基于改进蚁群算法的聚类分析方法研究∗
2018-09-28武书舟闫丽娜张秋艳申晓留
武书舟 闫丽娜 张秋艳 申晓留
(华北电力大学控制与计算机工程学院 北京 102206)
1 引言
随着大数据广泛应用,数据聚类分析技术已经成为大数据领域研究的一个重要课题,比如在图像处理、客户信息分析、金融分析以及医学领域等方面都得到充分应用。聚类的本质是在数据样本类型完全不知道的情况下,将相似度较高的数据对象归为一类,每个聚类中心代表相应类型,整个聚类过程为无监督学习[1]。
蚁群算法属于智能优化算法的一种,由Marco Dorigo博士根据蚂蚁在寻找食物过程中发现路径问题提出来的,通过实验发现蚂蚁可通过一种信息素的化学物质标记所走过的路径,进而找到食源到蚁穴的最短距离。随着对蚁群算法理论深入研究,该算法的分布式计算、信息正反馈及启发式搜索等特征,充分的在组合优化问题、旅行商问题、背包问题、车辆调度问题和二次分配问题等实际应用中得以体现[3~17]。随后学者根据蚁群堆积尸体及分工行为,提出了蚁群聚类算法,随着理论的不断成熟发展已成功运用于电路设计、文本挖掘等方面。遗传算法在1975年由John Holland教授在达尔文生物进化论及孟德尔遗传变异理论基础上提出,成为新一代仿生算法[6~18]。随着对该算法原理深入研究,不断在组合优化、机器学习、智能控制及模式识别等领域得以应用[7]。
尽管蚁群算法和遗传算法已被应用到许多领域,但各自算法本身存在缺陷。蚁群算法初期信息素匮乏,求解速度慢,容易陷入局部最优解困境;遗传算法不能够充分利用系统中反馈信息,容易做大量无用冗余迭代,精确效率低[8]。本文为解决蚁群算法在聚类过程中搜索速度慢、易于陷入局部最优解情况,同遗传算法变异因子相结合,将两者算法优缺点进行互补,通过实验证明基于遗传算法改进的蚁群算法在聚类过程中在一定程度上解决了算法在聚类过程收敛速度慢和易于陷入局部最优解的问题。
2 基本蚁群算法原理
2.1 蚁群算法基本原理
蚂蚁依靠嗅觉来判断物体方位,蚂蚁可以凭借同类物种在周围环境中散发的信息素来寻找食物,蚂蚁在寻食过程是在没有先验基础上进行的,但蚂蚁仍够找到食源与蚁穴之间的最佳路径。通过大量实验发现,蚂蚁能够感知散发出的信息素及强度,会倾向信息素浓度高的路径移动,这样在蚂蚁移动过程中不断加强原有路径上信息素的浓度,导致蚂蚁在后续路径选择上有较大的概率选择信息素浓度高的路径[9]。在相同时间段内较短的路径会被更多的蚂蚁访问,因此蚂蚁在选择路径上更倾向于较短的路径,经过长时间的路径选择蚂蚁便会找到一条食源与蚁穴之间的最短路径。
蚂蚁凭借散发在路径上的信息素能够找到食源与蚁穴之间最短的路径,但是该条路径不一定是最短路径。蚁群算法不仅具有寻食行为,而且有蚁穴清理行为。该行为可以应用在数据挖掘聚类中,蚂蚁在蚁穴清理过程中,将蚂蚁尸体看成等待分析的数据集合,最终将尸体堆积为几大堆,堆积的尸体对应的最终聚类结果。蚁群聚类算法最早是在1991年J.L.Deneubourg提出的,同时将该方法应用到数据分析领域[10]。蚁群聚类算法的基本机制是蚁堆对工蚁搬运死蚂蚁具有吸引力,同时蚁堆规模大小决定对工蚁的吸引力大小,若蚁堆越大,吸引力就越大,促使蚁堆越来越大,此过程属于正反馈过程,由此机制可以看聚类结果受到数据空间分布状态的影响。
2.2 蚁群聚类算法模型—基于蚂蚁搬运尸体行为
假设所要聚类的数据对象随机的分布在二维且比例可以伸缩的网络空间中,每个网格中含有一个对象,人工蚂蚁沿着网格单元移动,没有移动数据的蚂蚁遇到数据对象时可以根据某种概率大小来搬运此数据;携带者数据对象的蚂蚁当遇到空单元或者搬运数据对象与邻近网格中的数据对象相似时,蚂蚁会根据相应的概率将数据对象放下,其放下的数据对象概率根据周围对象类型密度来判断,若是密度大就将数据放下,反之亦然,因此具有相同类型的数据对象就会聚集起来[12]。
假设二维网格中的数据对象σi和σj之间的距离(相似度)d(σi,σj)用欧式距离表示,若两个数据对象相似即 d(σi,σj)=0 ,反之 d(σi,σj)=1,通过相似性计算可以得出一个二维的相似度矩阵。若多个蚂蚁在此二维网格中不断重复数据对象拾起和放下操作,在某时刻蚂蚁在r位置上发现数据对象σi后,其局部密度可以由公式表示为
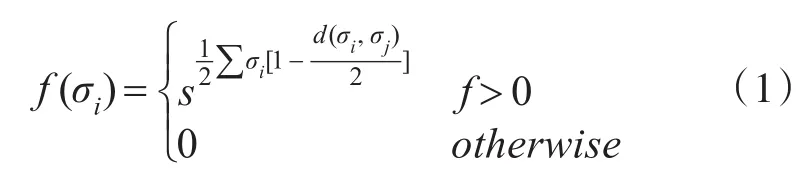
其中 f(σi)为相似度密度,σj∈Grid(s×s)(r),单元 r的邻域面积为s×s,其中蚂蚁在运动过程中拾起数据对象的概率 Pp(σi)和放下对象的概率 Pd(σi)表示,其中公式如下:
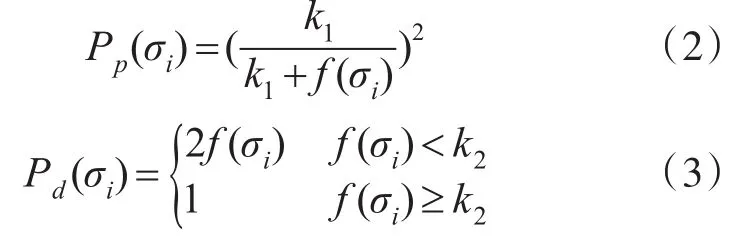
其中k1和k2都是阈值常数。该方法基于二维网格基础进行聚类,当对高维数据进行聚类时,可以通过降维的方式将数据对象映射到相对较小的维度空间内,然后再进行聚类,注意网格精确度将会影响聚类效果。
数据对象被拾起和放下规则是:在网格中的随机数据对象与其计算所得的拾起和放下可能性值大小进行比较,若随机数较小则人工蚂蚁执行拾起和放下操作,两个动作受局部相似密度 f(σi)的影响,若是相似度大,拾起的概率Pp(σi)小,即该数据对象就归于此簇,同时放下的概率Pd(σi)大,数据对象应属于该簇,反之亦然。
2.3 蚁群算法存在缺陷
基于蚂蚁堆形成原理实现的聚类算法不必预先指定簇的数目,并能构造局部任意形状的簇。通过散发信息素可以强化路径。但该算法仍然存在一定的缺陷,人工蚂蚁随机地拾起、移动和放下数据对象,所以在聚类过程中算法收敛速度较慢;尽管正反馈机制可以找到性能较好的解,但是容易出现停滞现象[15]。
3 改进蚁群算法
3.1 基于遗传算法的蚁群聚类算法原理
在本文中主要解决一般蚁群算法在聚类过程中存在的缺陷,其解决方法是在每次迭代搜索后,将当前解和最优解进行交叉变异,这样扩大了解的搜索空间,提高了搜索速度,同时避免了陷入局部最优解的现象。
3.2 具体算法实现过程
改进的蚁群聚类算法是将基本蚁群算法同遗传算法中的变异因子相结合,在蚁群算法在迭代过程中产生遗传算法所需的初始种群数据,提高了数据的多样性:
程序中参数的初始化;
程序在聚类的过程中需要迭代的次数t_max=1000;
将m只蚂蚁随机置于n个城市中;
初始状况下信息素矩阵(样本数*聚类数);最佳路径度量值,初始值设置为无穷大,该值越小聚类效果越好;
对于每只蚂蚁,按照转移概率选择下一个城市,并切修改路径信息,即路径上的信息素;
通过路径标示符求解出每一类的聚类中心,计算出各样本到聚类中心的偏离误差;
根据偏离误差的大小F,找到最佳路径;
接下来引入遗传算法的变异率,对找到的最佳路径进行变异,典型的操作如以下代码:


通过对最佳路径进行变异后,重新计算各个样本到其对应的聚类中心的偏移误差F_temp,然后通过比较两次计算的偏移误差,来确定此时的最佳路径。若是F_temp<F,则F=F_temp,然后比较F与F_min的大小,进行信息素的更改;相反则不进行F=F_temp操作。
当程序达到最大迭代次数时,聚类完成。
改进蚁群算法实现的流程如图1所示。
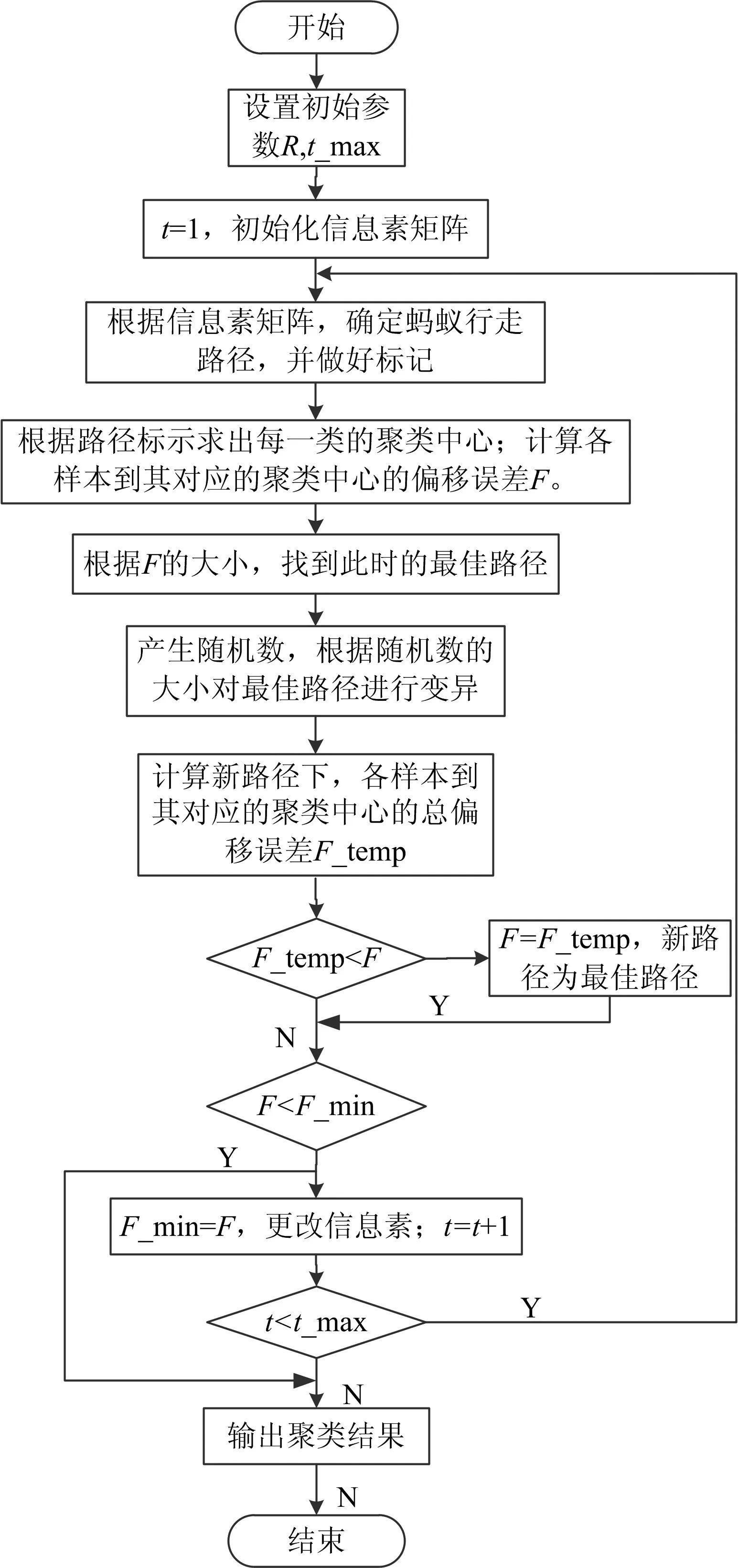
图1 改进蚁群算法流程图
4 实验对比
在实验过程中,首先设定出50个待聚类的数据对象为聚类样本,在Matlab软件中通过控制参数的方法来验证改进的蚁群聚类算法如何在基本蚁群算法基础上提高性能的。通过设定参数,将两种算法聚类结果进行对比可以发现,以当前样本为例,聚类最短所用时间为320s左右。其实验对比过程如下。
基本蚁群算法与G蚁群算法中的参数设置如以下表格所示。
4.1 一般蚁群算法实验参数设置
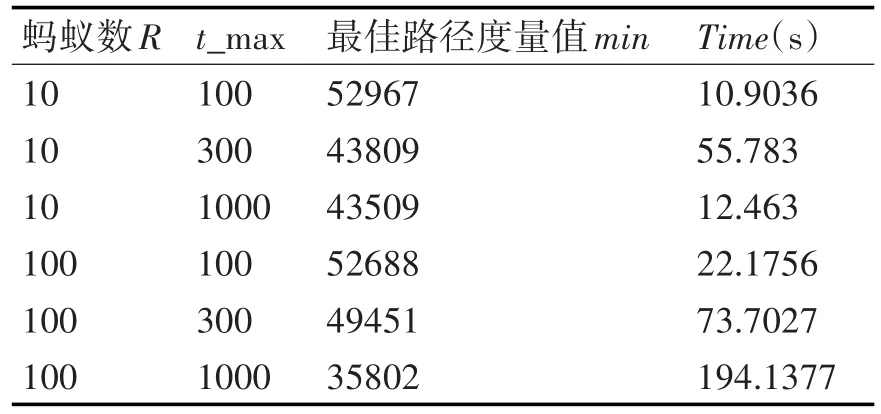
表1 蚁群算法参数设置表
在一般蚁群聚类过程中,以控制变量方式进行实验对比,发现当 R=100时,迭代次数为t_max=1000,min=35802,此时聚类用时Time=194.1377s。图2为聚类效果图。
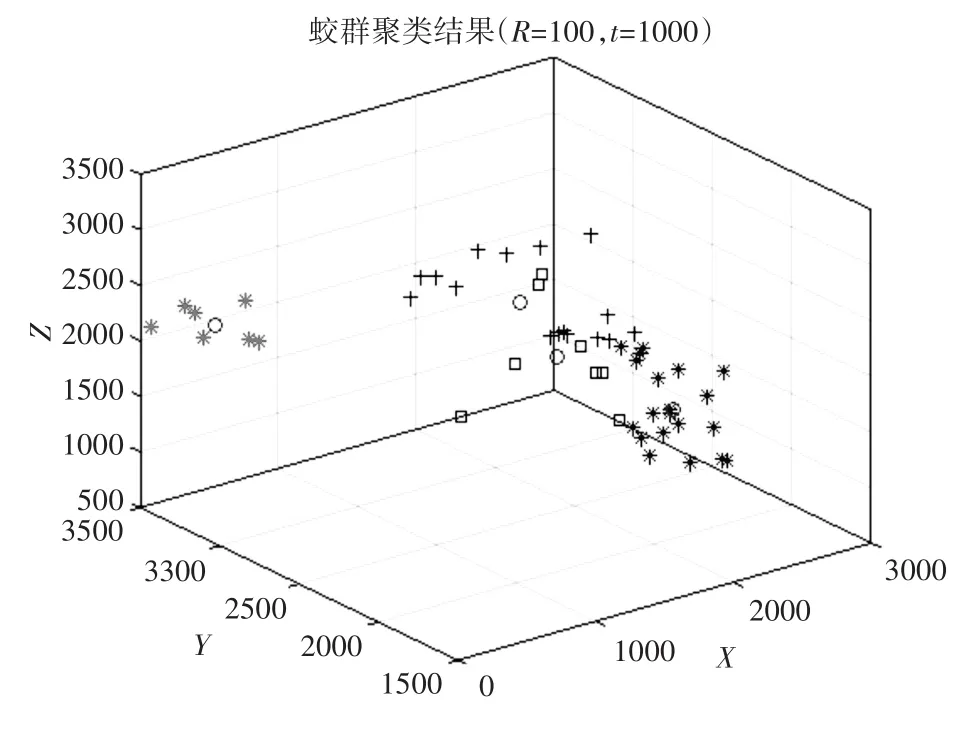
图2 聚类效果图
为达到更为理想的聚类效果,逐渐增加迭代次数,经过多次实验证明,当迭代次数增加到4000和5000时,min最短距离在19726左右浮动,聚类结果基本保持不变,此时的聚类时间Time=151.7225s,此时的聚类效果可以看成为最优聚类效果。最优聚类效果如图3所示:
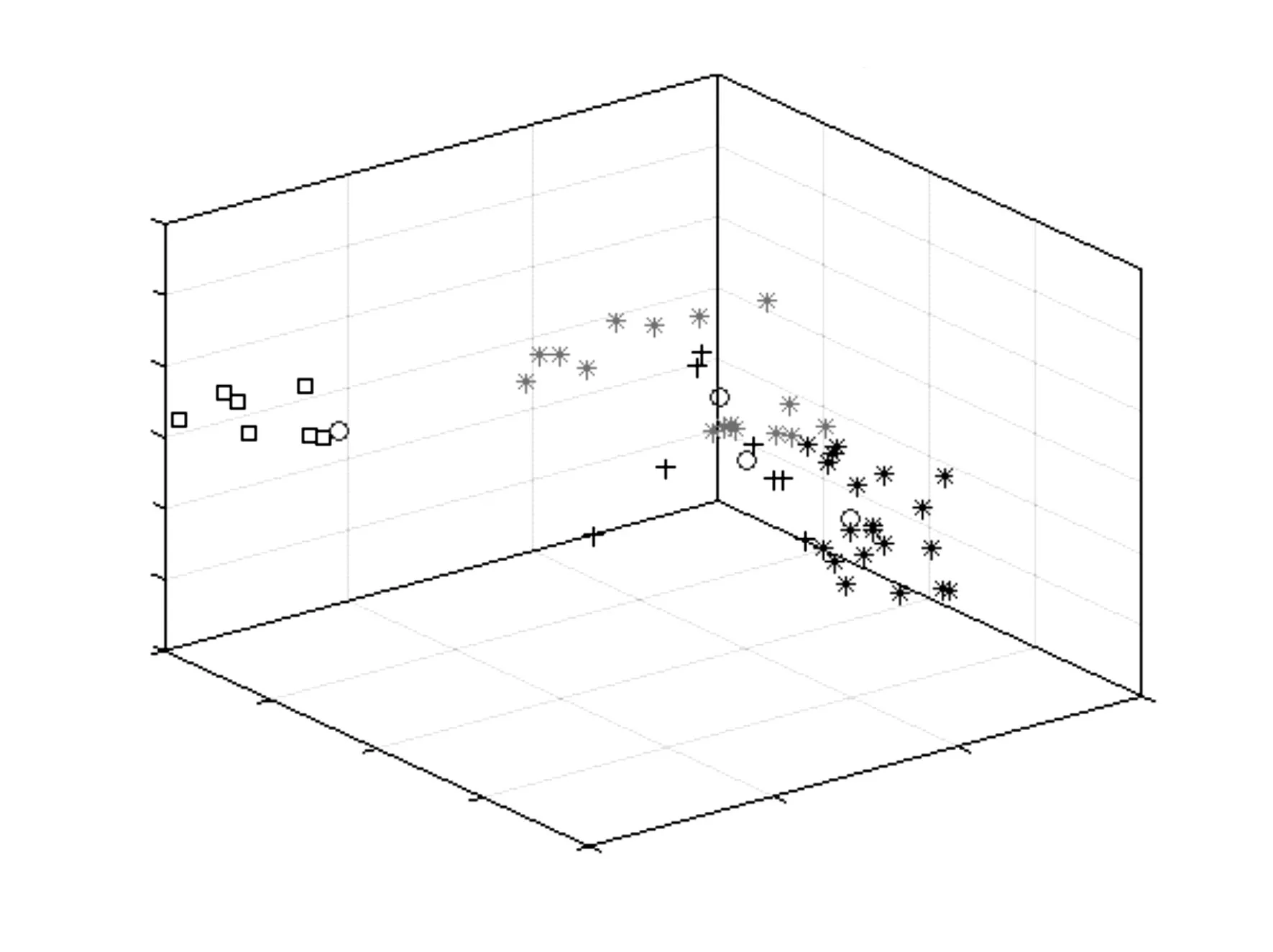
图3 最优聚类效果图
4.2 改进蚁群算法实验参数设置
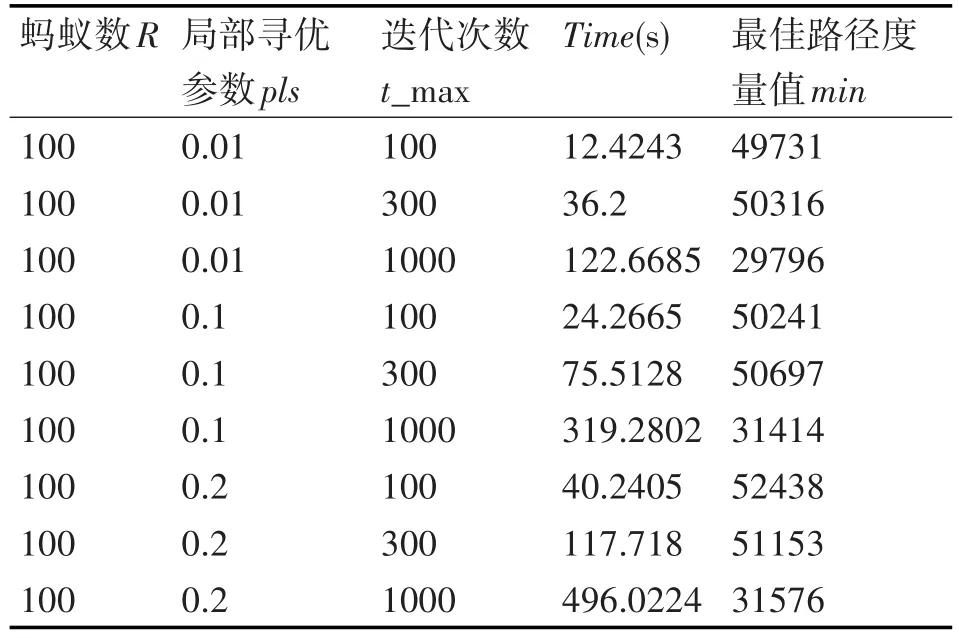
表2 改进蚁群算法参数设置表
在改进蚁群算法聚类实验过程中,通过设置不同的寻优参数、蚂蚁数量及迭代次数,将其聚类结果进行对比,选择为出最优聚类结果。实验证明当局部寻优参数 pls=0.01,R=100,t_max=1000时,此时的聚类效果能够达到最优。如图4所示为改进蚁群算法聚类效果图。
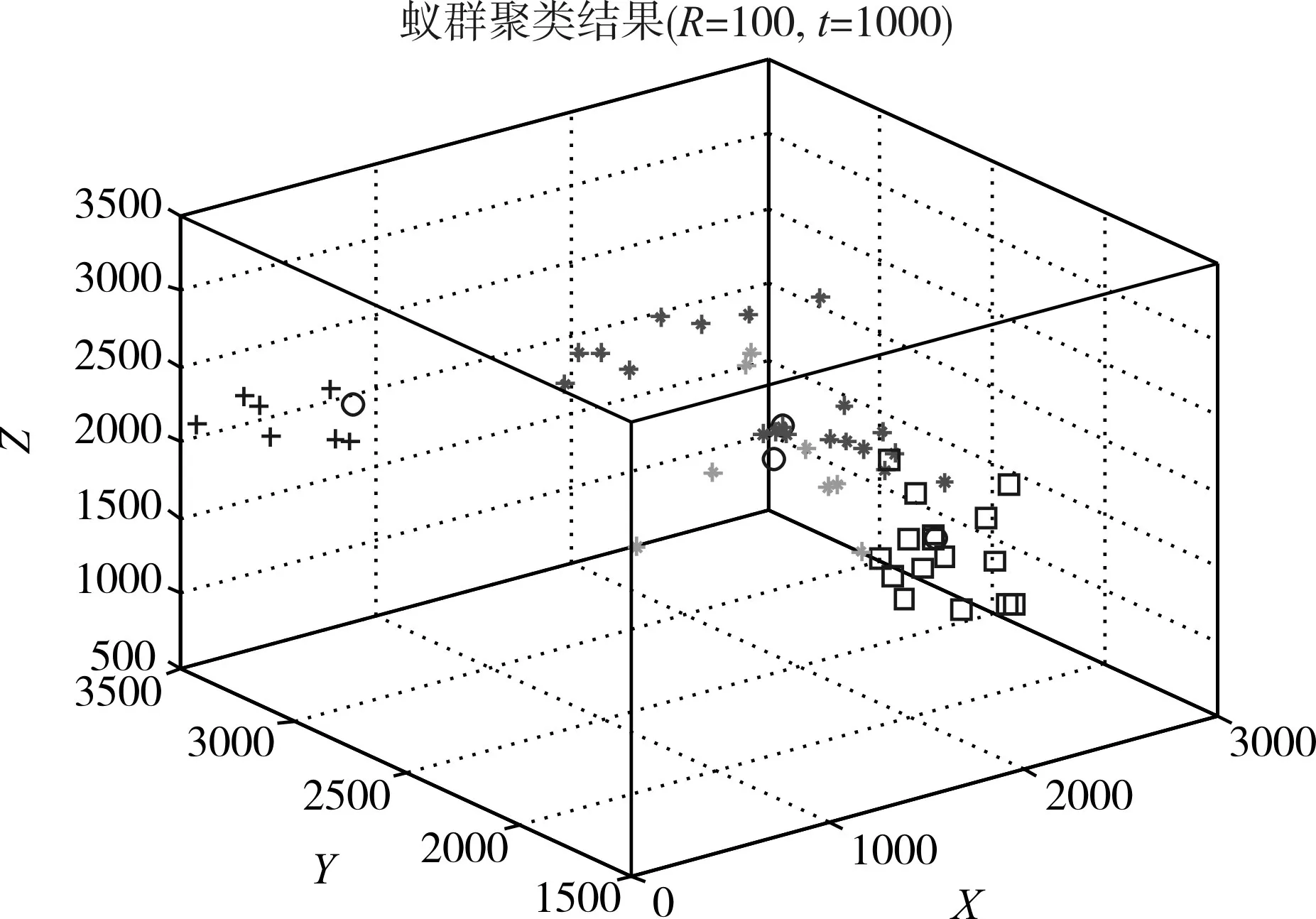
图4 改进蚁群算法聚类效果图
经过一般蚁群算法和改进蚁群算法实验对比发现,当控制变量(蚂蚁数量、迭代次数、聚类个数)相同时,基于遗传改进的蚁群算法的聚类用时和聚类效果明显优越于一般蚁群算法。将蚁群算法与遗传算法相结合,不断扩大了解的搜索空间,同时有效地避免陷入局部最优解的局面;结合聚类结果图可以发现改进的蚁群算法能够快速找到最优解,提高了收敛速度。
5 结语
本文介绍了一般蚁群算法聚类原理及算法所存在的缺陷,针对该算法在聚类过程中存在收敛速度慢和易于陷入局部最优解问题的缺陷,本文提出一种基于遗传改进蚁群聚类分析算法,主要在原来蚁群算法基础上同遗传算法变异因子相结合。在实验过程中采用控制变量方法、对比分析方法,验证改进的蚁群算法是否能够提高收敛性及陷入局部最优解的性能,经过实验证明改进蚁群算法聚类效果优于一般蚁群聚类算法,在一定程度上提高了收敛性,扩大了解的搜索范围并有效避免陷入局部最优解的困境。
