴有明确的话语标记(marker)或调节语(tuning device)(Goatly 1997;Cameron,Deignan 2003),因此可将这类标记语作为隐喻识别的文本线索。该标注也是隐喻自动识别方法的重要组成部分。鉴于Goatly对隐喻话语标记语做过迄今为止最详尽的分类:包括显性标记语、强调词、弱化修饰词、元语言、拟态词等(Goatly 1997:172 -199),本研究主要基于上述分类标准,分别为每个类别的隐喻标记语进行从字母A到L的标注,并记录其序号和内容。具体标注格式如下:
<metsignal>
<metsignal N =“11” >
<signal>literally, something of< /signal>
<sigclass>A-L</sigclass>
< /metsignal>
5.4 语用标注
隐喻是人类认知世界的基本推理机制,其基本功能是能够让我们通过具体、简单、显性的经验结构来表征抽象、复杂、隐性的经验结构。然而,如果从语篇视角研究隐喻的功能,我们需要探讨交际中更具体的问题。比如,为什么某种特定的隐喻形式只出现于某类特定的文本或语篇中。这类问题通常与隐喻对现实的表征相关。具体来说,隐喻具有说服、理解、评价、解释、突显、掩盖、表达情感或信仰、理论化等功能。当然,在同种语篇中,也可能出现几种功能共现的情况。如果从语言交际的视角看,隐喻的功能则主要体现在隐喻使用的刻意性(deliberateness)方面,即,隐喻使用者是否刻意引导话语接受者通过某个事物来理解另一事物,或是隐喻话语接受者在经历刻意性的隐喻话语之后是否改变对当前话题的某些观点(Krennmayr 2011:152)。 具体标注格式如下:
<view>
<metfunction>persuasion</metfunction>
< communication > deliberate < /communica⁃tion>
</view>
6 结束语
隐喻标注在隐喻语料库建设与应用过程中具有重要意义,是当前语料库隐喻研究的重要课题之一。本研究在以往国内外大型隐喻语料库标注实践的基础上,深入探讨隐喻标注的相关重要问题。在理论指导方面,系统提出隐喻标注的基本原则;在标注语言方面,论证XML在隐喻标注中的优势及可行性;在标注方法方面,对隐喻标注的概念作出重新定义,并倡导“人工识别+机器辅助”与“机器标注+人工辅助”并用的理念;在标注覆盖度方面,对隐喻标注内容作出具体说明,并建议采用“基本标注+选择性标注”的方案。此外,语料库隐喻标注研究依旧任重道远,对概念隐喻理论中涉及基本隐喻等重要信息的自动提取、识别与标注,是重点,更是难点。
