一种基于多义词向量表示的词义消歧方法
2018-09-29李国佳赵莹地郭鸿奇
李国佳 赵莹地 郭鸿奇

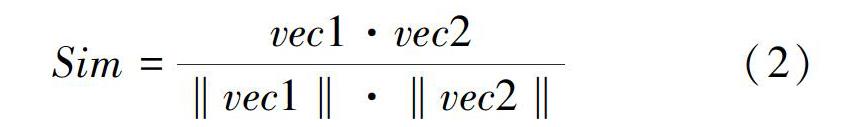
摘 要:词义消歧是自然语言处理领域的基本任务。在词语词向量表示的基础上,计算获得多义词语上下文窗口的向量表示。利用统计的多义词及词义个数,基于K-means算法聚类文本语料集中多义词的上下文窗口表示,在原始文本语料集中对多义词语根据聚类类别进行标记。在标记的文本语料集上,训练获得多义词语每个词义的向量表示。对句子中的多义词语,给出了一种基于多义词向量表示的词义消歧方法,实验结果显示该方法有效可行。
关键词:多义词向量表示; K-means; 词义消歧
Abstract: Word sense disambiguation is a basic task in natural language process. To the original text corpus, the vector representation of polysemous word context window is calculated based on vector representation. Using statistical polysemy and the numbers of word sense, the vector representation of polysemy context window is clustered based on K-means, and the polysemous words are marked in the original text corpus. On the marked text corpus, the vector representation of polysemy' word sense is trained by using neural network language model. A word sense disambiguation method based on polysemy vector representation is presented. The experimental results show that the method is effective and feasible.
Key words: polysemy vector representation; K-means; word sense disambiguation
引言
詞义消歧(Word Sense Disambiguation)在机器翻译、信息检索、主题分析和文本分类中具有广泛的应用。多义词语在不同上下文环境下对应的具体词义不同,对句子中的多义词语,通过词义消歧获得词语在上下文中特定语义,能提高词语表示的准确性。
词义消歧主要方法有2类,分别是:基于外部知识资源方法和基于语料库的方法。其中,基于外部知识资源方法,利用人工的字典或词典来获得词语语义间的关系,通过将这些关系量化后再进行词义消歧,准确率一般要高于基于语料库的方法,但构建字典、词典需要耗费大量的人力、物力。高雪霞等人使用外部词汇资源中同义词、上义词和下义词3个语义关系,利用Jaccard系数相似度量方法,来计算最佳词义[1]。基于语料库的方法,以语料库为知识资源,通过自动或半自动的学习确定词语在给定上下文下的具体词义,从而实现词义消歧,但语料库的规模和领域影响词义消歧的效果[2]。杨陟卓提出一种自动生成有标注语料的方法,采用机器翻译系统将训练实例的上下文进行翻译生成伪训练实例,同时采用训练实例和伪训练实例构建贝叶斯消歧模型实现词义消歧[3]。张春祥等人将歧义词汇左右邻接的4个词汇单元的多种语言学知识作为消歧特征,利用贝叶斯分类器和最大熵分类器确定歧义词汇的语义类别,结合大量无标注语料使用Co-Training算法提高词义消歧分类器的性能[4]。杨安等人利用无标注的原始语料构建词向量模型,结合特定领域关键词信息及WordNet资源,设计一套打分系统,选择得分最高所对应的词义作为词义消歧的结果[5]。
针对多义词语的表示问题,Reisinger 等人提出多原型向量空间模型,其中每个词语的上下文表示将聚类为簇,通过对聚类簇内词语所有的上下文向量表示进行平均生成词语不同的原型向量[6]。Huang等人基于神经网络语言模型,结合词语全局语义信息,利用K-means算法聚类每个词语的上下文表示,并在原始文本语料库中将每个词语的出现情况标记为其所关联的聚类类别,训练获得多义词语的词向量表示[7]。
本文利用原始文本语料集,训练得到词语的词向量表示,结合多义词词典统计获得多义词词义的个数,基于K-means聚类获得多义词语上下文窗口表示的聚类类别,在原始文本语料集中将多义词标记为不同类别,训练获得多义词各个词义的向量表示,进而给出了一种基于多义词向量表示的词义消歧方法,实验结果验证了该方法是有效可行的。
1 多义词语的向量表示
1.1 词语的向量化表示
在自然语言处理领域的各项任务中,词语是最小的处理单元。常用的词语表示方法是将词语处理为向量的形式。一般的词语表示是将每个词语表示为一个向量,向量的维数是词典的大小,这种形式称为词语的向量化表示。一种简单的词语向量化表示方法是One-hot Representation,将每个词语表示为一个长的向量,其中一个维度的值为1,表示当前词语,其它维度值为零。由于语言中词语数量及增长变化,容易造成计算上的维度灾难,并且这种表示对任意2个词表示是孤立的,无法体现词语之间的语义关系。
2003年,Bengio等人提出利用神经网络语言模型训练获得词语的向量化表示[8],也称为词嵌入(Word Embedding)或词向量(Word Representation)。通过对海量文本的训练学习,将词语表示为稠密连续的低维度向量,避免了传统词语表示的维数灾难和数据稀疏问题,也反映了词语语义之间的联系。在自然语言处理领域的多项任务中,具有较好的效果。
近年来,许多学者利用基于神经网络的语言模型来训练获得词语的向量化表示,基本思路是通过无监督方式在大规模的文本数据集上训练学习得到词语的词向量表示。
1.2 多义词向量表示
词语词向量表示(Word Embedding)将每一个词语对应唯一的向量表示。在实际语言现象中,一个词语在不同的上下文语境中可能具有多种语义的情况,也就是一词多义现象。词向量表示不能区分表示多义词语的不同词义,对于多义词语,不同的词义需要对应特定的向量表示,以获得更精确的词义表示。
多义词向量表示,对每个多义词的不同词义,都对应一个向量表示,能够区别表示不同词义。在词语词向量表示的基础上,利用外部知识库,根据多义词语在文本语料集中的上下文环境,使用聚类算法对上下文窗口表示聚类,将聚类结果标记到文本语料集中,在标记的文本语料集上训练获得多义词向量表示。
2 基于K-means聚类的多义词向量表示
2.1 多义词语的上下文表示
多义词语的上下文表示,一种简单的表示方法是基于多义词语的上下文窗口,利用窗口内的词语来表示,也可以融合多义词语所在句子或所在段落及文档的主题之间关联性,综合计算獲得多义词语的上下文表示。多义词语的上下文窗口,是指句子中与多义词语左右邻接的多个词语,窗口大小为邻接词语数量。
对句子中多义词语,上下文的窗口大小设为k,表示左右邻接词汇的数量。对于多义词语左、右邻接词语小于k的情况,分别获取左、右邻接的全部词语作为上下文窗口内的词语。
利用多义词语的上下文窗口,由窗口中词语的词向量进行综合计算获得多义词语的上下文表示,数学计算公式可表述为:
2.2 结合多义词词典的K-means聚类
K-means算法是常用的文本聚类算法之一,通过计算样本和目标类别之间的距离,使相似的样本归为同一类,不同类别之间的距离要尽可能大,类别内部的距离要尽可能小。K-means算法实现简单,适用范围较广,但需要事先确定聚类类别的数目,即K的大小。
一般来说,多义词语的具体词义由上下文语言环境体现,因此对多义词语的上下文进行聚类,能够获得不同词义的聚类簇。将聚类簇样本作为原始文本语料集,利用神经网络语言模型,可以训练获得多义词的向量表示。
在实际的语言环境中,不同多义词语包含的词义数目是有差异的。借助外部知识库,统计获得常用多义词语及词义个数作为多义词词典,以多义词词典中词义个数作为K-means聚类算法的初始K值,在此基础上,实现基于多义词词典的K-means聚类算法,研发得到的算法设计过程如下。
输入:文本语料集中多义词的上下文表示Cw[N](N表示样本总数),多义词及词义个数K。
输出:每个聚类簇中样本个数n[j],每个聚类簇中样本C[j]及聚类簇质心。
Step 1 随机选择K个样本点作为初始质心,记为Ct[j]。
Step 2 对每一个样本Cw[i],计算样本Cw[i]和每个质心Ct[j]之间的距离dis[j],将Cw[i]聚类到距离最近的质心Ct[j],形成K个聚类簇C[j][n[j]];重新计算每个簇的质心Ct[k]。
Step 3 重复执行Step 2,直到聚类簇质心不再发生变化或达到最大迭代次数。
2.3 多义词向量表示的训练过程
对文本语料集中的每个多义词语,基于K-means算法对多义词语在原始文本语料集中所有样本的上下文窗口表示进行聚类,得到K个聚类簇。在文本语料集中按照K个类别对多义词语做出标记,不同的聚类类别代表多义词语不同的词义。在标记的文本语料集上基于神经网络语言模型训练词语词向量,得到词语在不同上下文中表达不同词义的向量表示。多义词向量表示的训练过程可描述为:
Step 1 利用外部知识库构建多义词词典,统计多义词语及其词义的个数。
Step 2 获取词语在文本语料集中的上下文窗口表示。
Step 3 结合多义词词典基于K-means算法聚类多义词语的上下文窗口表示,得到词语上下文表示的聚类簇。
Step 4 按照聚类簇类别在文本语料集中进行标记,多义词语根据聚类类别标记为多个词义表示。
Step 5 在标记的文本语料集上利用神经网络语言模型训练获得多义词语的向量表示。
3 词义消歧
基于多义词语的向量表示,对语句中的多义词语,通过计算多义词语的上下文窗口表示和在文本语料集中对应的聚类簇质心间的相似度,来获得多义词语在上下文中特定词义的词向量表示,进行词义消歧。对这一内容可阐释分述如下。
3.1 相似度计算
多义词语上下文窗口表示和聚类簇质心间的相似度,使用2个向量的夹角余弦值来度量。具体计算公式可表示为:
其中,Sim表示多义词语上下文窗口表示和聚类簇质心点的相似度;vec1是多义词语上下文窗口的向量表示;vec2是多义词语聚类簇质心点的向量表示。
3.2 基于多义词向量表示的词义消歧
根据词语的语义由其上下文决定的思想,多义词语在上下文中特定语义,可以通过计算多义词语的上下文窗口表示和在文本语料集中对应的聚类簇质心间的相似度来获得,将最大相似度值所对应的词向量表示作为多义词语在上下文中特定语义的词向量表示,计算方法的数学公式可写作如下形式:
以句子中多义词语的词义消歧为例,利用词语的上下文信息,本文给出的词义消歧方法包含3个步骤,设计论述可详见如下。
Step 1 识别句子中多义的词语。
Step 2 计算多义词语的上下文窗口表示。
Step 3 计算句子中多义词语的上下文窗口表示和在文本语料集中对应的聚类簇质心间的相似度,将最大相似度值所对应的词向量表示作为多义词语在上下文中特定语义的词向量表示。
詞语的上下文窗口表示由2.1节的公式(1)计算得到。在公式(1)中,若wi也是多义词语,则vecwi为该词语在文本语料集中最常出现的语义所对应的词向量,最常出现的语义可以由文本语料集中该词语语义样本出现的次数来运算确定。
多义词语有2个及以上的词向量表示,不同的词义对应不同的向量表示,可以识别出句子中的多义词语。根据词语词义数量的多少,依照先少后多的顺序依次对多义词语进行消歧。
4 实验结果及分析
实验设计流程主要包含2部分:首先训练获得多义词的词向量表示,然后基于多义词向量表示进行词义消歧。
4.1 实验参数
训练获得多义词的词向量表示,原始文本语料集采用维基中文百科文本语料(文本大小约为1.9 GB)和搜狐新闻语料集(文本大小约为680 MB),实验用多义词词典根据现代汉语多义词词典,由人工统计部分常用多义词语及词义个数。采用Google的Word2Vec模型来进行词向量的训练,向量维度设为150(一般为100~300),训练模型使用CBOW,其它设置均选择默认。多义词语的上下文窗口大小设为3(一般为3~5),中文分词选用jieba分词工具。
基于多义词向量表示的词义消歧,测试数据集使用SemEval-2007国际语义测评任务中SemEval-2007 task5,该任务的测试集包含40个多义词语,分为名词和动词两大类,多义词语的上下文窗口大小为3。词语上下文窗口出现的未登录词不参与计算。
词义消歧的实验结果采用准确率来进行评价,计算公式即如式(4)所示:
由表1、表2中可以看出,名词性多义词语进行词义消歧的准确率要高于动词性多义词语。一般来说,在上下文环境中,名词的词义更加明确,也更加容易区分,训练得到的名词性多义词语的向量表示,更能较好地区别表示名词性多义词语的不同词义。
从整体上来看,单字的多义词消歧正确率一般低于双字的多义词,在多义词语向量表示的训练过程中,需要对语料集文本进行分词,分词的粒度和准确性会影响分词的效果,而对于单字的多义词来说,分词后的样本较少,训练得到的单字多义词的向量表示不能做到准确区分表示词义,例如动词“出”,习惯用法是与其它词语组合,共同作为一个词语来加以使用。
整体词义消歧的平均准确率为52%,由于语料库规模的限制,影响多义词上下文窗口表示的聚类效果,降低了训练获得的多义词向量表示的准确性。受限于语言学的知识,人工编制的多义词词典,未能收录全部的多义词,多义词词义的个数的统计也存在误差,因而也在一定程度上降低了多义词上下文窗口表示的聚类效果及标记准确性。
5 结束语
针对多义词词义消歧的问题,利用人工构建的多义词词典,在K-means聚类多义词语上下文窗口表示的基础上,训练获得多义词语的向量表示,给出了一种基于多义词向量表示的词义消歧方法,对句子中的多义词语进行词义消歧。实验结果表明,词义消歧方法具备良好实效及操作可行性。后续工作中,亟待进一步研究的问题主要有:多义词词典的持续完善,语料库的规模和质量影响多义词向量表示的精度,词义消歧的准确性也依赖中文分词的粒度和准确性以及词语上下文窗口的表示方法。
参考文献
[1] 高雪霞,炎士涛. 基于WordNet词义消歧的语义检索研究[J]. 湘潭大学自然科学学报,2017, 39(2):118-121.
[2] 郭鸿奇,李国佳. 一种基于词语多原型向量表示的句子相似度计算方法[J]. 智能计算机与应用,2018,8(2):38-42.
[3] 杨陟卓. 基于上下文翻译的有监督词义消歧研究[J]. 计算机科学,2017,44(4):252-255,280.
[4] 张春祥,徐志峰,高雪瑶. 一种半监督的汉语词义消歧方法[J]. 西南交通大学学报,2018,3(2): http://kns.cnki.net/kcms/detail/51.1277.U.20180306.1913.006.html.
[5] 杨安,李素建,李芸. 基于领域知识和词向量的词义消歧方法[J]. 北京大学学报(自然科学版),2017,53(2):204-210.
[6] REISINGER J, MOONEY R J. Multi-prototype vector-space models of word meaning [C] // Proceedings of the 11th Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-2010). Los Angeles: ACL, 2010:109-117.
[7] HUANG E H, SOCHER R, MANNING C D, et al. Improving word representations via global context and multiple word prototypes [C] //Meeting of the Association for Computational Linguistics. Korea Jeju Island:ACM,2012:873-882.
[8] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J] . Journal of Machine Learning Research, 2003, 3 (6): 1137-1155.
